Знакомство с микросервисной архитектурой серьезно изменило мой подход к разработке. В этой публикации я расскажу о различных аспектах использования микросервисов. Для иллюстрации некоторых из них буду использовать архитектуру проекта по аренде недвижимости.
Подопытное приложение
Клиент просматривает список доступных квартир и бронирует их, также он может размещать на сервисе свои квартиры.
При классическом подходе для построения чаще всего выбирается фреймворк и внутри него реализуются компоненты. В случае с микросервисами для каждого компонента строится отдельное приложение и подбирается свой набор инструментов. Компоненты чаще всего взаимодействуют через REST API.
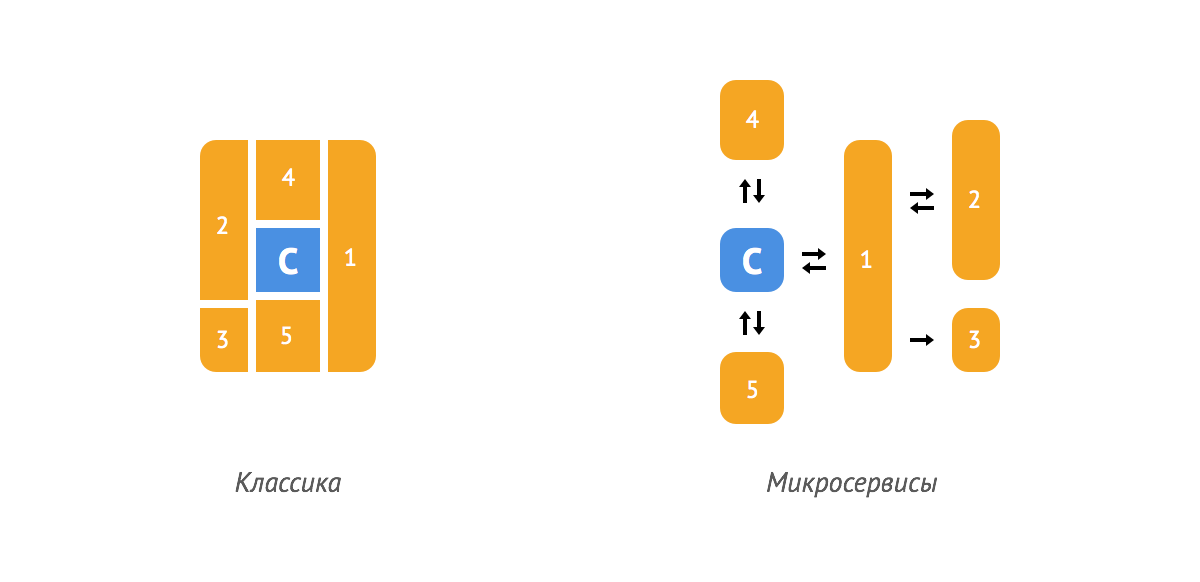
Компоненты: C — данные по квартирам (ядро), 1 — бронирование, 2 — оплата, 3 — логирование броней, 4 — размещение квартир, 5 — администрирование контента.
Обратите внимание, что перед созданием микросервисного приложения придется как следует продумать бизнес-логику и разбить приложение на самодостаточные компоненты. А теперь поговорим о том, почему микросервисы это круто.
Просто используйте молоток, чтобы забивать гвозди. Это применимо и в разработке ИТ-продуктов.

Для примера рассмотрим третий компонент нашего приложения — логирование. В самом базовом понимании нам нужно просто записывать текст в разные файлы.
Получается, что нам не нужен сложный фреймворк и база данных. Для реализации достаточно будет простенького модуля записи в файлы, рест-апи, и совсем немного человеко/часов на разработку и поддержку.
На рынке ежедневно появляются десятки SaaS-решений, решающих самые различные задачи. И если мы понимаем, что легче воспользоваться таким решением, чем заниматься обслуживанием своего, то мы можем просто убрать один свой микросервис и заменить его SaaS-сервисом. При этом изменить нужно будет только взаимодействие с API.

Здесь наиболее подходящим примером будет сервис оплаты (второй компонент). Однако тут уместнее говорить о переход от SaaS-решения к своему. Например, чтобы снизить процент комиссии.
В рамках одного проекта вам придется заниматься логикой взаимодействия для разных типов пользователей. Обслуживающий персонал вашего проекта (например: администраторы и модераторы) не исключение (модули 4 и 5).

Однако стоит учитывать, что потребности у этих групп разные и для каждой из них разрабатывается свой интерфейс. Будет отлично, если логика отдельного интерфейса будет соответствовать логике приложения. Это позволит работать над задачей на новом качественном уровне.
Когда 20+ человек работают над кодом одного проекта, даже с очень хорошей архитектурой, это вызывает проблемы. Багов становится гораздо больше, тестирование превращается в пытку и т.д. В итоге продукту очень трудно развиваться и практически невозможно сделать качественный скачек через обновления.

