Существует достаточно широкий круг задач, где требуется анализ, аудио-визуальных моделей реальности. Это относится и к статическим изображениям, и к видео.

Ниже приведен небольшой обзор некоторых существующих методов поиска и идентификации нечетких дубликатов видео, рассмотрены их преимущества и недостатки. На основе структурного представления видео построена комбинация методов.
Обзор совсем небольшой, за подробностями, лучше обращаться к первоисточникам.
Понятие «нечеткий дубликат» означает неполное или частичное совпадение объекта с другим объектом подобного класса. Дубликаты бывают естественные и искусственные. Естественные дубликаты — схожие объекты, при схожих условиях. Искусственные нечеткие дубликаты — полученные на основе одного и того же оригинала.
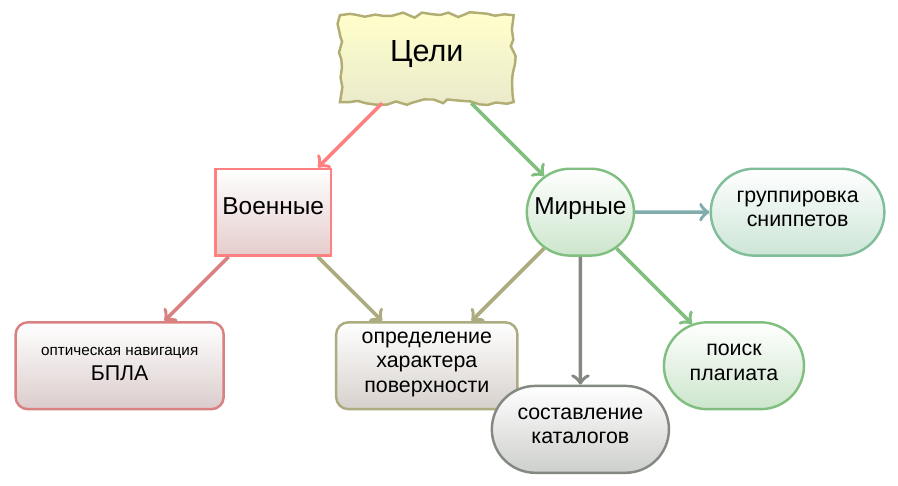
Поиск нечетких дубликатов может быть полезен для оптической навигации беспилотных летальных аппаратов (к сожалению, не всегда в мирных целях), для определения характера ландшафта местности, составления каталогов видео, группировки сниппетов поисковых систем, фильтрация видео рекламы, и поиска «пиратского» видео.
Проблема поиска нечетких дубликатов видео (НДВ) тесно связана с проблемами классификации (КВ) и поиска по видео (ПВ). Задача поиска НДВ может быть сведена к классификации, а та, в свою очередь, к аннотации и поиску по видео. |{поиск НДВ}| < |{КВ}| < |{ПВ}|. Но эти задачи являются самостоятельными.

Для поиска НДВ видео делят на отрезки. Из каждого отрезка выделяют ключевые кадры. Характеристики ключевых кадров используются для представления всего видео целиком. Подобие между видео вычисляют как подобие наборов этих характеристик.
Способы поиска НДВ образуют две категории: методы, использующие глобальные характеристики (ГХ); методы, использующие локальные характеристики (ЛХ). Грань между категориями условна, очень часто применяют смешанные техники. ГХ-методы выделяют подписи уровня кадра для моделирования пространственной, цветовой и временной информации. ГХ обобщают глобальную статистику низкоуровневых признаков. Сходство между видео определяется как соответствие последовательностей подписей (сигнатур). Они могут быть полезны, для поиска «почти одинаковых» видео и могут выявить незначительные правки в пространственно-временной области. ГХ неэффективны при работе с искусственными НДВ, которые были получены в результате косметического редактирования. Для таких групп более полезны методы, использующие низкоуровневые характеристики сегмента или кадра. Обычно на работу этих методов влияют изменения во временном порядке и вставка или удаление кадров. По сравнению с глобальными методами, подходы уровня сегмента медленнее. Они более требовательны по памяти, хотя и способны к выявлению копий, которые подверглись существенному редактированию.
ЛХ-методы, сводят задачу поиска похожих видео к задаче поиска дубликатов изображений. Основные шаги при сравнении изображений: определение особых точек; выделение окрестностей особых точек; построение векторов признаков; выделение деcкрипторов изображений; сравнение деcкрипторов пары изображений. В работе Robust voting algorithm based on labels of behavior for video copy detection выделяют особые точки кадра (с помощью детектора Харриса) и отслеживают их положение на протяжении всего видео. После чего формируют множество траекторий точек.

