В последнее время часто вижу статьи о том, почему вы должны использовать nosql или о том, что вы никогда не должны им пользоваться и уповать только на реляционные хранилища. Однако, на мой взгляд, эти прекрасные инструменты могут отлично уживаться вместе, позволяя использовать их общие достоинства и избегая их недостатков.

Около года назад нашей команде досталась прекрасная возможность поработать над сайтом одного нового английского телеканала. Как и большинство подобных проектов, он ориентируется на развлекательные и информационные программы, новости, а также взаимодействует с посетителями с помощью социальных сетей.
У заказчика было два критичных требования, которыми мы и руководствовались при выборе технологий, используемых для реализации проекта:
Чтобы гарантировать целостность данных, мы решили сохранять их в реляционном виде в MS SQL, а для обеспечения скорости работы пользовательской части сайта мы взяли mongodb. Для каждого типа страниц была создана своя собственная, денормализованная коллекция документов. Таким образом, данные сперва сохраняются в MS SQL, а затем уже оттуда публикуются во все необходимые коллекции mongo DB.
И зачем же использовать монгу, если можно обойтись одним SQL, спросите вы? Для обоснования выбора рассмотрим несколько примеров.
Начнем с примерной схемы сущностей какого-либо телешоу. У нас есть таблица программ, сезонов, серий и дат трансляции эпизодов:

Страница программы содержит описание программы, список сезонов программы, список эпизодов с кратким описанием эпизода, датой выхода эпизода, ссылкой на его страницу. У нас есть 3 варианта получения необходимых данных из реляционной базы:
В целом, все выглядит довольно неплохо, однако при использовании денормализованной коллекции телепрограмм в монге не нужно ничего придумывать — достаточно сделать один запрос, вытаскивающий данные по идентификатору — и все.
На сайте есть несколько страниц отображающих свежую информацию — новости, программы, посты из инстаграма и твиттера, погоду, рекламу, сведения о перебоях в работе метрополитена и т.д.
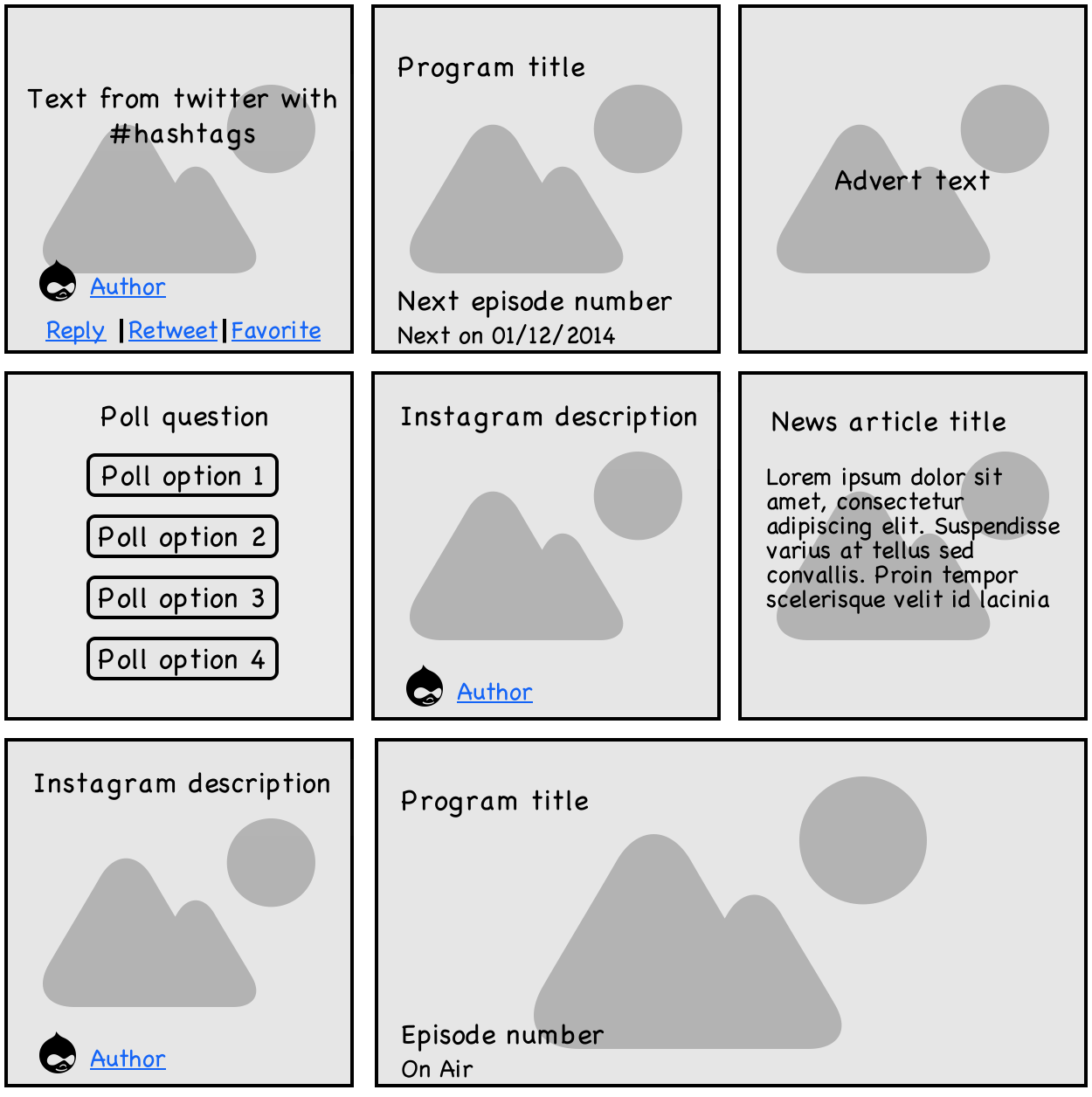
