Предыдущие части
- Часть первая — habrahabr.ru/post/255361
- Часть вторая — habrahabr.ru/post/255523
- Часть третья — habrahabr.ru/post/255825
- Часть четвертая — habrahabr.ru/post/256045
В данной части мы рассмотрим
Здесь мы в общих чертах рассмотрим работу с операторами модификации данных:
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- SELECT … INTO … – сохранить результат запроса в новой таблице
- MERGE – слияние данных
- Использование конструкции OUTPUT
- TRUNCATE TABLE – DDL-операция для быстрой очистки таблицы
В самом конце вас ждут «Приложение 1 – бонус по оператору SELECT» и «Приложение 2 – OVER и аналитические функции», в которых будут показаны некоторые расширенные конструкции:
- PIVOT
- UNPIVOT
- GROUP BY ROLLUP
- GROUP BY GROUPING SETS
- использование приложения OVER
Операции модификации данных очень сильно связаны с конструкциями оператора SELECT, т.к. по сути выборка модифицируемых данных идет при помощи них. Поэтому для понимания данного материала, важное место имеет уверенное владение конструкциями оператора SELECT.
Данная часть, как я и говорил, будет больше обзорная. Здесь я буду описывать только те основные формы операторов модификации данных, которыми я сам регулярно пользуюсь. Поэтому на полноту изложения рассчитывать не стоит, здесь будут показан только необходимый минимум, который новички могут использовать как направление для более глубокого изучения. За более подробной информацией по каждому оператору обращайтесь в MSDN. Хотя кому-то возможно и в таком объеме информации будет вполне достаточно.
Т.к. прямая модификация информации в РБД требует от человека большой ответственности, а также потому что пользователи обычно модифицируют информацию БД посредством разных АРМ, и не имеют полного доступа к БД, то данная часть больше посвящается начинающим ИТ-специалистам, и я буду здесь очень краток. Но конечно, если вы смогли освоить оператор SELECT, то думаю, и операторы модификации вам будут под силу, т.к. после оператора SELECT здесь нет ничего сверхсложного, и по большей части должно восприниматься на интуитивном уровне. Но порой сложность представляют не сами операторы модификации, а то что они должны выполняться группами, в рамках одной транзакции, т.е. когда дополнительно нужно учитывать целостность данных. В любом случае можете почитать и попытаться проделать примеры в ознакомительных целях, к тому же в итоге вы сможете получить более детальную базу, на которой можно будет отработать те или иные конструкции оператора SELECT.
Проведем изменения в структуре нашей БД
Давайте проведем небольшое обновление структуры и данных таблицы Employees:
-- информацию по ЗП решено хранить до 2-х знаков после запятой
ALTER TABLE Employees ALTER COLUMN Salary numeric(20,2)
-- информацию по процентам решено хранить только в целых числах
ALTER TABLE Employees ALTER COLUMN BonusPercent tinyint
А также для демонстрационных целей расширим схему нашей БД, а за одно повторим DDL. Назначения таблиц и полей указаны в комментариях:
-- история изменений ЗП у сотрудников
CREATE TABLE EmployeesSalaryHistory(
EmployeeID int NOT NULL, -- ссылка на ID сотрудника
DateFrom date NOT NULL, -- с какой даты
DateTo date, -- по какую дату. Содержит NULL если это последняя установленная ЗП.
Salary numeric(20,2) NOT NULL, -- сумма ЗП за этот период
CONSTRAINT PK_EmployeesSalaryHistory PRIMARY KEY(EmployeeID,DateFrom),
CONSTRAINT FK_EmployeesSalaryHistory_EmployeeID FOREIGN KEY(EmployeeID) REFERENCES Employees(ID)
)
GO
-- таблица для хранения истории начислений по ЗП
CREATE TABLE EmployeesSalary(
EmployeeID int NOT NULL,
SalaryDate date NOT NULL, -- дата начисления
SalaryAmount numeric(20,2) NOT NULL, -- сумма начисления
Note nvarchar(50), -- примечание
-- здесь сумма ЗП может фиксироваться по человеку 1 раз в день
CONSTRAINT PK_EmployeesSalary PRIMARY KEY(EmployeeID,SalaryDate),
-- связь с таблицей Employees
CONSTRAINT FK_EmployeesSalary_EmployeeID FOREIGN KEY(EmployeeID) REFERENCES Employees(ID)
)
GO
-- справочник по типам бонусов
CREATE TABLE BonusTypes(
ID int IDENTITY(1,1) NOT NULL,
Name nvarchar(30) NOT NULL,
CONSTRAINT PK_BonusTypes PRIMARY KEY(ID)
)
GO
-- таблица для хранения истории начислений бонусов
CREATE TABLE EmployeesBonus(
EmployeeID int NOT NULL,
BonusDate date NOT NULL, -- дата начисления
BonusAmount numeric(20,2) NOT NULL, -- сумма начисления
BonusTypeID int NOT NULL,
BonusPercent tinyint,
Note nvarchar(50), -- примечание
-- бонус одного типа может фиксироваться по человеку 1 раз в день
CONSTRAINT PK_EmployeesBonus PRIMARY KEY(EmployeeID,BonusDate,BonusTypeID),
-- связь с таблицей Employees и BonusTypes
CONSTRAINT FK_EmployeesBonus_EmployeeID FOREIGN KEY(EmployeeID) REFERENCES Employees(ID),
CONSTRAINT FK_EmployeesBonus_BonusTypeID FOREIGN KEY(BonusTypeID) REFERENCES BonusTypes(ID)
)
GO
Вот такой полигон мы должны были получить в итоге:
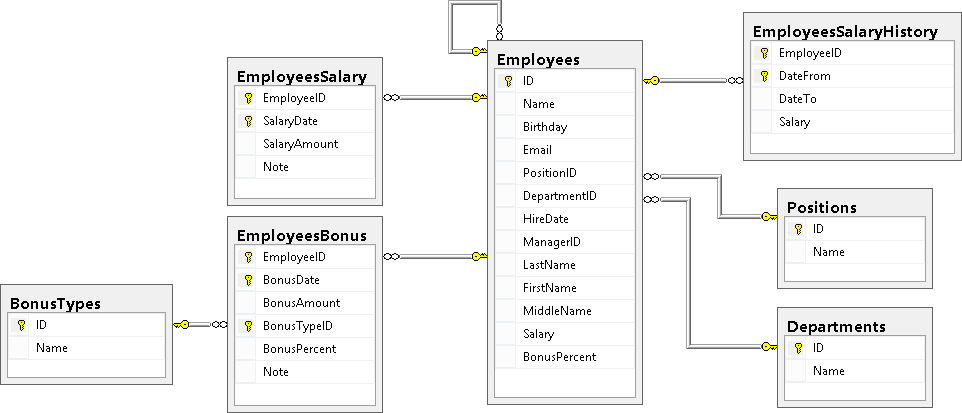
Кстати, потом этот полигон (когда он будет наполнен данными) вы и можете использовать для того чтобы опробовать на нем разнообразные запросы – здесь можно опробовать и разнообразные JOIN-соединения, и UNION-объединения, и группировки с агрегированием данных.
INSERT – вставка новых данных
Данный оператор имеет 2 основные формы:
- INSERT INTO таблица(перечень_полей) VALUES(перечень_значений) – вставка в таблицу новой строки значения полей которой формируются из перечисленных значений
- INSERT INTO таблица(перечень_полей) SELECT перечень_значений FROM … – вставка в таблицу новых строк, значения которых формируются из значений строк возвращенных запросом.
В диалекте MS SQL слово INTO можно отпускать, что мне очень нравится и я этим всегда пользуюсь.
К тому же стоит отметить, что первая форма в диалекте MS SQL с версии 2008, позволяет вставить в таблицу сразу несколько строк:
INSERT таблица(перечень_полей) VALUES
(перечень_значений1),
(перечень_значений2),
…
(перечень_значенийN)
INSERT – форма 1. Переходим сразу к практике
Наполним таблицу EmployeesSalaryHistory предоставленными нам данными:
INSERT EmployeesSalaryHistory(EmployeeID,DateFrom,DateTo,Salary)
VALUES
-- Иванов И.И.
(1000,'20131101','20140531',4000),
(1000,'20140601','20141230',4500),
(1000,'20150101',NULL,5000),
-- Петров П.П.
(1001,'20131101','20140630',1300),
(1001,'20140701','20140930',1400),
(1001,'20141001',NULL,1500),
-- Сидоров С.С.
(1002,'20140101',NULL,2500),
-- Андреев А.А.
(1003,'20140601',NULL,2000),
-- Николаев Н.Н.
(1004,'20140701','20150131',1400),
(1004,'20150201','20150131',1500),
-- Александров А.А.
(1005,'20150101',NULL,2000)
Таким образом мы вставили в таблицу EmployeesSalaryHistory 11 новых записей.
SELECT *
FROM EmployeesSalaryHistory
| EmployeeID | DateFrom | DateTo | Salary |
|---|---|---|---|
| 1000 | 2013-11-01 | 2014-05-31 | 4000.00 |
| 1000 | 2014-06-01 | 2014-12-30 | 4500.00 |
| 1000 | 2015-01-01 | NULL | 5000.00 |
| 1001 | 2013-11-01 | 2014-06-30 | 1300.00 |
| 1001 | 2014-07-01 | 2014-09-30 | 1400.00 |
| 1001 | 2014-10-01 | NULL | 1500.00 |
| 1002 | 2014-01-01 | NULL | 2500.00 |
| 1003 | 2014-06-01 | NULL | 2000.00 |
| 1004 | 2014-07-01 | 2015-01-31 | 1400.00 |
| 1004 | 2015-02-01 | 2015-01-31 | 1500.00 |
| 1005 | 2015-01-01 | NULL | 2000.00 |
Хоть мы в этом случае могли и не указывать перечень полей, т.к. мы вставляем данные всех полей и в таком же виде, как они перечислены в таблице, т.е. мы могли бы написать:
INSERT EmployeesSalaryHistory
VALUES
-- Иванов И.И.
(1000,'20131101','20140531',4000),
(1000,'20140601','20141230',4500),
(1000,'20150101',NULL,5000),
…
Но я бы не рекомендовал использовать такой подход, особенно если данный запрос будет использоваться регулярно, например, вызываясь из какого-то АРМ. Опять же это чревато тем, что структура таблицы может изменяться, в нее могут быть добавлены новые поля, или же последовательность полей может быть изменена, что еще опасней, т.к. это может привести к появлению логических ошибок во вставленных данных. Поэтому лучше лишний раз не полениться и перечислить явно все поля, в которые вы хотите вставить значение.
