
...{...
"some-key_comment":"my comment for key and value",
"some-key":"some-value",
...}...
...{...
"some-key":"some-value", //какой-какой key?? Ай, комментарии - нельзя!
...}...
Придумаем JSON-подобный формат с комментариями в стиле JS, чтобы их можно было выполнять как JS, а, очистив от комментариев — читать как JSON. ("TL:DR: покажите мне код.")
Сыр-бор и источник
Кстати, Дуглас Крокфорд, который это всё устроил, в 2012 году объяснил: )
Я убрал комментарии из JSON, потому что видел людей, использующих их для хранения директив разбора — практика, которая разрушила бы совместимость (формата). Я знаю, что отсутствие комментариев некоторых печалит, но их (комментариев) не должно быть.
Допустим, вы используете JSON для хранения конфигурационных файлов, которые привыкли комментировать. Вставьте любые комментарии, как вам нравится. Затем пропустите их через JSMin перед работой JSON-парсера.
Сделал он это на G+, где можно ставить только «плюсы», а комментарии закрыл. Так что, какова бы ни была реакция общества под объяснением, мы увидим только «плюсы» (или смотреть у тех, кто расшаривал этот пост).
И цитата Крокфорда из другого места:
Основная причина, отчего я удалил комментарии — были люди, которые пытались парсить данные на основе комментариев, что полностью ломало совместимость. Я никак не мог контролировать их, поэтому лучшим выходом было комментарии удалить.
Поэтому дальше читаем, кликнув и согласившись на обещание:
| «Обещаю, что я буду осторожен и не буду использовать комментарии для парсинга данных! |
Всё уже сделано до нас
В том и дело, что требуется ещё один парсер, а так — большой проблемы нет. И проблема этим не ограничивается — иногда надо файл слегка изменить, оставив комментарии. Первую часть (парсер) решили, например, через JSON.minify(). Вторую и ряд других проблем (концевые запятые или вообще без них, многострочные комменты, ключи и строки-значения без кавычек) — не поленились решить в Hjson, потратив 750 строк на код JS (с комментариями на 10-15%).
Стоп, а нужно ли это вообще?
Несомненно, суровым программистам (таким, которые пишут комментарии как значения ключей в JSON), а также роботам (сетевым и вообще) это не нужно. Они прекрасно перекодируют имена ключей в любом знакомом им конфиге, а программисты — так вообще, имеют ещё интеллект, позволяющий им разбираться в незнакомых названиях и строить эвристики по их расшифровке без всякого компьютера. Остальные, в том числе не суровые программисты, считают комментарии полезными и тратят время не только на их чтение иногда, но и на их написание. Несомненно, Крокфорд относится к суровым программистам, а создатели YAML — нет. С этим приходится мириться и соединять миры роботов (и с.п.) и людей.
Есть ещё хакеры, которым подойдёт совершенно хакерский, валидный способ записи JSON с последовательным повторением одинаковых ключей (в JS+»use strict" даст ошибку). Значение первого ключа в большинстве парсеров не сохранится, поэтому его (и все такие, кроме последнего) можно использовать как комментарии. Способ тоже страдает «машинностью».
...{...
"some-key":"comments_comments",
"some-key":"some-value",
...}...
Итого, не все будут за «ещё один формат, 16-й по счёту». Любая попытка построить, а тем более, применить конвертор форматов приведёт к игнорированию некоторой частью девелоперских юнитов данного формата. В тех же индивидуумах, в которых странным образом сочетаются осколки разных миров, которые ещё не определились со своей сущностью, процедуры конвертации
Поэтому данный формат содержит в себе несочетаемое, подобно компьютеру для блондинки: с одной стороны, методы преобразований, которые под силу применить только роботам, с другой стороны, результаты предстают в более человекочитаемой форме.
Мост между роботами и людьми
Можно придумать плагин к Grunt/Gulp (например, grunt-strip-json-comments, Gulp...) для очистки файлов от комментриев. Но суть действия сводится к небольшому (до 1 К) регулярному выражению, которое проще написать в Gruntfile.js, чем в него же вписывать ещё один плагин. Более того, такое же выражение нужно и для JS на клиенте, чтобы читать тот же JSON, поэтому от его явного вида мы всё равно не убежим.
