Доброго времени суток, уважаемые Хабровчане.
В качестве краткой предыстории: год назад, придя на новое место работы в качестве руководителя отдела разработки БД (на базе Microsoft SQL Server), я испытал глубочайший шок от увиденного. Крупная компания, сложное веб-приложение, многомиллионные контракты, а разработка ведется на production-БД, баг-репорты поступают и обрабатываются по методике «кто громче крикнет» или «надо сделать прям вчера». Естественно ни о системе контроля версий, continuous integration, процедурах и workflow речи и не шло.
Сегодня ситуация сильно изменилась (хотя, кого я обманываю — только начинает меняться) и я хотел бы поделиться как техническими, так и процедурными деталями решений, которые мы используем сейчас. Технические детали на 90% касаются непосредственно разработки для Microsoft SQL Server, а вот процедурные изменения у нас коснулись и веб-девелоперов, и инженеров, и аналитиков, и тестеров.
Сразу оговорюсь, я не являюсь представителем компаний/рекламщиком программных продуктов, которые я буду упоминать в статье. Выбор используемого софта лучше всего подходил для наших задач по функционалу, цене, а также удовлетворял моим личным предпочтениям.
Кому интересны подробности — добро пожаловать под кат.
Warning: очень много текста, описания процедур и процессов (которые, может, никому и не интересны).
В качестве системы учета заявок было выбрано решение на базе Atlassian JIRA. Основными причинами были: тесная интеграция с другими продуктами, которые будут упоминаться в статье; крайне удобная работа по agile-методологии разработки; широкие возможности по кастомизации и автоматизации процессов.
Мы решили придерживаться двух-недельных Agile-спринтов с планированием разработки и тестирования на 3 спринта (т.е. на 1.5 месяца) вперед. О деталях самого процесса ниже.
Не скрою, я являюсь фанатом продуктов Atlassian. Для системы контроля версий был выбрал Atlassian Stash (Git). Однако применений веток разработки (branching), слияния веток (merging) и прочим прелестям Git в процессе разработки кода БД мы не нашли. Все коммиты происходят в master branch.
Для коммитов мы используем продукт RedGate Source Control (плагин для SSMS). Здесь мы столкнулись с первой технической сложностью: мне хотелось, чтобы по нажатию кнопки «Commit» в SSMS — код не просто коммитился, а также происходил push в репозиторий. Это оправдано с точки зрения разработки на shared-БД. Пока ведется разработка (изменения кода хранимой процедуры, изменение структуры таблиц) — изменения хранятся в самой базе. Как только разработка завершена код нужно видеть в source control. Как известно работа с Git представляет собой работу с локальным репозиторием, изменения из которого затем пушатся в репозиторий. К сожалению RedGate SC не умеет делать push «из коробки».
Для обхода данного ограничения было написано 2 bat-скрипта для RedGate, которые используются как pull и commit hooks. Когда разработчик обновляет список изменений в окне плагина — выполняется Pull, при котором репозиторий на станции разработчика становится идентичным текущему состоянию репозитория. Так, в списке на commit, остаются только изменения, которые присутствуют в БД, но отсутствуют в системе контроля версий.
После выбора изменений (к примеру хранимая процедура и таблица), которые следует закоммитить и нажатия кнопки Commit — изменения попадают в локальный репозиторий, а после этого, автоматически происходит push в Git.
Прикладываю файл конфигурации RedGate Source Control, а также исходники pull.bat и commit.bat, которые в нем используются:
Как можно заметить, работа со Stash/Git ведется через SSH с авторизацией по ключам. Первичная настройка Red-Gate задокументирована и по факту имеет 2 шага: установить плагин и запустить скрипт первоначальной настройки (который сам создаст нужные папки в профиле пользователя и сделает первый clone репозитория).
