Некоторое время назад мне стало интересно посмотреть, как выглядит CSS код нашего проекта, и как он менялся в течение целого года. Так на свет появился проект node-specificity. Что он делает? Он позволяет получить ответы на следующие вопросы:

Хорошо, почему это вообще важно? Может быть и нет, пока вы не работаете c кодом, состоящим из десятков тысяч строк, который сложно поддерживать, или вы довольно много экспериментируете. Ну и, конечно, если это не важно, то, по крайней мере, это должно показаться интересным.
Итак, node-specificity предоставляет две команды. Одна из них используется для процессинга CSS файлов и создания профайлов. Вторая — для чтения и «исследования» этих самых профайлов. Давайте разберем на примере. У меня есть несколько версий CSS файлов моего блога. Последняя версия — v8.css.
Создадим профайлы для этих файлов:
Мы только что создали профайлы для каждого отдельного CSS файла, поскольку мы хотим посмотреть на изменения во времени. Если у вас на сайте используется больше, чем один файл CSS, то вам необходимо создавать профайл для всех файлов, например, так:
Метка (label) используется как имя профайла в отчетах. После того как мы создали профайлы, мы можем запустить отчет. Давайте посмотрим на отчет «server»:
Откройте браузер и перейдите по адресу «http://localhost:4000/». Сейчас вы должны увидеть страницу с различными элементами управления и странным графиком. Это график распределения специфичности (см. заглавную картинку). Для каждой специфичности (кортеж) вы видите количество селекторов этой специфичности в каждом профайле.
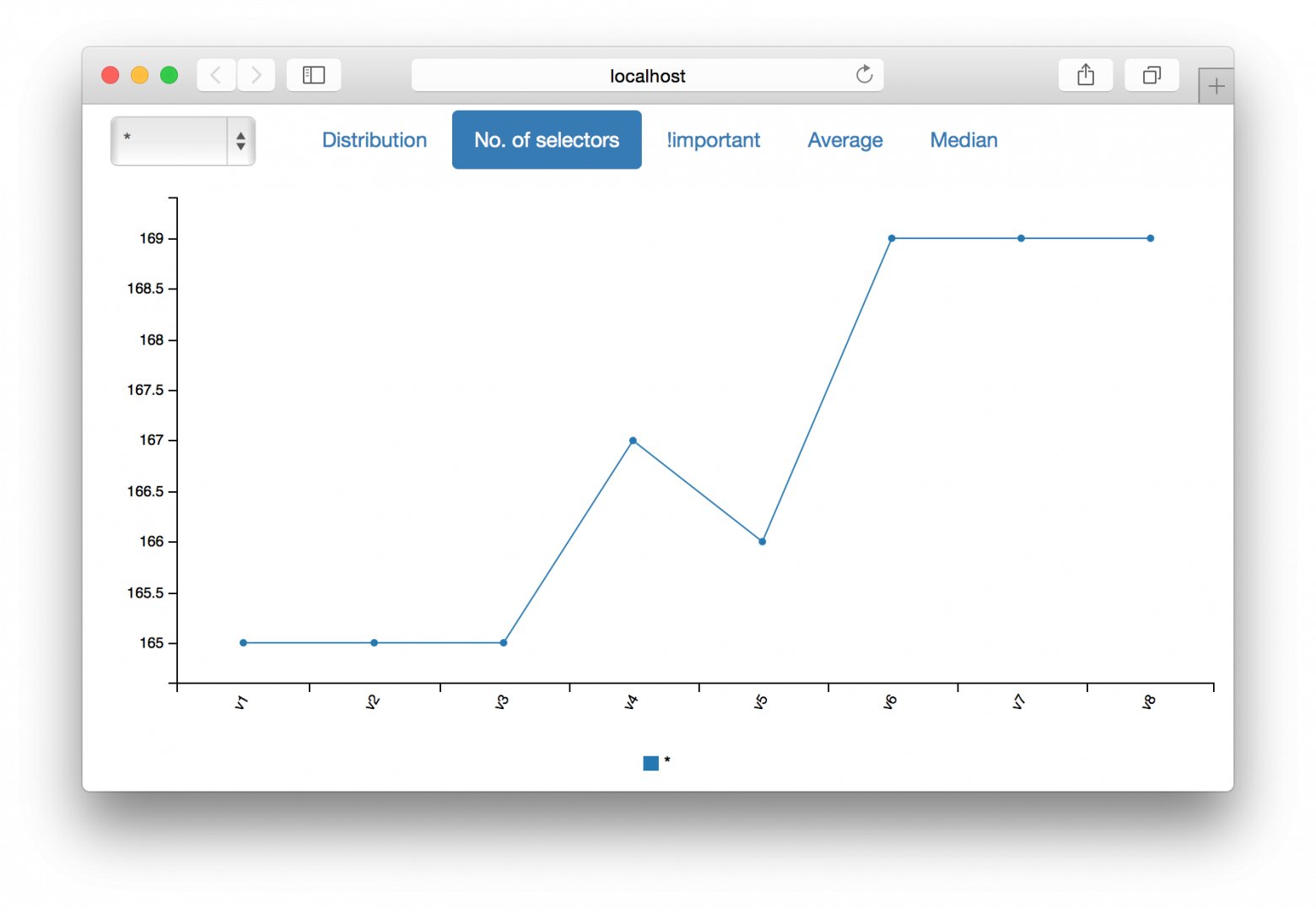
Другие графики: количество селекторов в файлах и профайлах; доля тех, что содержат
Кроме того, вы можете просматривать все эти графики для каждого профайла в отдельности. Для этого необходимо выбрать нужный профайл из списка слева. Например, ниже представлен график распределения специфичности для профайла v8.json.