Методы для преобразований форматов собраны в объект jsonComm, который работает в среде Javascript. Для решения частных задач не нужен весь объект — не всегда имеет смысл брать в проект все методы. Например с задачей простого удаления комментариев (как в gulp-strip-json-comments) справляется метод, состоящий из одного регулярного выражения (jsonComm.unComment(), до 1 КБ несжатого кода; пример далее; в тестовом разделе проекта jsonComm есть тесты и бенчмарки для оценки корректности и быстродействия), которое даже компилировать не надо, если нет цели применять разные настройки правил.
Настройки могут быть, к примеру, такие. Каким символом отмечать начало комментария? Если в среде чистого JS есть уверенный ответ — "//", то сторонники Пайтона или YAML скажут — "#". Попытки объединить непримиримых приводят к настройкам правил и к конверторам — тем самым, с которых, в том числе, начали. В среде адептов JS нет надобности в настройках, и они выжгут из проекта упоминание о "#". Потому что нельзя тратить 36 микросекуд (микро-) на генерацию регекспа ради лояльности к такой ереси. Лоялисты — тоже выжгут, но удлинят регексп и станут тратить 0.1-0.5 (условно) микросекунд (микро-) уже не на генерацию, а на каждый цикл перекодировки. За это их ненавидят пуритане. Ведь роботы мыслят гораздо быстрее, и им медлительность видится в другом масштабе.
Какие задачи можно решать при комментировании JSON?
- просто читать в JS или NodeJS формат jsonComm (с комментариями), удалять из них комментарии и далее верифицировать как обычный JSON в JSON.parse(); то же самое, что делает большинство проектов по добавлению комментариев в JSON. Работает быстро (десятки-сотни мкс).
- читать не JSON, а файлы JS (с кодом) чтобы из оставшейся части взять некоторые константы как настройки (например, в NodeJS), когда файл JS будет их тоже использовать при своём исполнении в другом месте (на клиенте) — своеобразный шаблон с упрощением структуры конфигурации;
- как в предыдущем пункте, но уже хочется изменить некоторые настройки после прочтения (например, в Ноде обновить номер сборки или внести настройки конфига), чтобы далее JS на клиенте, ничего не подозревая, использовал их. Это — аналог шаблона на чтение-запись.
Здесь — не все мыслимые задачи, но группа, достаточная для простого конфигурирования проекта. Вместо Yaml с комментариями или костыльных комментариев в чистом JSON — пишем jsonComm с расширением *.js, который может или читаться как JSON (на сервере, при сборке проекта или на клиенте), или выполняться как JS, имея комментарии в JS- или YAML-стиле.
Задачи разделяются на 2 практических случая — когда нам не нужно редактировать свой jsonComm, и когда редактировать нужно, при этом оставляя все комментарии. Когда происходит только чтение (это же — случай клиентского AJAX), ограничиваемся единственным методом jsonComm.unComment() c одним регекспом, и далее — JSON.parse().
Случай записи изменённых значений или ключей потребует небольшой процедуры парсинга текстового файла JsonComm (с комментариями, без их удаления) или JS, чтобы точечно изменить требуемое. Манипуляция возможна для файлов "*.js", если коды языка в них не будем трогать скриптами — требуется лишь не ошибаться в записи значений ключей. К необходимым методам добавляется второй: jsonComm.change().
Какие ещё задачи можно решать при комментировании JSON?
Задачи академического типа:
- получить «валидный» доступ к комментариям jsonComm, переведя их сначала в пары «ключ#»-«комментарий», выбрав основу ключа из той строки, возле которой он найден, а затем, после парсинга из правильного JSON — обрабатывать их далее (например, переводя в другой формат);
- работать с Yaml напрямую (но теряем признанную браузером/средой JS основу для валидации)
- взаимное преобразование в Yaml и обратно через выше сделанный валидный JSON;
- то же для XML; тогда получится кластер из четвёрки языков описания данных, 2 из которых признаны в браузерах и многочисленных вычислительных средах.
