
Со времени предыдущего поста из жизни lock-free контейнеров прошло немало времени. Я рассчитывал быстро написать продолжение трактата об очередях, но вышла заминка: о чем писать, я знал, но реализации на C++ этих подходов у меня не было. «Не годится писать о том, что сам не попробовал», — подумал я, и в результате я попытался реализовать в libcds новые алгоритмы очередей.
Сейчас настал момент, когда я могу аргументированно продолжить свой цикл. В данной статье закончим с очередями.
Кратко напомню, на чем я остановился. Были рассмотрены несколько интересных алгоритмов lock-free очередей, а под занавес приведены результаты их работы на некоторых синтетических тестах. Главный вывод — всё плохо! Надежды на то, что lock-free подход на магическом compare-and-swap (CAS) даст нам пусть не линейный, но хотя бы какой-то рост производительности с увеличением числа потоков, не оправдались. Очереди не масштабируются. В чем причина?..
Ответ на этот вопрос лежит в особенностях архитектуры современных процессоров. Примитив CAS – довольно тяжелая инструкция, сильно нагружающая кеш и внутренний протокол синхронизации. При активном использовании CAS над одной и той же линией кеша процессор занят в основном поддержкой когерентности кешей, о чем подробнее профессор Paul McKenney
Стеки и очереди — очень недружественные для lock-free подхода структуры данных, так как они имеют небольшое число точек входа. Для стека такая точка только одна — вершина стека, для очереди их две — голова и хвост. CAS конкурирует за доступ к этим точкам, при этом проседает производительность при 100% загрузке процессора, — все потоки чем-то заняты, но только один выиграет и получит доступ к голове/хвосту. Ничего не напоминает?.. Это же классический spin-lock! Получается, при lock-free подходе на CASах мы избавились от внешней синхронизации мьютексом, но получили внутреннюю, на уровне инструкции процессора, и мало что выиграли.
Ограниченные очереди
Следует отметить, что все вышесказанное относится к неограниченным (unbounded) MPMC (multiple producer/multiple consumer) очередям. В ограниченных (bounded) по числу элементов очередях, которые строятся, как правило, на основе массива, данная проблема может быть не так ярко выражена за счет аккуратного рассредоточения (разброса) элементов очереди по массиву. Также более быстрые алгоритмы могут быть построены для очередей с одним писателем или/и одним читателем.
Проблема эффективной реализации конкурентных очередей интересует исследователей до сих пор. В последние годы усилилось понимание того, что различного рода ухищрения при реализации lock-free очереди «в лоб» не дают ожидаемого результата и следует придумать какие-то другие подходы. Далее мы рассмотрим некоторые из них.
Flat combining
Этот метод я уже описывал в статье о стеке, но flat combining является универсальным методом, поэтому применим и к очереди. Отсылаю читателей к видеозаписи моей презентации на C++ User Group, Russia, посвященной как раз реализации flat combining.
На правах рекламы
Пользуясь случаем, хочу послать лучи поддержки sermp — вдохновителю и организатору C++ User Group, Russia. Сергей, твой бескорыстный труд на этом поприще бесценен!
Читателей призываю обратить внимание на данное мероприятие и поддержать его своей явкой, а также, кому есть чем поделиться, презентациями. На своем опыте убедился, что живое общение намного круче, чем даже чтение хабра.
Также обращаю ваше внимание на грядущую конференцию C++Russia 27-28 февраля 2015 в Москве, — приходите!
Читателей призываю обратить внимание на данное мероприятие и поддержать его своей явкой, а также, кому есть чем поделиться, презентациями. На своем опыте убедился, что живое общение намного круче, чем даже чтение хабра.
Также обращаю ваше внимание на грядущую конференцию C++Russia 27-28 февраля 2015 в Москве, — приходите!
Массив очередей

Подход, лежащий на поверхности, но тем не менее довольно трудный для реализации, со множеством подводных камней, предложен в 2013 году в статье под названием «Замена конкуренции на сотрудничество для реализации масштабируемой lock-free очереди», как нельзя лучше подходящим к теме данного поста.