Сопоставление с образцом происходит на основе нечеткого поиска. Подход облегчает локализацию нечетких дубликатов фрагментов. Однако, метод дорог из-за выделения особых точек кадров. А факт того, что траектории точек чувствительны к движению камеры, делают алгоритм применимым только для поиска точных копий видео.
Авторы Non-identical Duplicate Video Detection Using The SIFT method выделяют особые точки ключевых кадров, и оценивают подобие кадров на основе SIFT. Подобие кадров вычисляют как среднее арифметическое количества совпавших особых точек. Но для определения сходства видео, используется полная оценка соответствия (ПОС) как среднее значение подобия ключевых кадров по всему видео. Важно, что среднее значение вычисляется, не по всем возможным парам кадров, а только по некоторым из них. Это позволяет экономить вычислительные ресурсы.
Работа интересна и тем, что в ней выделение кадров происходит вдоль временной оси, а не поперек, как в обычном видео. Такой срез позволяет извлекать временную информацию из видео, и применять к ней пространственные методы сравнения, такие же как к обычным кадрам: к срезам двух видео применяют SIFT и вычисляют ПОС.
По результатам экспериментов метод продольного выделения кадров —хуже обычного. Особенно это проявляется, если в видео много резких движений камеры. К минусам общего подхода можно отнести применение SIFT. Эксперименты проводились на видео с маленьким разрешением (320×240). При увеличении размера кадров выделение особых точек будет очень затратным. Если применять ПОС только к обычным кадрам, то временная информация видео не будет учтена.
Методы, использующие визуальные слова, являются улучшенной версией прямого сравнения особых точек кадров. В их основе лежит квантование особых точек — формирование «слов». Сравнение кадров (и видео) целиком происходит по частотным словарям, как для текстов. Работа Inria-Learar's video copy detection system демонстрирует превосходную производительность метода. Ключевые кадры представлены особенностями, которые получены с помощью SIFT. Затем эти характеристики квантуются в визуальные слова. Из визуальных слов строится бинарная подпись. Но, для применения визуальных слов, должны быть построены частотные словари для заранее известной предметной области.
С помощью ГХ-методов из видео выделяют цветовую, пространственную и временную информацию, представляют ее в виде последовательности символов, и применяют методы поиска совпадающих строк.
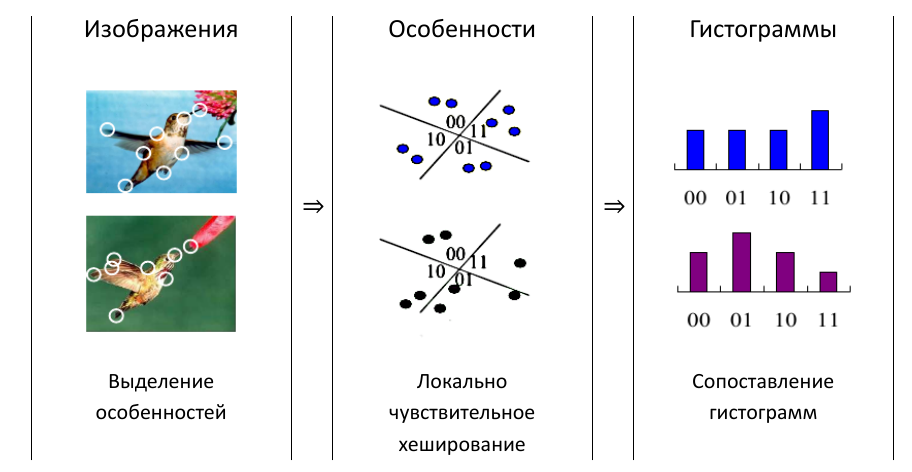
В работе Efficiently matching sets of features with random histograms применяют локально-чувствительное хеширование (ЛЧХ). Его используют для отображения цветовой гистограммы каждого ключевого кадра на бинарный вектор. Характеристики кадра выделяются из локальных особенностей изображения. Эти характеристики представляются как множества точек в пространстве характеристик. При помощи ЛЧХ точки отображаются на дискретные значения. По набору особенностей строится гистограмма кадра. Далее гистограммы сравниваются как обычные последовательности.
Экспериментальные результаты подтвердили эффективность. Но, как было указано в работе Large-scale near-duplicate Web video search: challenge and opportunity метод страдает от потенциальной проблемы большого потребления памяти. Временная информация никак не учитывается.
