Предлагаю читателям «Хабрахабра» перевод статьи главного архитектора компании Malwarebytes о том, как они достигли обработки 1 миллиона запросов в минуту всего на 4 серверах.
У нас в Malwarebytes мы переживаем бешеный рост и с тех пор, как я присоединился к компании около года назад в Кремниевой Долине, одной из моих основных обязанностей было проектирование и разработка архитектур нескольких систем для развития быстрорастущей компании и всей необходимой инфраструктуры для поддержки продукта, который используют миллионы людей каждый день. Я работал в индустрии антивирусов более 12 лет в нескольких разных компаниях, и знаю, насколько сложными получаются в итоге эти системы, из-за колоссальных объемов данных, с которыми приходится иметь дело ежедневно.
Что интересно, так это то, что последние 9 лет или около того, вся разработка веб-бекендов, с которой я сталкивался, осуществлялась на Ruby on Rails. Не поймите меня неправильно, я люблю Ruby on Rails и я верю, что это великолепная среда, но через некоторое время вы привыкаете мыслить о разработке систем в стиле Ruby, и вы забываете, насколько эффективной и простой ваша архитектура могла бы быть, если бы вы задействовали мультипоточность, параллелизм, быстрое исполнение и эффективное использование памяти. Много лет я писал на C/C++, Delphi и C#, и я начал осозновать насколько менее сложными вещи могут быть, если вы выбрали правильный инструмент для дела.
Как Главный Архитектор, я не любитель холиваров о языках и фреймворках, которые так популярны в сети. Я верю, что эффективность, продуктивность и поддерживаемость кода зависят в основном от того, насколько простым вы сможете построить ваше решение.
Работая над одной из частей нашей системы сбора анонимной телеметрии и аналитики, перед нами стояла задача обрабатывать огромное количество POST-запросов от миллионов клиентов. Веб-обработчик должен был получать JSON-документ, который может содержать коллекцию данных (payload), которые, в свою очередь нужно сохранить на Amazon S3, чтобы наши map-reduce системы позже обработали эти данные.
Традиционно мы бы посмотрели в сторону worker-уровневной (worker-tier) архитектуры, и использовали такие вещи, как:
И установили бы 2 разных кластера, один для веб фронтенда, и другой для воркеров (workers), чтобы можно было масштабировать фоновые задачи.
Но с самого начала наша команда знала, что мы должны написать это на Go, посколько на этапе обсуждения мы уже понимали, что эта система должна будет справляться с огромным траффиком. Я использовал Go около 2 лет, и мы разработали несколько систем на нём, но ни одна из них не работала пока с такими нагрузками.
Мы начали с создания нескольких структур, чтобы описать данные запроса, которые будут приниматься в POST-запросах, и метод для загрузки их на наш S3-бакет.
Изначально мы взяли простейшее наивное решение POST-обработчика, просто стараясь распараллелить обработку с помощью простой go-рутины:
Для средних нагрузок, такой подход будет работать для большинства людей, но он быстро показал себя неэффективным в большем масштабе. Мы ожидали, что запросов будет много, но, когда мы выкатили первую версию в продакшн, то поняли что ошиблись на порядки. Мы совершенно недооценили количество траффика.
Подход выше плох по нескольким причинам. В нём нет способа контролировать, сколько горутин мы запускаем. И поскольку мы получали 1 миллион POST-запросов в минуту, этот код, конечно, быстро падал и крашился.
Мы должны были найти другой путь. С самого начала мы обсуждали, что нам нужно уменьшить время обработки запроса до минимума и тяжелые задачи делать в фоне. Разумеется, это то, как вы должны это делать в мире Ruby on Rails, иначе у вас заблокируются все доступные веб-обработчики, и неважно, используете ли вы puma, unicorn или passenger (Только давайте не обсуждать тут JRuby, пожалуйста). Значит мы должны были бы использовать общепринятые решения для таких задач, такие как Resque, Sidekiq, SQS, и т.д… Этот список большой, так как существует масса способов решить нашу задачу.