Идея очень проста. Вместо одной очереди строится массив размером K, каждый элемент которого — lock-free очередь, представленная односвязным списком. Новый элемент добавляется в следующий (по модулю K) слот массива. Тем самым нивелируется толчея на хвосте очереди, — вместо одного хвоста мы имеем K хвостов, так что можно ожидать, что мы получим линейную масштабируемость вплоть до K параллельных потоков. Конечно, нам нужно иметь некий общий атомарный монотонно возрастающий счетчик push-операций, чтобы мультиплексировать каждую вставку в свой слот массива. Естественно, данный счетчик будет единой «точкой преткновения» для всех push-потоков. Но авторы утверждают (по моим наблюдениям, небезосновательно), что инструкция
xadd атомарного добавления (в нашем случае — инкремента) на архитектуре x86 чуть быстрее, чем CAS. Таким образом, можно ожидать, что на x86 мы получим выигрыш. На других архитектурах атомарный fetch_add эмулируется CAS'ом, так что выигрыш будет не так заметен.Код удаления элемента из очереди аналогичен: имеется атомарный счетчик удаленных элементов (pop-счетчик), на основании которого по модулю K выбирается слот массива. Для исключения нарушения основного свойства очереди — FIFO – каждый элемент содержит дополнительную нагрузку (
ticket) — значение push-счетчика на момент добавления элемента, фактически — порядковый номер элемента. При удалении в слоте ищется элемент с ticket = текущему значению pop-счетчика, найденный элемент и является результатом операции pop().Интересен способ, которым решается проблема удаления из пустой очереди. В данном алгоритме сначала идет атомарный инкремент счетчика удалений (pop-счетчика), а затем — поиск в соответствующем слоте. Вполне может быть, что слот пустой. Это значит, что пуста и вся очередь. Но ведь pop-счетчик уже инкрементирован, и дальнейшее его использование приведет к нарушению FIFO и даже к потере элементов. Делать откат (декремент) нельзя — вдруг в это же самое время другие потоки добавляют или удаляют элементы (вообще, «назад-отыграть-нельзя» является неотъемлемым свойством lock-free подхода). Поэтому при возникновении ситуации
pop() из пустой очереди массив объявляется инвалидным, что приводит к созданию нового массива с новыми push- и pop-счетчиками при следующей вставке элемента.К сожалению, авторы не озаботились (как они пишут, по причине недостатка места) проблемой освобождения памяти, уделив ей лишь несколько предложений с поверхностным описанием применения схемы Hazard Pointer к своему алгоритму. Мне
libcds нет. К тому же алгоритм подвержен неограниченному накоплению удаленных элементов в случае, если очередь никогда не пуста, то есть если не происходит инвалидации массива, так как не предусматривается удаления элементов из списка-слота массива. pop() просто ищет элемент с текущим ticket'ом в соответствующем слоте, но физического исключения элемента из списка не происходит до инвалидации всего массива.Подытоживая, можно сказать: алгоритм интересный, но управление памятью не описано достаточно четко. Требуется дополнительное изучение.
Сегментированные очереди
Другой способ повысить масштабируемость очереди — нарушить её основное свойство first-in – first-out (FIFO). Так ли уж это страшно, зависит от задачи: для некоторых строгое соблюдение FIFO обязательно, для других — в некоторых пределах вполне допустимо.
Конечно, нарушать основное свойство FIFO совсем уж кардинально не хочется, — в этом случае мы получим структуру данных, называемую пулом, в которой не соблюдается вообще никакого порядка: операция
pop() возвращает любой элемент. Это уже не очередь. Для очереди с нарушением FIFO хотелось бы иметь какие-то гарантии этого нарушения, например: операция pop() возвратит один из первых K элементов. Для K=2 это значит, что для очереди с элементами A, B, C, D,… pop() возвратит A или B. Такие очереди называются сегментированными или K-сегментированными, чтобы подчеркнуть значение фактора K — ограничения на нарушение FIFO. Очевидно, что для строгой (fair) FIFO-очереди K=1.Насколько мне известно, впервые простейшая сегментированная очередь подробно рассмотрена в 2010 году в работе, посвященной как раз допустимым ослаблениям требований, накладываемых на lock-free структуры данных. Внутреннее строение очереди довольно просто (рисунок из вышеуказанной статьи, K=5):

Очередь представляет собой односвязный список сегментов, каждый сегмент — это массив размером K элементов.