Думаю, тут стоит прерваться на то, как выстроен сам workflow для разработчиков. Обращу внимание, что все шаги процесса форсированы с помощью JIRA, где также производятся проверки различных условий для определения возможности или невозможности выполнения перехода (transition) задачи из одного статуса в другой.
Как обычно процесс начинается с создания Issue в JIRA. Это может быть баг-репорт, запрос новой фичи, модификация существующей фичи или идея. В зависимости от выбранного компонента, типа issue и due date данному билету выставляется приоритет. После этого он попадает в очередь планирования. Issue с высоким приоритетом в очереди планирования рассматриваются и планируются в течение 24-48 часов, все остальное — раз в неделю на планерках команды.
Под «планированием» я подразумеваю определение сложности и этапов задачи, объемов требуемой документации, общение с человеком от которого поступила заявка (для выяснения подробностей) и принятия решения о том в какой Agile Sprint следует поместить решение данной задачи.
Такой процесс требует обязательного выставления предварительной оценки сроков, необходимых для выполнения задачи. Спринты мы стараемся выстраивать таким образом, чтобы каждый разработчик был занят 33 часа в неделю. Оставшиеся 7 часов оставляем в качестве буфера для реакции на срочные задачи, встречи и ситуации, когда другой разработчик вышел на больничный/ушел в отпуск.
В случае «переполнения» текущего/будущего спринта требуется принимать решение о том, какие задачи мы можем отодвинуть на более поздний срок. Аналогично, в случае если разработчик остался без работы в течение спринта — можно переместить и взяться за выполнение задачи, запланированной на следующее окно.
Задачи могут находится в следующих статусах:
Перемещения задач между статусами возможны только согласно следующей схеме:
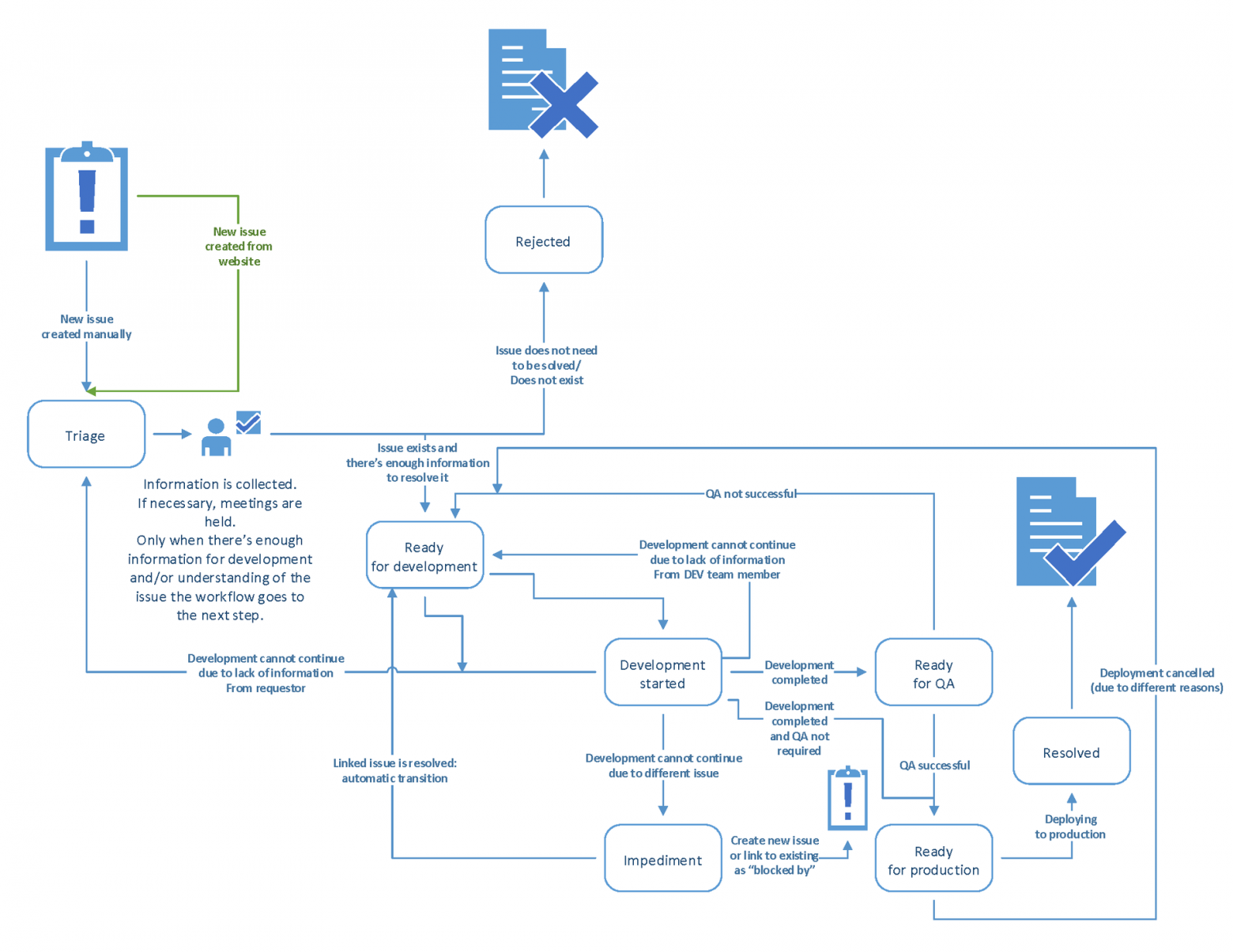
Ситуации, при которых должно происходить перемещение описаны на схеме (хоть и на английском, но думаю понимание не составит проблемы для читателей), так что повторяться я не буду. Лучше расскажу о том, чего на схеме не видно:
Краткое отступление: описанные процессы совместимы с IEEE стандартами по разработке.