В работе Robust video signature based on ordinal measure используются порядковые подписи для моделирования относительного распределения интенсивности в кадре. Расстояние между двумя фрагментами измеряется с помощью временного сходства подписей. Подход позволяет искать нечеткие дубликаты видео с разными разрешением, частотой кадров, с незначительными пространственными изменениями кадров. Плюсом алгоритма является возможность работы в режиме реального времени. К минусам можно отнести неустойчивость к большим вставкам лишних кадров. Метод плохо применим для поиска естественных нечетких дубликатов, например, если объект снимался при разной освещенности.
В работе Comparison of sequence matching techniques for video copy detection описана подпись движения, которая фиксирует относительное изменение интенсивности с течением времени. Сравниваются цветовые подписи, подписи движения и порядковая подпись. Эксперименты показывают, что порядковая подпись является более эффективной…
Предложенный в работе Near-duplicate Video Retrieval Based on Clustering by Multiple Sequence Alignment подход сводит задачу поиска нечетких дубликатов видео к задаче классификации видео. Метод основан на множественном выравнивании последовательностей (MSA). Подобный подход используется в биоинформатике для поиска выравнивания последовательностей ДНК. Авторы используют эвристическое выравнивание и итеративные методы, предложенные в работе Muscle: multiple sequence alignment with high accuracy and high throughput. Метод можно описать следующей последовательностью шагов.
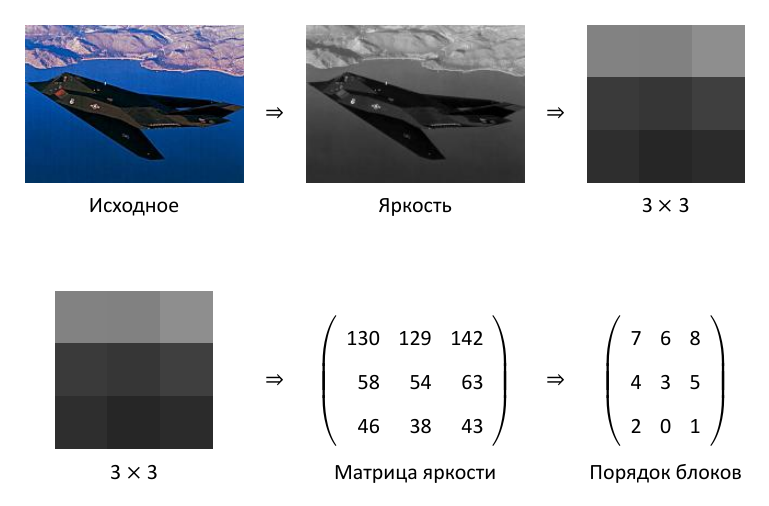
Для представления видео как геномов выделяют ключевые кадры, переводят в полутоновое цветовое пространство и разбивают кадры на блоки 2 × 2. Возможно всего 24 = (2 ⋅ 2)! пространственных порядковых шаблона. Каждому такому шаблону можно поставить в соответствие букву латинского алфавита.

Матрица расстояний строится при использовании скользящего окна размера n. Таким образом, сравнение видео происходит на основе n-грамм. Сравнение между двумя ДНК-представлениями видео происходит только в окне.
Размер окна и размер шага (на сколько сдвигать окно после сравнения) задаются как параметры.
Направляющее дерево строится жадным эвристическим алгоритмом присоединения соседей. Согласно матрице расстояний выделяют два наиболее близких ДНК-представления и объединяют их в один узел дерева как профиль видео. В этой модели каждое видео-ДНК — листья дерева, в узлах дерева оказываются профили. Профили также сравниваются между собой, и склеиваются аналогично листовым представлением. В результате образуется дерево принятия решений.
Ниже показано направляющее дерево.
Плюсы подхода: обладает высокой точностью и полнотой и не требует особенных вычислительных затрат. Минусы подхода — метод никак не учитывает временную информацию видео.
В работе A suffix array approach to video copy detection in video sharing socialnetworks введена подпись на основе определения границ сцен (съёмок).
Существует три различных понятия. Кадр или фотографический кадр — статическая картинка. Сцена или монтажный кадр — множество кадров связанных единством места и времени. Съемка или кинематографический кадр, множество кадров связанных единством съемки. Сцена может включать несколько съемок. В литературе съемку часто называют «сценой». Далее мы будем рассматривать съемку, но называть ее будем так же, — «сценой».
Видео содержит больше информации, чем просто серия кадров. События в видео уникально определяют его временную структуру, которая может быть представлена набором ключевых кадров.
