Здравствуйте. В этой статье я расскажу про свой хобби-проект не-фон неймановского компьютера. Архитектура соответствует функциональной парадигме: программа есть дерево применений элементарных функций друг к другу. Железо — однородная статическая сеть примитивных узлов, на которую динамическое дерево программы спроецировано, и по которой программа «ползает» вычисляясь.

Примерно так работает дерево, только здесь для наглядности вычисляются арифметическое выражение, а не комбинаторное; шаг на рисунке — один такт машины.
Сейчас готов ранний прототип, существующий как в виде потактового программного симулятора, так и в виде реализации на ПЛИС.
ЭВМ традиционной архитектуры изменили мир, но период невероятного, опьяняющего роста видимо закончен. Один из основных ограничивающих факторов — бутылочное горло между процессором и памятью, препятствующее параллелизации. Функциональное программирование — привлекательное направление ухода от ограничений фон неймановской, централизованной архитектуры, однако попытки создать архитектуру ЭВМ на базе функционального подхода не имели успеха.
Но время идёт, технологии микроэлектроники совершенствуются и становятся более демократичными. Я пробую делать свой компьютер на базе комбинаторной логики. Вычислительная задача формулируется как выражение — дерево применений функций-комбинаторов друг к другу:
Выполнение программы понимается как трансформация этого выражения в некоторую простую форму, дающую ответ. Система полна по Тьюрингу, у чего есть обратная сторона: не всякое выражение удаётся вычислить. Подробнее о том, как посчитать что-то с помощью комбинаторной логики смотрите тут и тут.
Основная идея — разместить дерево программы на аппаратном дереве ячеек, способных применять комбинаторы.
Зачем аппаратное дерево? Дело в том, что когда мы проецируем дерево программы на привычное нам одномерное адресное пространство, неизбежно возникают нелокальные, «длинные» связи. Вот пример плоской записи древовидного выражения: "(A*B) + (C*D) — E" Здесь "+" является источником данных для "-", но в формуле они разнесены.

Непересекающиеся поддеревья можно вычислять независимо и одновременно, отсюда естественный параллелизм. Общей памяти нет: данные хранятся локально, а значит нет того самого горла «процессор — шина — память». Все операции, кроме копирования поддеревьев, выполняются быстро. В своей предыдущей статье я показал, как можно использовать дерево такой структуры для сортировки чисел.
Итак, у нас есть дерево применений одних функций к другим,
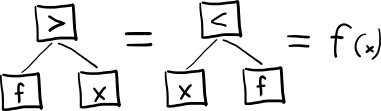
где листья — элементарные функции, в случае комбинаторной логики это базовые комбинаторы, например, набор S, K, I:
Синтаксис для ассемблера позаимствуем у эзотерического функционального языка программирования unlambda (как и было обещано в этой публикации, в самом конце):
Это решение позволяет использовать интерпретатор unlambda для проверки корректности вычислений.
Здесь штрих (`) -символ применения функции. Используется префиксная запись, то есть `fx = f(x).
F( G(X,Y), H(Z,V) ) = ``F``GXY``HZV
Именно в такой форме выражение подаётся на вход машины. Загрузка происходит через корень дерева, внешнее устройство посимвольно передаёт программу корневому узлу, который первый символ забирает себе, а оставшуюся часть передаёт своим потомкам, каждый из которых выполняет процедуру загрузки рекурсивно. Получив поддерево полностью, узел сообщает об этом предку и начинает выполнять свою часть программы.
Для примера вычислим булевское выражение, "(1|0)&(0|1)". В комбинаторном базисе это можно представить как ````ssk````siik`ki````sii`kik Да, такие выражения невозможно читать, но их можно писать см. учебник. В результате выполнения программы такого вида, состояние машины будет эволюционировать от первоначальной формулы к единственному булевскому значению, либо «1», закодированное как «k», либо значение «0» в виде "`ki". Для данной конкретной формулы получаем именно «k».
На вычисление уходит 116 тактов. Из них первые 67 тактов продолжается загрузка программы. С точки зрения практической полезности цифры не обнадёживают, но потенциал для оптимизации есть, например использование более богатого набора комбинаторов сократит и размер и время выполнения программы.
