Comments 84
Lo-Dash, кстати, лучше.
Исходный код lodash намного больше и запутаннее, чем underscore. Поэтому, если пользоваться Lo-Dash из коробки и не заглядывать в исходник, то да — он лучше. А если учить js, изучая исходный ход, то определенно лучше Underscore.
В исходный код lodash не заглядывал, возможно, вы правы. Но минифицированные исходники lodash, больше всего лишь на 3К, при этом содержат множество действительно полезных вещей, отсутствующих в underscore. Я, к примеру, весьма часто пользуюсь каррированием фукнций и слиянем объектов (aka deep extend). Кроме того, бенчмарки показывают в разы более быстрое (по сравнению с underscore) выполнение таких классических функций как each, map и т.д. Вообще, кому интересно мнение из первых рук, могут почитать ответ создателя lodash на вопрос об отличиях этих двух библиотек и причинах их параллельного существования.
как-то раз сделал тесты, и выиграли transducer'ы jsperf.com/like-a-linq-libraries-performance/4
вы хоть slug читали? ясное дело что вот такой код будет быстрее… но как я из него композицию сделаю?
Кто такой slug?
Не просто быстрее, а на порядок быстрее.
В этом тесте только в 4 случаях из 12 используется композиция. В остальных, и в приведённом мной тоже, никакой композиции нет.
Не просто быстрее, а на порядок быстрее.
В этом тесте только в 4 случаях из 12 используется композиция. В остальных, и в приведённом мной тоже, никакой композиции нет.
Вот тут об этом en.wikipedia.org/wiki/Semantic_URL#Slug
jsperf.com/like-a-linq-libraries-performance/11
А вот тут lodash выигрывает
А вот тут lodash выигрывает
Где вы тут такое увидели?
Сорри, забыл приатачить картинку hsto.org/files/2d2/c9f/ee8/2d2c9fee89874f1e969e22158e358508.png
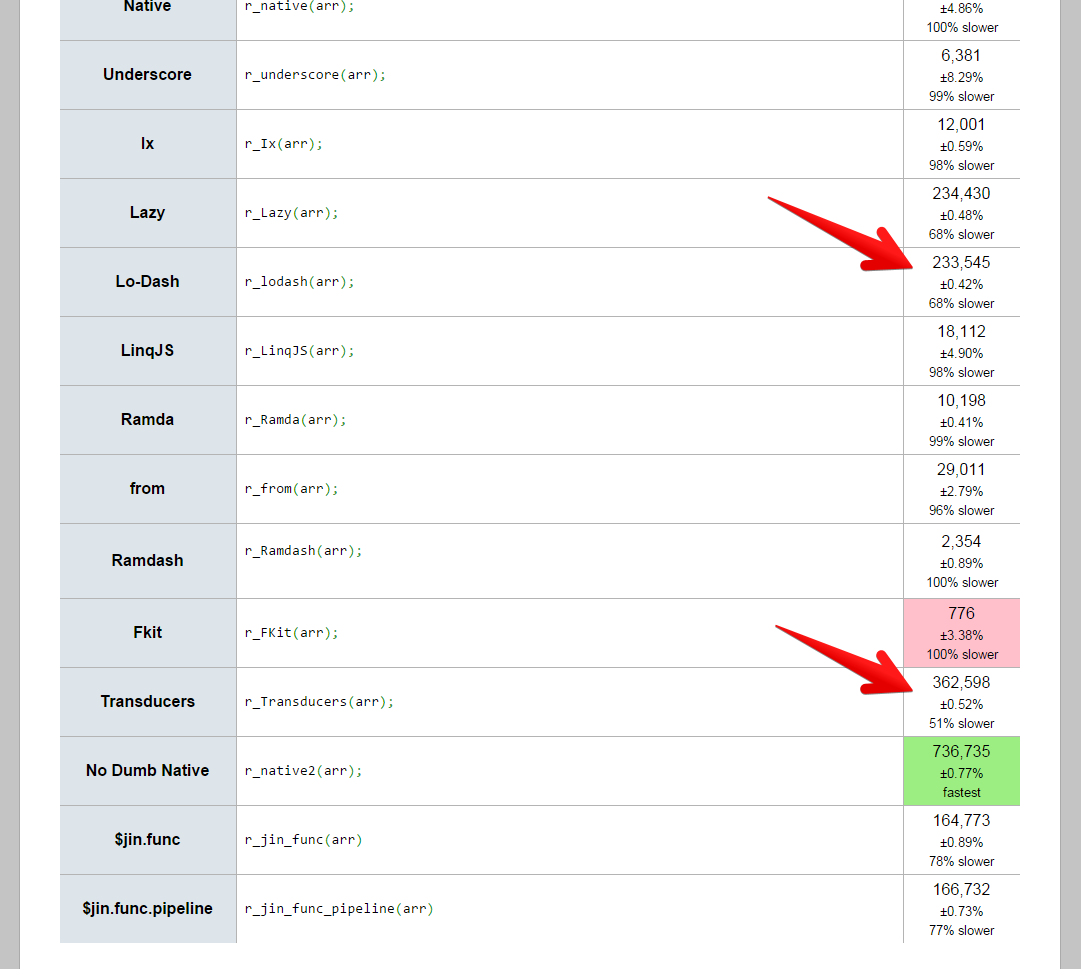{kind=link}
Не понимаю, как данный тест относится к производительности Undescore / LoDash. Сделать на 10000 элементов
map и filter и после взять slice 100 — это тест ленивых вычислений, в них трансдьюсеры, конечно хороши. Но без ленивых вычислений никто в здравом уме подобного не допустит.Если интересно, вот еще компоновка трандьюсеров в RxJs и Bacon. Был вдохновлен тем, что сделал Pozadi в своей библиотеке Kefir. В RxJs официально уже добавлена поддержка трандьюсеров. codepen.io/xgrommx/pen/iqkya
Извиняюсь, не та версия. Вот правильная: jsperf.com/like-a-linq-libraries-performance/12
Я там фильтр поменял, чтобы реже срабатывал. Lazy вырвался вперёд.
Я там фильтр поменял, чтобы реже срабатывал. Lazy вырвался вперёд.