Эти данные, очень разрозненные по структуре, имеют общую природу и отображаются на одних и тех же страницах — на главной странице отображается самая свежая информация, на странице какого-либо региона показываются только связанные с ним события, на странице новостей отображаются только статьи. В SQL каждый тип тайла хранится в отдельной таблице, так как структура их может серьезно отличаться. Такая выборка из реляционной базы превращается в маленький локальный ад — количество запросов к базе растет с каждым добавленным типом тайлов, и это не учитывая сложность написания такой выборки непосредственно в коде. Чтобы как-то облегчить жизнь можно было бы использовать таблицу и метаданные, так упрощается фильтрация данных, но добавляется необходимость склейки их в объект на стороне приложения. И для этой ситуации какое-либо nosql хранилище вроде монги становится идеальным решением проблемы. В ранее появлявшихся статьях о монге на Хабре любое упоминание об отсутствии схемы вызывало вопросы «как же так? Схема есть всегда». Вопросы этого типа совершенно разумны, но немного не о том. Отсутствие схемы в данном контексте — это возможность сохранять данные с разной схемой, но одной природой в рамках одной коллекции. По ним можно строить индексы и фильтровать данные, а также легко десереализовать их в объект с правильным и нужным типа, с которым легко работать в приложении.
Использование sql и nosql в связке выглядит очень привлекательным и удобным. Однако, как мы знаем, за удобство необходимо чем-то платить. В нашем случае — это необходимость написания функционала публикации данных из sql в mongodb. На наш взгляд, это приемлемая цена.
Я старался не привязываться к языку, на котором написано приложение и к sql и nosql инструментам. Вместо монги можно подставить любое другое нереляционное хранилище.
В качестве предисловия
Около года назад нашей команде досталась прекрасная возможность поработать над сайтом одного нового английского телеканала. Как и большинство подобных проектов, он ориентируется на развлекательные и информационные программы, новости, а также взаимодействует с посетителями с помощью социальных сетей.
У заказчика было два критичных требования, которыми мы и руководствовались при выборе технологий, используемых для реализации проекта:
- Очень важно, чтобы данные были целостными;
- Сайт должен работать с достаточно большим количеством одновременных пользователей.
