 Сравнительно недавно была статья «Полуавтоматическая регистрация юнит-тестов на чистом С», в которой автор продемонстрировал решение задачи с использованием счётчиков из Boost. Следуя этому же принципу, была предпринята (успешная) попытка повторить данный опыт уже без использования Boost из соображения нелогичности наличия в проекте на C зависимости от Boost, да ещё и в таком небольшом объёме. При этом в тестах присутствовали вспомогательные директивы препроцессора в большом количестве. И всё бы так и осталось, но практически на завершающей стадии был найден альтернативный способ регистрации, который позволяет полностью избавится от дополнительных действий. Это C89-решение для регистрации тестов и чуть более требовательное к системе сборке решение для регистрации наборов тестов.
Сравнительно недавно была статья «Полуавтоматическая регистрация юнит-тестов на чистом С», в которой автор продемонстрировал решение задачи с использованием счётчиков из Boost. Следуя этому же принципу, была предпринята (успешная) попытка повторить данный опыт уже без использования Boost из соображения нелогичности наличия в проекте на C зависимости от Boost, да ещё и в таком небольшом объёме. При этом в тестах присутствовали вспомогательные директивы препроцессора в большом количестве. И всё бы так и осталось, но практически на завершающей стадии был найден альтернативный способ регистрации, который позволяет полностью избавится от дополнительных действий. Это C89-решение для регистрации тестов и чуть более требовательное к системе сборке решение для регистрации наборов тестов.Мотивация всего этого простая и понятная, но для полноты стоит её кратко обозначить. В отсутствии авто-регистрации приходится иметь дело либо с набором/вставкой повторяющегося кода, либо с внешними по отношению к компилятору генераторами. Первое делать неохотно плюс само это занятие подвержено ошибкам, второе добавляет лишние зависимости и усложняет процесс сборки. Идея же использовать C++ в тестах только ради этой возможности, когда всё остальное написано на C, вызывает чувство стрельбы из пушки по воробьям. К всему этому, в принципе, интересно решить задачу на том же уровне, на котором она возникла.
Определим конечную цель как нечто похожее на код ниже с дополнительным условием, что имена тестов не повторяются нигде кроме места их определения, т.е. они набираются один и только один раз и далее не копируются никаким автогенератором.
TEST(test1) { /* Do the test. */ }
TEST(test2) { /* Do the test. */ }
После небольшого отступления для внесения определённости в терминологию, можно будет приступить к поиску решения.
Терминология и предполагаемая структура тестов
Различные тестовые фреймворки несогласовано используют слова для обозначения отдельных тестов или их групп. Поэтому определим некоторые слова явно, а заодно покажем их значение на примере довольно распространённой структуры тестов.
Под коллекцией тестов («suite») будет пониматься группа наборов тестов («fixture»). Это наибольшая структурная единица иерархии. Наборы в свою очередь группируют тесты внутри коллекции. Тесты уже сами по себе. Количество элементов каждого типа произвольное.
Это же графически:
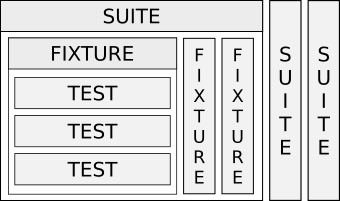
Каждый больший уровень объединяет элементы меньших и опционально добавляет процедуры подготовки («setup») и завершения («teardown») тестов.
Регистрация тестов в наборах
Never let your sense of morals prevent you from doing what is right.
— ISAAC ASIMOV, Foundation
Отдельные тесты добавляются чаще чем целые наборы, поэтому и авто-регистрация для них более актуальна. Также все они располагаются в пределах одной единицы трансляции, что упрощает решение задачи.