Какое совпадение, делал выводы о большей запутанности как раз на основе функции-карри (побитовые маски, более длинные конструкции, типа «дедка за репку, бабка за дедку, внучка за бабку, венуть функцию, где прыгнуть в начало и — дедка за репку...», одновременно там же создаются, в зависимости от битов, реализации партиалов), а, насчет разницы размеров, то 1441 vs 10190 строк кода. В общем, по такому коду новичек сможет комфортно учить js, если предварительно победит в парочке международных олимпиад на C++.
Какое совпадение, делал выводы о большей запутанности как раз на основе функции-карри (побитовые маски, более длинные конструкции, типа «дедка за репку, бабка за дедку, внучка за бабку, венуть функцию, где прыгнуть в начало и — дедка за репку...»
Так нет же в underscore каррирования, как можно здесь что-то сравнивать? К тому же, вполне возможно, что хитрая и непонятная на первый взгляд конструкция обеспечивает стабильность и быстродействие, факторы несколько более важные, нежели пригодность для обучения. Вообще, изучать JS по исходникам — развлечение не для каждого, и мне кажется не совсем корректным сравнивать такие фундаментальные библиотеки на этом основании.
Сравнивал, как бы корректно выразиться, «стиль» кода, какой сложности конструкций придерживаются авторы, а карри взял, потому что было интересно, как этот зверь реализован на чистом js. В Underscore бы его не взяли по философским причинам, они не добавят отдельную функцию, если ее поведение можно без проблем организовать другой (например партиалом). У них такие принципы: минимальный набор функций, красивый и простой код, больше свободы, поэтому для самостоятельного изучения js это очень хороший вариант. Так сказать, спасибо добрым дядям, что вместили столько полезных знаний в такой относительно небольшой объем достаточно понятного исходного кода.
Пост сделан для новичков — самоучек, с точки зрения новичка — самоучки. Для таких фактор пригодности к самостоятельному изучению — самый важный. С помощью исходников underscore и backbone, новичок сможет самостоятельно найти ответ на популярный вопрос: «Что я должен знать и уметь, чтобы нормально программировать на javascript?».
В плане простоты, краткости и изящности исходного кода, underscore — это просто шедевр!
А что делает в тэгах статьи backbone?
Потому что, если захотеть нормально разобраться в исходном коде backbone, то желательно сначала понять исходный код underscore. И если есть желание поучиться пользоваться underscore просто как библиотекой, то, в первую очередь, стоит заглянуть в исходник backbone.
В общем взаимосвязи у этих библиотек достаточно, чтобы, рассматривая одну, упоминать другую.