Head и Tail указывают на первый и последний сегмент в списке соответственно. Операция push() вставляет новый элемент в произвольный свободный слот tail-сегмента, операция pop() извлекает элемент из произвольного занятого слота head-сегмента. При таком подходе очевидно, что чем меньше размер K сегмента, тем менее нарушается свойство FIFO; при K=1 мы получим строгую очередь. Таким образом, варьируя K, мы можем управлять степенью нарушения FIFO.В описываемом алгоритме каждый слот сегмента может быть в одном из трех состояний: свободный, занят (содержит элемент) и «мусор» (элемент был прочитан из слота). Заметим, что операция
pop() переводит слот в состояние «мусор», которое не является эквивалентом состояния «свободный»: состояние «мусор» является конечным состоянием слота, запись значения в такой слот недопустима. В этом проявляется недостаток алгоритма — слот в состоянии «мусор» нельзя повторно использовать, что приводит к распределению новых сегментов даже в такой типичной для очереди последовательности операций, как чередующийся push() / pop(). Этот недостаток был исправлен в другой работе ценой значительного усложнения кода.Исследуем
Итак, в libcds появились реализации двух новых алгоритмов для очередей — FCQueue и SegmentedQueue. Посмотрим их перформанс и попробуем понять, стоило ли ими заниматься.
К сожалению, сервер, на котором я гонял тесты для предыдущей статьи, был загружен другими задачами, а впоследствии рухнул. Пришлось прогонять тесты на другом сервере, менее мощном — 2 x 12 core AMD Opteron 1.5ГГц c 64G памяти под управлением Linux, который был практически свободен — idle на уровне 95%.
Я изменил визуализацию результатов — вместо времени выполнения теста по оси Y я теперь откладываю количество мегаопераций в секунду (Mop/s). Напомню, что тест – классический producer/consumer: всего 20 миллионов операций — 10M push и 10M pop без всякой эмуляции payload, то есть тупая долбежка в очередь. Во всех тестах lock-free очередей используется Hazard Pointer для безопасного освобождения памяти.
Старые данные в новых попугаях
График из предыдущей статьи в новых попугаях — MOp/s, выглядит так

Сначала — лирическое отступление: к чему мы стремимся? Что мы хотим получить, говоря о масштабируемости?
Идеальное масштабирование — линейное увеличение Mop/s при увеличении числа потоков, если железо физически поддерживает такое количество потоков. Реально хорошим результатом будет какое-то увеличение Mop/s, более похожее на логарифмическое. Если при увеличении числа потоков мы получаем проседание производительности, то алгоритм является немасштабируемым, или масштабируемым до некоторых пределов.
Результаты для интрузивных очередей (напомню, интрузивный контейнер характеризуется тем, что он содержит указатель на сами данные, а не их копию, как в STL; тем самым не требуется распределять память под копию элементов, что в мире lock-free считается моветоном).
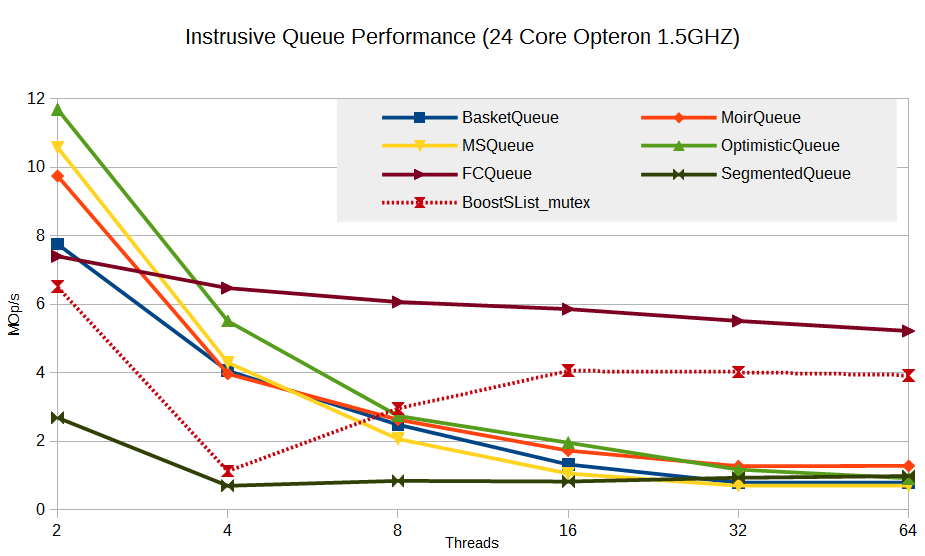
Видно, что Flat Combining реализован не напрасно, — эта техника показывает очень хороший результат на фоне других алгоритмов. Да, увеличения производительности она не дает, но и существенного проседания не видно. Более того, существенным бонусом является то, что она практически не нагружает процессор, — всегда работает только одно ядро. Остальные алгоритмы показывают 100% загрузку ЦП при большом числе потоков.