Итак, необходимо организовать хранилище списка тестов средствами языка, не используя при этом препроцессор как главный управляющий элемент. Отказ от препроцессора означает, что мы остаёмся без явных счётчиков. Но наличие счётчика практически обязательно, если необходимо уникально идентифицировать тесты и, вообще, как-то к ним обращаться, а не только объявлять. При этом под рукой всегда есть встроенный макрос
__LINE__, на надо ещё придумать как его можно применить в данной ситуации. Есть и ещё одно ограничение: какие-то явные присваивания элементам глобального массива на подобиеtest_type tests[];
static void test(void) { /* Do the test. */ }
tests[__LINE__] = &test;
не подходят, так как вне функций такие операции просто не поддерживаются на уровне языка. Исходная ситуация выглядит не очень радужно:
- Нет возможности хранить ни промежуточное ни конечное состояния.
- Нет возможности определить несвязные элементы, а потом собрать их вместе.
- Как результат, отсутствует возможность определить связную структуру (в основном массив, но список тоже подойдёт, был бы способ), по причине невозможности сослаться на предыдущую сущность.
Но не всё так безнадёжно, как может показаться. Представим идеальный вариант, как будто у нас есть то, чего не хватает. В этом случае код после разворачивания вспомогательных макросов мог бы выглядеть примерно следующим образом:
MagicDataStructure MDS;
static void test1(void) { /* Do the test. */ }
MDS[__LINE__] = &test1;
static void test2(void) { /* Do the test. */ }
MDS[__LINE__] = &test2;
static void fixture(void)
{
int i;
for (i = 0; i < MDS.length; ++i) {
MDS.func[i]();
}
}
Дело за малым: реализовать «магическую» структуру, которая, между прочим, подозрительно похожа на массив предопределённого размера. Имеет смысл подумать, как бы мы работали будь это массивом на самом деле:
- Определили бы массив проинициализировав все элементы
NULL. - Присвоили бы значения отдельным элементам.
- Обошли бы весь массив и вызвали каждый не-
NULLэлемент.
Данный набор операций — это всё, что нам нужно и не выглядит слишком уж нереальным, возможно, массивы действительно здесь пригодятся. По определению, массив — это набор однотипных элементов. Обычно это какая-то одна сущность с поддержкой операции индексирования, но имеет смысл рассматривать тот же массив как группу из отдельных элементов. Скажем, то ли это
int arr[4];
то ли
int arr0, arr1, arr2, arr3;
На данный момент и в свете наличия упоминания макроса
__LINE__ выше, уже должно быть понятно куда клонит автор. Осталось понять, как можно реализовать псевдо-массив с поддержкой присваивания на этапе компиляции. Это представляется занятным упражнением, поэтому стоит ещё немного повременить с демонстрацией готового решения и задаться следующими вопросами:- Какая сущность в C может появляться больше одного раза и не вызвать при этом ошибку компиляции?
- Что может трактоваться компилятором по разному в зависимости от контекста?
Подумайте о заголовочных файлах. Ведь то, что в них, обычно присутствует ещё где-то в коде. Например:
/* file.h */
int a;
/* file.c */
#include "file.h"
int a = 4;
/* ... */
При этом всё прекрасно работает. Вот более близкий к задаче пример:
static void run(void);
int main(int argc, char *argv[])
{
run();
return 0;
}
static void run(void) { /* ... */ }
Вполне себе заурядный код, который можно немного расширить для получения желаемой функциональности:
#include <stdio.h>
static void (*run_func)(void);
int main(int argc, char *argv[])
{
if (run_func) run_func();
return 0;
}
static void run(void) { puts("Run!"); }
static void (*run_func)(void) = &run;
Читателю предлагается самостоятельно убедится, что изменение порядка или комментирование последнего упоминания