В общем взаимосвязи у этих библиотек достаточно, чтобы, рассматривая одну, упоминать другую.
Во-первых, в тексте бэкбон никак не упоминается и такой вывод не делается. Во-вторых, долго и активно используя underscore/lodash безо всяких проблем и недопониманий, к бэкбону никакого касательства не имел и не имею, так что этот тезис весьма спорный. С тем же успехом можно поставить тэг haskell ввиду несомненной связи андерскора с традициями функционального программирования.
[del]
А есть такой разбор по последней (2+) версии jquery?
Пришлось лезть в закрома закладок))) james.padolsey.com/jquery/#v=2.0.3
Спасибо за статью. Интересно было быстро ознакомиться с работой такой библиотеки. А с Lo-Dash-ем такое провернуть не планируете? Никогда не пользовался Underscore-ом, но поработав с Lo-Dash-ем полгода я в него по уши влюблён :)
Это библеотека функций, тогда по вашему jQuery тоже «божественный» объект.
Именно так. Все 3 обсуждаемые тут библиотеки являются примерами плохого дизайна.
1. Совершенно разнородные функции находятся в одном неймспейсе, превращая его в помойку.
2. Совершенно различные действия выполняются одной и той же функцией, повышая вероятность ошибок.
3. Любая функция может быть вызвана на любом наборе данных, приводя к неопределённому поведению, вместо всплытия исключения.
4. Использование одной функции неизбежно приводит к необходимости грузить их все.
1. Совершенно разнородные функции находятся в одном неймспейсе, превращая его в помойку.
2. Совершенно различные действия выполняются одной и той же функцией, повышая вероятность ошибок.
3. Любая функция может быть вызвана на любом наборе данных, приводя к неопределённому поведению, вместо всплытия исключения.
4. Использование одной функции неизбежно приводит к необходимости грузить их все.
А что тогда пример хорошего дизайна? Приведите пожалуйста аналог какой-нибудь из вышеперечисленных библиотек, у которого хороший, по вашему мнению, дизайн.
К сожалению, хороший дизайн сейчас не в тренде, так что в пример могу привести разве что свои наработки. Например, dom wrapper, но там до сих пор ни документации, ни тестов, так что рекомендовать использовать именно его не буду.
А следование SoC и использование CommonJS-модулей, ответственных за отдельные задачи — чем вам не пример хорошего дизайна?
Кстати если конкретно об underscore говорить, то давно уже лучше использовать полифиллы для массивов/объектов на стандартные методы (map, forEach, ...), чем библиотеку «всего».
Кстати если конкретно об underscore говорить, то давно уже лучше использовать полифиллы для массивов/объектов на стандартные методы (map, forEach, ...), чем библиотеку «всего».
1. Справедливо, хотя плюсы у такого подхода тоже есть.
2. Пример? По-моему, нет там такого.
3. Это проблема типизации и вообще JS, а не библиотеки. Т. к. все что не массив, есть словарь. Безопаснее функции над коллекциями (словарями) вы никак не напишите.
4. Underscore это последнее, из-за чего будет тормозить ваше приложение.
2. Пример? По-моему, нет там такого.
3. Это проблема типизации и вообще JS, а не библиотеки. Т. к. все что не массив, есть словарь. Безопаснее функции над коллекциями (словарями) вы никак не напишите.
4. Underscore это последнее, из-за чего будет тормозить ваше приложение.
1. Какие же? Экономия ресурса клавиатуры?
2. Первая же функция: api.jquery.com/add/
3. Напишу:
4. Речь не о тормозах, а об увеличении объёмов. Впрочем, чем больше объём, тем медленнее идёт сборка. Конкретно underscore — да, довольно компактен, в отличие от куда более популярного, но и более функционального jQuery.
2. Первая же функция: api.jquery.com/add/
$( '<div/>' ).add( 'foo' ) // Молчим, хотя элемент не найден
$( '<div/>' ).add( 'foo&bar' ) // Syntax error, unrecognized expression: foo&bar, хотя html валиден
3. Напишу:
$.dom( document.body ).html( '123' ) // Всё ОК
$.list([ 1, 2, 3 ]).html( '123' ) // TypeError: undefined is not a function
4. Речь не о тормозах, а об увеличении объёмов. Впрочем, чем больше объём, тем медленнее идёт сборка. Конкретно underscore — да, довольно компактен, в отличие от куда более популярного, но и более функционального jQuery.