Особенность этих задач — практической необходимости в них нет, но видя нишу, место под них зарезервировано (функции toYaml, toXml, fromYaml, fromXml, to; последняя — это «в jsonComm»). Без комментариев — такой кластер и без того уже есть в работах других библиотек. Чтобы влиться в него с комментариями, нужно начать хотя бы с функции перевода комментариев jsonComm в один из валидных и признанных форматов. Очевидно, первый кандидат — JSON.
Первое же знакомство со способами комментирования создаёт много вопросов — к каким ключам привязвать комментарии до найденной пары, а каким — после? Например, комментарии после разделителя-запятой, но стоящие на той же строке, обычно относятся к предыдущей паре, поэтому на разделитель будет влиять и окончание строки. Второе: многострочные комментарии логически могут относиться к разным смежным парам. Третье: а к чему относятся комментарии в массивах? Их ключи выражены неявно, и логично бы создать рядом лежащий массив. А если он многомерный и с редким заполнением? Четвёртое: комментариев на строке может быть несколько; пара может быть растянута на 3 и более строк.
Весь этот круг не менее надуманных, но реальных проблем потребует достаточно продуманного подхода, чтобы автоматическая конвертация комментариев не приводила к ухудшению читаемости форматов. Поэтому не будем спешить с их изготовлением. Займёмся лучше формальным описанием грамматики jsonComm.
Грамматика jsonComm
Чаще всего встречаются пары в файлах JSON, зписанные на отдельных строчках:
<набор пробельных отступов>"<ключ>": <значение>
Значение — строка в кавычках или другие термы по всем правилам JSON. Ключ — любая строка, лишь с особым экранированием кавычек внутри себя. Между элементами могут быть пробельные символы, а разделяются пары запятыми или скобками, которые могут стоять где угодно до или после пары, в том числе, на соседних строках.
У нас будет очень похожий формат (jsonComm), с той разницей, что на месте пробельных символов могут быть комментарии 2 типов.
Оказывается, экономичнее при этом ориентироваться не по строкам, а по разделителям (скобкам, запятым). Переносы строк для многострочных комментариев вообще не имеют значения, а для однострочных служат признаком конца. Это повлияет на то, какой парсер будет работать в алгоритме преобразования.
Далее, при решении творческой задачи по вопросу того, к какой паре отнести комментарии, расположение разделителя и переносов строк снова будет иметь значение. Для просто удаления комментариев — оказывается, что переносы строк не важны (не следует лишь удалять концевой перенос однострочного комментария).
С учётом сказанного, основная конструкция грамматики jsonComm выглядит так:
(("{" | "[" | ",")<пробелы>)
<пробелы-комменты>
(<пробелы>"<ключ>"<пробелы>)
<пробелы-комменты>
(<пробелы>(":")<пробелы>)
<пробелы-комменты>
(<пробелы><значение><пробелы>)
<пробелы-комменты>
|
<пробелы-комменты>
(<пробелы><значение><пробелы>)
<пробелы-комменты>
(<пробелы>("}" | "]" | ","))
После фильтрации выбрасывается всё, что не в скобках, и остаётся всё, что изображено в круглых скобках. С некоторыми особенностями, конечно, которые на этой упрощённой схеме не отображены (пустое значение означает значение-структуру). Схема может пропустить неправильный JSON, может вообще пропустить любой текст, кроме комментариев, например, программу или текст книги. И это хорошо тем, что при валидации, если её делают, JSON всё равно проверяется, а если валидации нет, а текст парсится JS-компилятором, то надобность в удалении комментариев отсутствует, схема в этом режиме не работает.
Похожая, более сложная схема нужна будет для вставления комментариев-значений (функция jsonComm.comm2json()). В ней из jsonComm вида
...
,"some-key":"some-value" //comments_comments
...}...
создаём
...
"some-key#":"comments_comments",
"some-key":"some-value",
...}...
или без строчки с ключом для комментария. Если в области текста, относящейся к паре, встретилось несколько комментариев, всех их копируют в значение «some-key#». Но если комментарий встретился не в районе пары (в массиве, до или после всех скобок), он игнорируется. Все символы комментария приходится преобразовывать в валидные для JSON. Например, табы — в "\t", "\" — в "\\",….
Как на практике содержать JsonComm?