Под ключевыми кадрами в данном случае понимаются не I-кадр, а просто некоторый особый кадр видео. Под событиями понимается не смысловая составляющая сюжета видео, а только изменение содержимого кадров. Выделение ключевых кадров основано на поиске различий в гистограммах яркости. После извлечения ключевых кадров, вычисляется длина между текущим ключевым кадром и предыдущим. Все длины записываются как одномерная последовательность. Эта последовательность длин сцен — и есть подпись видео. Эксперименты показывают, что два несвязанных видеоклипа не имеют длинного набора последовательных ключевых кадров с теми же длинами сцен. В работе предложен эффективный способ сопоставления подписей видео. для этого используется суффиксный массив. Проблема сводится к поиску общих подстрок. Метод плохо работает если в видео много перемещений камеры или объектов и при плавных переходах между сценами. К минусам стоит отнести и невозможность работы в режиме реального времени, для сравнения необходимо иметь видео целиком.
В работе Алгоритм поиска дубликатов в базе видеопоследовательностей на основе сопоставления иерархии смен сцен предложен алгоритм сопоставлении дерева сцен (съёмок). На основе найденных смен сцен строят двоичное дерево. Поддеревья соответствуют фрагментам видео. Корневые вершины поддеревьев хранят величины и положение доминирующей смены сцен в текущем фрагменте. При сравнении, в одном дереве (более длинное видео) ищут вершины наиболее близкие по величине к корню второго дерева, и сопоставляют их координаты. Процедуру выполняют рекурсивно для оставшихся смен сцен. Плюсами метода являются устойчивость к большинству приемов создания искусственных дубликатов (т.к. используется только временная информация), малая сложность сравнения двух клипов и возможность создания иерархических индексов фильмов. Это позволяет отлавливать несовпадения, на начальных этапах проверки. Минусами подхода как и предыдущего является то, что не учитываются характеристики самих сцен. Для определения нечетких дубликатов требуется иметь видео-запрос полностью, что не всегда возможно.
Для поиска НДВ применяют самые разнообразные методы. На данный момент наиболее перспективными кажутся ГХ-методы. Они позволяют без особых вычислительных затрат приближенно решить задачу. Однако, для уточнения могут потребоваться ЛХ-методы. Как показано в работе Large-scale near-duplicate Web video search: challenge and opportunity применение комбинированных подходов дает точность выше чем у каждого из методов по-отдельности.
Интерес представляют работы, в которых строится структурная модель видео. Видео можно рассматривать как последовательность фактов, развивающихся во времени. Причем, в разных видео могут быть различны как сами факты, так и их порядок. Свойства фактов образуют пространственную характеристику видео, а продолжительность и порядок фактов — временную. Самый простой способ выделить факты из видео — использовать точки смены сцен (съёмок). Важно учитывать, что время в двух различных видео может идти по-разному. Мы предлагаем использовать отношения длин сцен к длинам соседних сцен… Относительные длины сцен двух нечетких дубликатов редко будут совпадать. Это связано, в том числе, и с ошибками распознавания границ сцен. Для решения такой проблемы, можно применить алгоритмы выравнивания последовательностей. Но, так, мы сравним только порядок видео-фактов. Для сравнения самих фактов требуются внутренние характеристики сцен, например, характеристики начального и конечного кадров. Тут удобно удобно использовать визуальные слова, как прием из ЛХ-методов. Таким образом, мы получили дескриптор сцены.
Формально cцена как «съемка», кинематографический кадр — совокупность множества фотографических кадров внутри временной области, кадры, которой значительно отличается от кадров соседних областей. На картинке ниже — первые кадры сцен некоторого видео.
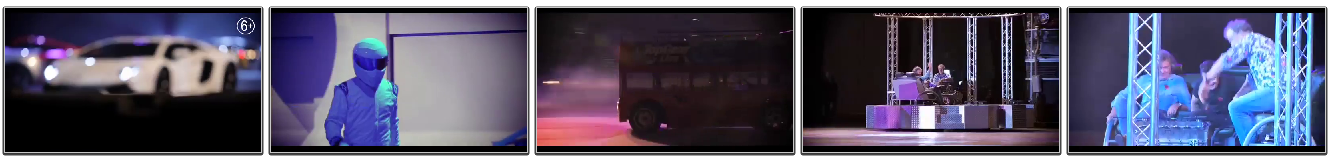
Если исходное видео сжать разными кодеками, мы получим нечеткие дубликаты этого видео. Выделяя сцены в каждом видео, увидим, что точки перемены сцен для этих двух файлов не совпадают.