В качестве решения для ревью изменений кода мы используем Atlassian (да неужели?!) Fisheye/Crucible. Полная интеграция с JIRA и Stash позволяет быстро переходить со страницы issue к просмотру связанных коммитов и code-ревью. Никаких хитростей с интеграцией JIRA+Stash+Crucible/Fisheye нет, так что и рассказывать мне по этой теме больше нечего.
На мой взгляд это самая интересная часть нашего процесса (относительно БД). Как упоминалось ранее, мы работаем с общей (shared) базой данных, всего используется три сепарированных среды: Development, Test/QA и Production.
Development база данных всегда имеет самую последнюю версию, т.к. разработчики постоянно меняют код и схему именно в ней. Front-end приложение, которое обращается к данной базе также обновляется постоянно (как только у веб-разработчиков локально собрался (без ошибок) билд с новой фичей/исправлением — он сразу публикуется).
Все изменения в DEV публикуются в QA. Однако, говоря „все“ — я лукавлю. Публикуются только те изменения, которые закоммичены в source control (мы же не хотим публиковать что-то, что еще находится „в процессе разработки“). Так что вместо банальной синхронизации схемы мы используем возможности RedGate SQL CI и нашего билд-сервера — Atlassian Bamboo.
В Bamboo создан MSBuild план, который вызывает SQL CI. Как только происходит коммит SQL CI генерирует ALTER и CREATE команды, и накатывает их на QA базу данных.
Хоть мне и известно, что „настоящей“ непрерывной интеграцией следует считать такую же публикацию изменений на production, однако у меня не хватает смелости так делать. Вместо этого мы используем RedGate SQL Compare для синхронизации схемы с QA при закрытии спринта. Соответственно, если смотреть с точки зрения процесса — QA база для нас является production. Однако это не меняет подхода, который следует применять при разработке БД используя этот процесс — ни одно изменение не должно быть фатальным (breaking). В мире Microsoft SQL Server в качестве БД для веб-приложений это значит что при публикации версии процедур должны корректно завершаться и не вызывать deadlock-ов. Безусловно это требует соответствующей архитектуры веб-приложения — все запросы выполняются через хранимые процедуры, классы должны поддерживать отсутствие ожидаемых параметров у процедуры или их большее количество. Процедуры же должны поддерживать NULL-параметры и соответствующим образом реагировать на такие ситуации, не создавая угроз безопасности. В нашем случае это представляется возможным.