Несколько заметок про INSERT:
- Порядок перечисления полей не имеет значения, вы можете написать и (EmployeeID,DateFrom,DateTo,Salary) и (DateFrom,DateTo, EmployeeID,Salary). Здесь важно только то, чтобы он совпадал с порядком значений, которые вы перечисляете в скобках после ключевого слова VALUES.
- Так же важно, чтобы при вставке были заданы значения для всех обязательных полей, которые помечены в таблице как NOT NULL.
- Можно не указывать поля у которых была указана опция IDENTITY или же поля у которых было задано значение по умолчанию при помощи DEFAULT, т.к. в качестве их значения подставится либо значение из счетчика, либо значение, указанное по умолчанию. Такие вставки мы уже делали в первой части.
- В случаях, когда значение поля со счетчиком нужно задать явно используйте опцию IDENTITY_INSERT.
В предыдущих частях мы периодически использовали опцию IDENTITY_INSERT. Давайте и здесь воспользуемся данной опцией для создания строк в таблице BonusTypes, у которой поле ID указано с опцией IDENTITY:
-- даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT BonusTypes ON
INSERT BonusTypes(ID,Name)VALUES
(1,N'Ежемесячный'),
(2,N'Годовой'),
(3,N'Индивидуальный')
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT BonusTypes OFF
Давайте вставим информацию по начислению сотрудникам ЗП, любезно предоставленную нам бухгалтером:
|
|
|
|
|
|
Думаю, приводить содержимое таблицы уже нет смысла.
INSERT – форма 2
Данная форма позволяет вставить в таблицу данные полученные запросом.
Для демонстрации наполним таблицу с начислениями бонусов одним большим запросом:
INSERT EmployeesBonus(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent)
-- расчет ежемесячных бонусов
SELECT hist.EmployeeID,bdate.BonusDate,hist.Salary/100*emp.BonusPercent,1 BonusTypeID,emp.BonusPercent
FROM EmployeesSalaryHistory hist
JOIN
(
VALUES -- весь период работы компании - последние дни месяцев
('20131130'),
('20131231'),
('20140131'),
('20140228'),
('20140331'),
('20140430'),
('20140531'),
('20140630'),
('20140731'),
('20140831'),
('20140930'),
('20141031'),
('20141130'),
('20141230'),
('20150131'),
('20150228'),
('20150331')
) bdate(BonusDate)
ON bdate.BonusDate BETWEEN hist.DateFrom AND ISNULL(hist.DateTo,'20991231')
JOIN Employees emp ON hist.EmployeeID=emp.ID
WHERE emp.BonusPercent IS NOT NULL AND emp.BonusPercent>0
AND NOT EXISTS( -- исключаем сотрудников, которым по какой-то причине не дали бонус в указанный период
SELECT *
FROM
(
VALUES
(1001,'20140115'),
(1001,'20140430'),
(1001,'20141031'),
(1001,'20141130'),
(1001,'20150228')
) exclude(EmployeeID,BonusDate)
WHERE exclude.EmployeeID=emp.ID
AND exclude.BonusDate=bdate.BonusDate
)
UNION ALL
-- годовой бонус за 2014 год - всем кто проработал больше полугода
SELECT
hist.EmployeeID,
'20141231' BonusDate,
hist.Salary/100*
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount,
2 BonusTypeID,
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusPercent
FROM EmployeesSalaryHistory hist
JOIN Employees emp ON hist.EmployeeID=emp.ID
WHERE CAST('20141231' AS date) BETWEEN hist.DateFrom AND ISNULL(hist.DateTo,'20991231')
AND emp.HireDate<='20140601'
UNION ALL
-- индивидуальные бонусы
SELECT EmployeeID,BonusDate,BonusAmount,3 BonusTypeID,NULL BonusPercent
FROM
(
VALUES
(1001,'20140930',300),
(1002,'20140331',500),
(1002,'20140630',500),
(1002,'20140930',500),
(1002,'20141230',500),
(1002,'20150331',500),
(1004,'20140831',200)
) indiv(EmployeeID,BonusDate,BonusAmount)
В таблицу EmployeesBonus должно было вставиться 50 записей.
Результат каждого запроса объединенных конструкциями UNION ALL вы можете проанализировать самостоятельно. Если вы хорошо изучили базовые конструкции, то вам должно быть все понятно, кроме возможно конструкции с VALUES (конструктор табличных значений), которая появилась с MS SQL 2008.
Пара слов про конструкцию VALUES
SELECT EmployeeID,BonusDate,BonusAmount,3 BonusTypeID,NULL BonusPercent
FROM
(
VALUES
(1001,'20140930',300),
(1002,'20140331',500),
(1002,'20140630',500),
(1002,'20140930',500),
(1002,'20141230',500),
(1002,'20150331',500),
(1004,'20140831',200)
) indiv(EmployeeID,BonusDate,BonusAmount)
В случае необходимости, данную конструкцию можно заменить, аналогичным запросом, написанным через UNION ALL:
SELECT 1001 EmployeeID,'20140930' BonusDate,300 BonusAmount,3 BonusTypeID,NULL BonusPercent
UNION ALL
SELECT 1002,'20140331',500,3,NULL
UNION ALL
SELECT 1002,'20140630',500,3,NULL
UNION ALL
SELECT 1002,'20140930',500,3,NULL
UNION ALL
SELECT 1002,'20141230',500,3,NULL
UNION ALL
SELECT 1002,'20150331',500,3,NULL
UNION ALL
SELECT 1004,'20140831',200,3,NULL
Думаю, комментарии излишни и вам не составит большого труда разобраться с этим самостоятельно.
Так что, идем дальше.
INSERT + CTE-выражения
Совместно с INSERT можно применять CTE выражения. Для примера перепишем тот же запрос перенеся все подзапросы в блок WITH.
Для начала полностью очистим таблицу EmployeesBonus при помощи операции TRUNCATE TABLE:
TRUNCATE TABLE EmployeesBonus
Теперь перепишем запрос вынеся запросы в блок WITH:
WITH cteBonusType1 AS(
-- расчет ежемесячных бонусов
SELECT hist.EmployeeID,bdate.BonusDate,hist.Salary/100*emp.BonusPercent BonusAmount,1 BonusTypeID,emp.BonusPercent
FROM EmployeesSalaryHistory hist
JOIN
(
VALUES -- весь период работы компании - последние дни месяцев
('20131130'),
('20131231'),
('20140131'),
('20140228'),
('20140331'),
('20140430'),
('20140531'),
('20140630'),
('20140731'),
('20140831'),
('20140930'),
('20141031'),
('20141130'),
('20141230'),
('20150131'),
('20150228'),
('20150331')
) bdate(BonusDate)
ON bdate.BonusDate BETWEEN hist.DateFrom AND ISNULL(hist.DateTo,'20991231')
JOIN Employees emp ON hist.EmployeeID=emp.ID
WHERE emp.BonusPercent IS NOT NULL AND emp.BonusPercent>0
AND NOT EXISTS( -- исключаем сотрудников, которым по какой-то причине не дали бонус в указанный период
SELECT *
FROM
(
VALUES
(1001,'20140115'),
(1001,'20140430'),
(1001,'20141031'),
(1001,'20141130'),
(1001,'20150228')
) exclude(EmployeeID,BonusDate)
WHERE exclude.EmployeeID=emp.ID
AND exclude.BonusDate=bdate.BonusDate
)
),
cteBonusType2 AS(
-- годовой бонус за 2014 год - всем кто проработал больше полугода
SELECT
hist.EmployeeID,
'20141231' BonusDate,
hist.Salary/100*
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusAmount,
2 BonusTypeID,
CASE DepartmentID
WHEN 2 THEN 10 -- 10% от ЗП выдать Бухгалтерам
WHEN 3 THEN 15 -- 15% от ЗП выдать ИТ-шникам
ELSE 5 -- всем остальным по 5%
END BonusPercent
FROM EmployeesSalaryHistory hist
JOIN Employees emp ON hist.EmployeeID=emp.ID
WHERE CAST('20141231' AS date) BETWEEN hist.DateFrom AND ISNULL(hist.DateTo,'20991231')
AND emp.HireDate<='20140601'
),
cteBonusType3 AS(
-- индивидуальные бонусы
SELECT EmployeeID,BonusDate,BonusAmount,3 BonusTypeID,NULL BonusPercent
FROM
(
VALUES
(1001,'20140930',300),
(1002,'20140331',500),
(1002,'20140630',500),
(1002,'20140930',500),
(1002,'20141230',500),
(1002,'20150331',500),
(1004,'20140831',200)
) indiv(EmployeeID,BonusDate,BonusAmount)
)
INSERT EmployeesBonus(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent)
SELECT *
FROM cteBonusType1
UNION ALL
SELECT *
FROM cteBonusType2
UNION ALL
SELECT *
FROM cteBonusType3
Как видим вынос больших подзапросов в блок WITH упростил основной запрос – сделал его более понятным.
UPDATE – обновление данных
Данный оператор в MS SQL имеет 2 формы:
- UPDATE таблица SET … WHERE условие_выборки – обновлении строк таблицы, для которых выполняется условие_выборки. Если предложение WHERE не указано, то будут обновлены все строки. Это можно сказать классическая форма оператора UPDATE.
- UPDATE псевдоним SET … FROM … – обновление данных таблицы участвующей в предложении FROM, которая задана указанным псевдонимом. Конечно, здесь можно и не использовать псевдонимов, используя вместо них имена таблиц, но с псевдонимом на мой взгляд удобнее.
Давайте при помощи первой формы приведем даты приема каждого сотрудника в порядок. Выполним 6 отдельных операций UPDATE:
-- приведем даты приема в порядок
UPDATE Employees SET HireDate='20131101' WHERE ID=1000
UPDATE Employees SET HireDate='20131101' WHERE ID=1001
UPDATE Employees SET HireDate='20140101' WHERE ID=1002
UPDATE Employees SET HireDate='20140601' WHERE ID=1003
UPDATE Employees SET HireDate='20140701' WHERE ID=1004
-- а здесь еще почистим поле FirstName
UPDATE Employees SET HireDate='20150101',FirstName=NULL WHERE ID=1005
Вторую форму, где применялся псевдоним, мы уже тоже успели использовать в первой части, когда обновляли поля PositionID и DepartmentID, на значения возвращаемые подзапросами:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Сейчас конечно данный и следующий запрос не сработают, т.к. поля Position и Department мы удалили из таблицы Employees. Вот так можно было бы представить этот запрос при помощи операций соединений:
UPDATE e
SET
PositionID=p.ID,
DepartmentID=d.ID
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
Надеюсь суть обновления здесь понятна, тут обновляться будут строки таблицы Employees.