Для решения этой проблемы предлагается использовать относительные длины сцен. Относительная длина сцены вычисляется как вектор отношений абсолютной длины сцены к абсолютным длинам остальных сцен видео. В практических задачах удобнее вычислять отношения длин, для трех предыдущих сцен, а не для всех. Это удобно и в случае, если все видео целиком нам недоступно и мы имеем дело с видео-потоком, например в задачах реального времени.
Относительные длины сцен двух нечетких дубликатов редко будут совпадать. Более того, многие сцены могут просто не распознаваться. Это связано, в том числе, с ошибками распознавания границ сцен.
Если относительная длина сцены одного видео отличается от длины сцены другого видео не более чем в два раза, и все предыдущие сцены выравнены, то, текущая пара сцен выражает одно и то же явление, при условии, что оба видео являются нечеткими дубликатами друг друга (гипотеза Гейла-Черча). Подобный подход применяется в математической лингвистике для выравнивания параллельных корпусов текстов на разных языках. Чем менее отличаются относительные длины сцен, тем более вероятно, что сцены похожи. Если длины отличаются больше чем в два раза, то длину меньшей сцены складывают с длиной следующей сцены этого же видео, и рассматривают объединенную сцену как одну. В случае совпадения относительных длин сцен видео применяется сравнение внутренних свойств сцены.
Таким образом, формально можно описать предложенный дескриптор сцены. Он состоит из вектора отношений длины сцены к длинам других сцен и характеристик начального и конечного кадров. Его удобно его сразу хранить, с объединениями соседних сцен (трех предыдущих) учитывая гипотезу Гейла-Черча.
Благодаря такому дескриптору и различным техническим ухищрениям (семантическое хеширование) был построен достаточно очевидный алгоритм.

Но практическая реализация его пока в зачаточном состоянии. Какие-то результаты все же были получены *, но по некоторым внешним причинам работа была временно остановлена.
Буду очень рад любым замечаниям и дополнениям.
UPD 1:
Некоторое дополнение по материалу можно найти в презентации: Элементы поиска нечетких дубликатов видео
Еще по теме:
Спасибо goodok за исправление грамматических ошибок.
Ниже приведен небольшой обзор некоторых существующих методов поиска и идентификации нечетких дубликатов видео, рассмотрены их преимущества и недостатки. На основе структурного представления видео построена комбинация методов.
Обзор совсем небольшой, за подробностями, лучше обращаться к первоисточникам.
Понятие «нечеткий дубликат» означает неполное или частичное совпадение объекта с другим объектом подобного класса. Дубликаты бывают естественные и искусственные. Естественные дубликаты — схожие объекты, при схожих условиях. Искусственные нечеткие дубликаты — полученные на основе одного и того же оригинала.
Поиск нечетких дубликатов может быть полезен для оптической навигации беспилотных летальных аппаратов (к сожалению, не всегда в мирных целях), для определения характера ландшафта местности, составления каталогов видео, группировки сниппетов поисковых систем, фильтрация видео рекламы, и поиска «пиратского» видео.
Проблема поиска нечетких дубликатов видео (НДВ) тесно связана с проблемами классификации (КВ) и поиска по видео (ПВ). Задача поиска НДВ может быть сведена к классификации, а та, в свою очередь, к аннотации и поиску по видео. |{поиск НДВ}| < |{КВ}| < |{ПВ}|. Но эти задачи являются самостоятельными.
Общий алгоритм
Для поиска НДВ видео делят на отрезки. Из каждого отрезка выделяют ключевые кадры. Характеристики ключевых кадров используются для представления всего видео целиком. Подобие между видео вычисляют как подобие наборов этих характеристик.
Подходы
Способы поиска НДВ образуют две категории: методы, использующие глобальные характеристики (ГХ); методы, использующие локальные характеристики (ЛХ). Грань между категориями условна, очень часто применяют смешанные техники. ГХ-методы выделяют подписи уровня кадра для моделирования пространственной, цветовой и временной информации. ГХ обобщают глобальную статистику низкоуровневых признаков. Сходство между видео определяется как соответствие последовательностей подписей (сигнатур). Они могут быть полезны, для поиска «почти одинаковых» видео и могут выявить незначительные правки в пространственно-временной области. ГХ неэффективны при работе с искусственными НДВ, которые были получены в результате косметического редактирования. Для таких групп более полезны методы, использующие низкоуровневые характеристики сегмента или кадра. Обычно на работу этих методов влияют изменения во временном порядке и вставка или удаление кадров. По сравнению с глобальными методами, подходы уровня сегмента медленнее. Они более требовательны по памяти, хотя и способны к выявлению копий, которые подверглись существенному редактированию.
