В России обсуждают вопросы о создании мега Национального биометрического Центра с объемом базы данных 100 – 150 млн. записей. А в Госдумму уже внесен проект закона об обязательной биометрической регистрации. Так как работать все это, теоретически, обязано на патриотическом оборудовании, то есть из соображений защиты информации желательно и мозги и оборудование географически должно располагаться внутри страны, я думаю, вам будет интересно ознакомится с тем, что же хорошего, теоретически, у нас может с этим получиться.
Совсем недавно завершилось двухлетнее тестирование pVTE-12 (Fingerprint Vendor Technology Evaluation 2012) при национальном институте стандартов США (НИСТ).

Цель тестирования – оценка реальных возможностей систем идентификации по отпечаткам пальцев на сегодняшний день. Это самое крупное тестирование (крупные базы и типы данных), которое длилось в течение двух лет.
Тестовые данные поделены на три группы:
А – отпечатки двух указательных пальцев без сегментации объемом 1.6 млн. записей.
B – отпечатки десяти пальцев, в группе 4+4+2 (это съем четырех пальцев + большого с каждой руки) с сегментацией. Объем базы 3 млн. записей.
С – прокатные и контактные отпечатки десяти пальцев в группе 4+4+1+1 с сегментацией. Объем базы 5 млн. записей.
Задача: за ограниченное количество времени осуществить поиск информации в режиме «один ко многим». Компании, не уложившиеся во временное ограничение снимались с теста. Потому все компании подготовили новые скоростные алгоритмы идентификации.
В протоколе фиксировалось не только точность сравнения но и скорость. Поэтому для тестирования компании предоставляли два варианта алгоритма: быстрый и более медленный.
Из 22 двух компаний только 18 смогли пройти хотя бы один тест. Это практически все известные в мире биометрические компании (NEC, 3M, Safran и пр.) а так же две российские – Сонда, Папиллон и еще несколько новых менее известных.
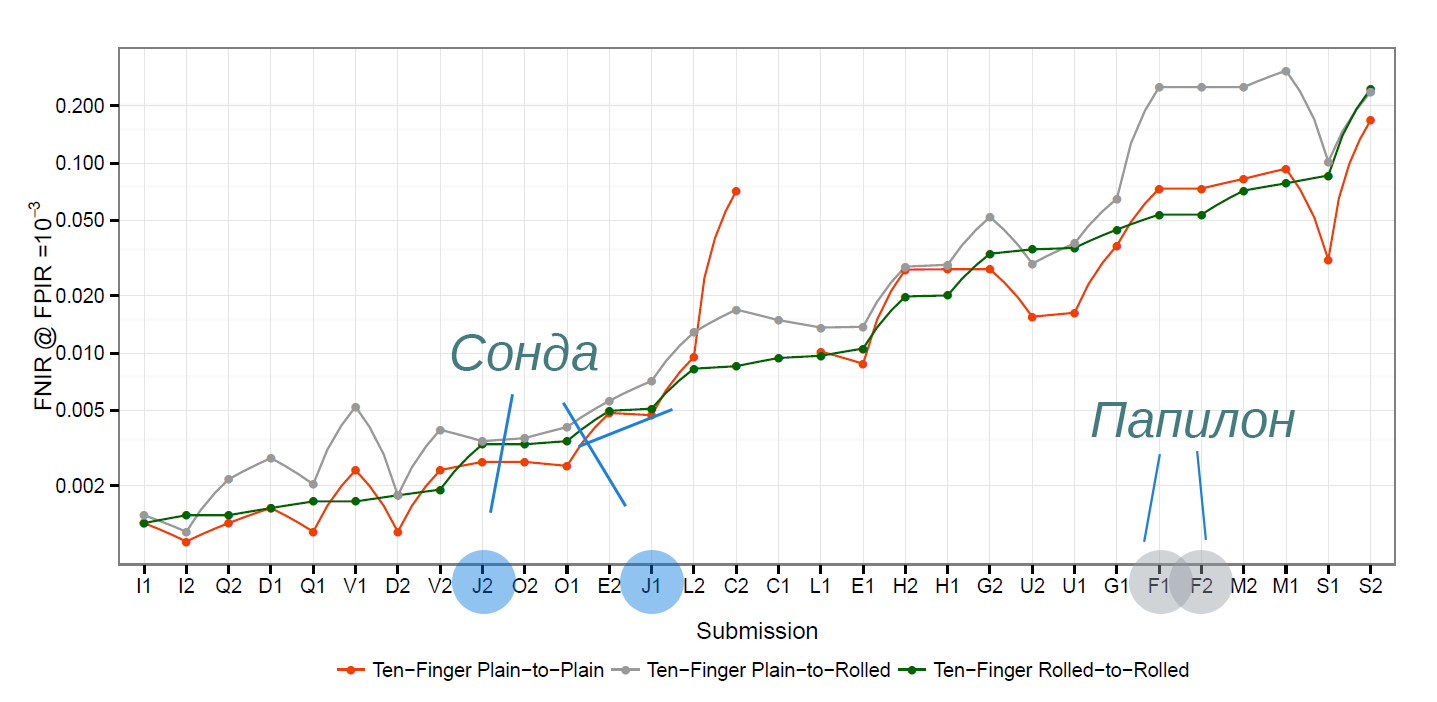
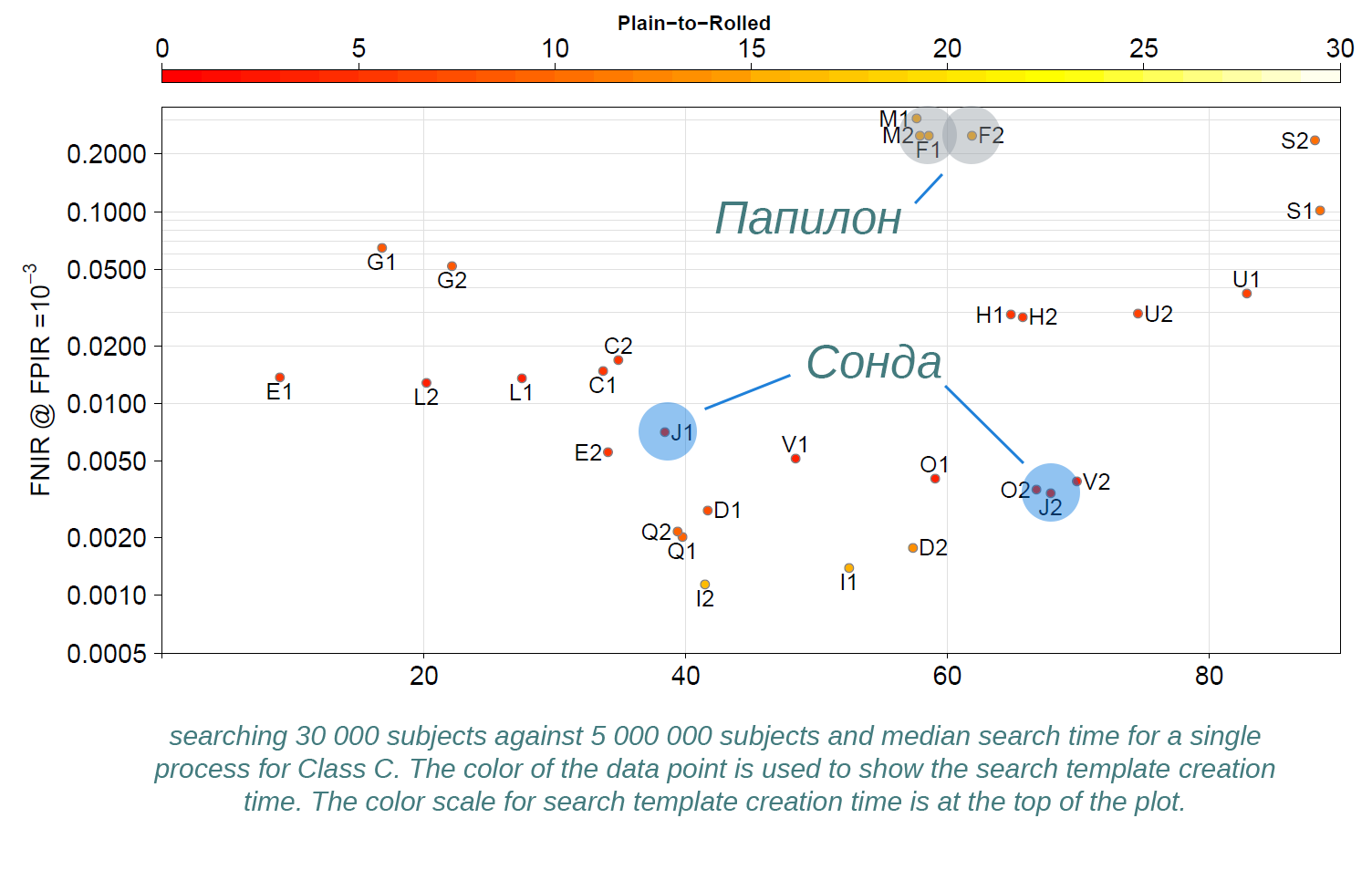
Самый важный тест — это тест «С» на базе 5 млн. записей. По точности первые три места заняли гиганты — NEC (Япония), Morpho/Safran (Франция) 3M Cogent (США).