Сначала вы можете сделать выборку, чтобы посмотреть какие данные будут обновлены и на какие значения:
SELECT
e.ID,
e.PositionID,e.DepartmentID, -- старые значения
e.Position,e.Department,
p.ID,d.ID, -- новые значения
p.Name,d.Name
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
А потом переписать это в UPDATE:
UPDATE e
SET
PositionID=p.ID,
DepartmentID=d.ID
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
Эх, не могу я так, все-таки давайте посмотрим, как это работает наглядно.
Для этого опять вспомним DDL и временно создадим поля Position и Department в таблице Employees:
ALTER TABLE Employees ADD Position nvarchar(30),Department nvarchar(30)
Зальем в них данные, предварительно посмотрев при помощи SELECT, что получится:
SELECT
e.ID,
e.Position,
p.Name NewPosition,
e.Department,
d.Name NewDepartment
FROM Employees e
LEFT JOIN Positions p ON p.ID=e.PositionID
LEFT JOIN Departments d ON d.ID=e.DepartmentID
Теперь перепишем и выполним обновление:
UPDATE e
SET
e.Position=p.Name,
e.Department=d.Name
FROM Employees e
LEFT JOIN Positions p ON p.ID=e.PositionID
LEFT JOIN Departments d ON d.ID=e.DepartmentID
Посмотрите, что получилось (должны были появиться значения в 2-х полях – Position и Department, находящиеся в конце таблицы):
SELECT *
FROM Employees
Теперь и этот запрос:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
И этот:
UPDATE e
SET
PositionID=p.ID,
DepartmentID=d.ID
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
Отработают успешно.
Не забудьте только предварительно посмотреть (это очень полезная привычка):
SELECT
e.ID,
e.PositionID,e.DepartmentID, -- старые значения
e.Position,e.Department,
p.ID,d.ID, -- новые значения
p.Name,d.Name
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
И конечно же можете использовать здесь условие WHERE:
UPDATE e
SET
PositionID=p.ID,
DepartmentID=d.ID
FROM Employees e
LEFT JOIN Positions p ON p.Name=e.Position
LEFT JOIN Departments d ON d.Name=e.Department
WHERE d.ID=3 -- обновить только данные по ИТ-отделу
Все, убедились, что все работает. Если хотите, то можете снова удалить поля Position и Department.
Вторую форму можно так же использовать с подзапросом:
UPDATE e
SET
HireDate='20131101',
MiddleName=N'Иванович'
FROM (SELECT MiddleName,HireDate FROM Employees WHERE ID=1000) e
В данном случае подзапрос должен возвращать в явном виде строки таблицы Employees, которые будут обновлены. В подзапросе нельзя использовать группировки или предложения DISTINCT, т.к. в этом случае мы не получим явных строк таблицы Employees. И соответственно все обновляемые поля должны содержаться в предложении SELECT, если конечно вы не указали «SELECT *».
Так же с UPDATE вы можете использовать CTE-выражения. Для примера перенесем наш подзапрос в блок WITH:
WITH cteEmp AS(
SELECT MiddleName,HireDate FROM Employees WHERE ID=1000
)
UPDATE cteEmp
SET
HireDate='20131101',
MiddleName=N'Иванович'
Идем дальше.
DELETE – удаление данных
Принцип работы DELETE похож на принцип работы UPDATE, и так же в MS SQL можно использовать 2 формы:
- DELETE таблица WHERE условие_выборки – удаление строк таблицы, для которых выполняется условие_выборки. Если предложение WHERE не указано, то будут удалены все строки. Это можно сказать классическая форма оператора DELETE (только в некоторых СУБД нужно писать DELETE FROM таблица WHERE условие_выборки).
- DELETE псевдоним FROM … – удаление данных таблицы участвующей в предложения FROM, которая задана указанным псевдонимом. Конечно, здесь можно и не использовать псевдонимов, используя вместо них имена таблиц, но с псевдонимом на мой взгляд удобнее.
Для примера при помощи первого варианта:
-- удалим неиспользуемые должности Логист и Кладовщик
DELETE Positions WHERE ID IN(6,7)
При помощи второго варианта удалим остальные неиспользуемые должности. В целях демонстрации запрос намеренно излишне усложнен. Сначала посмотрим, что именно удалиться (всегда старайтесь делать проверку, а то ненароком можно удалить лишнее, а то и всю информацию из таблицы):
SELECT pos.*
FROM
(
SELECT DISTINCT PositionID
FROM Employees
) emp
RIGHT JOIN Positions pos ON pos.ID=emp.PositionID
WHERE emp.PositionID IS NULL -- нет среди должностей указанных в Employees
Убедились, что все нормально. Переписываем запрос на DELETE:
DELETE pos -- удалить из этой таблицы
FROM
(
SELECT DISTINCT PositionID
FROM Employees
) emp
RIGHT JOIN Positions pos ON pos.ID=emp.PositionID
WHERE emp.PositionID IS NULL -- нет среди должностей указанных в Employees
В качестве таблицы Positions может выступать и подзапрос, главное, чтобы он однозначно возвращал строки, которые будут удаляться. Давайте добавим для демонстрации в таблицу Positions мусора:
INSERT Positions(Name) VALUES('Test 1'),('Test 2')
Теперь для демонстрации используем вместо таблицы Positions, подзапрос, в котором отбираются только определенные строки из таблицы Positions:
DELETE pos -- удалить из этой таблицы
FROM
(
SELECT DISTINCT PositionID
FROM Employees
) emp
RIGHT JOIN
(
SELECT ID
FROM Positions
WHERE ID>4 -- отбираем должности по условию
) pos
ON pos.ID=emp.PositionID
WHERE emp.PositionID IS NULL -- нет среди должностей указанных в Employees
Так же мы можем использовать CTE выражения (подзапросы, оформленные в блоке WITH). Давайте снова добавим для демонстрации в таблицу Positions мусора:
INSERT Positions(Name) VALUES('Test 1'),('Test 2')
И посмотрим на тот же запрос с CTE-выражением:
WITH ctePositionc AS(
SELECT ID
FROM Positions
WHERE ID>4 -- отбираем должности по условию
)
DELETE pos -- удалить из этой таблицы
FROM
(
SELECT DISTINCT PositionID
FROM Employees
) emp
RIGHT JOIN ctePositionc pos ON pos.ID=emp.PositionID
WHERE emp.PositionID IS NULL -- нет среди должностей указанных в Employees
Заключение по INSERT, UPDATE и DELETE
Вот по сути и все, что я хотел рассказать вам про основные операторы модификации данных – INSERT, UPDATE и DELETE.
Я считаю, что данные операторы очень легко понять интуитивно, когда умеешь пользоваться конструкциями оператора SELECT. Поэтому рассказ о операторе SELECT растянулся на 3 части, а рассказ о операторах модификации был написан в такой беглой форме.
И как вы увидели, с операторами модификации тоже полет фантазии не ограничен. Но все же старайтесь писать, как можно проще и понятней, обязательно предварительно проверяя, какие записи будут обработаны при помощи SELECT, т.к. обычно модификация данных, это очень большая ответственность.
В дополнение скажу, что в диалекте MS SQL cо всеми операциями модификации можно использовать предложение TOP (INSERT TOP …, UPDATE TOP …, DELETE TOP …), но мне пока ни разу не приходилось прибегать к такой форме, т.к. здесь непонятно какие именно TOP записей будут обработаны.
Если уж нужно обработать TOP записей, то я, наверное, лучше воспользуюсь указанием опции TOP в подзапросе и применю в нем нужным мне образом ORDER BY, чтобы явно знать какие именно TOP записей будут обработаны. Для примера снова добавим мусора:
INSERT Positions(Name) VALUES('Test 1'),('Test 2')
И удалим 2 последние записи:
DELETE emp
FROM
(
SELECT TOP 2 * -- 2. берем только 2 верхние записи
FROM Positions
ORDER BY ID DESC -- 1. сортируем по убыванию
) emp
Я здесь привожу примеры больше в целях демонстрации возможностей языка SQL. В реальных запросах старайтесь выражать свои намерения очень точно, дабы выполнение вашего запроса не привело к порче данных. Еще раз скажу – будьте очень внимательны, и не ленитесь делать предварительные проверки.
SELECT … INTO … – сохранить результат запроса в новой таблице
Данная конструкция позволяет сохранить результат выборки в новой таблице. Она представляет из себя что-то промежуточное между DDL и DML.
Типы колонок созданной таблицы будут определены на основании типов колонок набора, полученного запросом SELECT. Если в выборке присутствуют результаты выражений, то им должны быть заданы псевдонимы, которые будут служить в роли имен колонок.
Давайте отберем следующие данные и сохраним их в таблице EmployeesBonusTarget (перед FROM просто пишем INTO и указываем имя новой таблицы):
SELECT
bonus.EmployeeID,
bonus.BonusDate,
bonus.BonusAmount-bonus.BonusAmount BonusAmount, -- обнулим значения
bonus.BonusTypeID,
bonus.BonusPercent,
bonus.Note
INTO EmployeesBonusTarget -- сохраним результат в новой таблице EmployeesBonusTarget
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
WHERE emp.DepartmentID=3
Можете обновить список таблиц в инспекторе объектов и увидеть новую таблицу EmployeesBonusTarget:
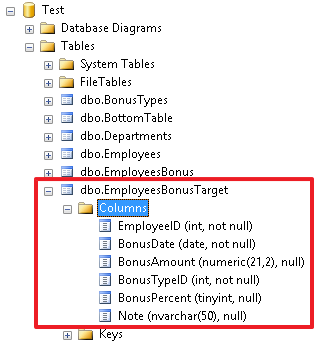
На самом деле я специально создал таблицу EmployeesBonusTarget, я ее буду использовать для демонстрации оператора MERGE.