Локальные характеристики
Отслеживание траекторий
ЛХ-методы, сводят задачу поиска похожих видео к задаче поиска дубликатов изображений. Основные шаги при сравнении изображений: определение особых точек; выделение окрестностей особых точек; построение векторов признаков; выделение деcкрипторов изображений; сравнение деcкрипторов пары изображений. В работе Robust voting algorithm based on labels of behavior for video copy detection выделяют особые точки кадра (с помощью детектора Харриса) и отслеживают их положение на протяжении всего видео. После чего формируют множество траекторий точек.
Сопоставление с образцом происходит на основе нечеткого поиска. Подход облегчает локализацию нечетких дубликатов фрагментов. Однако, метод дорог из-за выделения особых точек кадров. А факт того, что траектории точек чувствительны к движению камеры, делают алгоритм применимым только для поиска точных копий видео.
Среднее значение
Авторы Non-identical Duplicate Video Detection Using The SIFT method выделяют особые точки ключевых кадров, и оценивают подобие кадров на основе SIFT. Подобие кадров вычисляют как среднее арифметическое количества совпавших особых точек. Но для определения сходства видео, используется полная оценка соответствия (ПОС) как среднее значение подобия ключевых кадров по всему видео. Важно, что среднее значение вычисляется, не по всем возможным парам кадров, а только по некоторым из них. Это позволяет экономить вычислительные ресурсы.
Продольные кадры
Работа интересна и тем, что в ней выделение кадров происходит вдоль временной оси, а не поперек, как в обычном видео. Такой срез позволяет извлекать временную информацию из видео, и применять к ней пространственные методы сравнения, такие же как к обычным кадрам: к срезам двух видео применяют SIFT и вычисляют ПОС.
По результатам экспериментов метод продольного выделения кадров —хуже обычного. Особенно это проявляется, если в видео много резких движений камеры. К минусам общего подхода можно отнести применение SIFT. Эксперименты проводились на видео с маленьким разрешением (320×240). При увеличении размера кадров выделение особых точек будет очень затратным. Если применять ПОС только к обычным кадрам, то временная информация видео не будет учтена.
Визуальные слова
Методы, использующие визуальные слова, являются улучшенной версией прямого сравнения особых точек кадров. В их основе лежит квантование особых точек — формирование «слов». Сравнение кадров (и видео) целиком происходит по частотным словарям, как для текстов. Работа Inria-Learar's video copy detection system демонстрирует превосходную производительность метода. Ключевые кадры представлены особенностями, которые получены с помощью SIFT. Затем эти характеристики квантуются в визуальные слова. Из визуальных слов строится бинарная подпись. Но, для применения визуальных слов, должны быть построены частотные словари для заранее известной предметной области.
Глобальные характеристики
С помощью ГХ-методов из видео выделяют цветовую, пространственную и временную информацию, представляют ее в виде последовательности символов, и применяют методы поиска совпадающих строк.
Локально-чувствительное хеширование
В работе Efficiently matching sets of features with random histograms применяют локально-чувствительное хеширование (ЛЧХ). Его используют для отображения цветовой гистограммы каждого ключевого кадра на бинарный вектор. Характеристики кадра выделяются из локальных особенностей изображения. Эти характеристики представляются как множества точек в пространстве характеристик. При помощи ЛЧХ точки отображаются на дискретные значения. По набору особенностей строится гистограмма кадра. Далее гистограммы сравниваются как обычные последовательности.
Экспериментальные результаты подтвердили эффективность. Но, как было указано в работе Large-scale near-duplicate Web video search: challenge and opportunity метод страдает от потенциальной проблемы большого потребления памяти. Временная информация никак не учитывается.
Порядковые подписи
В работе Robust video signature based on ordinal measure используются порядковые подписи для моделирования относительного распределения интенсивности в кадре. Расстояние между двумя фрагментами измеряется с помощью временного сходства подписей. Подход позволяет искать нечеткие дубликаты видео с разными разрешением, частотой кадров, с незначительными пространственными изменениями кадров. Плюсом алгоритма является возможность работы в режиме реального времени. К минусам можно отнести неустойчивость к большим вставкам лишних кадров. Метод плохо применим для поиска естественных нечетких дубликатов, например, если объект снимался при разной освещенности.