1. utils.string.split(str) и utils.collect.map(array) это менее читабельно, чем _.split(str) и _.map(array), хоть и не по фен-шую.
2. Согласен, это косяк jQuery. Но я имел ввиду underscore.
3. Ну дык TypeError же. Где тут неопределенное поведение?
2. Согласен, это косяк jQuery. Но я имел ввиду underscore.
3. Ну дык TypeError же. Где тут неопределенное поведение?
1. utils — тот же god object, тут лучше так: $.str( str ).split( delimiter ) и $.list( array ).map( mapper )
2. А, ну у него всё хорошо, да.
3. Вот именно, что нигде :-)
2. А, ну у него всё хорошо, да.
3. Вот именно, что нигде :-)
Я думаю, термин «божественный объект» не может относится к библиотекам. Ведь библиотека НЕ завязана на ваш код.
Я думаю, что термин «божественный объект» может относится к тем объектом, которые делаю многое в вашем коде и ещё хранят состояние многих других объектов ВАШЕГО же кода.
Библиотеку можно рассматривать как расширение языка. Вы же не говорите, что сам язык javascript — это «божественный объект»?
Я думаю, что термин «божественный объект» может относится к тем объектом, которые делаю многое в вашем коде и ещё хранят состояние многих других объектов ВАШЕГО же кода.
Библиотеку можно рассматривать как расширение языка. Вы же не говорите, что сам язык javascript — это «божественный объект»?
Что за странное деление на «ВАШЕ» и «НЕ ВАШЕ»? В моём коде нет «божественных объектов», в коде jQuery-like библиотек — есть. Да даже если бы они засовывали всё это не в объект, а в класс или функцию — суть паттерна от этого бы не поменялась. Их обёртка умеет «слишком много»: и на дуде играть и вагоны разгружать. Каждый jQuery/Underscore/LoDash/тысячи_их инстанс — это «мини божок», «мастер на все руки», который маскирует и без того не шибко явную типизацию: можно передать ему что угодно, вызвать какой угодно метод и словить потом неопределённое поведение.
Говорю, глобальный скоуп в JS — тоже божественный объект, который и на NaN умеет проверять и url экранировать.
Говорю, глобальный скоуп в JS — тоже божественный объект, который и на NaN умеет проверять и url экранировать.
А можно по подробнее?
1. utils — тот же god object, тут лучше так: $.str( str ).split( delimiter ) и $.list( array ).map( mapper )
$.str( str ) и $.list( array ) — это своеобразный вызов конструкторов или создание замыкания?
1. utils — тот же god object, тут лучше так: $.str( str ).split( delimiter ) и $.list( array ).map( mapper )
$.str( str ) и $.list( array ) — это своеобразный вызов конструкторов или создание замыкания?
Это обоачивание в декоратор с защитой от двойного оборачивания
А в чем профит? Зачем оборачивать? Почему просто в метод не передать?
Например для цепочек:
$.set([ 1 , 2 , 3 ]).add([ 3 , 4 , 5 ]).drop([ 1 ]).toArray() // [ 2 , 3 , 4 , 5 ]
[2,3,4,5]… м?
Что-то не так?
просто можно было бы сразу написать компьютеру пару скобок и несколько чисел.
Если бы я приводил пример JSON, то именно так бы и написал. Тут же демонстрируется работа цепочек вызовов.
а компьютеру она зачем?
Языки программирования компьютеру вообще по барабану. Он байтики туда-сюда и всё :-)
про компьютера и байтики
Если речь о байтиках — то они для компьютера в Вашем примере как перчики Халапеньо. Можно их сыпать в дисковод или даже в винтиляторы, но если попробовать то процессор все равно нагреется! Даже если сделать цепочку миллионов вызовов то жадный процессоро-стек скушает все преимущества чуда инженерной мысли и на выходе останется только написать пару скобок и несколько чисел.
Если речь о байтиках — то они для компьютера в Вашем примере как перчики Халапеньо. Можно их сыпать в дисковод или даже в винтиляторы, но если попробовать то процессор все равно нагреется! Даже если сделать цепочку миллионов вызовов то жадный процессоро-стек скушает все преимущества чуда инженерной мысли и на выходе останется только написать пару скобок и несколько чисел.