Еще пара слов про конструкцию SELECT … INTO …
Данную конструкцию иногда удобно применять при формировании очень сложных отчетов, которые требуют выборки из множества таблиц. В этом случае данные обычно сохраняют во временных таблицах (#). Т.е. предварительно при помощи запросов, мы сбрасываем данные во временные таблицы, а затем используем эти временные таблицы в других запросах, которые формируют окончательный результат:
SELECT
ID,
CONCAT(LastName,' ',FirstName,' ',MiddleName) FullName, -- используем псевдоним FullName
Salary,
BonusPercent,
Salary/100*ISNULL(BonusPercent,0) Bonus -- используем псевдоним Bonus
INTO #EmployeesBonus -- сохранить результат во временной таблице
FROM Employees
SELECT …
FROM #EmployeesBonus b
JOIN …
Иногда данную конструкцию удобно использовать, чтобы сделать полную копию всех данных текущей таблицы:
SELECT *
INTO EmployeesBackup
FROM Employees
Это можно использовать, например, для подстраховки, перед тем как вносить серьезные изменения в структуру таблицы Employees. Вы можете сохранить копию либо всех данных таблицы, либо только тех данных, которых коснется модификация. Т.е. если что-то пойдет не так, вы сможете восстановить данные таблицы Employees с этой копии. В таких случаях конечно хорошо сделать предварительный бэкап БД на текущий момент, но это бывает не всегда возможно из-за огромных объемов, срочности и т.п.
Чтобы не засорять основную базу, можно создать новую БД и сделать копию таблицы туда:
CREATE DATABASE TestTemp
GO
SELECT *
INTO TestTemp.dbo.EmployeesBackup -- используем префикс ИмяБаза.Схема.
FROM Employees
Для того чтобы увидеть новую БД TestTemp, соответственно, обновите в инспекторе объектов список баз данных, в ней и уже можете найти данную таблицу.
На заметку.
В БД Oracle так же есть конструкция для сохранения результата запроса в новую таблицу, выглядит она следующим образом:
CREATE TABLE EMPLOYEES_BACK -- сохранить результат в новой таблице с именем EMPLOYEES_BACK AS SELECT * FROM EMPLOYEES
MERGE – слияние данных
Данный оператор хорошо подходит для синхронизации данных 2-х таблиц. Такая задача может понадобится при интеграции разных систем, когда данные передаются порциями из одной системы в другую.
В нашем случае, допустим, что стоит задача синхронизации таблицы EmployeesBonusTarget с таблицей EmployeesBonus.
Давайте добавим в таблицу EmployeesBonusTarget какого-нибудь мусора:
INSERT EmployeesBonusTarget(EmployeeID,BonusDate,BonusAmount,BonusTypeID,Note)VALUES
(9999,'20150101',9999.99,0,N'это мусор'),
(9999,'20150201',9999.99,0,N'это мусор'),
(9999,'20150301',9999.99,0,N'это мусор'),
(9999,'20150401',9999.99,0,N'это мусор'),
(9999,'20150501',9999.99,0,N'это мусор'),
(9999,'20150601',9999.99,0,N'это мусор')
Теперь при помощи оператора MERGE добьемся того, чтобы данные в таблице EmployeesBonusTarget стали такими же, как и в EmployeesBonus, т.е. сделаем синхронизацию данных.
Синхронизацию мы будем осуществлять на основании сопоставления данных входящих в первичный ключ таблицы EmployeesBonus (EmployeeID, BonusDate, BonusTypeID):
- Если для строки таблицы EmployeesBonusTarget соответствия по ключу не нашлось, то нужно сделать удаление таких строк из EmployeesBonusTarget
- Если соответствие нашлось, то нужно обновить строки EmployeesBonusTarget данными соответствующей строки из EmployeesBonus
- Если строка есть в EmployeesBonus, но ее нет в EmployeesBonusTarget, то ее нужно добавить в EmployeesBonusTarget
Сделаем реализацию всей этой логики при помощи инструкции MERGE:
MERGE EmployeesBonusTarget trg -- таблица приемник
USING EmployeesBonus src -- таблица источник
ON trg.EmployeeID=src.EmployeeID AND trg.BonusDate=src.BonusDate AND trg.BonusTypeID=src.BonusTypeID -- условие слияния
-- 1. Строка есть в trg но нет сопоставления со строкой из src
WHEN NOT MATCHED BY SOURCE THEN
DELETE
-- 2. Есть сопоставление строки trg со строкой из источника src
WHEN MATCHED THEN
UPDATE SET
trg.BonusAmount=src.BonusAmount,
trg.BonusPercent=src.BonusPercent,
trg.Note=src.Note
-- 3. Строка не найдена в trg, но есть в src
WHEN NOT MATCHED BY TARGET THEN -- предложение BY TARGET можно отпускать, т.е. NOT MATCHED = NOT MATCHED BY TARGET
INSERT(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent,Note)
VALUES(src.EmployeeID,src.BonusDate,src.BonusAmount,src.BonusTypeID,src.BonusPercent,src.Note);
Данная конструкция должна оканчиваться «;».
После выполнения запроса сравните 2 таблицы, их данные должны быть одинаковыми.
Конструкция MERGE чем-то напоминает условный оператор CASE, она так же содержит блоки WHEN, при выполнении условий которых происходит то или иное действие, в данном случае удаление (DELETE), обновление (UPDATE) или добавление (INSERT). Модификация данных производится в таблице приемнике.
В качестве источника может выступать запрос. Например, синхронизируем только данные по отделу 3 и для примера исключаем блок «NOT MATCHED BY SOURCE», чтобы данные не удались в случае не совпадения:
MERGE EmployeesBonusTarget trg -- таблица приемник
USING
(
SELECT bonus.*
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
WHERE emp.DepartmentID=3
) src -- источник
ON trg.EmployeeID=src.EmployeeID AND trg.BonusDate=src.BonusDate AND trg.BonusTypeID=src.BonusTypeID -- условие слияния
-- 2. Есть сопоставление строки trg со строкой из источника src
WHEN MATCHED THEN
UPDATE SET
trg.BonusAmount=src.BonusAmount,
trg.BonusPercent=src.BonusPercent,
trg.Note=src.Note
-- 3. Строка не найдена в trg, но есть в src
WHEN NOT MATCHED BY TARGET THEN -- предложение BY TARGET можно отпускать, т.е. NOT MATCHED = NOT MATCHED BY TARGET
INSERT(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent,Note)
VALUES(src.EmployeeID,src.BonusDate,src.BonusAmount,src.BonusTypeID,src.BonusPercent,src.Note);
Я показал работу конструкции MERGE в самом общем ее виде. При помощи нее можно реализовывать более разнообразные схемы для слияния данных, например, можно включать в блоки WHEN дополнительные условия (WHEN MATCHED AND … THEN). Это очень мощная конструкция, позволяющая в подходящих случаях сократить объем кода и совместить в рамках одного оператора функционал всех трех операторов – INSERT, UPDATE и DELETE.
И естественно с конструкцией MERGE так же можно применять CTE-выражения:
WITH cteBonus AS(
SELECT bonus.*
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
WHERE emp.DepartmentID=3
)
MERGE EmployeesBonusTarget trg -- таблица приемник
USING cteBonus src -- источник
ON trg.EmployeeID=src.EmployeeID AND trg.BonusDate=src.BonusDate AND trg.BonusTypeID=src.BonusTypeID -- условие слияния
-- 2. Есть сопоставление строки trg со строкой из источника src
WHEN MATCHED THEN
UPDATE SET
trg.BonusAmount=src.BonusAmount,
trg.BonusPercent=src.BonusPercent,
trg.Note=src.Note
-- 3. Строка не найдена в trg, но есть в src
WHEN NOT MATCHED BY TARGET THEN -- предложение BY TARGET можно отпускать, т.е. NOT MATCHED = NOT MATCHED BY TARGET
INSERT(EmployeeID,BonusDate,BonusAmount,BonusTypeID,BonusPercent,Note)
VALUES(src.EmployeeID,src.BonusDate,src.BonusAmount,src.BonusTypeID,src.BonusPercent,src.Note);
В общем, я постарался вам задать направление, более подробнее, в случае необходимости, изучайте уже самостоятельно.
Использование конструкции OUTPUT
Конструкция OUTPUT дает возможность получить информацию по строкам, которые были добавлены, удалены или изменены в результате выполнения DML команд INSERT, DELETE, UPDATE и MERGE. Данная конструкция, представляет расширение для операций модификации данных и в каждой СУБД может быть реализовано по-своему, либо вообще отсутствовать.
Конструкция OUTPUT имеет 2 основные формы:
- OUTPUT перечень_выражений – используется для возврата результата в виде набора
- OUTPUT перечень_выражений INTO принимающая_таблица(список_полей) – используется для вставки результата в указанную таблицу
Рассмотрим первую форму
Добавим в таблицу Positions новые записи:
INSERT Positions(Name)
OUTPUT inserted.*
VALUES
(N'Test 1'),
(N'Test 2'),
(N'Test 3')
После выполнения данной операции, записи будут вставлены в таблицу Positions и в добавок мы увидим информацию по добавленным строкам на экране.
Ключевое слово «inserted» дает нам доступ к значениям добавленных строк. В данном случае использование «inserted.*» вернет нам информацию по всем полям, которые есть в таблице Positions (ID и Name).
Так же после OUTPUT вы можете явно указать возвращаемый на экран перечень полей посредством «inserted.имя_поля», также вы можете использовать разные выражения:
INSERT Positions(Name)
OUTPUT inserted.ID,inserted.Name,'I'
VALUES
(N'Test 4'),
(N'Test 5'),
(N'Test 6')
При использовании DML команды DELETE, доступ к значениям измененных строк получается при помощи ключевого слова «deleted»:
DELETE Positions
OUTPUT deleted.ID,deleted.Name,'D'
WHERE Name LIKE N'Test%'
При использовании DML команды UPDATE, мы можем использовать ключевое слово:
- deleted – для того, чтобы получить доступ к значениям строки, которые были до обновления (старые значения)
- inserted – для того, чтобы получить новые значения строки
Продемонстрируем на таблице Employees:
UPDATE Employees
SET
LastName=N'Александров',
FirstName=N'Александр'
OUTPUT
deleted.ID,
deleted.LastName [Старая Фамилия],
deleted.FirstName [Старое Имя],
inserted.ID,
inserted.LastName [Новая Фамилия],
inserted.FirstName [Новое Имя]
WHERE ID=1005
| ID | Старая Фамилия | Старое Имя | ID | Новая Фамилия | Новое Имя |
|---|---|---|---|---|---|
| 1005 | NULL | NULL | 1005 | Александров | Александр |
В случае MERGE мы можем так же использовать «inserted» и «deleted» для доступа к значениям обработанных строк.