А наша компания Сонда (суровая Челябинская!) в режиме поиска контактных отпечатков по прокатным заняла 4-ое место!
В режиме поиска контактных по контактным и прокатных по прокатным — 5-ое.
Вероятность ошибки на уровне 0.3 % и отличается от группы лидеров где-то в два раза, однако по скорости сравнения и по длине математического кода Сонда превосходит лидеров.
Что касается Папилона, то очень жаль. По видимому, ребята что-то сделали не так с алгоритмами и вероятность ошибки от группы лидеров отличается в 40-100 раз и составляет от 5 до 20%, что на практике конечно же, недопустимо.
По результатам тестов НИСТ выделил пять компаний, которые предоставили оптимальные алгоритмы с учетом трех факторов: точность идентификации, скорость сравнения и требуемые ресурсы: Сонда (Россия), Innovatrics (Словакия), Morpho (Франция), IDSolutions (США) и AA Technology (Китай).
В след за этим событием, хотелось быть получить комментарий о результатах теста у нашего местного специалиста по биометрии ZlodeiBaal.
Полный отчет о тестировании: nvlpubs.nist.gov/nistpubs/ir/2014/NIST.IR.8034.pdf
Совсем недавно завершилось двухлетнее тестирование pVTE-12 (Fingerprint Vendor Technology Evaluation 2012) при национальном институте стандартов США (НИСТ).
Цель тестирования – оценка реальных возможностей систем идентификации по отпечаткам пальцев на сегодняшний день. Это самое крупное тестирование (крупные базы и типы данных), которое длилось в течение двух лет.
Тестовые данные поделены на три группы:
А – отпечатки двух указательных пальцев без сегментации объемом 1.6 млн. записей.
B – отпечатки десяти пальцев, в группе 4+4+2 (это съем четырех пальцев + большого с каждой руки) с сегментацией. Объем базы 3 млн. записей.
С – прокатные и контактные отпечатки десяти пальцев в группе 4+4+1+1 с сегментацией. Объем базы 5 млн. записей.
Задача: за ограниченное количество времени осуществить поиск информации в режиме «один ко многим». Компании, не уложившиеся во временное ограничение снимались с теста. Потому все компании подготовили новые скоростные алгоритмы идентификации.
В протоколе фиксировалось не только точность сравнения но и скорость. Поэтому для тестирования компании предоставляли два варианта алгоритма: быстрый и более медленный.
Из 22 двух компаний только 18 смогли пройти хотя бы один тест. Это практически все известные в мире биометрические компании (NEC, 3M, Safran и пр.) а так же две российские – Сонда, Папиллон и еще несколько новых менее известных.
Код компании Наименование Тесты
C afis team A, B, C
D 3M Cogent A, B, C
E Neurotechnology A, B, C
F Papillon A, B, C
G Dermalog A, B, C
H Hisign Bio-Info Institute A, B, C
I NEC A, B, C
J Sonda A, B, C
K Tiger IT A
L Innovatrics A, B, C
M SPEX A, B, C
O ID Solutions A, B, C
P id3 A
Q Morpho A, B, C
S Decatur Industries A, B, C
T BIO-key A
U Aware A, B, C
V AA Technology A, B, C
Самый важный тест — это тест «С» на базе 5 млн. записей. По точности первые три места заняли гиганты — NEC (Япония), Morpho/Safran (Франция) 3M Cogent (США).
А наша компания Сонда (суровая Челябинская!) в режиме поиска контактных отпечатков по прокатным заняла 4-ое место!
В режиме поиска контактных по контактным и прокатных по прокатным — 5-ое.
Вероятность ошибки на уровне 0.3 % и отличается от группы лидеров где-то в два раза, однако по скорости сравнения и по длине математического кода Сонда превосходит лидеров.
Что касается Папилона, то очень жаль. По видимому, ребята что-то сделали не так с алгоритмами и вероятность ошибки от группы лидеров отличается в 40-100 раз и составляет от 5 до 20%, что на практике конечно же, недопустимо.
По результатам тестов НИСТ выделил пять компаний, которые предоставили оптимальные алгоритмы с учетом трех факторов: точность идентификации, скорость сравнения и требуемые ресурсы: Сонда (Россия), Innovatrics (Словакия), Morpho (Франция), IDSolutions (США) и AA Technology (Китай).
В след за этим событием, хотелось быть получить комментарий о результатах теста у нашего местного специалиста по биометрии ZlodeiBaal.
Полный отчет о тестировании: nvlpubs.nist.gov/nistpubs/ir/2014/NIST.IR.8034.pdf