До сих пор мы могли записать без проблем и плагинов только JSON со всеми оговорками отсутствия комментариев или с присутствием, но в виде значений (или править JS как текстовые файлы, или хранить в БД). Сейчас будем пользоваться изменяемыми (для NodeJS) файлами jsonComm, имеющими расширение *.js.
Выявлены 2 практические ниши применения JsonComm-файлов: на чтение конфигураций, оформленных с комментариями, на обновление конфигураций, и одна академическая — конвертор форматов.
Если файлы нужно только читать (клиентский JS и прочее), читаем их как xhr.responseText в AJAX или как *.js и преобразуем JsonComm в объекты-структуры с валидацией через JSON.parse().
Если файлы нужно модифицировать, то для быстроты работы используем алгоритм поиска и замены по уникальным ключам, не повторяющимся в файле (jsonComm.change()). Тогда не нужно делать дерево разбора, одновременно обходя комментарии (впрочем, это тоже не должно быть медленно, но отдельный сложный однопроходный алгоритм).
Нет проблем добавить пайтоновский стиль однострочных комментариев (#comments_comments). Но тогда не будет работать способ чтения как файла *.js. В коде проекта заложена возможность отключить синтаксис "#" у комментариев (на начальном этапе компиляции регекспа).
Простые случаи, когда это нужно:
* В сборщике проекта на Grunt/Gulp/… вычисляем новый номер версии и запоминаем его в тот же файл конфигураци.
* там же, в сборщике, создаём константы проекта на основе других параметров сборки и пишем их как параметры для JS.
Чуть более сложно, клиентский JS тоже может приобрести функцию записи таких файлов, через отправку результата на сервер. Это даст ещё больше вариантов использования (сборочная панель на клиенте), оставляя комментарии в файле. Для этого ему надо модифицировать и отправить строку (образ многострочного файла) на сервер, а там её записать в файл (конечно, с решением вопросов безопасности).
Реализация
Чтобы долго не крутить циклы, преобразование выполняется «одним махом» на регулярных выражениях.
Выкусывание комментариев
Преобразователь фактически работает как цикл по строкам, методично выкусывая комментарии и пропуская допустимые фрагменты JSON. На его базе несложно построить и распознаватели текста комментариев, чтобы их сохранять в особые ключи-значения. Таким способом, мы допускаем комментарии для дальнейших операций, но не для того, чтобы «нарушить совместимость» (при желании — всегда можно), а чтобы код с комментарием был более удобной записью хуже читаемого выражения из 2 пар «ключ-комментарий» и «ключ-значение».
Не
"ключ_": "комментарий",
"ключ": "значение",
, а
"ключ": "значение" //комментарий
Решение выполняет также задачу по распределению ответственности за валидность кода. Всё, что относится к комментариям, контролируется визуально и с подсветкой синтаксиса в IDE разработчиком. Правильность остального JSON разбирает стандартный парсер JSON.parse().
Начнём с простого. Как приблизительно работает парсинг на регекспах? Попробуем удалять концевые комментарии. (Код не используется далее, он — только для примера.)
('\n'+строки_файла).replace(/(^|\r?\n)(([^"\r\n:]*"(\\"|[^"\r\n])*"|[^"\r\n:]*):?([^"\r\n]*"[^"\r\n]*"|[^"\r\n]*)[^\/"\r\n]*?|[^\/"\r\n]*?)(\/\*\*\/|\/\*([\s\S]?(?!\*\/))+.{3}|\/\/[^\r\n]*)/g,'$1$2')Для понимания, как оно устроено, обратим внимание на функциональные части:
(^|\r?\n) — захватывающие скобки для отображения предыдущего переноса строки.Следующая за ним скобка и её пара — ...