Я понимаю, что описанный мною сценарий может быть крайне специфичен, а его применение невозможно в других условиях. Однако я писал это с целью поделиться опытом с сообществом, и надеждой что может быть я познакомлю кого-то с новыми инструментами или дам шанс взглянуть на чужой процесс разработки — может Вы увидите где можно улучшить собственные процедуры, а может увидите моменты, в которых Ваш подход грамотнее и логичнее. Хотел рассказать гораздо больше — о том, как устроено и интегрировано в этот процесс автоматизированное тестирование (automated unit testing и integration testing), как мы используем Microsoft Data Quality Services для процесса QA, как организована документация, но текста получилось и так слишком много. Может сделаю это в отдельной статье. Ну а пока, буду рад вопросам и конструктивной критике.
В качестве краткой предыстории: год назад, придя на новое место работы в качестве руководителя отдела разработки БД (на базе Microsoft SQL Server), я испытал глубочайший шок от увиденного. Крупная компания, сложное веб-приложение, многомиллионные контракты, а разработка ведется на production-БД, баг-репорты поступают и обрабатываются по методике «кто громче крикнет» или «надо сделать прям вчера». Естественно ни о системе контроля версий, continuous integration, процедурах и workflow речи и не шло.
Сегодня ситуация сильно изменилась (хотя, кого я обманываю — только начинает меняться) и я хотел бы поделиться как техническими, так и процедурными деталями решений, которые мы используем сейчас. Технические детали на 90% касаются непосредственно разработки для Microsoft SQL Server, а вот процедурные изменения у нас коснулись и веб-девелоперов, и инженеров, и аналитиков, и тестеров.
Сразу оговорюсь, я не являюсь представителем компаний/рекламщиком программных продуктов, которые я буду упоминать в статье. Выбор используемого софта лучше всего подходил для наших задач по функционалу, цене, а также удовлетворял моим личным предпочтениям.
Кому интересны подробности — добро пожаловать под кат.
Warning: очень много текста, описания процедур и процессов (которые, может, никому и не интересны).
Баг-трекинг, планирование и отслеживание проекта
В качестве системы учета заявок было выбрано решение на базе Atlassian JIRA. Основными причинами были: тесная интеграция с другими продуктами, которые будут упоминаться в статье; крайне удобная работа по agile-методологии разработки; широкие возможности по кастомизации и автоматизации процессов.
Мы решили придерживаться двух-недельных Agile-спринтов с планированием разработки и тестирования на 3 спринта (т.е. на 1.5 месяца) вперед. О деталях самого процесса ниже.
Система контроля версий
Не скрою, я являюсь фанатом продуктов Atlassian. Для системы контроля версий был выбрал Atlassian Stash (Git). Однако применений веток разработки (branching), слияния веток (merging) и прочим прелестям Git в процессе разработки кода БД мы не нашли. Все коммиты происходят в master branch.
Для коммитов мы используем продукт RedGate Source Control (плагин для SSMS). Здесь мы столкнулись с первой технической сложностью: мне хотелось, чтобы по нажатию кнопки «Commit» в SSMS — код не просто коммитился, а также происходил push в репозиторий. Это оправдано с точки зрения разработки на shared-БД. Пока ведется разработка (изменения кода хранимой процедуры, изменение структуры таблиц) — изменения хранятся в самой базе. Как только разработка завершена код нужно видеть в source control. Как известно работа с Git представляет собой работу с локальным репозиторием, изменения из которого затем пушатся в репозиторий. К сожалению RedGate SC не умеет делать push «из коробки».
