Это третья часть эксперимента по созданию системы распознания мошеннических платежей (antifraud-система). Целью является создание доступного (в плане стоимости разработки и владения) antifraud-сервиса, который позволит сразу нескольким участникам проведения online-платежей – мерчантам, агрегаторам, платежным системам, банкам – снизить риски проведения мошеннических платежей (fraud) через их площадки.
В прошлой части мы сфокусировали внимание на функциональных и нефункциональных требованиях к антифрод-сервису. В этой части статьи рассмотрим программную архитектуру сервиса, его модульную структуру и ключевые детали реализации такого сервиса.
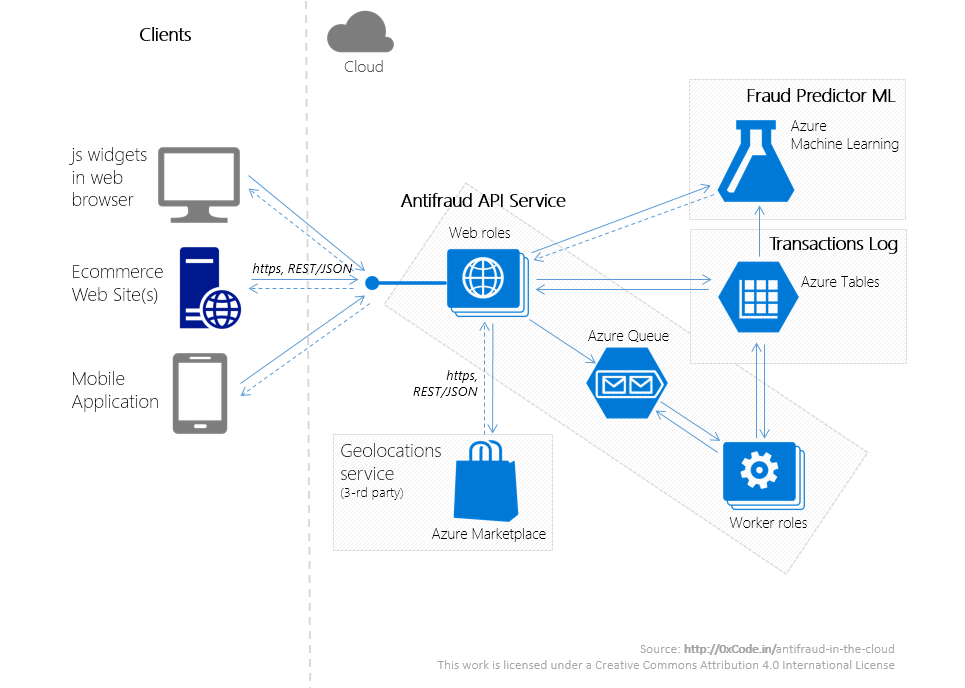
Инфраструктура
Сервис представляет собой несколько приложений, работающих в Microsoft Azure. Размещение с использованием облачной платформы вместо on-premise размещения не только позволит при незначительных временных затратах разработать сервис, отвечающий всем требованиям, перечисленным во второй части в разделе «Нефункциональные требования -> Атрибуты качества», но и существенно снизит первоначальные финансовые затраты на аппаратное и программное обеспечение.
Антифрод-сервис состоит из следующих систем:
Кроме того, у сервиса имеются многочисленные программные клиенты (Clients), представляющие собой web-приложения мерчантов, либо js-виджеты, вызывающие REST-сервисы Antifraud API Service.
Принципиальная схема взаимодействия этих систем проиллюстрирована выше.
Инфраструктура, наряду с предметной областью и законодательными актами, потенциально несет в себе большое количество ограничений, который должны быть учтены на архитектурном уровне. И если доменные и юридические ограничения мы уже обсудили в предыдущих частях статьи, то преимущества и ограничения, связанные с выбором облачной платформы Microsoft Azure обсудим ниже.