Давайте для примера создадим таблицу PositionsTarget, на которой после будет показан пример с MERGE:
SELECT
CAST(ID AS int) ID, -- чтобы поле создалось без опции IDENTITY
Name+'-old' Name -- изменим название
INTO PositionsTarget
FROM Positions
WHERE ID=2 -- вставим только одну должность
Добавим в PositionsTarget мусора:
INSERT PositionsTarget(ID,Name)VALUES
(100,N'Qwert'),
(101,N'Asdf')
Выполним команду MERGE с конструкцией OUTPUT:
MERGE PositionsTarget trg -- таблица приемник
USING Positions src -- таблица источник
ON trg.ID=src.ID -- условие слияния
-- 1. Строка есть в trg но нет сопоставления со строкой из src
WHEN NOT MATCHED BY SOURCE THEN
DELETE
-- 2. Есть сопоставление строки trg со строкой из источника src
WHEN MATCHED THEN
UPDATE SET
trg.Name=src.Name
-- 3. Строка не найдена в trg, но есть в src
WHEN NOT MATCHED BY TARGET THEN -- предложение BY TARGET можно отпускать, т.е. NOT MATCHED = NOT MATCHED BY TARGET
INSERT(ID,Name)
VALUES(src.ID,src.Name)
OUTPUT
deleted.ID Old_ID,
deleted.Name Old_Name,
inserted.ID New_ID,
inserted.Name New_Name,
CASE
WHEN deleted.ID IS NOT NULL AND inserted.ID IS NOT NULL THEN 'U'
WHEN deleted.ID IS NOT NULL THEN 'D'
WHEN inserted.ID IS NOT NULL THEN 'I'
END OperType;
| Old_ID | Old_Name | New_ID | New_Name | OperType |
|---|---|---|---|---|
| NULL | NULL | 1 | Бухгалтер | I |
| 2 | Директор-old | 2 | Директор | U |
| NULL | NULL | 3 | Программист | I |
| NULL | NULL | 4 | Старший программист | I |
| 100 | Qwert | NULL | NULL | D |
| 101 | Asdf | NULL | NULL | D |
Думаю, назначение первой формы понятно – сделать модификацию и получить результат в виде набора, который можно вернуть пользователю.
Рассмотрим вторую форму
У конструкции OUTPUT, есть и более важное предназначение – она позволяет не только получить, но и зафиксировать (OUTPUT … INTO …) информацию о том, что уже произошло по факту, то есть после выполнения операции модификации. Она может оказаться полезна в случае логированния произошедших действий. В некоторых случаях, ее можно использовать как хорошую альтернативу тригерам (для прозрачности действий).
Давайте создадим демонстрационную таблицу, для логирования изменений по таблице Positions:
CREATE TABLE PositionsLog(
LogID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_PositionsLog PRIMARY KEY,
ID int,
Old_Name nvarchar(30),
New_Name nvarchar(30),
LogType char(1) NOT NULL,
LogDateTime datetime NOT NULL DEFAULT SYSDATETIME()
)
А теперь сделаем при помощи конструкции (OUTPUT … INTO …) запись в эту таблицу:
-- добавление
INSERT Positions(Name)
OUTPUT inserted.ID,inserted.Name,'I' INTO PositionsLog(ID,New_Name,LogType)
VALUES
(N'Test 1'),
(N'Test 2')
-- обновление
UPDATE Positions
SET
Name+=' - new' -- обратите внимание на синтаксис "+=", аналогично Name=Name+' - new'
OUTPUT
deleted.ID,
deleted.Name,
inserted.Name,
'U'
INTO PositionsLog(ID,Old_Name,New_Name,LogType)
WHERE Name LIKE N'Test%'
-- удаление
DELETE Positions
OUTPUT deleted.ID,deleted.Name,'D' INTO PositionsLog(ID,Old_Name,LogType)
WHERE Name LIKE N'Test%'
Посмотрите, что получилось:
SELECT * FROM PositionsLog
TRUNCATE TABLE – DDL-операция для быстрой очистки таблицы
Данный оператор является DDL-операцией и служит для быстрой очистки таблицы – удаляет все строки из нее. За более детальными подробностями обращайтесь в MSDN.
Некоторые вырезки из MSDN. TRUNCATE TABLE – удаляет все строки в таблице, не записывая в журнал удаление отдельных строк. Инструкция TRUNCATE TABLE похожа на инструкцию DELETE без предложения WHERE, однако TRUNCATE TABLE выполняется быстрее и требует меньших ресурсов системы и журналов транзакций.
Если таблица содержит столбец идентификаторов (столбец с опцией IDENTITY), счетчик этого столбца сбрасывается до начального значения, определенного для этого столбца. Если начальное значение не задано, используется значение по умолчанию, равное 1. Чтобы сохранить столбец идентификаторов, используйте инструкцию DELETE.
Инструкцию TRUNCATE TABLE нельзя использовать если на таблицу ссылается ограничение FOREIGN KEY. Таблицу, имеющую внешний ключ, ссылающийся сам на себя, можно усечь.
Пример:
TRUNCATE TABLE EmployeesBonusTarget
Заключение по операциям модификации данных
Здесь я наверно повторю, все что писал ранее.
Старайтесь в первую очередь написать запрос на модификацию как можно проще, в первую очередь попытайтесь выразить свое намерение при помощи базовых конструкций и в последнюю очередь прибегайте к использованию подзапросов.
Прежде чем запустить запрос на модификацию данных по условию, убедитесь, что он выбирает именно необходимые записи, а не больше и не меньше. Для этой цели воспользуйтесь операцией SELECT.
Не забывайте перед очень серьезными изменениями делать резервные копии, хотя бы той информации, которая будет подвергнута модификации, это можно сделать при помощи SELECT … INTO …
Помните, что модификация данных это очень серьезно.
Приложение 1 – бонус по оператору SELECT
Подумав, я решил дописать этот раздел для тех, кто дошел до конца.
В данном разделе я дам примеры с использованием некоторых расширенных конструкций:
- PIVOT
- UNPIVOT
- GROUP BY ROLLUP
- GROUP BY GROUPING SETS
Попробуйте разобрать каждый из следующих примеров самостоятельно, анализируя результаты выполнения запросов. Обращайте внимание на комментарии, которые я указал в текстах запросов, некоторые важные вещи указаны в них.
Получение сводных отчетов при помощи GROUP BY+CASE и конструкции PIVOT
Для начала давайте посмотрим, как можно создать сводный отчет при помощи конструкции GROUP BY и CASE-условий. Можно сказать, это классический способ создания сводных отчетов:
-- получение сводной таблицы при помощи GROUP BY
SELECT
EmployeeID,
SUM(CASE WHEN MONTH(BonusDate)=1 THEN BonusAmount END) BonusAmount1,
SUM(CASE WHEN MONTH(BonusDate)=2 THEN BonusAmount END) BonusAmount2,
SUM(CASE WHEN MONTH(BonusDate)=3 THEN BonusAmount END) BonusAmount3,
SUM(CASE WHEN MONTH(BonusDate)=4 THEN BonusAmount END) BonusAmount4,
SUM(CASE WHEN MONTH(BonusDate)=5 THEN BonusAmount END) BonusAmount5,
SUM(CASE WHEN MONTH(BonusDate)=6 THEN BonusAmount END) BonusAmount6,
SUM(CASE WHEN MONTH(BonusDate)=7 THEN BonusAmount END) BonusAmount7,
SUM(CASE WHEN MONTH(BonusDate)=8 THEN BonusAmount END) BonusAmount8,
SUM(CASE WHEN MONTH(BonusDate)=9 THEN BonusAmount END) BonusAmount9,
SUM(CASE WHEN MONTH(BonusDate)=10 THEN BonusAmount END) BonusAmount10,
SUM(CASE WHEN MONTH(BonusDate)=11 THEN BonusAmount END) BonusAmount11,
SUM(CASE WHEN MONTH(BonusDate)=12 THEN BonusAmount END) BonusAmount12,
SUM(BonusAmount) TotalBonusAmount
FROM EmployeesBonus
WHERE BonusDate BETWEEN '20140101' AND '20141231' -- отберем данные за 2014 год
GROUP BY EmployeeID
Теперь рассмотрим, как получить эти же данные при помощи конструкции PIVOT:
-- получение сводной таблицы при помощи PIVOT
SELECT
EmployeeID,
[1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12],
ISNULL([1],0)+ISNULL([2],0)+ISNULL([3],0)+ISNULL([4],0)+
ISNULL([5],0)+ISNULL([6],0)+ISNULL([7],0)+ISNULL([8],0)+
ISNULL([9],0)+ISNULL([10],0)+ISNULL([11],0)+ISNULL([12],0) TotalBonusAmount
FROM
(
/*
в данном подзапросе мы отберем только необходимые для свода данные:
- поля BonusMonth и BonusAmount будут задействованы в конструкции PIVOT
- прочие поля, в данном случае это только EmployeeID, будут использованны для группировки данных
*/
SELECT
EmployeeID,
MONTH(BonusDate) BonusMonth,
BonusAmount
FROM EmployeesBonus
WHERE BonusDate BETWEEN '20140101' AND '20141231'
) q
PIVOT(SUM(BonusAmount) FOR BonusMonth IN([1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])) p
В конструкции PIVOT кроме SUM, как вы думаю догадались, можно использовать и другие агрегатные функции (COUNT, AVG, MIN, MAX, …).
