Опубликована статья Yoongu Kim & others. Flipping Bits in Memory Without Accessing Them: An Experimental Study of DRAM Disturbance Errors, описывающая способ изменения содержимого DRAM памяти, не требующий доступа по этому адресу. Фактически это означает нарушение изоляции памяти между процессами или виртуальными машинами. Из проверенных 129 модулей памяти, 110 оказались подвержены уязвимости, в том числе, все модули, выпущенные после 2012 года.
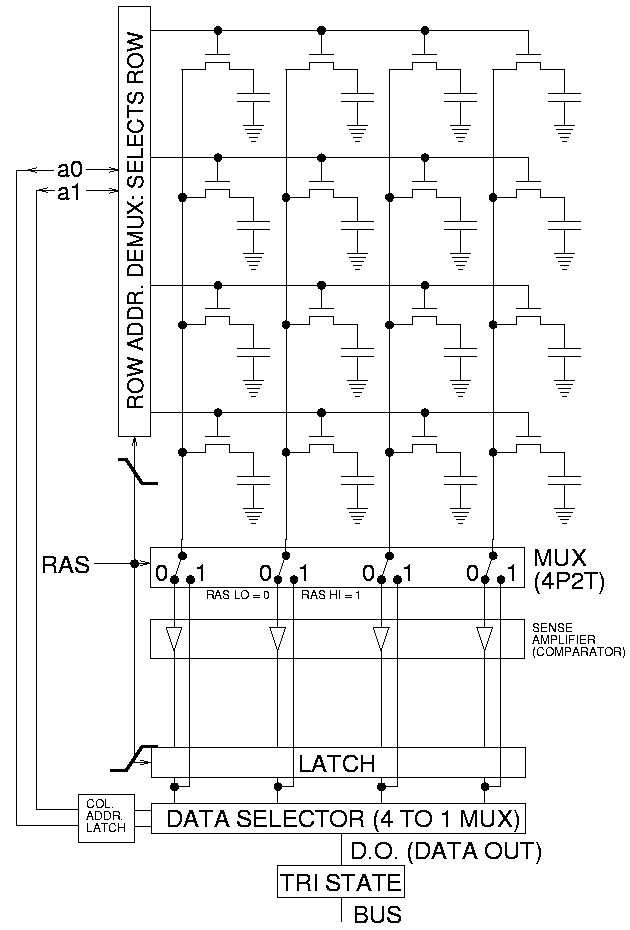
DRAM представляет собой двумерную решётку, в узлах которой находятся ячейки памяти, каждая из которых хранит один бит. Каждая ячейка состоит из транзистора, и конденсатора, который может быть заряжен или не заряжен, что соответствует значению бита 1 или 0. Конденсаторы со временем теряют заряд, так что необходимо периодически (раз в несколько десятков миллисекунд) перезаписывать информацию (регенерация). В современных чипах для улучшения производительности делают несколько независимых модулей («банков»), с отдельными выходными каскадами.
Для чтения информации, на одну из горизонтальных линий (wordline) подаётся напряжение, так что соответствующая линия транзисторов открывается. При этом с вертикальных линий (bitline) считываются заряды конденсаторов ячеек в данной строке. После этого wordline закрывается, что позволяет перейти к считыванию другой строки.
Оказалось, что если периодически включать и выключать wordline, наведённые токи приводят к увеличению утечки в соседних ячейках того же банка, и если сделать много переключений между циклами регенерации, этого может быть достаточно для переключения бита с 0 на 1 или наоборот.
Эффекта можно достичь с помощью кода, не требующего никаких специальных привилегий. Простейшая атака выглядит так:
Адреса X и Y должны быть в одном банке, но в разных строках DRAM. Сброс кэша нужен, чтобы гарантировать чтение из RAM на каждом цикле. Два адреса надо использовать, чтобы обеспечить включение/выключение wordline на каждом цикле. Этот код не вызывает уязвимость, поскольку логика DRAM оптимизирует включение wordline, и необходимых постоянных переключений не происходит:
Чтобы вызвать ошибку, необходимо сделать несколько сотен тысяч циклов за время между двумя регенерациями (обычно 64 мс), что вполне достижимо. Наличие ECC не сильно помогает, так как нередки ошибки одновременно в нескольких битах.
Организация DRAM
DRAM представляет собой двумерную решётку, в узлах которой находятся ячейки памяти, каждая из которых хранит один бит. Каждая ячейка состоит из транзистора, и конденсатора, который может быть заряжен или не заряжен, что соответствует значению бита 1 или 0. Конденсаторы со временем теряют заряд, так что необходимо периодически (раз в несколько десятков миллисекунд) перезаписывать информацию (регенерация). В современных чипах для улучшения производительности делают несколько независимых модулей («банков»), с отдельными выходными каскадами.
Для чтения информации, на одну из горизонтальных линий (wordline) подаётся напряжение, так что соответствующая линия транзисторов открывается. При этом с вертикальных линий (bitline) считываются заряды конденсаторов ячеек в данной строке. После этого wordline закрывается, что позволяет перейти к считыванию другой строки.
Оказалось, что если периодически включать и выключать wordline, наведённые токи приводят к увеличению утечки в соседних ячейках того же банка, и если сделать много переключений между циклами регенерации, этого может быть достаточно для переключения бита с 0 на 1 или наоборот.
Демонстрация
Эффекта можно достичь с помощью кода, не требующего никаких специальных привилегий. Простейшая атака выглядит так:
code1a:
mov (X), %eax ; прочитать адрес X
mov (Y), %ebx ; прочитать адрес Y
clflush (X) ; сбросить строку кэша, соответствующую адресу X
clflush (Y) ; сбросить строку кэша, соответствующую адресу Y
mfence ; дождаться окончания операций с кэшем
jmp code1a
Адреса X и Y должны быть в одном банке, но в разных строках DRAM. Сброс кэша нужен, чтобы гарантировать чтение из RAM на каждом цикле. Два адреса надо использовать, чтобы обеспечить включение/выключение wordline на каждом цикле. Этот код не вызывает уязвимость, поскольку логика DRAM оптимизирует включение wordline, и необходимых постоянных переключений не происходит:
code1b:
mov (X), %eax
clflush (X)
mfence
jmp code1b
Чтобы вызвать ошибку, необходимо сделать несколько сотен тысяч циклов за время между двумя регенерациями (обычно 64 мс), что вполне достижимо. Наличие ECC не сильно помогает, так как нередки ошибки одновременно в нескольких битах.