[^\/"\r\n]*?) — вторые используемые для копирования захватывающие скобки."(\\"|[^"\r\n])*" — ключ или строка в кавычках; если кавычек нет — далее ищется альтернатива из просто\s*\/\*\*\/|\s*\/\*([\s\S]?(?!\*\/))+.{3} — парсер многострочного комментария.\/\/[^\r\n]* — парсер однострочного комментария до конца строки.С выкусыванием комментариев в конце строки у этого несложного выражения — всё отлично. Хуже дело — с выкусыванием комментариев со звёздочкой между ключами и значениями. Можно пренебречь и не писать таких комментариев. Тем более, что у «конкурента» YAML имеются только концевые. Но, имея функциональные части, уже можно построить более сложное выражение, чтобы не накладывать таких ограничений. При этом придётся не просто оставлять «всё до комментария в строке», но и между ними — усложняются оставляемые фрагменты. Фактически, это — вся jsonComm.unComment(jsonCommString). Именно эту строчку можно копировать в Gruntfile.js вместо подключения модуля, чтобы очистить строку JSON от комментариев.
jsonCommString.replace(/(?:(?:((?:\{|,)\s*)(?:(?:\s*(?:\/\/|#)[^\r\n]*(\r?\n|$))*(?:\s*\/\*\*\/|\s*\/\*(?:[\s\S]?(?!\*\/))+.{3})*)*(\s*"(?:\\"|[^\r\n"])*"\s*)(?:(?:\s*(?:\/\/|#)[^\r\n]*(\r?\n|$))*(?:\s*\/\*\*\/|\s*\/\*(?:[\s\S]?(?!\*\/))+.{3})*)*(\s*:\s*)(?:(?:\s*(?:\/\/|#)[^\r\n]*(\r?\n|$))*(?:\s*\/\*\*\/|\s*\/\*(?:[\s\S]?(?!\*\/))+.{3})*)*(\s*(?:[0-9.eE+-]+|true|false|null|"(?:\\"|[^\r\n"])*"|(?!:\{|:\[))\s*)(?:(?:\s*(?:\/\/|#)[^\r\n]*(\r?\n|$))*(?:\s*\/\*\*\/|\s*\/\*(?:[\s\S]?(?!\*\/))+.{3})*)*(\s*(?:\}|(?!,))\s*)?)+?|(?:((?:\[|,)\s*)(?:(?:\s*(?:\/\/|#)[^\r\n]*(\r?\n|$))*(?:\s*\/\*\*\/|\s*\/\*(?:[\s\S]?(?!\*\/))+.{3})*)*(\s*(?:[0-9.eE+-]+|true|false|null|"(?:\\"|[^\r\n"])*"|(?!:\{|:\[))\s*)(?:(?:\s*(?:\/\/|#)[^\r\n]*(\r?\n|$))*(?:\s*\/\*\*\/|\s*\/\*(?:[\s\S]?(?!\*\/))+.{3})*)*(\s*(?:\]|(?!,))\s*)?)+?|(?:(?:\s*(?:\/\/|#)[^\r\n]*(\r?\n|$))*(?:\s*\/\*\*\/|\s*\/\*(?:[\s\S]?(?!\*\/))+.{3})*)*\s*)/g,'$1$2$3$4$5$6$7$8$9$10$11$12$13$14')Тут широко используются незахватывающие скобки, чтобы оставить только захватывающие, для дальнейшей простоты второго аргумента в .replace(). (Подсказка-лайфхак: такие строки лучше всего читать в редакторе, имеющем выделение с подсветкой и выделение парных скобок, напр. от jetbrains.)
Для преобразования строки jsonComm в JSON достаточно этого выражения. Как показывают бенчмарки, это преобразование достаточно хорошо летает — время выполнения — десятки-сотни микросекунд на страницу (сильно зависит от сложности разбора). Хуже будет дело с академическим скриптом для вывода комментариев в JSON, когда в replace() понадобится функция.
Так, мы получили валидный JSON, решив первую часть задачи — прочитать jsonComm.
Затем, парсинг валидности оставшегося кода, как задумано, возлагается на стандартную JSON.parse(), после чего получаем структуру данных в JS. Следующая часть задачи — кое-что автоматически подредактировать в исходном тексте, оставив комментарии на местах.
Вставка некоторых обновлённых значений
Созданное отделение данных от комментариев прекрасно используется для поиска по части текста, не включающей комментарии. Соответственно, правка значений тоже ведётся по шаблону пары «ключ-значение» и не попадает в области комментариев, сколь бы похожим на них текст там не был.
Напомним ограничения, которые накладываем на правки.
- в тексте jsonComm ищутся уникальные ключи (в кавычках). Копии ключей в комментариях игнорируются. Для одинаковых имён ключей из разных веток структуры — изменится первое и создастся некритическая ошибка в отчёте.