Конструкция UNPIVOT
Давайте теперь рассмотрим, как работает конструкция UNPIVOT. Для демонстрации сбросим сводный результат в таблицу DemoPivotTable:
SELECT
EmployeeID,
SUM(CASE WHEN MONTH(BonusDate)=1 THEN BonusAmount END) BonusAmount1,
SUM(CASE WHEN MONTH(BonusDate)=2 THEN BonusAmount END) BonusAmount2,
SUM(CASE WHEN MONTH(BonusDate)=3 THEN BonusAmount END) BonusAmount3,
SUM(CASE WHEN MONTH(BonusDate)=4 THEN BonusAmount END) BonusAmount4,
SUM(CASE WHEN MONTH(BonusDate)=5 THEN BonusAmount END) BonusAmount5,
SUM(CASE WHEN MONTH(BonusDate)=6 THEN BonusAmount END) BonusAmount6,
SUM(CASE WHEN MONTH(BonusDate)=7 THEN BonusAmount END) BonusAmount7,
SUM(CASE WHEN MONTH(BonusDate)=8 THEN BonusAmount END) BonusAmount8,
SUM(CASE WHEN MONTH(BonusDate)=9 THEN BonusAmount END) BonusAmount9,
SUM(CASE WHEN MONTH(BonusDate)=10 THEN BonusAmount END) BonusAmount10,
SUM(CASE WHEN MONTH(BonusDate)=11 THEN BonusAmount END) BonusAmount11,
SUM(CASE WHEN MONTH(BonusDate)=12 THEN BonusAmount END) BonusAmount12,
SUM(BonusAmount) TotalBonusAmount
INTO DemoPivotTable -- сбросим сводный результат в таблицу
FROM EmployeesBonus
WHERE BonusDate BETWEEN '20140101' AND '20141231'
GROUP BY EmployeeID
Первым делом посмотрите, как у нас выглядят данные в данной таблице:
SELECT *
FROM DemoPivotTable
Теперь применим к данной таблице конструкцию UNPIVOT:
-- демонстрация UNPIVOT
SELECT
*,
CAST(REPLACE(ColumnLabel,'BonusAmount','') AS int) BonusMonth
FROM DemoPivotTable
UNPIVOT(BonusAmount FOR ColumnLabel IN(BonusAmount1,BonusAmount2,BonusAmount3,BonusAmount4,
BonusAmount5,BonusAmount6,BonusAmount7,BonusAmount8,
BonusAmount9,BonusAmount10,BonusAmount11,BonusAmount12)) u
Обратите внимание, что NULL значения не войдут в результат.
Как вы наверно догадались, на месте таблицы может стоять и подзапрос с заданным для него псевдонимом.
GROUP BY ROLLUP и GROUP BY GROUPING SETS
Данные конструкции позволяют подбить промежуточные итоги по строкам.
Пример первый:
-- GROUP BY ROLLUP и функция GROUPING
SELECT
--GROUPING(YEAR(bonus.BonusDate)) g1,
--GROUPING(bonus.EmployeeID) g2,
--GROUPING(emp.Name) g3,
CASE
WHEN GROUPING(YEAR(bonus.BonusDate))=1 THEN 'Общий итог'
WHEN GROUPING(bonus.EmployeeID)=1 THEN 'Итого за '+CAST(YEAR(bonus.BonusDate) AS varchar(4))+' год'
END RowTitle,
emp.Name,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=1 THEN bonus.BonusAmount END) BonusAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=2 THEN bonus.BonusAmount END) BonusAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=3 THEN bonus.BonusAmount END) BonusAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=4 THEN bonus.BonusAmount END) BonusAmountQ4,
SUM(bonus.BonusAmount) TotalBonusAmount
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
GROUP BY ROLLUP(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)
-- исключаем ненужный итог обрабатывая GROUPING
HAVING NOT(GROUPING(YEAR(bonus.BonusDate))=0 AND GROUPING(bonus.EmployeeID)=0 AND GROUPING(emp.Name)=1)
Чтобы понять, как работает функции GROUPING, раскомментируйте поля g1, g2 и g3, чтобы они попали в результирующий набор, а также закомментируйте предложение HAVING.
Пример второй:
-- GROUP BY ROLLUP и функция GROUPING_ID
SELECT
/*
GROUPING_ID (a, b, c) input = GROUPING(a) + GROUPING(b) + GROUPING(c)
бинарное 001 = десятичное 1
бинарное 011 = десятичное 3
бинарное 111 = десятичное 7
*/
--GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name) gID,
CASE GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)
WHEN 7 THEN 'Общий итог'
WHEN 3 THEN 'Итого за '+CAST(YEAR(bonus.BonusDate) AS varchar(4))+' год'
END RowTitle,
emp.Name,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=1 THEN bonus.BonusAmount END) BonusAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=2 THEN bonus.BonusAmount END) BonusAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=3 THEN bonus.BonusAmount END) BonusAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=4 THEN bonus.BonusAmount END) BonusAmountQ4,
SUM(bonus.BonusAmount) TotalBonusAmount
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
GROUP BY ROLLUP(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)
-- исключаем ненужный итог обрабатывая GROUPING_ID
HAVING GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)<>1
Здесь для понимания, можете так же раскомментировать поле gID и закомментировать предложение HAVING.
Пример третий:
-- GROUP BY GROUPING SETS и функция GROUPING_ID
SELECT
/*
GROUPING_ID (a, b, c) input = GROUPING(a) + GROUPING(b) + GROUPING(c)
бинарное 001 = десятичное 1
бинарное 011 = десятичное 3
бинарное 111 = десятичное 7
*/
--GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name) gID,
CASE GROUPING_ID(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name)
WHEN 7 THEN 'Общий итог'
WHEN 3 THEN 'Итого за '+CAST(YEAR(bonus.BonusDate) AS varchar(4))+' год'
END RowTitle,
emp.Name,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=1 THEN bonus.BonusAmount END) BonusAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=2 THEN bonus.BonusAmount END) BonusAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=3 THEN bonus.BonusAmount END) BonusAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,bonus.BonusDate)=4 THEN bonus.BonusAmount END) BonusAmountQ4,
SUM(bonus.BonusAmount) TotalBonusAmount
FROM EmployeesBonus bonus
JOIN Employees emp ON bonus.EmployeeID=emp.ID
GROUP BY GROUPING SETS(
(YEAR(bonus.BonusDate),bonus.EmployeeID,emp.Name), -- Имя сотрудника
(YEAR(bonus.BonusDate)), -- Сумма по годам
() -- Общий итог
)
При помощи GROUPING SET можно явно указать какие именно итоги нам нужны, поэтому здесь можно обойтись без предложения HAVING.
Т.е. можно сказать, что GROUP BY ROLLUP частный случай GROUP BY GROUPING SETS, когда делается вывод всех итогов.
Пример использования FULL JOIN
Здесь для примера выведем для каждого сотрудника сводные данные по начислениям бонусов и ЗП, поквартально:
-- пример использования FULL JOIN
WITH cteBonus AS(
SELECT
YEAR(BonusDate) BonusYear,
EmployeeID,
SUM(CASE WHEN DATEPART(QUARTER,BonusDate)=1 THEN BonusAmount END) BonusAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,BonusDate)=2 THEN BonusAmount END) BonusAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,BonusDate)=3 THEN BonusAmount END) BonusAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,BonusDate)=4 THEN BonusAmount END) BonusAmountQ4,
SUM(BonusAmount) TotalBonusAmount
FROM EmployeesBonus
GROUP BY YEAR(BonusDate),EmployeeID
),
cteSalary AS(
SELECT
YEAR(SalaryDate) SalaryYear,
EmployeeID,
SUM(CASE WHEN DATEPART(QUARTER,SalaryDate)=1 THEN SalaryAmount END) SalaryAmountQ1,
SUM(CASE WHEN DATEPART(QUARTER,SalaryDate)=2 THEN SalaryAmount END) SalaryAmountQ2,
SUM(CASE WHEN DATEPART(QUARTER,SalaryDate)=3 THEN SalaryAmount END) SalaryAmountQ3,
SUM(CASE WHEN DATEPART(QUARTER,SalaryDate)=4 THEN SalaryAmount END) SalaryAmountQ4,
SUM(SalaryAmount) TotalSalaryAmount
FROM EmployeesSalary
GROUP BY YEAR(SalaryDate),EmployeeID
)
SELECT
ISNULL(s.SalaryYear,b.BonusYear) AccYear,
ISNULL(s.EmployeeID,b.EmployeeID) EmployeeID,
s.SalaryAmountQ1,s.SalaryAmountQ2,s.SalaryAmountQ3,s.SalaryAmountQ4,
s.TotalSalaryAmount,
b.BonusAmountQ1,b.BonusAmountQ2,b.BonusAmountQ3,b.BonusAmountQ4,
b.TotalBonusAmount,
ISNULL(s.TotalSalaryAmount,0)+ISNULL(b.TotalBonusAmount,0) TotalAmount
FROM cteSalary s
FULL JOIN cteBonus b ON s.EmployeeID=b.EmployeeID AND s.SalaryYear=b.BonusYear
Попробуйте самостоятельно разобрать, почему я здесь применил именно FULL JOIN. Посмотрите на результаты, которые дают запросы размещенные в блоке WITH.
Приложение 2 – OVER и аналитические функции
Предложение OVER служит для проведения дополнительных вычислений, на окончательном наборе, полученном оператором SELECT (в подзапросах или запросах). Поэтому предложения OVER может быть применено только в блоке SELECT, т.е. его нельзя использовать, например, в блоке WHERE.
Выражения с использованием OVER могут в некоторых ситуациях значительно сократить запрос. В данном приложении я постарался привести самые основные моменты с использованием данной конструкции. Надеюсь, что самостоятельная проработка каждого приведенного здесь запроса и их результатов, поможет вам разобраться с особенностями конструкции OVER и вы сможете применять ее по назначению (не злоупотребляя ими чрезмерно там, где можно обойтись без них и наоборот) при написании своих запросов.