И нашей второй попыткой было создание буферизированного канала, в котором мы могли поместить очередь задач, и загружать их на S3, а так как мы можем контролировать максимальное количество объектов в нашей очереди, и у нас есть куча RAM, чтобы держать все в памяти, мы решили, что будет достаточно просто буферизировать задачи в канале очереди.
А затем, собственно, чтобы вычитывать задачи из очереди и обрабатывать их, мы использовали что-то подобное этому коду:
Честно говоря, я понятия не имею, о чём мы тогда думали. Это, видимо, было поздней ночью, с кучей выпитых Red-Bull-ов. Этот подход не дал нам никакого выигрыша, мы просто обменяли плохую конкурентность на буферизированный канал и это просто откладывало проблему. Наш синхронный обработчик очереди загружал лишь одну пачку данных на S3 за единицу времени, и поскольку частота входящих запросов была намного больше возможности обработчика загружать их на S3, наш буферизированный канал очень быстро достигал своего лимита и блокировал возможность добавлять в очередь новые задачи.
Мы молча проигнорировали проблему и запустили обратный отсчет краха нашей системы. Время отклика (latency) увеличивалось по наростающей уже через несколько минут после того, как мы задеплоили эту глючную версию.
Мы решили использовать популярный паттерн работы с каналами в Go, чтобы создать двухуровневую систему каналов, одна — для работы с очередью каналов, другую для контроля за количеством обработчиков задач, работающих с очередью одновременно.
Идея была в том, чтобы распараллелить загрузку на S3, контролируя этот процесс, чтобы не перегрузить машину и не упираться в ошибки соединения с S3. Поэтому мы выбрали Job/Worker паттерн. Для тех, кто знаком с Java, C#, etc, считайте это Go-способом реализации Worker Thread-Pool, используя каналы.
Мы изменили наш хендлер запросов так, чтобы он создавал объект типа Job с данными, и отправлял его в канал JobQueue, чтобы далее его подхватывали обработчики задач.
Во время инициализации сервера мы создаем Dispatcher и вызываем Run() чтобы создать пул воркеров (pool of workers) и начать слушать входящие задачи в JobQueue.
Ниже приведён наш код реализации диспатчера:
Заметьте, что мы указываем количество обработчиков, которые будут запущены и добавлены в пул. Поскольку мы использовали Amazon Elasticbeanstalk для этого проекта и докеризированное Go-окружение, и всегда старались следовать двенадцатифакторной методологии, чтобы конфигурировать наши системы в продакшене, то мы читаем эти значения из переменных окружения. Таким образом мы можем контролировать количество обработчиков и максимальный размер очереди, чтобы быстро подтюнить эти параметры без редеплоя всего кластера.
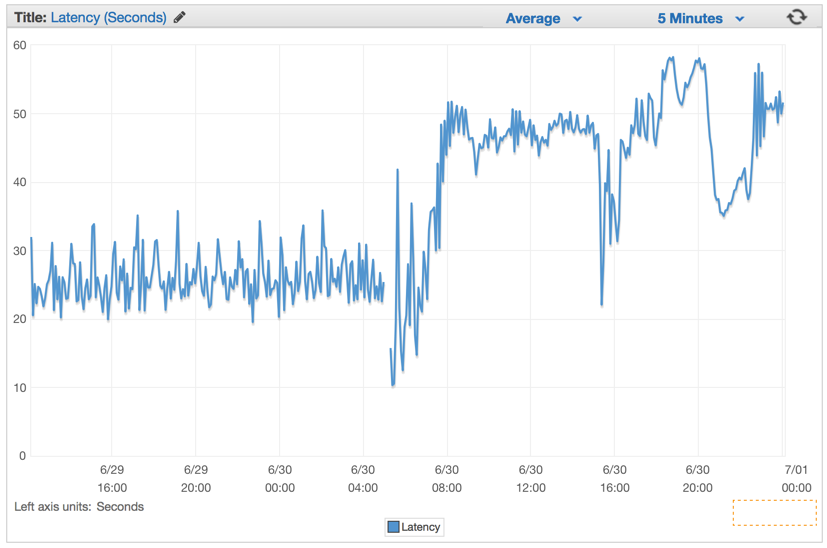
Сразу же после того, как мы задеплоили последнее решение, мы увидели, что время отклика упало до незначительных цифр и наша возможность обрабатывать запросы выросла радикально.