Описываемые результаты получены на программном симуляторе. Исходники и исполняемый файл для win здесь. Симулятор — консольное приложение, установки не требует, комбинаторное выражение передаётся как параметр командной строки.
Симулятор точно соответствует реализованной на verilog-е ПЛИС-версии, но с одним принципиальным отличием — он не ограничен по физическим ресурсам. То есть, симулятор обладает потенциально бесконечным деревом, а на ПЛИС дерево ограничено. Дерево из 63 узлов, то есть глубины 6, занимает 16000 Altera LE, это много; если программа в процессе вычисления вырастает больше, то вычисления заканчиваются неудачей. Единственная польза от аппаратной версии — показать принципиальную реализуемость в железе.
Вернёмся к вычислениям. Теперь посчитаем арифметическое выражение, (2+1). Чтобы перевести это на язык комбинаторной логики используем нумералы Чёрча. Получаем выражение ````si`k`s``s`kski``s``s`kski. Чтобы получить что-то осмысленное, подставим это выражение вот так: ``(2+1)ki. Вычислив это получим `k`k`ki, количество букв к символизирует полученный ответ. На вычисление уходит 124 такта. А вот на вычисление ``(1+2)ki уходит уже 243 такта, на ``(3+3)ki 380 тактов. Увы, пока всё очень медленно, ниже я наметил пути ускорения.
Приведённые примеры это простые, безусловно «схлопывающиеся» выражения, на практике такие задачи лучше выполнит традиционная машина. Однако, комбинаторная логика будучи полной по Тьюрингу системой, позволяет решать задачи большей вычислительной сложности, соответствующие выражения могут расти в процессе вычисления. Правда, это свойство привносит риск безудержного роста или даже никогда не завершающейся программы, но и преимущество предлагаемая архитектура сможет показать только на таких задачах. Здесь в описании появляются циклы и рекурсия, классическая конструкция для их организации,- комбинатор неподвижной точки:
`Yx = `x`Yx = `x`x`Yx = `x`x`x`x…
Y(x)= x(Y(x))= x(x(x(x(...))))
На приведённых выше двух простых примерах видно, что булевские вычисления выглядят интереснее арифметики, машина очень чувствительна к размеру объектов. Но вычисление булевских выражений само по себе малоперспективно: задача даже на последовательной машине выполняется за О(1), то есть, программа будет грузиться дольше чем выполняться.
Этого «недостатка» лишена задача SAT. Здесь у нас булевское выражение дополняется переменными, и надо определить, выполняется ли формула; это уже NP-полная проблема. Можно добиться значительного ускорения, одновременно проверяя несколько наборов значений переменных. Именно к такого типа задачам я сейчас присматриваюсь. Интересны задачи с непредсказуемыми ветвлениями и без больших чисел, такие как символьные вычисления и автоматическое доказательство теорем.
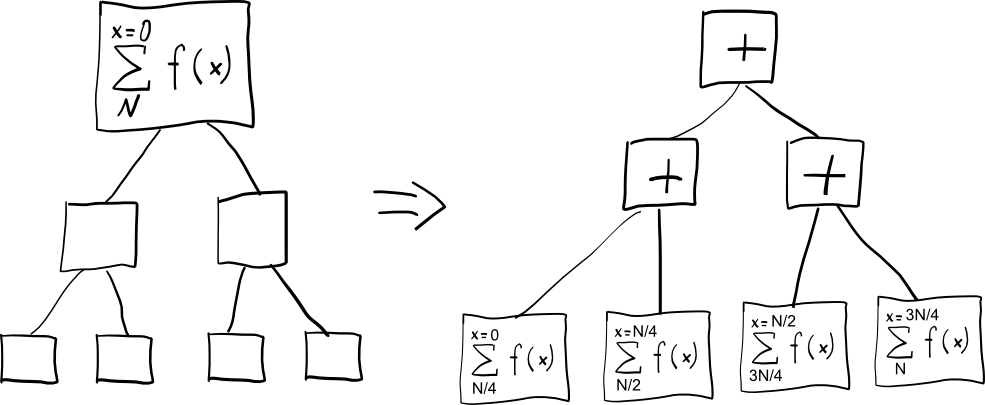
Идеальная задача должна формулироваться маленьким выражением, которое сначала растёт как дерево из семечка, формируя как можно больше параллельно вычисляющихся веток, а затем сворачиваться обратно, комбинируя результаты от веток, что-то вроде микро MapReduce:
Есть ещё одно направление возможных применений: реконфигурируемые вычисления. Идея такая: дополнить алфавит машины специальными блоками, не являющимися комбинаторами, но несущими особый, внешний к языку смысл. Работа в две фазы, комбинаторная машина работает в первой фазе. В ходе выполнения программы все комбинаторы должны вычислится, и остаться только специальные блоки, образующие некоторую искомую структуру, которая (во второй фазе) будет выполнять целевую работу.