Чтобы гарантировать целостность данных, мы решили сохранять их в реляционном виде в MS SQL, а для обеспечения скорости работы пользовательской части сайта мы взяли mongodb. Для каждого типа страниц была создана своя собственная, денормализованная коллекция документов. Таким образом, данные сперва сохраняются в MS SQL, а затем уже оттуда публикуются во все необходимые коллекции mongo DB.
И зачем же использовать монгу, если можно обойтись одним SQL, спросите вы? Для обоснования выбора рассмотрим несколько примеров.
Пример первый
Начнем с примерной схемы сущностей какого-либо телешоу. У нас есть таблица программ, сезонов, серий и дат трансляции эпизодов:
Страница программы содержит описание программы, список сезонов программы, список эпизодов с кратким описанием эпизода, датой выхода эпизода, ссылкой на его страницу. У нас есть 3 варианта получения необходимых данных из реляционной базы:
- Один большой запрос с джойнами. Хорошо — один запрос на страницу. Плохо – большое количество дублированных данных и как серьезное повышение нагрузки на сервер БД;
- Четыре запроса из ОРМ, по одному на каждую таблицу. Хорошо — ни в одном запросе не извлекается и не возвращается никакая лишняя информация. Плохо — собственно четыре запроса, для каждого из которых отрабатывает unit of work, а значит четыре раза создается и удаляется контекст подключения к БД. Вариант вполне себе традиционный и даже неплохой, минусы решаются с помощью прикручивания кеша;
- Хранимая процедура, выполняющая четыре запроса и возвращающая четыре набора данных. Хорошо — никаких лишних данных, один запрос к БД из клиента. Плохо — достаточно сложно найти ОРМ для .net, в которой такая возможность реализована в каком-либо удобоваримом виде.
В целом, все выглядит довольно неплохо, однако при использовании денормализованной коллекции телепрограмм в монге не нужно ничего придумывать — достаточно сделать один запрос, вытаскивающий данные по идентификатору — и все.
Пример второй
На сайте есть несколько страниц отображающих свежую информацию — новости, программы, посты из инстаграма и твиттера, погоду, рекламу, сведения о перебоях в работе метрополитена и т.д.
Эти данные, очень разрозненные по структуре, имеют общую природу и отображаются на одних и тех же страницах — на главной странице отображается самая свежая информация, на странице какого-либо региона показываются только связанные с ним события, на странице новостей отображаются только статьи. В SQL каждый тип тайла хранится в отдельной таблице, так как структура их может серьезно отличаться. Такая выборка из реляционной базы превращается в маленький локальный ад — количество запросов к базе растет с каждым добавленным типом тайлов, и это не учитывая сложность написания такой выборки непосредственно в коде. Чтобы как-то облегчить жизнь можно было бы использовать таблицу и метаданные, так упрощается фильтрация данных, но добавляется необходимость склейки их в объект на стороне приложения. И для этой ситуации какое-либо nosql хранилище вроде монги становится идеальным решением проблемы. В ранее появлявшихся статьях о монге на Хабре любое упоминание об отсутствии схемы вызывало вопросы «как же так? Схема есть всегда». Вопросы этого типа совершенно разумны, но немного не о том. Отсутствие схемы в данном контексте — это возможность сохранять данные с разной схемой, но одной природой в рамках одной коллекции. По ним можно строить индексы и фильтровать данные, а также легко десереализовать их в объект с правильным и нужным типа, с которым легко работать в приложении.
Чем платить?
Использование sql и nosql в связке выглядит очень привлекательным и удобным. Однако, как мы знаем, за удобство необходимо чем-то платить. В нашем случае — это необходимость написания функционала публикации данных из sql в mongodb. На наш взгляд, это приемлемая цена.
Вместо заключения
Я старался не привязываться к языку, на котором написано приложение и к sql и nosql инструментам. Вместо монги можно подставить любое другое нереляционное хранилище.