Для обхода данного ограничения было написано 2 bat-скрипта для RedGate, которые используются как pull и commit hooks. Когда разработчик обновляет список изменений в окне плагина — выполняется Pull, при котором репозиторий на станции разработчика становится идентичным текущему состоянию репозитория. Так, в списке на commit, остаются только изменения, которые присутствуют в БД, но отсутствуют в системе контроля версий.
После выбора изменений (к примеру хранимая процедура и таблица), которые следует закоммитить и нажатия кнопки Commit — изменения попадают в локальный репозиторий, а после этого, автоматически происходит push в Git.
Прикладываю файл конфигурации RedGate Source Control, а также исходники pull.bat и commit.bat, которые в нем используются:
CommandLineHooks.xml
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<!---->
<HooksConfig version="1" type="HooksConfig">
<!-- The name of the config file that will be displayed in the SQL Source Control user interface -->
<Name>Git_CompanyName</Name>
<Commands type="Commands" version="2">
<element>
<key type="string">GetLatest</key>
<!-- Updates the local working folder with latest version in source control. -->
<!-- Valid macros: ($ScriptsFolder) ($Message) -->
<value version="1" type="GenericHookCommand">
<CommandLine>%UserProfile%\Documents\SQLSourceControl\projectname\Pull.bat</CommandLine>
<Verify>exitCode == 0</Verify>
</value>
</element>
<element>
<key type="string">Add</key>
<!-- Adds new files to the local working copy. Changes can then be committed to source control using the Commit command. -->
<!-- Valid macros: ($ScriptsFolder) ($Message) ($Files) ($Folders) -->
<value version="1" type="GenericHookCommand">
<CommandLine>"C:\Program Files (x86)\Git\bin\git" add ($Files)</CommandLine>
<Verify>exitCode == 0</Verify>
</value>
</element>
<element>
<key type="string">Edit</key>
<!-- Makes the local working copy of the file(s) available for editing. Changes can then be committed to source control using the Commit command. -->
<!-- Valid macros: ($ScriptsFolder) ($Message) ($Files) ($Folders) -->
<value version="1" type="GenericHookCommand">
<CommandLine></CommandLine>
<Verify>exitCode == 0</Verify>
</value>
</element>
<element>
<key type="string">Delete</key>
<!-- Deletes the file(s) from the local working copy. Changes can then be committed to source control using the Commit command. -->
<!-- Valid macros: ($ScriptsFolder) ($Message) ($Files) ($Folders) -->
<value version="1" type="GenericHookCommand">
<CommandLine>"C:\Program Files (x86)\Git\bin\git" rm ($Files)</CommandLine>
<Verify>exitCode == 0</Verify>
</value>
</element>
<element>
<key type="string">Commit</key>
<!-- Commits all changes in the local working folder to source control. -->
<!-- Valid macros: ($ScriptsFolder) ($Message) -->
<value version="1" type="GenericHookCommand">
<CommandLine>%UserProfile%\Documents\SQLSourceControl\projectname\Commit.bat "($Message)"</CommandLine>
<Verify>exitCode == 0</Verify>
</value>
</element>
<element>
<key type="string">Revert</key>
<!-- Undoes changes if an error occurs during a commit -->
<!-- Valid macros: ($ScriptsFolder) -->
<value version="1" type="GenericHookCommand">
<CommandLine>"C:\Program Files (x86)\Git\bin\git" checkout "($ScriptsFolder)\"</CommandLine>
<Verify>exitCode == 0</Verify>
</value>
</element>
</Commands>
</HooksConfig>
Pull.bat
@echo off
set HOME=%USERPROFILE%
cd %UserProfile%\Documents\SQLSourceControl\projectname
"C:\Program Files (x86)\Git\bin\git" remote add origin ssh://git@stash.companyname.com:7999/projectname/projectname-sql.git
"C:\Program Files (x86)\Git\bin\git" pull --force origin master
Commit.bat
@echo off
set HOME=%USERPROFILE%
set comment=%1
cd %UserProfile%\Documents\SQLSourceControl\projectname
"C:\Program Files (x86)\Git\bin\git" remote add origin ssh://git@stash.companyname.com:7999/projectname/projectname-sql.git
"C:\Program Files (x86)\Git\bin\git" pull origin master
"C:\Program Files (x86)\Git\bin\git" commit -m %comment% -o %UserProfile%\Documents\SQLSourceControl\projectname-sql
"C:\Program Files (x86)\Git\bin\git" push origin master
Как можно заметить, работа со Stash/Git ведется через SSH с авторизацией по ключам. Первичная настройка Red-Gate задокументирована и по факту имеет 2 шага: установить плагин и запустить скрипт первоначальной настройки (который сам создаст нужные папки в профиле пользователя и сделает первый clone репозитория).