Например, если взять в качестве специальных блоков логические элементы можно получить динамическую ПЛИС, которая будет по запросу формировать на лету скажем, умножитель на требуемую константу или сумматор вычисляемой разрядности из параметризованной схемы сумматора.

Мы проделали почти то же самое выше, когда применяли Чёрчевское число (3+3) к комбинаторам к и i, которые не выполнялись (в качестве функций) в процессе вычислений, а служили для наглядного представления результата. Заменив к на однобитный сумматор, мы бы получили к моменту завершения вычислений условный сумматор разрядности 6.
Это потенциальное применение не столь требовательно к производительности, при условии, что переконфигурирование требуется не слишком часто.
Поскольку дерево функциональной программы довольно разреженное, укладывать его на сбалансированное статическое бинарное дерево очень невыгодно. Поэтому в ближайших планах переход на аппаратное динамическое дерево, которое будет жить на регулярном графе, работающем по принципу клеточного автомата.
Но любой граф конечен, а многие функциональные выражения имеют тенденцию к неограниченному росту, особенно при энергичном исполнении; это ещё одна проблема, которую в будущем надо решать. Сейчас используется скорее энергичная чем ленивая стратегия вычислений, вероятно её придётся модифицировать, но чтобы заняться этим, нужно найти модельную задачу, приближённую к практической.
Определённую выгоду в смысле оптимизации можно получить, расширяя набор аппаратно реализованных комбинаторов, сейчас используется базисный набор SKI, возможно будут полезны другие комбинаторы, в том числе
Ввода-вывода как такового сейчас нет, ответ даёт само тело программы, трансформированное в ходе выполнения. Мысли как можно было-бы реализовать IO есть, но пока эта задача у меня не приоритетна.
Сейчас машина использует передачу параметров по значению, что приводит к необходимости копировать аргументы, собственно, большую часть времени машина занимается копированием. Реализовать передачу по ссылке было бы архи заманчиво, у программного интерпретатора эффективность от такого перехода взлетает на порядки! Как это реализовать на аппаратной сети узлов, я пока слабо представляю, но когда появится ориентировочная практическая задача, намерен серьёзно этим заняться.
Ещё одна функция, потенциально расширяющая возможности машины,- аппаратное сопоставление с образцом, в частности, проверка поддеревьев на равенство.
Повышение уровня программирования также в списке приоритетных задач, пока все силы идут на улучшение симулятора.
Куда более успешной сестрой комбинаторной логики является лямбда-исчисление. Можно ли модифицировать вычислительное дерево под этот вариант функционального программирования? В принципе да. Главная неприятность в том, что у нас появляется потенциально бесконечное количество имён переменных, а значит вызов переменной нельзя уложить на один аппаратный узел (конечный). Но это решаемо; в принципе, можно перейти на лямбда-исчисление, как на более популярную модель. Я остановился на комбинаторной логике, поскольку комбинаторы изящнее проецируются на операции с поддеревьями.
Идею создать специализированный вычислитель функциональных программ я перенял у своего научного руководителя, Вадима Николаевича Фалька, когда учился в аспирантуре МИРЭА десяток лет назад. Научная работа команды фокусировалась на теоретических исследованиях в области функционального и функционально-логического программирования. В частности, Фальком был разработан язык Falgol, своего рода функциональный ассемблер. Позиционировался он для теоретико-вычислительных целей, вроде доказательства корректности программ, но были и попытки построить на его основе вычислительную машину.