Через несколько минут после разогрева Elastic Load Balancer-ов, мы увидели что наше ElasticBeanstalk приложение обрабатывает порядка 1 миллиона запросов в минуту. У нас есть обычно несколько часов утром, когда пики трафика достигают более 1 миллиона запросов в минуту.
Как только мы задеплоили новый код, количество необходимых серверов значительно упало, со 100 до примерно 20 серверов.
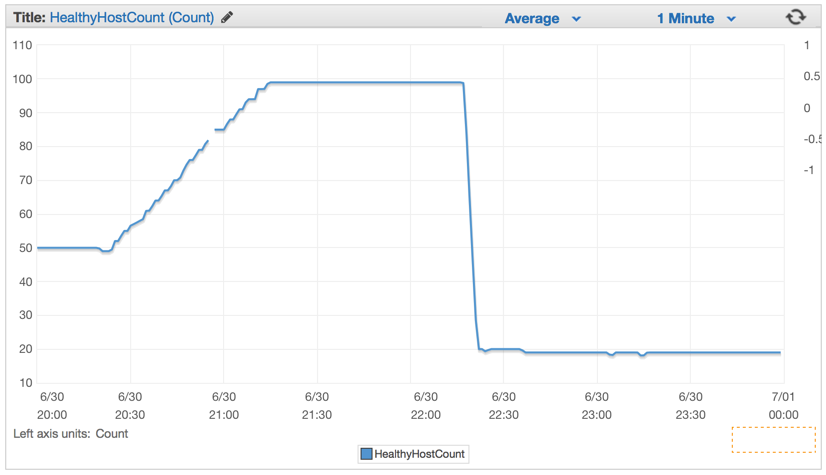
После того, как мы настроили наш кластер и настройки авто-масштабирования, мы смогли уменьшить их количество еще больше — до 4-х EC c4.large инстансов и Elastic Auto-Scaling запускал новый инстанс, если использование CPU превышало 90% в течении 5 минут.
Я глубоко уверен, что простота всегда побеждает. Мы могли создать сложную систему с кучей очередей, фоновыми процессами, сложным деплоем, но вместо всего этого мы решили воспользоваться силой авто-масштабирования ElasticBeanstalk и эффективностью и простотой подхода к конкурентности, которую Golang даёт из коробки.
Не каждый день вы видите кластер из всего 4х машин, которые даже слабее, чем мой нынешний Macbook Pro, обрабатывающие POST-запросы, пишущие на Amazon S3 бакет 1 миллион раз каждую минуту.
Всегда есть правильный инструмент для задачи. И для тех случаев, когда ваша Ruby on Rails система нуждается в более мощном веб-обработчике, выйдите немного из экосистемы ruby для более простых, при этом более мощных решений.
У нас в Malwarebytes мы переживаем бешеный рост и с тех пор, как я присоединился к компании около года назад в Кремниевой Долине, одной из моих основных обязанностей было проектирование и разработка архитектур нескольких систем для развития быстрорастущей компании и всей необходимой инфраструктуры для поддержки продукта, который используют миллионы людей каждый день. Я работал в индустрии антивирусов более 12 лет в нескольких разных компаниях, и знаю, насколько сложными получаются в итоге эти системы, из-за колоссальных объемов данных, с которыми приходится иметь дело ежедневно.