Используемые антифрод-системой сервисы Azure – Cloud service для web-/worker-ролей, Azure Table, Azure Queue, Azure ML, etc. – кроме почти нулевых начальных финансовых затрат на инфрастуктуру дают следующие преимущества из коробки:
В качестве бонусов я рассматриваю:
Но воспользоваться всеми этими преимуществами получилось только благодаря «заточке» архитектуры антифрод-сервиса под облако, так:
Кроме того, антифрод-сервис – near real-time система, поэтому при реализации антифрод-сервиса:
Необходимо также держать в голове, что у всех облачных сервисов есть ограничения:
Взаимодействие между компонентами сервиса
Для мерчанта сервис представляет собой REST-сервис, с которым можно взаимодействовать по протоколу https – Antifraud API Service. Antifraud API Service работает в кластере, состоящем из нескольких stateless web-ролей (web-роль в Azure – слой приложения, выполняющий роль веб-приложения).
Следующая диаграмма последовательностей описывает возможные взаимодействия мерчанта со всеми подсистемами антифрод-сервиса.

Рассмотрим каждый из шагов подробнее.
Запрос от мерчанта поступает на Контроллер (в терминах MVC) (Шаг 1). После чего полученная Модель (в терминах MVC) проходит:
Эвристики, глобальные фильтры и признаки валидности платежных данных были подробно обсуждены в предыдущей части статьи.
На шаге 2 объект предметной области трансформируется в DTO-объект, который:
Для улучшения качества работы алгоритма предсказания клиентам доступен API уточнения результатов транзакции. Так, если реальный результат проведения платежа отличался от значения, которое вернул наш антифрод-сервис, мерчант может сообщить об этом, отправив запрос на уточнение результатов транзакций (шаг 9). Такие запросы:
Из очереди запросы забираются одним из роботов, представляющих собой stateless worker-роль (worker-роль – в Azure это слой приложения, выполняющий роль обработчика).
Как информация о транзакциях, так и дополнительная информация по ним (в основном статистика) сохраняется в лог транзакций – долговременное хранилище на основе Azure Table (сервис, представляющий собой отказоустойчивое NoSQL-хранилище (key-value)).
Лог транзакция представляет собой 2 таблицы:
На шагах 7, 8 проходит переобучение модели. Обучающая выборка представляет собой данные из лога транзакций, т.к. в хранилище лога содержится последняя информация по платежам и их результатам. Переобучение может происходить по расписанию, по появлению фиксированного значения новых записей в логе транзакций, по преодолению определенного порога неверных предсказаний.
Подробнее вопроса обучения модели обнаружения мошеннических платежей коснемся в следующей заключительной части.
Заключение 3-ей части
В этой части мы обсудили архитектуру антифрод-сервиса, выделили в нем функциональные части – Antifraud API Service, Fraud Predictor ML, Transactions Log, определили их зоны ответственности, а также способы взаимодействия между собой.
При правильном подходе к архитектуре развертывание антифрод-сервиса в облаке Microsoft Azure позволит существенно сократить первоначальные финансовые затраты на инфраструктуру, а также уменьшить время, затраченное на вопросы, связанные с масштабируемостью системы, надежным хранением данных и высокой доступностью сервисов.
В следующей заключительной части мы продолжим создавать антифрод-сервис, на порядок более дешевый по стоимости разработки и владения, чем его аналоги – разработаем сервис Fraud Predictor ML, который базируется на сервисе Azure Machine Learning и является аналитическим ядром антифрод-сервиса.
Полезные источники
[1] Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications, MSDN.
В прошлой части мы сфокусировали внимание на функциональных и нефункциональных требованиях к антифрод-сервису. В этой части статьи рассмотрим программную архитектуру сервиса, его модульную структуру и ключевые детали реализации такого сервиса.
Инфраструктура
Сервис представляет собой несколько приложений, работающих в Microsoft Azure. Размещение с использованием облачной платформы вместо on-premise размещения не только позволит при незначительных временных затратах разработать сервис, отвечающий всем требованиям, перечисленным во второй части в разделе «Нефункциональные требования -> Атрибуты качества», но и существенно снизит первоначальные финансовые затраты на аппаратное и программное обеспечение.
Антифрод-сервис состоит из следующих систем:
- Antifraud API Service – REST-сервис, предоставляющий API для взаимодействия с сервисом Fraud Predictor ML.
- Fraud Predictor ML – сервис обнаружения мошеннических платежей, в основе которого лежат алгоритмы машинного обучения.