Процесс разработки и тестирования
Думаю, тут стоит прерваться на то, как выстроен сам workflow для разработчиков. Обращу внимание, что все шаги процесса форсированы с помощью JIRA, где также производятся проверки различных условий для определения возможности или невозможности выполнения перехода (transition) задачи из одного статуса в другой.
Как обычно процесс начинается с создания Issue в JIRA. Это может быть баг-репорт, запрос новой фичи, модификация существующей фичи или идея. В зависимости от выбранного компонента, типа issue и due date данному билету выставляется приоритет. После этого он попадает в очередь планирования. Issue с высоким приоритетом в очереди планирования рассматриваются и планируются в течение 24-48 часов, все остальное — раз в неделю на планерках команды.
Под «планированием» я подразумеваю определение сложности и этапов задачи, объемов требуемой документации, общение с человеком от которого поступила заявка (для выяснения подробностей) и принятия решения о том в какой Agile Sprint следует поместить решение данной задачи.
Такой процесс требует обязательного выставления предварительной оценки сроков, необходимых для выполнения задачи. Спринты мы стараемся выстраивать таким образом, чтобы каждый разработчик был занят 33 часа в неделю. Оставшиеся 7 часов оставляем в качестве буфера для реакции на срочные задачи, встречи и ситуации, когда другой разработчик вышел на больничный/ушел в отпуск.
В случае «переполнения» текущего/будущего спринта требуется принимать решение о том, какие задачи мы можем отодвинуть на более поздний срок. Аналогично, в случае если разработчик остался без работы в течение спринта — можно переместить и взяться за выполнение задачи, запланированной на следующее окно.
Задачи могут находится в следующих статусах:
- Планирование (Triage);
- Отказ (Rejected);
- Готов к разработке (Development started);
- Разработка в процессе (In development);
- Ожидание (Impediment — препятствие для продолжения разработки);
- Готов к тестированию (Ready for QA);
- Готов к релизу (Ready for production);
- Закрыт (Resolved);
Перемещения задач между статусами возможны только согласно следующей схеме:
Ситуации, при которых должно происходить перемещение описаны на схеме (хоть и на английском, но думаю понимание не составит проблемы для читателей), так что повторяться я не буду. Лучше расскажу о том, чего на схеме не видно:
- Большие задачи разделяются на под-задачи. Parent issue не может быть ни в одном из статусов кроме «Ready for development», «Development started» и «Impediment»;
- Как только разработчик осуществляет commit — создается code-review для данного коммита (о том как это происходит — ниже);
- Сделать коммит можно только при наличии ссылки на JIRA тикет в комменте, чтобы коммит, и в последствии ревью, были автоматически привязаны к issue;
- Code-review мы решили считать частью процесса разработки, так что пока идет ревью — тикет находится в «Ready for development/Development started. Переместить тикет в „Ready for QA“ и тем более закрыть его пока открыт ревью — невозможно;
- В случае если решение задачи невозможно из-за того, что есть „блокирующая“ задача — используется соответствующий link в JIRA. Пока блокирующий тикет не закрыт — issue будет находится в статусе „Impediment“ и закрыть его будет невозможно;
- Да-да, вы все верно поняли, задачи не открываются повторно. В случае обнаружение бага/проблемы после релиза создается новый issue, который линкуется к предыдущему;
- После того, как issue был закрыт — изменения для него будут автоматически применены на боевую базу при закрытии спринта (о том как это происходит — также ниже);
Краткое отступление: описанные процессы совместимы с IEEE стандартами по разработке.