В работе Comparison of sequence matching techniques for video copy detection описана подпись движения, которая фиксирует относительное изменение интенсивности с течением времени. Сравниваются цветовые подписи, подписи движения и порядковая подпись. Эксперименты показывают, что порядковая подпись является более эффективной…
Видео как ДНК
Предложенный в работе Near-duplicate Video Retrieval Based on Clustering by Multiple Sequence Alignment подход сводит задачу поиска нечетких дубликатов видео к задаче классификации видео. Метод основан на множественном выравнивании последовательностей (MSA). Подобный подход используется в биоинформатике для поиска выравнивания последовательностей ДНК. Авторы используют эвристическое выравнивание и итеративные методы, предложенные в работе Muscle: multiple sequence alignment with high accuracy and high throughput. Метод можно описать следующей последовательностью шагов.
- Для видео строится ДНК-представление.
- Видео из базы данных, сравнивается каждое с каждым, и строится матрица расстояний.
- На основе матрицы расстояний с помощью метода присоединения соседей (neighbor joining) строится направляющее дерево (guide tree).
- На основе направляющего дерева выполняется прогрессивное выравнивание видео.
- Результаты выравнивания используются для формирования кластеров видео.
- При поиске в базе данных, запрос сравнивают с центрами кластеров. Если подобие между запросом и центром кластера превышает некоторый заданный порог, то все клипы кластера считаются нечеткими дубликатами запроса.
Для представления видео как геномов выделяют ключевые кадры, переводят в полутоновое цветовое пространство и разбивают кадры на блоки 2 × 2. Возможно всего 24 = (2 ⋅ 2)! пространственных порядковых шаблона. Каждому такому шаблону можно поставить в соответствие букву латинского алфавита.
Матрица расстояний строится при использовании скользящего окна размера n. Таким образом, сравнение видео происходит на основе n-грамм. Сравнение между двумя ДНК-представлениями видео происходит только в окне.
Размер окна и размер шага (на сколько сдвигать окно после сравнения) задаются как параметры.
Направляющее дерево строится жадным эвристическим алгоритмом присоединения соседей. Согласно матрице расстояний выделяют два наиболее близких ДНК-представления и объединяют их в один узел дерева как профиль видео. В этой модели каждое видео-ДНК — листья дерева, в узлах дерева оказываются профили. Профили также сравниваются между собой, и склеиваются аналогично листовым представлением. В результате образуется дерево принятия решений.
Ниже показано направляющее дерево.
Плюсы подхода: обладает высокой точностью и полнотой и не требует особенных вычислительных затрат. Минусы подхода — метод никак не учитывает временную информацию видео.
Смена сцен
В работе A suffix array approach to video copy detection in video sharing socialnetworks введена подпись на основе определения границ сцен (съёмок).
Существует три различных понятия. Кадр или фотографический кадр — статическая картинка. Сцена или монтажный кадр — множество кадров связанных единством места и времени. Съемка или кинематографический кадр, множество кадров связанных единством съемки. Сцена может включать несколько съемок. В литературе съемку часто называют «сценой». Далее мы будем рассматривать съемку, но называть ее будем так же, — «сценой».
Видео содержит больше информации, чем просто серия кадров. События в видео уникально определяют его временную структуру, которая может быть представлена набором ключевых кадров.
Под ключевыми кадрами в данном случае понимаются не I-кадр, а просто некоторый особый кадр видео. Под событиями понимается не смысловая составляющая сюжета видео, а только изменение содержимого кадров. Выделение ключевых кадров основано на поиске различий в гистограммах яркости. После извлечения ключевых кадров, вычисляется длина между текущим ключевым кадром и предыдущим. Все длины записываются как одномерная последовательность. Эта последовательность длин сцен — и есть подпись видео. Эксперименты показывают, что два несвязанных видеоклипа не имеют длинного набора последовательных ключевых кадров с теми же длинами сцен. В работе предложен эффективный способ сопоставления подписей видео. для этого используется суффиксный массив. Проблема сводится к поиску общих подстрок. Метод плохо работает если в видео много перемещений камеры или объектов и при плавных переходах между сценами. К минусам стоит отнести и невозможность работы в режиме реального времени, для сравнения необходимо иметь видео целиком.
В работе Алгоритм поиска дубликатов в базе видеопоследовательностей на основе сопоставления иерархии смен сцен предложен алгоритм сопоставлении дерева сцен (съёмок). На основе найденных смен сцен строят двоичное дерево. Поддеревья соответствуют фрагментам видео. Корневые вершины поддеревьев хранят величины и положение доминирующей смены сцен в текущем фрагменте. При сравнении, в одном дереве (более длинное видео) ищут вершины наиболее близкие по величине к корню второго дерева, и сопоставляют их координаты. Процедуру выполняют рекурсивно для оставшихся смен сцен. Плюсами метода являются устойчивость к большинству приемов создания искусственных дубликатов (т.к. используется только временная информация), малая сложность сравнения двух клипов и возможность создания иерархических индексов фильмов. Это позволяет отлавливать несовпадения, на начальных этапах проверки. Минусами подхода как и предыдущего является то, что не учитываются характеристики самих сцен. Для определения нечетких дубликатов требуется иметь видео-запрос полностью, что не всегда возможно.