run_func согласуется с ожиданиями, т.е. если run_func не переприсвоили, то единственный элемент «одно-элементного массива» (run_func) равен NULL, в противном случае он указывает на функцию run(). Отсутствие зависимости от порядке важное свойство, которое позволяет скрыть всю «магию» в заголовочном файле.Из примера выше легко сделать макрос для авторегистрации, который объявляет функцию и сохраняет указатель на неё в переменной пронумерованной с помощью значения макроса
__LINE__. Кроме самого макроса необходимо перечислить все возможные имена переменных-указателей и вызывать их по одному. Вот практически полное решение не считая наличие «лишнего» кода, который должен быть скрыт в заголовочном файле, но это уже детали:/* test.h */
#define CAT(X, Y) CAT_(X, Y)
#define CAT_(X, Y) X##Y
typedef void test_func_type(void);
#define TEST(name) \
static test_func_type CAT(name, __LINE__); \
static test_func_type *CAT(test_at_, __LINE__) = &CAT(name, __LINE__); \
static void CAT(name, __LINE__)(void)
/* test.c */
#include "test.h"
#include <stdio.h>
TEST(A) { puts("Test1"); }
TEST(B) { puts("Test2"); }
TEST(C) { puts("Test3"); }
typedef test_func_type *test_func_pointer;
static test_func_pointer test_at_1, test_at_2, test_at_3, test_at_4, test_at_5, test_at_6;
int main(int argc, char *argv[])
{
/* Это упрошённая версия для наглядности, на самом деле указатели стоит
* поместить в массив. */
if (test_at_1) test_at_1();
if (test_at_2) test_at_2();
if (test_at_3) test_at_3();
if (test_at_4) test_at_4();
if (test_at_5) test_at_5();
if (test_at_6) test_at_6();
return 0;
}
Для ясности может быть полезно посмотреть результат макро-подстановки, из которой вытекает факт невозможности размещения больше одного теста в строке, что, впрочем, более чем приемлемо.
static test_func_type A4; static test_func_type *test_at_4 = &A4; static void A4(void) { puts("Test1"); }
static test_func_type B5; static test_func_type *test_at_5 = &B5; static void B5(void) { puts("Test2"); }
static test_func_type C6; static test_func_type *test_at_6 = &C6; static void C6(void) { puts("Test3"); }
Ссылка на полную реализацию будет приведена ниже.
Почему это работает
Теперь пришла пора разобраться в том, что тут происходит, более детально и ответить на вопрос, почему это работает.
Если вспомнить пример с заголовками, то можно выделить несколько возможных варианта того, как члены данных могут быть представлены в коде:
int data = 0; /* (1) */
extern int data; /* (2) */
int data; /* (3) */
(1) однозначно является определением (а значит и объявлением тоже) из-за присутствия инициализатора.(2) является исключительно объявлением.(3) (наш случай) является объявлением и, возможно, определением. Отсутствие ключевого слова extern и инициализатора не оставляет компилятору иного выбора кроме как отложить принятие решения на счёт того, чем же является этот оператор («statement»). Именно это «колебание» компилятора и эксплуатируется для эмуляции авто-регистрации.На всякий случай несколько примеров с комментариями, чтобы окончательно прояснить ситуацию:
int data1; /* Определение, так как больше нигде не встречается. */
int data2 = 1; /* Определение, из-за инициализатора. */
int data2; /* Объявление, так как определение уже было. */
int data3; /* Изначально, неизвестно, но после обработки следующей строки
* становится понятно, что объявление. */
int data3 = 1; /* Определение, из-за инициализатора. */
/* Ключевое слово static ничего в этом плане не меняет. */
static int data4; /* Изначально, неизвестно, но после обработки следующей
* строки становится понятно, что объявление. */
static int data4 = 1; /* Определение, из-за инициализатора. */
static int data4; /* Объявление, так как определение уже было. */
int data5; /* Неизвестно, но в отсутствии определений считается определением. */
int data5; /* Аналогично, эти два "неизвестно" считаются за одно. */
int data6 = 0; /* Определение, из-за инициализатора. */
int data6 = 0; /* Ошибка, повторное определение. */
Для нас важными являются два случая:
- Есть только объявления. В этом случае переменная инициализируется нулями, по которым можно определить отсутствие теста в соответствующей строке.