Я занимался немного другим и не особо преуспел, если честно, но идея создать функционально-логический вычислитель посеялась и через 10 лет таки проросла. Всё это время я работал системным программистом в компании разрабатывающей железо, в том числе микросхемы, что позволило мне освоить основы цифровой схемотехники, и довести дело до аппаратного прототипа.
Проект продвигается. Удалось создать прототип не фон неймановского компьютера, сочетающего черты несколько интересных парадигм: функциональное программирование, клеточные автоматы; аналоги мне не известны. ПЛИС-вариант пока малополезен в силу ограничений по ёмкости, но программный симулятор точно соответствующий аппаратной модели позволяет изучать выполнение программ. О практическом использовании в нынешнем виде речи не идёт, но я уже ищу модельную задачу, которая будет взята как цель для будущего применения машины.
Напоследок ещё раз отмечу, что современное развитие электроники позволяет реализовывать весьма нетривиальные идеи, хотя дело это и трудоёмкое. Спасибо за внимание.
Р. В. Душкин aka darkus «Комбинаторы это просто»
David Madore «The Unlambda Programming Language»
Интерпретатор языка unlambda
Примерно так работает дерево, только здесь для наглядности вычисляются арифметическое выражение, а не комбинаторное; шаг на рисунке — один такт машины.
Сейчас готов ранний прототип, существующий как в виде потактового программного симулятора, так и в виде реализации на ПЛИС.
Идеология
ЭВМ традиционной архитектуры изменили мир, но период невероятного, опьяняющего роста видимо закончен. Один из основных ограничивающих факторов — бутылочное горло между процессором и памятью, препятствующее параллелизации. Функциональное программирование — привлекательное направление ухода от ограничений фон неймановской, централизованной архитектуры, однако попытки создать архитектуру ЭВМ на базе функционального подхода не имели успеха.
Но время идёт, технологии микроэлектроники совершенствуются и становятся более демократичными. Я пробую делать свой компьютер на базе комбинаторной логики. Вычислительная задача формулируется как выражение — дерево применений функций-комбинаторов друг к другу:
// простая арифметика на языке комбинаторной логики (классический способ представления)
2+3 = + 2 3 = + ( +1 1 ) ( +1 1 1 ) =
+ ( +1 1 ) ( +1 +1 1 )
`` ``si`k`s``s`ksk ``s``s`ksk i ``s``s`ksk ``s``s`ksk i
Выполнение программы понимается как трансформация этого выражения в некоторую простую форму, дающую ответ. Система полна по Тьюрингу, у чего есть обратная сторона: не всякое выражение удаётся вычислить. Подробнее о том, как посчитать что-то с помощью комбинаторной логики смотрите тут и тут.
Архитектура
Основная идея — разместить дерево программы на аппаратном дереве ячеек, способных применять комбинаторы.
Зачем аппаратное дерево? Дело в том, что когда мы проецируем дерево программы на привычное нам одномерное адресное пространство, неизбежно возникают нелокальные, «длинные» связи. Вот пример плоской записи древовидного выражения: "(A*B) + (C*D) — E" Здесь "+" является источником данных для "-", но в формуле они разнесены.
Непересекающиеся поддеревья можно вычислять независимо и одновременно, отсюда естественный параллелизм. Общей памяти нет: данные хранятся локально, а значит нет того самого горла «процессор — шина — память». Все операции, кроме копирования поддеревьев, выполняются быстро. В своей предыдущей статье я показал, как можно использовать дерево такой структуры для сортировки чисел.