Сегментированная очередь показывает себя аутсайдером. Быть может, это связано со спецификой реализованного алгоритма: распределение памяти под сегменты (в данном тесте размер сегмента равен 16), невозможность повторно использовать слоты сегмента, что приводит к постоянным аллокациям, реализация списка сегментов на основе boost::intrusive::slist под блокировкой (я пробовал два типа блокировок — spin-lock и std::mutex; результаты практически не отличаются).
Была у меня надежда, что основным тормозом является false sharing. В реализации сегментированной очереди сегмент представлял собой массив указателей на элементы. При размере сегмента равным 16 сегмент занимает 16 * 8 = 128 байт, то есть две линии кеша. При постоянной толкотне потоков на первом и последнем сегментах false sharing может проявить себя в полный рост. Поэтому я ввел дополнительную опцию в алгоритм — требуемый padding. При указании padding = размеру кеш-линии (64 байт) размер сегмента увеличивается до 16 * 64 = 1024 байт, но таким образом мы исключаем false sharing. К сожалению, оказалось, что padding практически никак не влияет на производительность SegmentedQueue. Быть может, причина этого в том, что алгоритм поиска ячейки сегмента является вероятностным, что приводит к многим неудачным попыткам чтения занятых ячеек, то есть опять-таки к false sharing. Или же false sharing вовсе не является основным тормозом для данного алгоритма и надо искать истинную причину.