Отчет «server» представляет из себя довольно мощный инструмент. Имейте в виду, что выше были продемонстрированы изображения для профайлов, состоящих из одного небольшого CSS файла. Если у вас несколько файлов в профайле, то графики заиграют интереснее.
Есть и другие типы отчетов. Возьмем, например, «inspect», который используется в качестве значения по умолчанию. Если вы выполните в терминале

Отчеты могут принимать дополнительные параметры командной строки. Их несколько. Например,
На этом все. Happy exploring!
- Как много селекторов в коде? Как их количество изменялось со временем?
- Каковы максимальное и среднее значения специфичности селекторов? Какова медиана? Как они изменялись со временем?
- Как выглядит распределение специфичности селекторов? Как оно изменялось со временем?
- В скольких селекторах используется
!importantдиректива? Как их количество изменялось со временем?
Хорошо, почему это вообще важно? Может быть и нет, пока вы не работаете c кодом, состоящим из десятков тысяч строк, который сложно поддерживать, или вы довольно много экспериментируете. Ну и, конечно, если это не важно, то, по крайней мере, это должно показаться интересным.
Итак, node-specificity предоставляет две команды. Одна из них используется для процессинга CSS файлов и создания профайлов. Вторая — для чтения и «исследования» этих самых профайлов. Давайте разберем на примере. У меня есть несколько версий CSS файлов моего блога. Последняя версия — v8.css.
Создадим профайлы для этих файлов:
$ node-specificity parse v1.css --label=v1 --output=v1.json
...
$ node-specificity parse v8.css --label=v8 --output=v8.json
Мы только что создали профайлы для каждого отдельного CSS файла, поскольку мы хотим посмотреть на изменения во времени. Если у вас на сайте используется больше, чем один файл CSS, то вам необходимо создавать профайл для всех файлов, например, так:
$ node-specificity parse main.css print.css --label=2014-12-23 --output=20141223.json
Метка (label) используется как имя профайла в отчетах. После того как мы создали профайлы, мы можем запустить отчет. Давайте посмотрим на отчет «server»:
$ node-specificity explore v*.json --report=server
Server is running on http://localhost:4000/
Press Ctrl + C to stop it.
Откройте браузер и перейдите по адресу «http://localhost:4000/». Сейчас вы должны увидеть страницу с различными элементами управления и странным графиком. Это график распределения специфичности (см. заглавную картинку). Для каждой специфичности (кортеж) вы видите количество селекторов этой специфичности в каждом профайле.
Другие графики: количество селекторов в файлах и профайлах; доля тех, что содержат
!important директиву; среднее значение и медиана специфичности.Кроме того, вы можете просматривать все эти графики для каждого профайла в отдельности. Для этого необходимо выбрать нужный профайл из списка слева. Например, ниже представлен график распределения специфичности для профайла v8.json.
Отчет «server» представляет из себя довольно мощный инструмент. Имейте в виду, что выше были продемонстрированы изображения для профайлов, состоящих из одного небольшого CSS файла. Если у вас несколько файлов в профайле, то графики заиграют интереснее.
Есть и другие типы отчетов. Возьмем, например, «inspect», который используется в качестве значения по умолчанию. Если вы выполните в терминале
node-specificity explore v8.json, то на экране для каждого профайла будет распечатан список всех селекторов, таблица со значениями специфичности и график распределения специфичности, очень похожий на тот, который вы могли видеть выше.Отчеты могут принимать дополнительные параметры командной строки. Их несколько. Например,
--no-inspect-selectors (см. картинку выше) отключает вывод списка селекторов.На этом все. Happy exploring!