Заключение
Для поиска НДВ применяют самые разнообразные методы. На данный момент наиболее перспективными кажутся ГХ-методы. Они позволяют без особых вычислительных затрат приближенно решить задачу. Однако, для уточнения могут потребоваться ЛХ-методы. Как показано в работе Large-scale near-duplicate Web video search: challenge and opportunity применение комбинированных подходов дает точность выше чем у каждого из методов по-отдельности.
Комбинация
Интерес представляют работы, в которых строится структурная модель видео. Видео можно рассматривать как последовательность фактов, развивающихся во времени. Причем, в разных видео могут быть различны как сами факты, так и их порядок. Свойства фактов образуют пространственную характеристику видео, а продолжительность и порядок фактов — временную. Самый простой способ выделить факты из видео — использовать точки смены сцен (съёмок). Важно учитывать, что время в двух различных видео может идти по-разному. Мы предлагаем использовать отношения длин сцен к длинам соседних сцен… Относительные длины сцен двух нечетких дубликатов редко будут совпадать. Это связано, в том числе, и с ошибками распознавания границ сцен. Для решения такой проблемы, можно применить алгоритмы выравнивания последовательностей. Но, так, мы сравним только порядок видео-фактов. Для сравнения самих фактов требуются внутренние характеристики сцен, например, характеристики начального и конечного кадров. Тут удобно удобно использовать визуальные слова, как прием из ЛХ-методов. Таким образом, мы получили дескриптор сцены.
Формально cцена как «съемка», кинематографический кадр — совокупность множества фотографических кадров внутри временной области, кадры, которой значительно отличается от кадров соседних областей. На картинке ниже — первые кадры сцен некоторого видео.
Если исходное видео сжать разными кодеками, мы получим нечеткие дубликаты этого видео. Выделяя сцены в каждом видео, увидим, что точки перемены сцен для этих двух файлов не совпадают.
Для решения этой проблемы предлагается использовать относительные длины сцен. Относительная длина сцены вычисляется как вектор отношений абсолютной длины сцены к абсолютным длинам остальных сцен видео. В практических задачах удобнее вычислять отношения длин, для трех предыдущих сцен, а не для всех. Это удобно и в случае, если все видео целиком нам недоступно и мы имеем дело с видео-потоком, например в задачах реального времени.
Относительные длины сцен двух нечетких дубликатов редко будут совпадать. Более того, многие сцены могут просто не распознаваться. Это связано, в том числе, с ошибками распознавания границ сцен.
Если относительная длина сцены одного видео отличается от длины сцены другого видео не более чем в два раза, и все предыдущие сцены выравнены, то, текущая пара сцен выражает одно и то же явление, при условии, что оба видео являются нечеткими дубликатами друг друга (гипотеза Гейла-Черча). Подобный подход применяется в математической лингвистике для выравнивания параллельных корпусов текстов на разных языках. Чем менее отличаются относительные длины сцен, тем более вероятно, что сцены похожи. Если длины отличаются больше чем в два раза, то длину меньшей сцены складывают с длиной следующей сцены этого же видео, и рассматривают объединенную сцену как одну. В случае совпадения относительных длин сцен видео применяется сравнение внутренних свойств сцены.
Таким образом, формально можно описать предложенный дескриптор сцены. Он состоит из вектора отношений длины сцены к длинам других сцен и характеристик начального и конечного кадров. Его удобно его сразу хранить, с объединениями соседних сцен (трех предыдущих) учитывая гипотезу Гейла-Черча.
А дальше …
Благодаря такому дескриптору и различным техническим ухищрениям (семантическое хеширование) был построен достаточно очевидный алгоритм.
Но практическая реализация его пока в зачаточном состоянии. Какие-то результаты все же были получены *, но по некоторым внешним причинам работа была временно остановлена.
Буду очень рад любым замечаниям и дополнениям.
UPD 1:
Некоторое дополнение по материалу можно найти в презентации: Элементы поиска нечетких дубликатов видео
Еще по теме:
Благодарности
Спасибо goodok за исправление грамматических ошибок.