Несмотря на проигрыш, есть одно интересное наблюдение: SegmentedQueue не показывает проседание производительности при увеличении числа потоков. Это вселяет надежду на то, что алгоритмы данного класса имеют какую-то перспективу. Просто надо реализовать их по-другому, более эффективно.
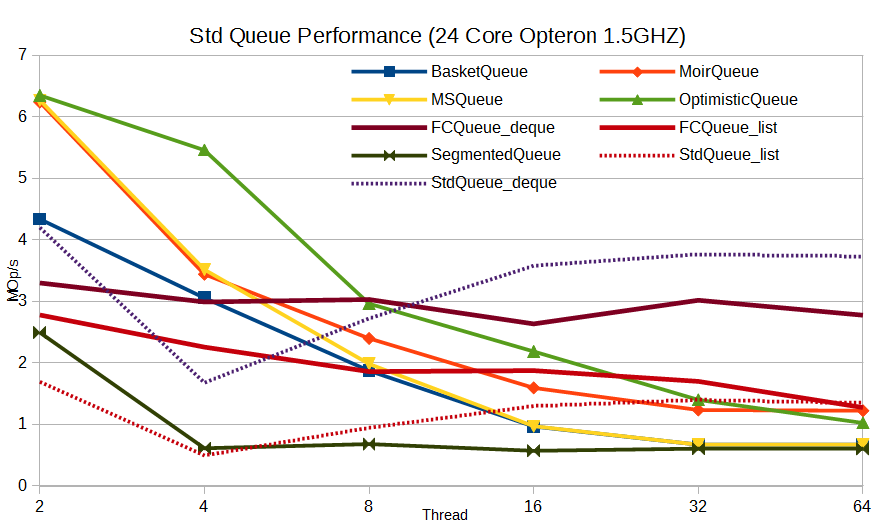
Для STL-like очередей, с созданием копии элемента, имеем похожую картину:
Наконец, просто ради интереса приведу результат bounded queue – алгоритм Дмитрия Вьюкова на основе массива, интрузивная реализация:
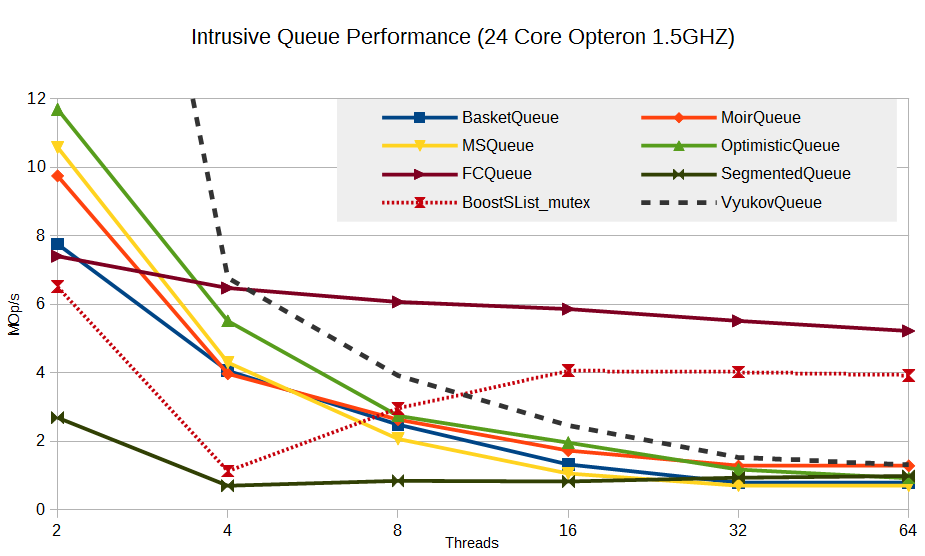
При числе потоков = 2 (один читатель и один писатель) эта очередь показывает 32 MOp/s, что не уместилось на графике. При увеличении числа потоков также наблюдаем деградацию производительности. В качестве оправдания можно отметить, что для очереди Вьюкова false sharing также может быть очень существенным тормозящим фактором, но опции, включающей padding по кеш-линии, для неё ещё нет в libcds.
для любителей странного
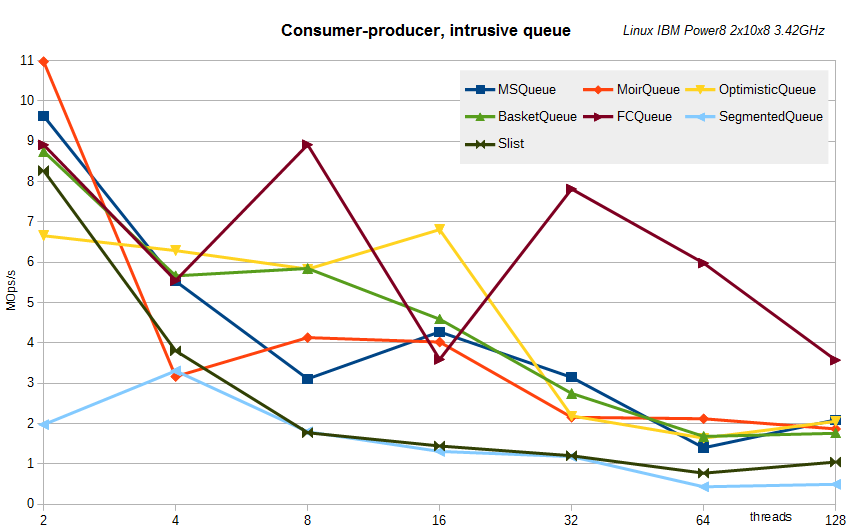
Попался мне и необычный Linux-сервер на IBM Power8 — два процессора 3.42 ГГц по десять ядер в каждом, каждое ядро может одновременно выполнять до 8 инструкций одновременно, итого 160 логических процессоров. Вот результаты тех же самых тестов на нем.