Underscore, как и jQuery — это конъюнктурные библиотеки. Когда они возникли, не существовало развитого JS, как и модульности; надежы на развитие языка не было. Сейчас 60% их функционала присутствует в нативных средствах и покрываются полифиллами, для других 40% есть отдельные, качественные решения.
Не нужно грузить jQuery если вам нужен ajax (fetch polyfill), css или селекторы.
Не нужно грузить jQuery если вам нужен ajax (fetch polyfill), css или селекторы.
Кстати, по поводу
fetch — его поддержка хоть где-нибудь планируется? :) И полифил IE10+. Хотя, как его в рассылке увидел, пришел в восторг :)<joke mode="Petrosyan">А зачем вам полифиллить утилиту загрузки хрома под виндой?</joke>
Из-за приличного процента пользователей, часто корпоративных? Моя бы воля — к черту бы послал, требования заказчиков. Больше интересует поддержка в нормальных браузерах искаропки, не в курсе?
Не знаю. Можно прогнать test.js по разным браузерам, если сильно нужно. Попробовать XHR-polyfill. Как правило, помогает. Ничего смертельного для IE они в коде не использовали, навскидку.
В том и дело, «если сильно нужно». Дабы подключить «простой XHR» — подключаем полифил XHR, полифил
Undescore.js появился уже после ES5 и, во многом, вытянул за счет методов, присутствующих в этом же ES5. Вместо полифила ES5, люди использовали его. Как бы и с
Promise и полифил самого fetch (ничего не забыл?). Хотя да, базовые возможности сполифилить — дело нескольких минут. И в стабильных, и в ночных сборках, и в обсуждениях разработки браузеров — глухо. Замечательная штука, но пока рано. Будем надеяться, скоро поспеет.Undescore.js появился уже после ES5 и, во многом, вытянул за счет методов, присутствующих в этом же ES5. Вместо полифила ES5, люди использовали его. Как бы и с
fetch и jQuery такого же не случилось.Не спорю, underscore — хороший тулкит, целый ящик с инструментами для разработки приложений. Подключил и пользуешься. Тут все — и типы, и списки, и объекты, и горка кокаина.
Возможно, для разработки больших приложений это и сэкономит несколько минут на упрощении логики и читабельности.
Но ставить весь код на такую жирную зависимость страшно. А что если не все знают underscore? А что если я часть кода захочу реиспользовать — таскать этого толстяка везде? А что если underscore сломается в IE9 или мне потребуется несколько кастомное его поведение? К примеру, `.each`, как выяснилось, не может прерваться в середине цикла (обсуждение на stackoverflow) — таких затруднений возникает множество.
В нативном JS таких беспокойств нет — лишь беспокойства о наличии полифиллов, которые весьма и весьма низки, благодаря сервису полифиллов.
Возможно, для разработки больших приложений это и сэкономит несколько минут на упрощении логики и читабельности.
Но ставить весь код на такую жирную зависимость страшно. А что если не все знают underscore? А что если я часть кода захочу реиспользовать — таскать этого толстяка везде? А что если underscore сломается в IE9 или мне потребуется несколько кастомное его поведение? К примеру, `.each`, как выяснилось, не может прерваться в середине цикла (обсуждение на stackoverflow) — таких затруднений возникает множество.
В нативном JS таких беспокойств нет — лишь беспокойства о наличии полифиллов, которые весьма и весьма низки, благодаря сервису полифиллов.
А мне-то что доказывать? :) С тем, что лучше использовать стандартизованный функционал, я полностью согласен. Я предпочитаю, по возможности, полифилы. Хотя местами вы перегибаете.
«Но ставить весь код на такую жирную зависимость страшно»? 5кб это просто чертовски много, если сравнивать со многими десятками-сотнями jQuery / Angular.
«А что если underscore сломается в IE9»? В IE 9 он не сломается, спасибо огромному комьнити — всё, что могло сломаться, давно пофиксили.
«мне потребуется несколько кастомное его поведение»? А если «потребуется» кастомное поведение стандартизованного функционала?
"
«Но ставить весь код на такую жирную зависимость страшно»? 5кб это просто чертовски много, если сравнивать со многими десятками-сотнями jQuery / Angular.
«А что если underscore сломается в IE9»? В IE 9 он не сломается, спасибо огромному комьнити — всё, что могло сломаться, давно пофиксили.
«мне потребуется несколько кастомное его поведение»? А если «потребуется» кастомное поведение стандартизованного функционала?