- цепочки ключей не анализируются (для простоты и скорости поиска)
- править пары, записанные не с начала строки — без проблем, потому что распознаватель ориентирован на скобки и запятые как маркеры пар. Но для удобства чтения и контроля лучше записывать изменяемые пары с начала строки.
- удалить пару нельзя; самое большее — заменить на null или "". Как следствие, редактируемые ключи продолжают работать при любых автоматических изменениях, исчезнуть могут только при ручных.
- изменяются только примитивы; массивы и структуры остаются на месте. Попытка изменить структуру приводит к нефатальной ошибке (пишется в лог ошибок).
- изменение (переименование) ключей возможно, хотя противоречит человеко-ориентированному подходу и может привести к нарушению цепочки автоматических изменений, которое будет сложно отлаживать. Этим механизмом, возможно, удобно менять значения местами (перестановкой не значений, а ключей).
Такая схема не отменяет правок сериализованных структур, но этот путь — уже не для людей. В настоящем виде правки рассчитаны на смену данных без смены структур, описанных в файлах jsonComm.
Тогда всё очень просто и быстро работает: в исходном файле отыскиваются единственные образцы вида «ключ» (в двойных кавычках), после чего скриптом имеем доступ к значению — строке, числу или логическому.
Изменение значений выполняется функцией jsonComm.change(h), где h — одноранговый набор пар «ключ»-«новое значение». (В крайнем случае — «ключ»- {«новый ключ»:«новое значение»}.)
Что интересно, для .change() файл (строка) не обязан быть приводимым к JSON и к нему не обязательно пытаться применять .unComment(). Это может быть JS-файл, который сначала выполнится (например, только для того, чтобы прочитать из него текущие значения настроек вместо чтения JSON), а затем к нему применится модификация значений. Т.е. .change() — это тоже достаточно автономная функция в сборке.
Академические задачи: смена формата файла
Чтобы ещё больше потратить места на библиотеку, придумываются задачи глобальной конвертации.
● получить комментарии в JSON (функция преобразования — jsonComm.comm2json),
● работа с YAML,
● двусторонние преобразования «jsonComm — YAML».
● то же для «jsonComm — XML».
В силу их невостребованности, для последних поставлены функции-заглушки, и только первая (comm2json) сделана ради академического интереса, для ответа на вопрос — насколько медленнее это будет. Приходится делать replace, в котором захватить параметры комментариев через функцию, а затем символ за символом проверять комментарии и преобразовывать имеющиеся в допустимые для JSON строковые символы.
Краткий ответ — становится медленее в 30 раз и тоже сильно зависит от сложности разбора, количества комментариев. Тестовый пример уложился примерно в 1 миллисекунду, но реальность легко сделает жизнь сложнее. Зато мы получаем первый инструмент для «полностью валидного» последующего преобразования в другие форматы данных (Yaml, XML).
Результаты теста
Посмотрим, как на субноуте средней руки эти 3 функции справляются с небольшим контрольным jsonComm, имеющим всевозможные (конечно, не все) сложности для парсинга. На скриншотах — исходные данные, но в проекте можно найти код этих данных и провести тесты на своём компьютере и браузере. На Firefox 34 (jsonComm.unComment):
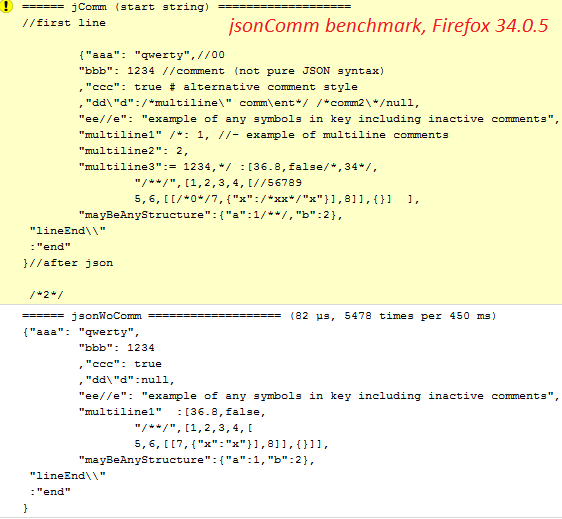
На Хроме в этом тесте — вдвое лучшие результаты.