- Есть минимум одно объявление и ровно одно определение. В соответствующую переменную заносится адрес функции с тестом.
Вот, собственно, и всё, что необходимо для реализации требуемых операций и получения рабочей автоматической регистрации. Эта двойственность некоторых операторов в тексте позволяет развернуть массив по-элементно и «присвоить» значения части массива.
Особенности и недостатки
Понятно, что если мы не хотим вставлять макрос в конце каждого файла с тестами, который бы служил маркером последней строки, то необходимо изначально закладываться на какое-то максимальное количество строк. Не самый лучший вариант, но и не самый худший. Скажем, один тестовый файл вряд ли будет вмещать в себя более тысячи строк и можно остановить свой выбор на этой верхней границе. Тут есть один не очень приятным момент: если в таком случае тесты будут определены на строке с номером большим 1000, то они будут лежать мёртвым грузом и никогда не вызовутся. К счастью, есть простой вариант «решения»: достаточно компилировать тесты с флагом
-Werror (менее жёсткий вариант: с -Werror=unused-function) и подобные файлы не скомпилируются. (UPD2: в комментариях подсказали как решить этот вопрос проще и с автоматическим прерыванием компиляции используя STATIC_ASSERT. Достаточно в каждый макрос TEST вставить проверку на допустимое значение __LINE__.)Достаточность подхода с фиксированным массивом в общем случае не единственная причина, по которой лучше заранее зафиксировать максимальное количество строк. Если этого не сделать, то соответствующие объявления (в месте вызова тестов) необходимо генерировать во время компиляции, что может её ощутимо замедлить (это не догадка, а результат попыток). Тут проще не усложнять, выгода от получения возможности компилировать файлы произвольного размера, кажется, не стоит того.
В примере с макросом
TEST() выше видно использование указателя на функцию, это всего лишь одна запись о тесте, но скорее всего захочется добавить больше. Неправильный способ это сделать: добавлять параллельные псевдо-массивы. Это только увеличит время компиляции. Правильный способ: использовать структуру, в этом случае добавление новых полей обходится практически бесплатно.Для реальной обработки (не копированием кода) элементов псевдо-массива необходимо сформировать настоящий массив. Не лучшим решением будет помещать в этот массив значения тех же указателей на функции (или копировать структуры с информацией о тестах), так как это сделает инициализатор не константным. А вот помещение указателей на указатели позволит сделать массив статическим, что освободит компилятор от необходимости генерировать код для присваивания значений на стеке во время исполнения, а также сократит время компиляции.
Изначально это решение родилось для реализации прозрачной регистрации
setup()/teardown() функций и только потом было применено к самим тестам. В принципе это годится для любой функциональности, которую можно переопределить. Достаточно вставить объявление указателя и предоставить макрос для его переопределения, если макрос не использовался, указатель будет равным нулю, в противном случае — определённому пользователем значению.Сообщения компилятора об ошибках верхнего уровня в тестах могут удивить своим объёмом, но это произойдёт в довольно редких случаях отсутствия завершающей точки с запятой и подобных синтаксических ошибках.
Наконец можно оценить результат стараний:
Набор тестов до: |
Набор тестов после: |
Регистрация наборов тестов в коллекциях
A trick is a clever idea that can be used once, while a technique is a trick that can be used at least twice.
— D. KNUTH, The Art Of Computer Programming 4A
Близкая в чем-то к предыдущей задача, но есть пара существенных отличий:
- Интересные символы (функции/данные) определены в различных единицах компиляции.
- И, как следствие, отсутствует счётчик аналогичный
__LINE__.
В силу первого пункта трюк из предыдущей секции в чистом виде тут не сработает, но основная идея останется прежней, в то время как средства её реализации немного поменяются.