Code-review
В качестве решения для ревью изменений кода мы используем Atlassian (да неужели?!) Fisheye/Crucible. Полная интеграция с JIRA и Stash позволяет быстро переходить со страницы issue к просмотру связанных коммитов и code-ревью. Никаких хитростей с интеграцией JIRA+Stash+Crucible/Fisheye нет, так что и рассказывать мне по этой теме больше нечего.
Непрерывная интеграция (continuous integration)
На мой взгляд это самая интересная часть нашего процесса (относительно БД). Как упоминалось ранее, мы работаем с общей (shared) базой данных, всего используется три сепарированных среды: Development, Test/QA и Production.
Development база данных всегда имеет самую последнюю версию, т.к. разработчики постоянно меняют код и схему именно в ней. Front-end приложение, которое обращается к данной базе также обновляется постоянно (как только у веб-разработчиков локально собрался (без ошибок) билд с новой фичей/исправлением — он сразу публикуется).
Все изменения в DEV публикуются в QA. Однако, говоря „все“ — я лукавлю. Публикуются только те изменения, которые закоммичены в source control (мы же не хотим публиковать что-то, что еще находится „в процессе разработки“). Так что вместо банальной синхронизации схемы мы используем возможности RedGate SQL CI и нашего билд-сервера — Atlassian Bamboo.
В Bamboo создан MSBuild план, который вызывает SQL CI. Как только происходит коммит SQL CI генерирует ALTER и CREATE команды, и накатывает их на QA базу данных.
Хоть мне и известно, что „настоящей“ непрерывной интеграцией следует считать такую же публикацию изменений на production, однако у меня не хватает смелости так делать. Вместо этого мы используем RedGate SQL Compare для синхронизации схемы с QA при закрытии спринта. Соответственно, если смотреть с точки зрения процесса — QA база для нас является production. Однако это не меняет подхода, который следует применять при разработке БД используя этот процесс — ни одно изменение не должно быть фатальным (breaking). В мире Microsoft SQL Server в качестве БД для веб-приложений это значит что при публикации версии процедур должны корректно завершаться и не вызывать deadlock-ов. Безусловно это требует соответствующей архитектуры веб-приложения — все запросы выполняются через хранимые процедуры, классы должны поддерживать отсутствие ожидаемых параметров у процедуры или их большее количество. Процедуры же должны поддерживать NULL-параметры и соответствующим образом реагировать на такие ситуации, не создавая угроз безопасности. В нашем случае это представляется возможным.
Заключение
Я понимаю, что описанный мною сценарий может быть крайне специфичен, а его применение невозможно в других условиях. Однако я писал это с целью поделиться опытом с сообществом, и надеждой что может быть я познакомлю кого-то с новыми инструментами или дам шанс взглянуть на чужой процесс разработки — может Вы увидите где можно улучшить собственные процедуры, а может увидите моменты, в которых Ваш подход грамотнее и логичнее. Хотел рассказать гораздо больше — о том, как устроено и интегрировано в этот процесс автоматизированное тестирование (automated unit testing и integration testing), как мы используем Microsoft Data Quality Services для процесса QA, как организована документация, но текста получилось и так слишком много. Может сделаю это в отдельной статье. Ну а пока, буду рад вопросам и конструктивной критике.