"
.each не может прерваться в середине"? Так это стандартное поведение и Array#forEach. Не ясно, что вы этим хотели сказать.5Кб сжатые (15Кб минифицированные) для некоторых модулей это очень много. Некоторые компоненты суммарно весят в разы меньше. Представьте, если component/events был бы на underscore? А ведь предпосылки есть.
О forEach я хотел сказать очевидное — библиотеки нужны, если они предоставляют что-то большее, чем существующие инструменты. В случае с underscore — API в пределе отражает 1:1 стандартное поведение. А зачем мне 1:1 стандартное поведение, если это задача полифиллов? Казалось бы, underscore может предложить что-то больше, как, к примеру, `$.each`, который, не гнушается вызывать `break` по `return false`. Но нет. Если я попробую написать реквест или сделать PR на эту тему — мне откажут, так как API устоялось и меняться не будет, в т. ч. в силу большого комьюнити. В итоге мне надо писать свой велосипед.
Это второе затруднение «божественных» библиотек — большое комьюнити блокирует развитие и замедляет изменения и принятие PR. es6-collections, к примеру, был пофикшен и переписан польностью из-за нескольких реквестов всего за пару дней. С underscore вообще какие-либо изменения едва возможны.
О forEach я хотел сказать очевидное — библиотеки нужны, если они предоставляют что-то большее, чем существующие инструменты. В случае с underscore — API в пределе отражает 1:1 стандартное поведение. А зачем мне 1:1 стандартное поведение, если это задача полифиллов? Казалось бы, underscore может предложить что-то больше, как, к примеру, `$.each`, который, не гнушается вызывать `break` по `return false`. Но нет. Если я попробую написать реквест или сделать PR на эту тему — мне откажут, так как API устоялось и меняться не будет, в т. ч. в силу большого комьюнити. В итоге мне надо писать свой велосипед.
Это второе затруднение «божественных» библиотек — большое комьюнити блокирует развитие и замедляет изменения и принятие PR. es6-collections, к примеру, был пофикшен и переписан польностью из-за нескольких реквестов всего за пару дней. С underscore вообще какие-либо изменения едва возможны.
По последнему, скорее, наоборот. Большое комьюнити, конечно, сдерживает развитие библиотеки, но API полифилов (к которым относится и es6-collections) ограничено спецификацией, от которой никуда не уйти, а underscore и подобных — только обратной совместимостью, которую иногда ломают — например, в последней версии перестали игнорировать дырки массива.
А вот «стандартная библиотека как зависимость другой библиотеки» — тема довольно занятная, но если мы начнём её здесь обсуждать — это затянется всерьёз и на долго. В любом случае, component/events не использует ничего выше es3 — зачем здесь undescore? Сравнивать 15кб undescore корректно хотя бы с 18кб es5-shim — они пересекаются хотя бы частично.
А вот «стандартная библиотека как зависимость другой библиотеки» — тема довольно занятная, но если мы начнём её здесь обсуждать — это затянется всерьёз и на долго. В любом случае, component/events не использует ничего выше es3 — зачем здесь undescore? Сравнивать 15кб undescore корректно хотя бы с 18кб es5-shim — они пересекаются хотя бы частично.
es5-shim это из серии underscore — полифилл всего, но уже концептуально лучше. Самым рациональным решением выглядит использование сервиса полифиллов и/или autopolyfiller.
А про изменения — наверное, это дело вкуса. Мне комфортнее либо рассчитывать на железобетонность стандартов, либо иметь возможность влиять на инструмент. В случае же, когда на инструмент влияет кто-то посередине, при этом не дает другим так просто этот инструмент настраивать под свои нужды — я предпочитаю использовать нативные средства напрямую. Потребность в котроле, видимо. Но тут я могу находиться в иллюзии насчет неизменности и неконтролруемости стандартов (возможности моего участия в этом).
А про изменения — наверное, это дело вкуса. Мне комфортнее либо рассчитывать на железобетонность стандартов, либо иметь возможность влиять на инструмент. В случае же, когда на инструмент влияет кто-то посередине, при этом не дает другим так просто этот инструмент настраивать под свои нужды — я предпочитаю использовать нативные средства напрямую. Потребность в котроле, видимо. Но тут я могу находиться в иллюзии насчет неизменности и неконтролруемости стандартов (возможности моего участия в этом).