Как упоминалось вначале, в этой части выдвигаются некоторые дополнительное требование к среде, а именно к системе сборки, которая должна быть в состоянии присваивать файлам идентификаторы в диапазоне
[0, N), где N представляет собой максимальное количество наборов тестов. Опять же, граница сверху, но, скажем, сто наборов в каждой коллекции тестов должно хватить многим.Если прошлый раз всю «грязную работу» за нас выполнял компилятор, то на этот раз настал черёд поработать компоновщику (он же «linker»). В каждой единице трансляции необходимо определять точку входа, используя тот самый идентификатор файла, а в главном файле коллекции тестов проверять символы на наличие и вызывать их.
Одним из возможных вариантов является использование «слабых символов». В этом случае функции почти везде определяются как обычно, но в главном файле они помечаются атрибутом
weak (как-то так: __attribute__((weak))). Очевидным недостатком является требование наличия поддержки слабых символов со стороны компилятора и компоновщика.Если немного подумать о структуре слабых символов, то становится заметна их схожесть с указателями на функции: неопределённые слабые символы равны нулю. Получается, что можно и вовсе обойтись без них: достаточно определить указатели на функции как и ранее, но без ключевого слова
static. Использование указателей в явной форме приносит также дополнительную выгоду в виде отсутствия автоматически сгенерированного имени в списке фреймов стека.На этом первое отличие от наборов тестов можно считать сведенным к уже известному решению. Остаётся определение отношения порядка между единицами трансляции. В самом файле недостаточно информации для выполнения этой задачи, поэтому необходима информация извне. Здесь для каждой системы сборки будут свои детали реализации, ниже же будет приведён пример для GNU/Make.
Определение самого порядка достаточно тривиально, пусть это будет позиция имени файла в отсортированном списке всех файлов, составляющих коллекцию тестов. Не стоит переживать о вспомогательных файлах без тестов, они не помешают, как максимум, создадут пропуски в нумерации, что несущественно. Передаваться же эта информация будет через макро-определение с помощью флага компилятора (
-D в данном случае).Собственно, функция определения идентификатора:
pos = $(strip $(eval T := ) \
$(eval i := 0) \
$(foreach elem, $1, \
$(if $(filter $2,$(elem)), \
$(eval i := $(words $T)), \
$(eval T := $T $(elem)))) \
$i)
Первым аргументом ожидается список всех имён файлов, а вторым имя текущего файла. Возвращает индекс. Функция не самая тривиальная на вид, но работу свою она выполняет исправно.
Добавление идентификатора
TESTID (здесь $(OBJ) хранит список объектный файлов):%.o: %.c
$(CC) -DTESTID=$(call pos, $(OBJ), $@) -c -o $@ $<
На этом практически все трудности преодолены и остаётся только использовать идентификатор в коде, например, так:
#define FIXTURE() \
static void fixture_body(void); \
void (*CAT(fixture_number_, TESTID))(void) = &fixture_body; \
static void fixture_body(void)
В главном файле коллекции тестов должны быть соответствующие объявления и их обход.
Оставшиеся трудности
При увеличении количества файлов выше установленного предела, некоторые из них могут «выпасть» из нашего поля зрения как это могло случится с тестами. На этот раз для решения потребуется дополнительная проверка времени компиляции. При заранее известном количестве файлов в коллекции легко проверить не будут ли они лишними. По сути, достаточно предоставить каждой единице трансляции доступ к этой информации с помощью ещё одного макроса:
... -DMAXTESTID=$(words $(OBJ)) ...
Останется только добавить проверку наличия достаточного количества объявлений с помощью чего-то вроде:
#define STATIC_ASSERT(msg, cond) \
typedef int msg[(cond) ? 1 : -1]; \
/* Fake use to suppress "Unused local variable" warning. */ \
enum { CAT(msg, _use) = (size_t)(msg *)0 }
Присутствует несколько менее очевидная проблема конфликта (двойного определения) функций при добавлении/удалении файлов наборов тестов. Подобные изменения вызывают смещение индексов и требуют перекомпиляции всех файлов, которые были этим затронуты. Тут стоит вспомнить проверку дат модификации файлов системами сборки и обновление даты каталога при изменении его состава, т.е. фактически к каждому компилируемому файлу необходимо добавить зависимость от директории, в которой он расположен.