Итак, у нас есть дерево применений одних функций к другим,
где листья — элементарные функции, в случае комбинаторной логики это базовые комбинаторы, например, набор S, K, I:
Ix = Ix = x - тождественное отображение
Kxy = (Kx)y = x - конструктор констант
Sxyz = ((Sx)y)z = (xz)(yz) - коннектор
SKI на аппаратном дереве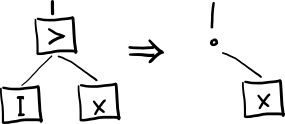
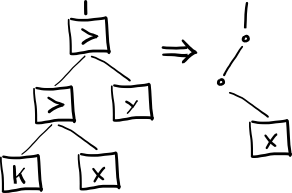
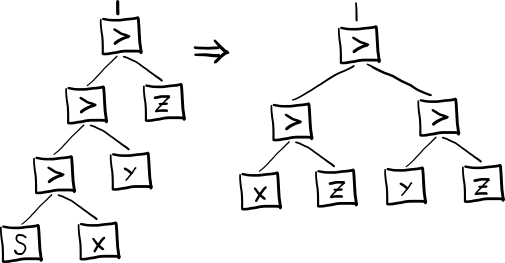
Синтаксис для ассемблера позаимствуем у эзотерического функционального языка программирования unlambda (как и было обещано в этой публикации, в самом конце):
`ix = Ix
``kxy = (Kx)y
```sxyz = ((Sx)y)z
Это решение позволяет использовать интерпретатор unlambda для проверки корректности вычислений.
Здесь штрих (`) -символ применения функции. Используется префиксная запись, то есть `fx = f(x).
F( G(X,Y), H(Z,V) ) = ``F``GXY``HZV
Именно в такой форме выражение подаётся на вход машины. Загрузка происходит через корень дерева, внешнее устройство посимвольно передаёт программу корневому узлу, который первый символ забирает себе, а оставшуюся часть передаёт своим потомкам, каждый из которых выполняет процедуру загрузки рекурсивно. Получив поддерево полностью, узел сообщает об этом предку и начинает выполнять свою часть программы.
Примеры работы
Для примера вычислим булевское выражение, "(1|0)&(0|1)". В комбинаторном базисе это можно представить как ````ssk````siik`ki````sii`kik Да, такие выражения невозможно читать, но их можно писать см. учебник. В результате выполнения программы такого вида, состояние машины будет эволюционировать от первоначальной формулы к единственному булевскому значению, либо «1», закодированное как «k», либо значение «0» в виде "`ki". Для данной конкретной формулы получаем именно «k».
На вычисление уходит 116 тактов. Из них первые 67 тактов продолжается загрузка программы. С точки зрения практической полезности цифры не обнадёживают, но потенциал для оптимизации есть, например использование более богатого набора комбинаторов сократит и размер и время выполнения программы.
Симулятор и ПЛИС-версия
Описываемые результаты получены на программном симуляторе. Исходники и исполняемый файл для win здесь. Симулятор — консольное приложение, установки не требует, комбинаторное выражение передаётся как параметр командной строки.
Краткое описание окна симулятора в интерактивном режиме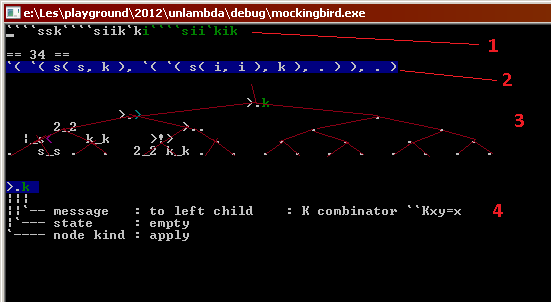
1) Программа на входе
2) Текущее состояние программы в виде текста
3) Полное состояние аппаратного дерева
4) Расшифровка состояния текущего узла
1) Программа на входе
2) Текущее состояние программы в виде текста
3) Полное состояние аппаратного дерева
4) Расшифровка состояния текущего узла
Здесь небольшой ролик с демонстрацией
Симулятор точно соответствует реализованной на verilog-е ПЛИС-версии, но с одним принципиальным отличием — он не ограничен по физическим ресурсам. То есть, симулятор обладает потенциально бесконечным деревом, а на ПЛИС дерево ограничено. Дерево из 63 узлов, то есть глубины 6, занимает 16000 Altera LE, это много; если программа в процессе вычисления вырастает больше, то вычисления заканчиваются неудачей. Единственная польза от аппаратной версии — показать принципиальную реализуемость в железе.