- Transactions Log (лог транзакций) – NoSQL хранилище информации о транзакциях.
Кроме того, у сервиса имеются многочисленные программные клиенты (Clients), представляющие собой web-приложения мерчантов, либо js-виджеты, вызывающие REST-сервисы Antifraud API Service.
Принципиальная схема взаимодействия этих систем проиллюстрирована выше.
Используемые архитектурные паттерны
Инфраструктура, наряду с предметной областью и законодательными актами, потенциально несет в себе большое количество ограничений, который должны быть учтены на архитектурном уровне. И если доменные и юридические ограничения мы уже обсудили в предыдущих частях статьи, то преимущества и ограничения, связанные с выбором облачной платформы Microsoft Azure обсудим ниже.
Используемые антифрод-системой сервисы Azure – Cloud service для web-/worker-ролей, Azure Table, Azure Queue, Azure ML, etc. – кроме почти нулевых начальных финансовых затрат на инфрастуктуру дают следующие преимущества из коробки:
- высокая доступность: SLA не ниже 99,95%;
- надежность хранения: системы хранения данных с высокой избыточностью;
- безопасность хранения: сертификаты ISO 27001/27002 и другие, включая PCI DSS 3.0;
- отказоустойчивость: все рабочие узлы можно (рекомендуется) запускать в нескольких экземплярах;
- масштабируемость: возможно автоматическое масштабирование количества рабочих узлов в зависимости от нагрузки, партицирование таблиц NoSQL-хранилища на основе PartitionKey;
В качестве бонусов я рассматриваю:
- удобный мониторинг приложения;
- глубокая интеграция с Visual Studio.
Но воспользоваться всеми этими преимуществами получилось только благодаря «заточке» архитектуры антифрод-сервиса под облако, так:
- web/worker-узлы являются stateless;
- горизонтальное партицирование для хранения структурированных или полуструктурированных данных (Sharding Pattern [1]);
- сетевых взаимодействия происходят только асинхронно и только с применением retry-политик (Retry Pattern [1]);
- для выравнивания нагрузок и гарантированной обработки задач используются очереди сообщений (паттерн Queue-Based Load Leveling Pattern [1]).
Кроме того, антифрод-сервис – near real-time система, поэтому при реализации антифрод-сервиса:
- используем алгоритмы параллельные по данным (простейший и один из самых эффективных MapReduce);
- применяем подход Push'n'Forget для таких мест как сохранение единичной записи в лог транзакций (на точность работы алгоритма машинного обучения одна пропавшая запись из 10K успешных не окажет сильного влияния);
- избегаем блокировок лога транзакций (любых разделяемых ресурсов), что достигается добавлением поля timestamp к информации о транзакции;
- «убиваем» (или хотя бы что-то с ними делаем) долгие запросы.
Необходимо также держать в голове, что у всех облачных сервисов есть ограничения:
- как технического характера: наиболее частые из них максимальное количество запросов в секунду, максимальный размер сообщения;
- так и технологического характера: наиболее серьезное из них – поддерживаемые протоколы взаимодействия с PaaS-сервисами.
Взаимодействие между компонентами сервиса
Для мерчанта сервис представляет собой REST-сервис, с которым можно взаимодействовать по протоколу https – Antifraud API Service. Antifraud API Service работает в кластере, состоящем из нескольких stateless web-ролей (web-роль в Azure – слой приложения, выполняющий роль веб-приложения).
Следующая диаграмма последовательностей описывает возможные взаимодействия мерчанта со всеми подсистемами антифрод-сервиса.
- Шаг 1. Отправка запроса с информацией о платеже.
- Шаг 2. Трансформация Модели (в терминах MVC).
- Шаг 3. Отправка запроса на сервис предсказания результата платежа.
- Шаг 4. Возвращение результата – будет ли платеж успешным.
- Шаг 5. Сохранение данных.
- Шаг 6. Возвращение результата клиенту.
- Шаг 7, 8. Пересчет и обновление обучающей выборки, переобучение модели.
- Шаг 9-12 (опционально). Клиент инициирует отправку запроса с информацией о результате платежа (в случае, когда результат предсказания отличается от реального результата платежа, переданного в запросе).