В итоге, правило компиляции файла с тестами принимает подобный вид:
%.o: %.c $(dir %.c)/.
$(CC) -DTESTID=$(call pos, $(OBJ), $@) -DMAXTESTID=$(words $(OBJ)) -c -o $@ $<
Собрав всё вместе, можно наблюдать следующее преображение определения коллекции тестов:
Коллекция тестов до: |
Коллекция тестов после: |
Дополнительные оптимизации
Необходимость в периодической перекомпиляции и некоторое замедление обработки каждого файла заставляют задуматься о способах компенсации этих издержек. Напомним некоторые из имеющихся возможностей.
Предкомпилированный заголовок. Раз сложный код долго обрабатывается компилятором, будет логично подготовить результат обработки один раз и переиспользовать его.
Использование ccache для ускорения повторной компиляции. Хорошая идея сама по себе, например, позволяет переключаться между ветками репозиториев неограниченное количество раз и не ждать полной перекомпиляции: суммарное время будет определятся в первую очередь скоростью вытаскивания данных из кеша.
-pipe флаг компилятора (если поддерживается). Уменьшит количество файловых операций за счёт использования дополнительной оперативной памяти.
Отключение оптимизации и исключение отладочной информации. В обычной ситуации это не должно никак сказаться на работе тестов, кроме некоторого ускорения процесса компиляции.
К чему это всё здесь? Возможное ухудшение производительности компиляции упоминалось выше несколько раз и хочется предоставить средства борьбы с этим, а также несколько сгладить эффект парой замечаний:
- Падение производительности в первую очередь заметно при полной пересборке тестов и в штатной ситуации не настолько критично.
- До применения описанного выше подхода к тестам, время полной пересборки тестов (с последующим запуском) в случае автора составляло 6,5 сек. После — увеличилось до 13 сек., но оптимизации как кода объявления тестов так и процесса их сборки исправили ситуацию, улучшив показатель до 5,5 сек. Ускорение процесса сборки прежней версии тестов улучшило время до 5,7 сек., что (на удивление) даже немного больше времени компиляции текущего варианта.
Ссылки
Изначально для написания тестов использовался seatest, в котором устраивало практически всё, но недоставало авто-регистрации. По результатам вышеописанной деятельности на основе seatest был сделан stic (там используется немного C99, но это не является обязательным в общем случае), добавляющий недостающее с точки зрения автора. Именно там можно посмотреть опущенные здесь детали реализации, а именно в заголовочном файле stic.h. Избранные промежуточные зарисовки доступны в отдельном репозитории. Пример интеграции можно найти вот в этом Makefile (для его понимания требуется знание синтаксиса).
Итоги
Судя по списку в Wikipedia, stic может быть первой успешной попыткой реализации авто-регистрации средствами C (естественно, с оглядкой на описанные ограничения). Все проверенные альтернативы включают внешние генераторы списка тестов (UPD: в комментариях подсказывают о способе регистрации тестов близком к реализации вызова статических конструкторов в C++, что, впрочем, требует наличия соответствующей поддержки со стороны компилятора и компоновщика, но сам подход определённо заслуживает внимания). Достоинство данного способа не только в отсутствии дополнительных зависимостей, но ещё и универсальности (компилятор не сделает ошибку из-за
#ifdef, в отличии от стороннего скрипта) и относительной простоте сбора дополнительных данных о тестах. Например, было довольно просто добавить предикат запуска теста в виде:TEST(os_independent)
{
/* ... */
}
TEST(unix_only, IF(not_windows))
{
/* ... */
}
Пусть каждый решает для себя сам, но автору однозначно понравился способ, процесс и результат, который теперь заменил собой seatest, упростил процесс добавления тестов и сократил объём тестов аж на 3911 строк, что составляет примерно 16% от их прежнего размера.