Вернёмся к вычислениям. Теперь посчитаем арифметическое выражение, (2+1). Чтобы перевести это на язык комбинаторной логики используем нумералы Чёрча. Получаем выражение ````si`k`s``s`kski``s``s`kski. Чтобы получить что-то осмысленное, подставим это выражение вот так: ``(2+1)ki. Вычислив это получим `k`k`ki, количество букв к символизирует полученный ответ. На вычисление уходит 124 такта. А вот на вычисление ``(1+2)ki уходит уже 243 такта, на ``(3+3)ki 380 тактов. Увы, пока всё очень медленно, ниже я наметил пути ускорения.
Приведённые примеры это простые, безусловно «схлопывающиеся» выражения, на практике такие задачи лучше выполнит традиционная машина. Однако, комбинаторная логика будучи полной по Тьюрингу системой, позволяет решать задачи большей вычислительной сложности, соответствующие выражения могут расти в процессе вычисления. Правда, это свойство привносит риск безудержного роста или даже никогда не завершающейся программы, но и преимущество предлагаемая архитектура сможет показать только на таких задачах. Здесь в описании появляются циклы и рекурсия, классическая конструкция для их организации,- комбинатор неподвижной точки:
`Yx = `x`Yx = `x`x`Yx = `x`x`x`x…
Y(x)= x(Y(x))= x(x(x(x(...))))
Гипотетические применения комбинаторной машины на практике
Логический вывод
На приведённых выше двух простых примерах видно, что булевские вычисления выглядят интереснее арифметики, машина очень чувствительна к размеру объектов. Но вычисление булевских выражений само по себе малоперспективно: задача даже на последовательной машине выполняется за О(1), то есть, программа будет грузиться дольше чем выполняться.
Этого «недостатка» лишена задача SAT. Здесь у нас булевское выражение дополняется переменными, и надо определить, выполняется ли формула; это уже NP-полная проблема. Можно добиться значительного ускорения, одновременно проверяя несколько наборов значений переменных. Именно к такого типа задачам я сейчас присматриваюсь. Интересны задачи с непредсказуемыми ветвлениями и без больших чисел, такие как символьные вычисления и автоматическое доказательство теорем.
Идеальная задача должна формулироваться маленьким выражением, которое сначала растёт как дерево из семечка, формируя как можно больше параллельно вычисляющихся веток, а затем сворачиваться обратно, комбинируя результаты от веток, что-то вроде микро MapReduce:
Реконфигурируемые вычисления
Есть ещё одно направление возможных применений: реконфигурируемые вычисления. Идея такая: дополнить алфавит машины специальными блоками, не являющимися комбинаторами, но несущими особый, внешний к языку смысл. Работа в две фазы, комбинаторная машина работает в первой фазе. В ходе выполнения программы все комбинаторы должны вычислится, и остаться только специальные блоки, образующие некоторую искомую структуру, которая (во второй фазе) будет выполнять целевую работу.
Например, если взять в качестве специальных блоков логические элементы можно получить динамическую ПЛИС, которая будет по запросу формировать на лету скажем, умножитель на требуемую константу или сумматор вычисляемой разрядности из параметризованной схемы сумматора.
Мы проделали почти то же самое выше, когда применяли Чёрчевское число (3+3) к комбинаторам к и i, которые не выполнялись (в качестве функций) в процессе вычислений, а служили для наглядного представления результата. Заменив к на однобитный сумматор, мы бы получили к моменту завершения вычислений условный сумматор разрядности 6.
Это потенциальное применение не столь требовательно к производительности, при условии, что переконфигурирование требуется не слишком часто.
Направления развития, проблемы и их возможные решения
Эффективное использование узлов
Поскольку дерево функциональной программы довольно разреженное, укладывать его на сбалансированное статическое бинарное дерево очень невыгодно. Поэтому в ближайших планах переход на аппаратное динамическое дерево, которое будет жить на регулярном графе, работающем по принципу клеточного автомата.