Выделение каждого значимого компонента в отдельный микросервис позволяет не только улучшить качество разработки, но и сократить количество разработчиков в рамках существующих задач, а освободившиеся человека/часы потратить на новые разработки.
В итоге каждый из 6 компонентов будет обслуживаться 1-3 разработчиками. И в своей работе они не будут пересекаться с коллегами из параллельных микросервисов. Также стоит обратить внимание, что с микросервисами удобно будет работать в рамках версионности, которая легко реализуется в классическом API.
Возможно это кажется вам сейчас избыточным и сложным, как будет казаться в случае любого вмешательство в вашу привычную экосистему разработки. Однако, микросервисную архитектуру обязательно стоит попробовать, хотя бы один раз, бесплатно.
А еще базовые функции каждого нового продукта можно будет собрать из уже готовых микросервисов. И это просто великолепно!

Для углубленного изучения концепции рекомендую прочитать вот эту публикацию: habrahabr.ru/post/249183.
Проектирование микросервиса
Подопытное приложение
Клиент просматривает список доступных квартир и бронирует их, также он может размещать на сервисе свои квартиры.
При классическом подходе для построения чаще всего выбирается фреймворк и внутри него реализуются компоненты. В случае с микросервисами для каждого компонента строится отдельное приложение и подбирается свой набор инструментов. Компоненты чаще всего взаимодействуют через REST API.
Компоненты: C — данные по квартирам (ядро), 1 — бронирование, 2 — оплата, 3 — логирование броней, 4 — размещение квартир, 5 — администрирование контента.
Обратите внимание, что перед созданием микросервисного приложения придется как следует продумать бизнес-логику и разбить приложение на самодостаточные компоненты. А теперь поговорим о том, почему микросервисы это круто.
Каждой задаче свой инструмент
Просто используйте молоток, чтобы забивать гвозди. Это применимо и в разработке ИТ-продуктов.
Для примера рассмотрим третий компонент нашего приложения — логирование. В самом базовом понимании нам нужно просто записывать текст в разные файлы.
Получается, что нам не нужен сложный фреймворк и база данных. Для реализации достаточно будет простенького модуля записи в файлы, рест-апи, и совсем немного человеко/часов на разработку и поддержку.
Незаменимых нет
На рынке ежедневно появляются десятки SaaS-решений, решающих самые различные задачи. И если мы понимаем, что легче воспользоваться таким решением, чем заниматься обслуживанием своего, то мы можем просто убрать один свой микросервис и заменить его SaaS-сервисом. При этом изменить нужно будет только взаимодействие с API.
Здесь наиболее подходящим примером будет сервис оплаты (второй компонент). Однако тут уместнее говорить о переход от SaaS-решения к своему. Например, чтобы снизить процент комиссии.
Каждому свое
В рамках одного проекта вам придется заниматься логикой взаимодействия для разных типов пользователей. Обслуживающий персонал вашего проекта (например: администраторы и модераторы) не исключение (модули 4 и 5).
Однако стоит учитывать, что потребности у этих групп разные и для каждой из них разрабатывается свой интерфейс. Будет отлично, если логика отдельного интерфейса будет соответствовать логике приложения. Это позволит работать над задачей на новом качественном уровне.
Вы маленькие, даже когда вы большие
Когда 20+ человек работают над кодом одного проекта, даже с очень хорошей архитектурой, это вызывает проблемы. Багов становится гораздо больше, тестирование превращается в пытку и т.д. В итоге продукту очень трудно развиваться и практически невозможно сделать качественный скачек через обновления.
Выделение каждого значимого компонента в отдельный микросервис позволяет не только улучшить качество разработки, но и сократить количество разработчиков в рамках существующих задач, а освободившиеся человека/часы потратить на новые разработки.
В итоге каждый из 6 компонентов будет обслуживаться 1-3 разработчиками. И в своей работе они не будут пересекаться с коллегами из параллельных микросервисов. Также стоит обратить внимание, что с микросервисами удобно будет работать в рамках версионности, которая легко реализуется в классическом API.
Итоги
Возможно это кажется вам сейчас избыточным и сложным, как будет казаться в случае любого вмешательство в вашу привычную экосистему разработки. Однако, микросервисную архитектуру обязательно стоит попробовать, хотя бы один раз, бесплатно.
А еще базовые функции каждого нового продукта можно будет собрать из уже готовых микросервисов. И это просто великолепно!
Для углубленного изучения концепции рекомендую прочитать вот эту публикацию: habrahabr.ru/post/249183.
Подолжение
Проектирование микросервиса