Для демонстрационных целей, для получения более наглядных результатов, добавим немного новых данных:
-- добавим новые должности
SET IDENTITY_INSERT Positions ON
INSERT Positions(ID,Name)VALUES
(10,N'Маркетолог'),
(11,N'Логист')
SET IDENTITY_INSERT Positions OFF
-- новые сотрудники
INSERT Employees(ID,Name,DepartmentID,PositionID,HireDate,Salary,Email)VALUES
(1006,N'Антонов А.А.',4,10,'20150215',1800,'a.antonov@test.tt'),
(1007,N'Максимов М.М.',5,11,'20150405',1200,'m.maksimov@test.tt'),
(1008,N'Данилов Д.Д.',5,11,'20150410',1200,'d.danolov@test.tt'),
(1009,N'Остапов О.О.',5,11,'20150415',1200,'o.ostapov@test.tt')
Предложение OVER дает возможность делать агрегатные вычисления, без применения группировки
SELECT
ID,
Name,
DepartmentID,
Salary,
-- получаем сумму ЗП всех сотрудников
SUM(Salary) OVER() AllSalary,
-- получаем сумму ЗП сотрудников этого же отдела
SUM(Salary) OVER(PARTITION BY DepartmentID) DepartmentSalary,
-- процент ЗП сотрудника от суммы ЗП всего отдела
CAST(Salary/SUM(Salary) OVER(PARTITION BY DepartmentID)*100 AS numeric(20,3)) SalaryPercentOfDepSalary,
-- кол-во всех сотрудников
COUNT(*) OVER() AllEmplCount,
-- кол-во сотрудников в отделе
COUNT(*) OVER(PARTITION BY DepartmentID) DepEmplCount
FROM Employees
| ID | Name | DepartmentID | Salary | AllSalary | DepartmentSalary | SalaryPercentOfDepSalary | AllEmplCount | DepEmplCount |
|---|---|---|---|---|---|---|---|---|
| 1005 | Александров А.А. | NULL | 2000.00 | 19900.00 | 2000.00 | 100.000 | 10 | 1 |
| 1000 | Иванов И.И. | 1 | 5000.00 | 19900.00 | 5000.00 | 100.000 | 10 | 1 |
| 1002 | Сидоров С.С. | 2 | 2500.00 | 19900.00 | 2500.00 | 100.000 | 10 | 1 |
| 1003 | Андреев А.А. | 3 | 2000.00 | 19900.00 | 5000.00 | 40.000 | 10 | 3 |
| 1004 | Николаев Н.Н. | 3 | 1500.00 | 19900.00 | 5000.00 | 30.000 | 10 | 3 |
| 1001 | Петров П.П. | 3 | 1500.00 | 19900.00 | 5000.00 | 30.000 | 10 | 3 |
| 1006 | Антонов А.А. | 4 | 1800.00 | 19900.00 | 1800.00 | 100.000 | 10 | 1 |
| 1007 | Максимов М.М. | 5 | 1200.00 | 19900.00 | 3600.00 | 33.333 | 10 | 3 |
| 1008 | Данилов Д.Д. | 5 | 1200.00 | 19900.00 | 3600.00 | 33.333 | 10 | 3 |
| 1009 | Остапов О.О. | 5 | 1200.00 | 19900.00 | 3600.00 | 33.333 | 10 | 3 |
Предложение «PARTITION BY» позволяет сделать разбиение данных по группам, можно сказать выполняет здесь роль «GROUP BY».
Можно задать группировку по нескольким полям, использовать выражения, например, «PARTITION BY DepartmentID,PositionID», «PARTITION BY DepartmentID,YEAR(HireDate)».
Поэкспериментируйте и с другими агрегатными функциями, которые мы разбирали – AVG, MIN, MAX, COUNT с DISTINCT.
Нумерация и ранжирование строк
Для цели нумерации строк используется функция ROW_NUMBER.
Пронумеруем сотрудников по полю Name и по нескольким полям LastName,FirstName,MiddleName:
SELECT
ID,
Name,
-- нумирация в порядке значений Name
ROW_NUMBER() OVER(ORDER BY Name) EmpNoByName,
-- нумирация в порядке значений LastName,FirstName,MiddleName
ROW_NUMBER() OVER(ORDER BY LastName,FirstName,MiddleName) EmpNoByFullName
FROM Employees
ORDER BY Name
| ID | Name | EmpNoByName | EmpNoByFullName |
|---|---|---|---|
| 1005 | Александров А.А. | 1 | 6 |
| 1003 | Андреев А.А. | 2 | 7 |
| 1006 | Антонов А.А. | 3 | 1 |
| 1008 | Данилов Д.Д. | 4 | 2 |
| 1000 | Иванов И.И. | 5 | 8 |
| 1007 | Максимов М.М. | 6 | 3 |
| 1004 | Николаев Н.Н. | 7 | 4 |
| 1009 | Остапов О.О. | 8 | 5 |
| 1001 | Петров П.П. | 9 | 9 |
| 1002 | Сидоров С.С. | 10 | 10 |
Здесь для задания порядка в OVER используется предложение «ORDER BY».
Для разбиения на группы, здесь так же в OVER можно использовать предложение «PARTITION BY»:
SELECT
emp.ID,
emp.Name EmpName,
dep.Name DepName,
-- нумирация сотрудников в разрезе отделов, в порядке значений Name
ROW_NUMBER() OVER(PARTITION BY dep.ID ORDER BY emp.Name) EmpNoInDepByName
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
ORDER BY dep.Name,emp.Name
| ID | EmpName | DepName | EmpNoInDepByName |
|---|---|---|---|
| 1005 | Александров А.А. | NULL | 1 |
| 1000 | Иванов И.И. | Администрация | 1 |
| 1002 | Сидоров С.С. | Бухгалтерия | 1 |
| 1003 | Андреев А.А. | ИТ | 1 |
| 1004 | Николаев Н.Н. | ИТ | 2 |
| 1001 | Петров П.П. | ИТ | 3 |
| 1008 | Данилов Д.Д. | Логистика | 1 |
| 1007 | Максимов М.М. | Логистика | 2 |
| 1009 | Остапов О.О. | Логистика | 3 |
| 1006 | Антонов А.А. | Маркетинг и реклама | 1 |
Ранжирование строк – это можно сказать нумерация, только группами. Есть 2 вида нумерации, с дырками (RANK) и без дырок (DENSE_RANK).
SELECT
emp.ID,
emp.Name EmpName,
emp.PositionID,
-- кол-во сотрудников в разрезе должностей
COUNT(*) OVER(PARTITION BY emp.PositionID) EmpCountInPos,
-- ранжирование с дырками - следующий номер зависит от кол-ва записей в предыдущей группе
RANK() OVER(ORDER BY emp.PositionID) RankValue,
-- ранжирование без дырок – плотная нумерация (последовательная)
DENSE_RANK() OVER(ORDER BY emp.PositionID) DenseRankValue
FROM Employees emp
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
| ID | EmpName | PositionID | EmpCountInPos | RankValue | DenseRankValue |
|---|---|---|---|---|---|
| 1005 | Александров А.А. | NULL | 1 | 1 | 1 |
| 1002 | Сидоров С.С. | 1 | 1 | 2 | 2 |
| 1000 | Иванов И.И. | 2 | 1 | 3 | 3 |
| 1001 | Петров П.П. | 3 | 2 | 4 | 4 |
| 1004 | Николаев Н.Н. | 3 | 2 | 4 | 4 |
| 1003 | Андреев А.А. | 4 | 1 | 6 | 5 |
| 1006 | Антонов А.А. | 10 | 1 | 7 | 6 |
| 1007 | Максимов М.М. | 11 | 3 | 8 | 7 |
| 1008 | Данилов Д.Д. | 11 | 3 | 8 | 7 |
| 1009 | Остапов О.О. | 11 | 3 | 8 | 7 |
Аналитические функции: LAG() и LEAD(), FIRST_VALUE() и LAST_VALUE()
Данные функции позволяют получить значения другой строки относительно текущей строки.
Рассмотрим LAG() и LEAD():
SELECT
ID CurrEmpID,
Name CurrEmpName,
-- значения предыдущей строки
LAG(ID) OVER(ORDER BY ID) PrevEmpID,
LAG(Name) OVER(ORDER BY ID) PrevEmpName,
LAG(ID,2) OVER(ORDER BY ID) PrevPrevEmpID,
LAG(Name,2,'not found') OVER(ORDER BY ID) PrevPrevEmpName,
-- значения следующей строки
LEAD(ID) OVER(ORDER BY ID) NextEmpID,
LEAD(Name) OVER(ORDER BY ID) NextEmpName,
LEAD(ID,2) OVER(ORDER BY ID) NextNextEmpID,
LEAD(Name,2,'not found') OVER(ORDER BY ID) NextNextEmpName
FROM Employees
ORDER BY ID
| CurrEmpID | CurrEmpName | PrevEmpID | PrevEmpName | PrevPrevEmpID | PrevPrevEmpName | NextEmpID | NextEmpName | NextNextEmpID | NextNextEmpName |
|---|---|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | NULL | not found | 1001 | Петров П.П. | 1002 | Сидоров С.С. |
| 1001 | Петров П.П. | 1000 | Иванов И.И. | NULL | not found | 1002 | Сидоров С.С. | 1003 | Андреев А.А. |
| 1002 | Сидоров С.С. | 1001 | Петров П.П. | 1000 | Иванов И.И. | 1003 | Андреев А.А. | 1004 | Николаев Н.Н. |
| 1003 | Андреев А.А. | 1002 | Сидоров С.С. | 1001 | Петров П.П. | 1004 | Николаев Н.Н. | 1005 | Александров А.А. |
| 1004 | Николаев Н.Н. | 1003 | Андреев А.А. | 1002 | Сидоров С.С. | 1005 | Александров А.А. | 1006 | Антонов А.А. |
| 1005 | Александров А.А. | 1004 | Николаев Н.Н. | 1003 | Андреев А.А. | 1006 | Антонов А.А. | 1007 | Максимов М.М. |
| 1006 | Антонов А.А. | 1005 | Александров А.А. | 1004 | Николаев Н.Н. | 1007 | Максимов М.М. | 1008 | Данилов Д.Д. |
| 1007 | Максимов М.М. | 1006 | Антонов А.А. | 1005 | Александров А.А. | 1008 | Данилов Д.Д. | 1009 | Остапов О.О. |
| 1008 | Данилов Д.Д. | 1007 | Максимов М.М. | 1006 | Антонов А.А. | 1009 | Остапов О.О. | NULL | not found |
| 1009 | Остапов О.О. | 1008 | Данилов Д.Д. | 1007 | Максимов М.М. | NULL | NULL | NULL | not found |
В данных функциях вторым параметром можно указать сдвиг относительно текущей строки, а третьим параметром можно указать возвращаемое значение для случая если для указанного смещения строки не существует.
Для разбиения данных по группам, попробуйте самостоятельно добавить предложение «PARTITION BY» в OVER, например, «OVER(PARTITION BY emp.DepartmentID ORDER BY emp.ID)».