Как-то так, слева выражение, справа его укладка на гипотетической аппаратуре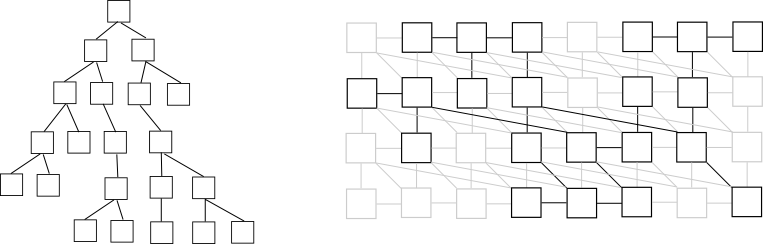
Но любой граф конечен, а многие функциональные выражения имеют тенденцию к неограниченному росту, особенно при энергичном исполнении; это ещё одна проблема, которую в будущем надо решать. Сейчас используется скорее энергичная чем ленивая стратегия вычислений, вероятно её придётся модифицировать, но чтобы заняться этим, нужно найти модельную задачу, приближённую к практической.
Расширение системы команд
Определённую выгоду в смысле оптимизации можно получить, расширяя набор аппаратно реализованных комбинаторов, сейчас используется базисный набор SKI, возможно будут полезны другие комбинаторы, в том числе
Bxyz = x(yz) - композиция х и y
Cxyz = xzy - перестановщик,
Wxy = xyy - удвоитель,
Yx = x(Yx) - комбинатор неподвижной точки.
(+1)nfx = f(nfx) - инкремент Чёрчевского числа
Ввода-вывода как такового сейчас нет, ответ даёт само тело программы, трансформированное в ходе выполнения. Мысли как можно было-бы реализовать IO есть, но пока эта задача у меня не приоритетна.
Сейчас машина использует передачу параметров по значению, что приводит к необходимости копировать аргументы, собственно, большую часть времени машина занимается копированием. Реализовать передачу по ссылке было бы архи заманчиво, у программного интерпретатора эффективность от такого перехода взлетает на порядки! Как это реализовать на аппаратной сети узлов, я пока слабо представляю, но когда появится ориентировочная практическая задача, намерен серьёзно этим заняться.
Ещё одна функция, потенциально расширяющая возможности машины,- аппаратное сопоставление с образцом, в частности, проверка поддеревьев на равенство.
Повышение уровня программирования также в списке приоритетных задач, пока все силы идут на улучшение симулятора.
О лямбдах
Куда более успешной сестрой комбинаторной логики является лямбда-исчисление. Можно ли модифицировать вычислительное дерево под этот вариант функционального программирования? В принципе да. Главная неприятность в том, что у нас появляется потенциально бесконечное количество имён переменных, а значит вызов переменной нельзя уложить на один аппаратный узел (конечный). Но это решаемо; в принципе, можно перейти на лямбда-исчисление, как на более популярную модель. Я остановился на комбинаторной логике, поскольку комбинаторы изящнее проецируются на операции с поддеревьями.
Предыстория
Идею создать специализированный вычислитель функциональных программ я перенял у своего научного руководителя, Вадима Николаевича Фалька, когда учился в аспирантуре МИРЭА десяток лет назад. Научная работа команды фокусировалась на теоретических исследованиях в области функционального и функционально-логического программирования. В частности, Фальком был разработан язык Falgol, своего рода функциональный ассемблер. Позиционировался он для теоретико-вычислительных целей, вроде доказательства корректности программ, но были и попытки построить на его основе вычислительную машину.
Я занимался немного другим и не особо преуспел, если честно, но идея создать функционально-логический вычислитель посеялась и через 10 лет таки проросла. Всё это время я работал системным программистом в компании разрабатывающей железо, в том числе микросхемы, что позволило мне освоить основы цифровой схемотехники, и довести дело до аппаратного прототипа.
Заключение
Проект продвигается. Удалось создать прототип не фон неймановского компьютера, сочетающего черты несколько интересных парадигм: функциональное программирование, клеточные автоматы; аналоги мне не известны. ПЛИС-вариант пока малополезен в силу ограничений по ёмкости, но программный симулятор точно соответствующий аппаратной модели позволяет изучать выполнение программ. О практическом использовании в нынешнем виде речи не идёт, но я уже ищу модельную задачу, которая будет взята как цель для будущего применения машины.
Напоследок ещё раз отмечу, что современное развитие электроники позволяет реализовывать весьма нетривиальные идеи, хотя дело это и трудоёмкое. Спасибо за внимание.
Ссылки
Р. В. Душкин aka darkus «Комбинаторы это просто»
David Madore «The Unlambda Programming Language»
Интерпретатор языка unlambda