Интрузивные очереди:
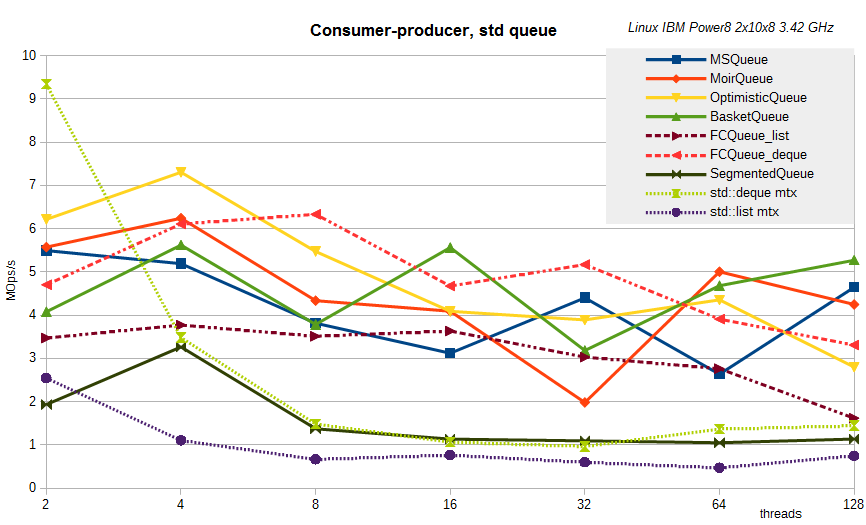
STL-like очереди:
Как видно, принципиальных изменений не наблюдается. Хотя нет, одно есть — показаны результаты для сегментированной очереди при размере сегмента K=256 — именно это K было для данного сервера близко к наилучшему.
Интрузивные очереди:
STL-like очереди:
Как видно, принципиальных изменений не наблюдается. Хотя нет, одно есть — показаны результаты для сегментированной очереди при размере сегмента K=256 — именно это K было для данного сервера близко к наилучшему.
В заключение хочу отметить одно интересное наблюдение. В вышеприведенных тестах для читателей и писателей нет никакой полезной нагрузки (payload), наша цель — просто запихнуть в очередь и прочитать из неё. В реальных задачах какая-то нагрузка всегда есть, — мы что-то делаем с данными, прочитанными из очереди, а перед тем, как поместить в очередь, мы данные готовим. Казалось бы, payload должен приводить к проседанию производительности, но практика показывает, что это далеко не всегда так. Я не раз наблюдал, что payload приводит к существенному росту

В этой статье я коснулся малой части работ, посвященных очередям, и только динамическим (unbounded), то есть без ограничения количества элементов. Как я уже говорил, очередь — одна из излюбленных структур данных для исследователей, видимо, потому, что плохо поддается масштабированию. За бортом обзора осталось множество других работ, — об ограниченных (bounded) очередях, work-stealing очередях, применяемых в планировщиках задач, single consumer или single producer очередях — алгоритмы таких очередей существенно заточены на одного писателя или читателя, а потому зачастую проще и/или намного производительнее, — и т.д. и т.п.
Новости из микромира libcds
За прошедшее с предыдущей статьи время была выпущена версия 1.6.0 библиотеки, в которой помимо реализации техники Flat Combining и SegmentedQueue пофикшено какое-то количество ошибок, существенно переработан SkipList и EllenBinTree.
Репозиторий для грядущей версии 2.0 переехал на github, а сама версия 2.0 посвящена переходу на стандарт C++11, причесыванию кода, унификации интерфейсов, из-за чего нарушится пресловутая обратная совместимость (что означает, что некоторые сущности будут переименованы), и удалению костылей поддержки старых компиляторов (ну и, как водится, исправлению найденных и генерации новых багов).
Репозиторий для грядущей версии 2.0 переехал на github, а сама версия 2.0 посвящена переходу на стандарт C++11, причесыванию кода, унификации интерфейсов, из-за чего нарушится пресловутая обратная совместимость (что означает, что некоторые сущности будут переименованы), и удалению костылей поддержки старых компиляторов (ну и, как водится, исправлению найденных и генерации новых багов).
Я рад, что мне удалось-таки, несмотря на большой временной лаг, довести повествование об очередях и стеках до логического конца, ибо это не самые дружественные для lock-free подхода и современных процессоров структуры данных, да и не очень для меня интересные.
Впереди нас ждут куда более увлекательные структуры — ассоциативные контейнеры (set/map), в частности, hash map, с красивыми алгоритмами и, надеюсь, более благодарные в плане масштабируемости.
Продолжение, думаю, воспоследует…
Lock-free структуры данных