Рассмотрим FIRST_VALUE() и LAST_VALUE():
SELECT
ID CurrEmpID,
Name CurrEmpName,
DepartmentID,
-- первое значение в группе
FIRST_VALUE(ID) OVER(PARTITION BY DepartmentID ORDER BY ID) FirstEmpID,
FIRST_VALUE(Name) OVER(PARTITION BY DepartmentID ORDER BY ID) FirstEmpName,
-- последнее значение в группе
LAST_VALUE(ID) OVER(PARTITION BY DepartmentID ORDER BY ID RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) LastEmpID,
LAST_VALUE(Name) OVER(PARTITION BY DepartmentID ORDER BY ID RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) LastEmpName
FROM Employees
ORDER BY DepartmentID,ID
| CurrEmpID | CurrEmpName | DepartmentID | FirstEmpID | FirstEmpName | LastEmpID | LastEmpName |
|---|---|---|---|---|---|---|
| 1005 | Александров А.А. | NULL | 1005 | Александров А.А. | 1005 | Александров А.А. |
| 1000 | Иванов И.И. | 1 | 1000 | Иванов И.И. | 1000 | Иванов И.И. |
| 1002 | Сидоров С.С. | 2 | 1002 | Сидоров С.С. | 1002 | Сидоров С.С. |
| 1001 | Петров П.П. | 3 | 1001 | Петров П.П. | 1004 | Николаев Н.Н. |
| 1003 | Андреев А.А. | 3 | 1001 | Петров П.П. | 1004 | Николаев Н.Н. |
| 1004 | Николаев Н.Н. | 3 | 1001 | Петров П.П. | 1004 | Николаев Н.Н. |
| 1006 | Антонов А.А. | 4 | 1006 | Антонов А.А. | 1006 | Антонов А.А. |
| 1007 | Максимов М.М. | 5 | 1007 | Максимов М.М. | 1009 | Остапов О.О. |
| 1008 | Данилов Д.Д. | 5 | 1007 | Максимов М.М. | 1009 | Остапов О.О. |
| 1009 | Остапов О.О. | 5 | 1007 | Максимов М.М. | 1009 | Остапов О.О. |
Думаю, здесь все понятно. Стоит только объяснить, что такое RANGE.
Параметры RANGE и ROWS
При помощи дополнительных параметров «RANGE» и «ROWS», можно изменить область работы функции, которая работает с предложением OVER. У каждой функции по умолчанию используется какая-то своя область действия. Такая область обычно называется окном.
Важное замечание. В разных СУБД для одних и тех же функций область по умолчанию может быть разной, поэтому нужно быть внимательным и смотреть справку конкретной СУБД по каждой отдельной функции.
Можно создавать окна по двум критериям:
- по диапазону (RANGE) значений данных
- по смещению (ROWS) относительно текущей строки
Общий синтаксис этих опций выглядит следующим образом:
Вариант 1:
{ROWS | RANGE} {{UNBOUNDED | выражение} PRECEDING | CURRENT ROW}
Вариант 2:
{ROWS | RANGE}
BETWEEN
{{UNBOUNDED PRECEDING | CURRENT ROW |
{UNBOUNDED | выражение 1}{PRECEDING | FOLLOWING}}
AND
{{UNBOUNDED FOLLOWING | CURRENT ROW |
{UNBOUNDED | выражение 2}{PRECEDING | FOLLOWING}}
Здесь проще понять если проанализировать в Excel результат запроса:
SELECT
ID,
Salary,
SUM(Salary) OVER() Sum1,
-- сумма всех строк - "все предыдущие" и "все последующие"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN unbounded preceding AND unbounded following) Sum2,
-- сумма строк до текущей строки включительно - "все предыдущие" и "текущая строка"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN unbounded preceding AND current row) Sum3,
-- сумма всех последующих от текущей строки включительно - "текущая строка" и "все последующие"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN current row AND unbounded following) Sum4,
-- сумма следующих трех строк - "1 следующую" и "3 следующие"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN 1 following AND 3 following) Sum5,
-- сумма трех строк - "1 предыдущая" и "1 следующую"
SUM(Salary) OVER(ORDER BY ID ROWS BETWEEN 1 preceding AND 1 following) Sum6,
-- сумма предыдущих "трех предыдущих" и "текущей"
SUM(Salary) OVER(ORDER BY ID ROWS 3 preceding) Sum7,
-- сумма "всех предыдущих" и "текущей"
SUM(Salary) OVER(ORDER BY ID ROWS unbounded preceding) Sum8
FROM Employees
ORDER BY ID
| ID | Salary | Sum1 | Sum2 | Sum3 | Sum4 | Sum5 | Sum6 | Sum7 | Sum8 |
|---|---|---|---|---|---|---|---|---|---|
| 1000 | 5000.00 | 19900.00 | 19900.00 | 5000.00 | 19900.00 | 6000.00 | 6500.00 | 5000.00 | 5000.00 |
| 1001 | 1500.00 | 19900.00 | 19900.00 | 6500.00 | 14900.00 | 6000.00 | 9000.00 | 6500.00 | 6500.00 |
| 1002 | 2500.00 | 19900.00 | 19900.00 | 9000.00 | 13400.00 | 5500.00 | 6000.00 | 9000.00 | 9000.00 |
| 1003 | 2000.00 | 19900.00 | 19900.00 | 11000.00 | 10900.00 | 5300.00 | 6000.00 | 11000.00 | 11000.00 |
| 1004 | 1500.00 | 19900.00 | 19900.00 | 12500.00 | 8900.00 | 5000.00 | 5500.00 | 7500.00 | 12500.00 |
| 1005 | 2000.00 | 19900.00 | 19900.00 | 14500.00 | 7400.00 | 4200.00 | 5300.00 | 8000.00 | 14500.00 |
| 1006 | 1800.00 | 19900.00 | 19900.00 | 16300.00 | 5400.00 | 3600.00 | 5000.00 | 7300.00 | 16300.00 |
| 1007 | 1200.00 | 19900.00 | 19900.00 | 17500.00 | 3600.00 | 2400.00 | 4200.00 | 6500.00 | 17500.00 |
| 1008 | 1200.00 | 19900.00 | 19900.00 | 18700.00 | 2400.00 | 1200.00 | 3600.00 | 6200.00 | 18700.00 |
| 1009 | 1200.00 | 19900.00 | 19900.00 | 19900.00 | 1200.00 | NULL | 2400.00 | 5400.00 | 19900.00 |
С RANGE все тоже самое, только здесь смещения идут не относительно строк, а относительно их значений. Поэтому в данном случае в ORDER BY допустимы значения только типа дата или число.
SELECT
PositionID,
Salary,
SUM(Salary) OVER(PARTITION BY PositionID) Sum1,
-- сумма ЗП для всех значений PositionID - "все меньшие" и "все большие"
SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN unbounded preceding AND unbounded following) Sum2,
-- сумма ЗП для значений меньших PositionID до текущего значения включительно - "все меньшие" и "текущее значение" (значения<=PositionID)
SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN unbounded preceding AND current row) Sum3,
-- сумма ЗП для всех больших значений от текущего значения включительно - "текущее значение" и "все большие" (значения>=PositionID)
SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN current row AND unbounded following) Sum4,
/*
Увы следующие комбинации для RANGE в MS SQL не работают, хотя в Oracle они работают.
Вырезки из MSDN:
Предложение RANGE не может использоваться со <спецификацией неподписанного значения> PRECEDING или со <спецификацией неподписанного значения> FOLLOWING.
<спецификация неподписанного значения> PRECEDING
Указывается с <беззнаковым указанием значения> для обозначения числа строк или значений перед текущей строкой.
Эта спецификация не допускается в предложении RANGE.
<спецификация неподписанного значения> FOLLOWING
Указывается с <беззнаковым указанием значения> для обозначения числа строк или значений после текущей строки.
Эта спецификация не допускается в предложении RANGE.
*/
-- сумма ЗП для трех значений - "+1" и "+3" (значение BETWEEN PositionID+1 AND PositionID+3)
--SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN 1 following AND 3 following) Sum5,
-- сумма ЗП для трех значений - "-1" и "+1" (значение BETWEEN PositionID-1 AND PositionID+1)
--SUM(Salary) OVER(ORDER BY PositionID RANGE BETWEEN 1 preceding AND 1 following) Sum6,
-- сумма ЗП для предыдущих трех значений - "-3" и "текущее" (значение BETWEEN PositionID-3 AND PositionID)
--SUM(Salary) OVER(ORDER BY PositionID RANGE 3 preceding) Sum7,
-- сумма ЗП для "всех предыдущих значений" и "текущего" (значения<=PositionID)
SUM(Salary) OVER(ORDER BY PositionID RANGE unbounded preceding) Sum8
FROM Employees
ORDER BY PositionID
| PositionID | Salary | Sum1 | Sum2 | Sum3 | Sum4 | Sum8 |
|---|---|---|---|---|---|---|
| NULL | 2000.00 | 2000.00 | 19900.00 | 2000.00 | 19900.00 | 2000.00 |
| 1 | 2500.00 | 2500.00 | 19900.00 | 4500.00 | 17900.00 | 4500.00 |
| 2 | 5000.00 | 5000.00 | 19900.00 | 9500.00 | 15400.00 | 9500.00 |
| 3 | 1500.00 | 3000.00 | 19900.00 | 12500.00 | 10400.00 | 12500.00 |
| 3 | 1500.00 | 3000.00 | 19900.00 | 12500.00 | 10400.00 | 12500.00 |
| 4 | 2000.00 | 2000.00 | 19900.00 | 14500.00 | 7400.00 | 14500.00 |
| 10 | 1800.00 | 1800.00 | 19900.00 | 16300.00 | 5400.00 | 16300.00 |
| 11 | 1200.00 | 3600.00 | 19900.00 | 19900.00 | 3600.00 | 19900.00 |
| 11 | 1200.00 | 3600.00 | 19900.00 | 19900.00 | 3600.00 | 19900.00 |
| 11 | 1200.00 | 3600.00 | 19900.00 | 19900.00 | 3600.00 | 19900.00 |
Заключение
Вот и все, уважаемые читатели, на этом я оканчиваю свой учебник по SQL (DDL, DML).
Надеюсь, что вам было интересно провести время за прочтением данного материала, а главное надеюсь, что он принес вам понимание самых важных базовых конструкций языка SQL.
Учитесь, практикуйтесь, добивайтесь получения правильных результатов.
Спасибо за внимание! На этом пока все.
PS. Отдельное спасибо всем, кто помогал сделать данный материал лучше, указывая на опечатки или давая дельные советы!