Рассмотрим каждый из шагов подробнее.
Запрос от мерчанта поступает на Контроллер (в терминах MVC) (Шаг 1). После чего полученная Модель (в терминах MVC) проходит:
- трансформацию из модели контроллера в доменный объект;
- запрос к внешним геолокационным сервисам (Azure Marketplace), с целью узнать страну по индексу плательщика и страну по IP хоста, с которого пришел запрос на снятие средств с карты;
- этап проверки через глобальные фильтры;
- этап проверки на валидность платежных данных;
- предварительный анализ полученной транзакции – считаем эвристики для таймфреймов 5 секунд, 1 минута, 24 часа;
- сокрытие личных данных покупателя и платежных данных – хэшируются имя владельца карты, имя владельца эккаунта на сайте мерчанта, адрес плательщика, телефон, email.
- удаляем ненужные данные – например, данные о сроке действия карты после шага 4 не понадобятся.
Эвристики, глобальные фильтры и признаки валидности платежных данных были подробно обсуждены в предыдущей части статьи.
На шаге 2 объект предметной области трансформируется в DTO-объект, который:
- передается в сервис Fraud Predictor ML (шаг 3);
- после получения ответа от Fraud Predictor ML (шаг 4) информация о транзакции и ее результате сохраняется в лог транзакций (шаг 5) (о нем чуть ниже);
- возвращаем клиенту ответ о предсказанном результате платежа (мошеннический или нет).
Для улучшения качества работы алгоритма предсказания клиентам доступен API уточнения результатов транзакции. Так, если реальный результат проведения платежа отличался от значения, которое вернул наш антифрод-сервис, мерчант может сообщить об этом, отправив запрос на уточнение результатов транзакций (шаг 9). Такие запросы:
- имеют формат <transaction_id, transaction_result, last_update_time>;
- обрабатываются Merchant API Service и после валидации ставятся в Azure Queue (отказоустойчивый сервис очередей).
Из очереди запросы забираются одним из роботов, представляющих собой stateless worker-роль (worker-роль – в Azure это слой приложения, выполняющий роль обработчика).
Хранилище транзакций
Как информация о транзакциях, так и дополнительная информация по ним (в основном статистика) сохраняется в лог транзакций – долговременное хранилище на основе Azure Table (сервис, представляющий собой отказоустойчивое NoSQL-хранилище (key-value)).
Лог транзакция представляет собой 2 таблицы:
- таблицу с фактами о транзакции TransactionsInfo: id транзакции (Row Key), id мерчанта, хэш имени держателя карты (если доступен), сумма и валюта платежа и т.п.;
- таблицу с рассчитанными статистическими метриками TransactionsStatistics: сколько раз платили с этой карты (несколько таймфреймов), со скольких IP адресов, как временной интервал был между платежами, как давно зарегистрировался покупатель у мерчанта, сколько раз совершал успешные платежи и т.д.
На шагах 7, 8 проходит переобучение модели. Обучающая выборка представляет собой данные из лога транзакций, т.к. в хранилище лога содержится последняя информация по платежам и их результатам. Переобучение может происходить по расписанию, по появлению фиксированного значения новых записей в логе транзакций, по преодолению определенного порога неверных предсказаний.
Подробнее вопроса обучения модели обнаружения мошеннических платежей коснемся в следующей заключительной части.
Заключение 3-ей части
В этой части мы обсудили архитектуру антифрод-сервиса, выделили в нем функциональные части – Antifraud API Service, Fraud Predictor ML, Transactions Log, определили их зоны ответственности, а также способы взаимодействия между собой.
При правильном подходе к архитектуре развертывание антифрод-сервиса в облаке Microsoft Azure позволит существенно сократить первоначальные финансовые затраты на инфраструктуру, а также уменьшить время, затраченное на вопросы, связанные с масштабируемостью системы, надежным хранением данных и высокой доступностью сервисов.
В следующей заключительной части мы продолжим создавать антифрод-сервис, на порядок более дешевый по стоимости разработки и владения, чем его аналоги – разработаем сервис Fraud Predictor ML, который базируется на сервисе Azure Machine Learning и является аналитическим ядром антифрод-сервиса.
Полезные источники
[1] Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications, MSDN.