У меня свой подход к стандартной библиотеке, универсальной как для клиента, так и до сервера. Полифилы ES5, ES6, в т.ч.: коллекции,
Promise, Symbol, итераторы; исправление таймеров, setImmediate, статические версии методов массива, заглушки консоли. Не всё необходимое стандартизовано, так что кроме этого есть словари и методы работы с ними, расширенные возможности частичного применения, простое форматирование даты и еще немного сахара. Можно собрать как с расширением build-it объектов, так и в своём пространстве имён. Само собой, кастомные сборки. Максимальная сборка — около 21кб (без учета gzip). Надо бы таки допилить статью — документацию — почти готова, но как-то не до того.Ой, а распилите jQuery. Очень нужно. А еще лучше формат MP3, XVID или MPG по байтам? Я понимаю, это не из той оперы, но просто люблю когда все распиливают. Еще распилите пожалуйста метод Хартри-Фока для решения уравнения Шредингера для атома гелия вручную :). Я не слишком наглый?
robflaherty.github.io/jquery-annotated-source/ первое есть)
О! Спасиб вам огромное. Ловите плюс. MP3 я тоже «более-менее» — нашел, там правда не все, и на Haskell, но хоть что-то. А XVID, MPG и Шредингер — это прям мечта детства :). Но видимо недостижимая.
Без холиварчика.
Освоил underscore, потом начал использовать coffeescript — и внезапно обнаружил, что теперь мне не нужен underscore. Не вникал в причины — просто констатирую факт.
Освоил underscore, потом начал использовать coffeescript — и внезапно обнаружил, что теперь мне не нужен underscore. Не вникал в причины — просто констатирую факт.
Очень жаль что Underscore слшиком монолитен для использования своих частей по-отдельности. Под частями я имею ввиду те, коих всего две: 1. реализацию на js-е неподдерживаемых native-функций и 2. библиотечные функции непосредственно сокращающие использующий код.
Смысл статьи ускользает от меня
А в чём тайный смысл использования ">>>" а не ">>"? Ведь ">>" и с отрицательными работает.
Очевидно же — uint32 vs int32, у первых максимальное значение 2**32-1, у вторых — 2**31-1. Ну и длина отрицательной не бывает.
Без контекста здесь было сложно судить. Например если это координаты то числа могут быть и отрицательными.
Но в данном случае судя по исходникам это длинна массива. А .length похоже действительно не может быть больше 2^32-1.
Хотя имхо массив даже 2ГБ это перебор для js, да и ">>" быстрее чем ">>>". Можно было и проверку на длину воткнуть если так критична производительность в этом месте.
Но в данном случае судя по исходникам это длинна массива. А .length похоже действительно не может быть больше 2^32-1.
Хотя имхо массив даже 2ГБ это перебор для js, да и ">>" быстрее чем ">>>". Можно было и проверку на длину воткнуть если так критична производительность в этом месте.
.length ограничено 2**53-1, т.е. MAX_SAFE_INTEGER, но всем наплевать. >> быстрее чем >>>? Покажите, я разницы уловить не могу.Ну «This is not the official ECMAScript Language Specification.». В 5.1 же сказано «Every Array object has a length property whose value is always a nonnegative integer less than 2^32.» (15.4 Array Objects). И в любом случае дефакто сейчас это 2^32-1.
Действительно по сравнению с делением разница в пределах погрешности. У меня изза динамического понижения частоты процессора первый тест выполнялся чуть медленнее.
Действительно по сравнению с делением разница в пределах погрешности. У меня изза динамического понижения частоты процессора первый тест выполнялся чуть медленнее.
Да и в проекте 6 тоже 2^32-1 судя по:
8. Else,
Let intLen be ToUint32(len).
If intLen ≠ len, then throw a RangeError exception.
9. Let putStatus be Put(array, "length", intLen, true). Ну вот сами себе всё и объяснили.
Массивами свойство
Что касается стандарта языка, то де-факто сейчас это как раз черновики ES6, возможности которого постепенно реализуются даже в IE. Большая часть спецификации заморожена и изменению не подлежит. ES5 разве что де-юре.
Массивами свойство
.length и протокол обхода array-like объектов не ограничены и современные методы работы с этим протоколом используют данную абстрактную операцию.Что касается стандарта языка, то де-факто сейчас это как раз черновики ES6, возможности которого постепенно реализуются даже в IE. Большая часть спецификации заморожена и изменению не подлежит. ES5 разве что де-юре.
Sign up to leave a comment.
Разбор Underscore