Как выполняется парсинг комментариев (jsonComm.comm2json)? Здесь замена работает через replace(,function).

У Хрома здесь и далее — сопоставимые результаты. Это значит, что его специально оптимизировали на замены строк (.replace()) без функций. В любом случае, первый тест — очень быстро, этот — умеренно.
Строчки форматируются неровно, но здесь это не имеет большого значения, потому что предназначение функции — получить валидный JSON с валидными комментариями. Показать красиво можно и стандартными средствами (.stringify), как показано далее в тесте (скриншот не приведён).
Как изменяются значения ключей (jsonComm.change)? Здесь форма и красивость результата — уже на первом месте, потому что предназначено для чтения конфигов людьми. Правила замены показаны в объекте jCommChanges.

Тут можно обратить внимание, что массивы и структуры не меняются по определению наших правил. Даже если написано «multiline1: {newKey:'newValue'}», изменяется только ключ, а запрос на изменение значения игнорируется.
Чем больше изменений требуется сделать на том же участке jsonComm, тем медленнее работает скрипт (что логично). Исходя из приведённых объёмов, можно оценить, какой будет скорость на больших JSON. В общем, скорость — достаточно хорошая, если даже для правок идёт речь о единицах миллисекунд.
Как упоминалось, первая функция с компилированным регекспом в несжатом виде занимает менее 1 КБ. Минифицированные первые 3 функции с выбрасыванием нереализованных остальных заглушек — 2.1 КБ (src/jsonComm.min.js).
Новые вклады в проект
Что хотелось бы увидеть в проекте от новых контрибьюторов?
1) Кроме академических разделов, есть элементы парсинга, которые не помешало бы оттачивать в коде, чтобы выделять комментарии точнее (как показывает тестовый вывод в jsonCommTest.htm под заголовком «jsonWithComm», выходная строка .comm2json() не очень совершенна). Впрочем, в JSON.stringify уже есть способы вывести строку красивее, как показывает следующая строка лога под заголовком «jsObjWithComm».
2) Интересно было бы сравнение скорости со скриптовым парсингом.
3) Не отмечаются ошибки неуникального парсинга. Не обрабатываются JSON в виде одного примитива.
4) Плагины для Grunt, Gulp,….
Приветствуется тестирование для сложных случаев исходных файлов и сообщение об ошибках в issues, распространение ссылок для другой потенциальной аудитории (Китай и некоторые другие развитые страны, в которых Гитхаб не заблокирован).
● Всё, что описано — работает здесь: jsonComm — проект (Github), описание проекта (англ.).
● Json — стандарт, rfc-4627 о нём же, rfc-7159 (март 2014): обновление стандарта.
● Вопрос "Как мне прокомментировать JSON?" на SO.
● JSON.minify() (блог) и Github.
● grunt-, gulp, broccoli-, strip-json-comments (Github)
● JSON Comments (другой автор)
● Предложения по совершенствованию JSON (англ., 2011)
● JSON5 (перекликается с прежним)
● Hjson, the Human JSON (Hjson keep my comments when updating a config file.)
Only registered users can participate in poll. Log in, please.
[Для разработчиков] Было ли у вас желание использовать в разработках обычные комментарии в JsON?
39.29% Да (и оставалось желанием)167
49.65% Нет, JsON не комментировал211
4.47% Да, и использовал, очищая затем JsON19
2.35% Да, испольльзовал, парся затем его как JS10
4.24% Комментировал, но он после этого не работал: ) (шёл, например, в статью)18
425 users voted. 79 users abstained.
Only registered users can participate in poll. Log in, please.
Прочитал ли я статью? Какая часть статьи мне оказалась полезной?
13.9% Не читал и не буду, по любой причине41
26.78% Только до ката79
34.92% До ката, затем код на Гитхабе, но всё бесполезно, тлен и суета103
17.97% Только до формул53
5.08% Код на Гитхабе пригодится15
15.25% Воду пропустил, но разбор кода оказался полезным45
295 users voted. 136 users abstained.