Что интересно, так это то, что последние 9 лет или около того, вся разработка веб-бекендов, с которой я сталкивался, осуществлялась на Ruby on Rails. Не поймите меня неправильно, я люблю Ruby on Rails и я верю, что это великолепная среда, но через некоторое время вы привыкаете мыслить о разработке систем в стиле Ruby, и вы забываете, насколько эффективной и простой ваша архитектура могла бы быть, если бы вы задействовали мультипоточность, параллелизм, быстрое исполнение и эффективное использование памяти. Много лет я писал на C/C++, Delphi и C#, и я начал осозновать насколько менее сложными вещи могут быть, если вы выбрали правильный инструмент для дела.
Как Главный Архитектор, я не любитель холиваров о языках и фреймворках, которые так популярны в сети. Я верю, что эффективность, продуктивность и поддерживаемость кода зависят в основном от того, насколько простым вы сможете построить ваше решение.
Проблема
Работая над одной из частей нашей системы сбора анонимной телеметрии и аналитики, перед нами стояла задача обрабатывать огромное количество POST-запросов от миллионов клиентов. Веб-обработчик должен был получать JSON-документ, который может содержать коллекцию данных (payload), которые, в свою очередь нужно сохранить на Amazon S3, чтобы наши map-reduce системы позже обработали эти данные.
Традиционно мы бы посмотрели в сторону worker-уровневной (worker-tier) архитектуры, и использовали такие вещи, как:
- Sidekiq
- Resque
- DelayedJob
- Elasticbeanstalk Worker Tier
- RabbitMQ
- и так далее
И установили бы 2 разных кластера, один для веб фронтенда, и другой для воркеров (workers), чтобы можно было масштабировать фоновые задачи.
Но с самого начала наша команда знала, что мы должны написать это на Go, посколько на этапе обсуждения мы уже понимали, что эта система должна будет справляться с огромным траффиком. Я использовал Go около 2 лет, и мы разработали несколько систем на нём, но ни одна из них не работала пока с такими нагрузками.
Мы начали с создания нескольких структур, чтобы описать данные запроса, которые будут приниматься в POST-запросах, и метод для загрузки их на наш S3-бакет.
type PayloadCollection struct {
WindowsVersion string `json:"version"`
Token string `json:"token"`
Payloads []Payload `json:"data"`
}
type Payload struct {
// [redacted]
}
func (p *Payload) UploadToS3() error {
// the storageFolder method ensures that there are no name collision in
// case we get same timestamp in the key name
storage_path := fmt.Sprintf("%v/%v", p.storageFolder, time.Now().UnixNano())
bucket := S3Bucket
b := new(bytes.Buffer)
encodeErr := json.NewEncoder(b).Encode(payload)
if encodeErr != nil {
return encodeErr
}
// Everything we post to the S3 bucket should be marked 'private'
var acl = s3.Private
var contentType = "application/octet-stream"
return bucket.PutReader(storage_path, b, int64(b.Len()), contentType, acl, s3.Options{})
}Решение “в лоб” с помощью Go-рутин
Изначально мы взяли простейшее наивное решение POST-обработчика, просто стараясь распараллелить обработку с помощью простой go-рутины:
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
go payload.UploadToS3() // <----- DON'T DO THIS
}
w.WriteHeader(http.StatusOK)
}Для средних нагрузок, такой подход будет работать для большинства людей, но он быстро показал себя неэффективным в большем масштабе. Мы ожидали, что запросов будет много, но, когда мы выкатили первую версию в продакшн, то поняли что ошиблись на порядки. Мы совершенно недооценили количество траффика.
Подход выше плох по нескольким причинам. В нём нет способа контролировать, сколько горутин мы запускаем. И поскольку мы получали 1 миллион POST-запросов в минуту, этот код, конечно, быстро падал и крашился.
Пробуем снова
Мы должны были найти другой путь. С самого начала мы обсуждали, что нам нужно уменьшить время обработки запроса до минимума и тяжелые задачи делать в фоне. Разумеется, это то, как вы должны это делать в мире Ruby on Rails, иначе у вас заблокируются все доступные веб-обработчики, и неважно, используете ли вы puma, unicorn или passenger (Только давайте не обсуждать тут JRuby, пожалуйста). Значит мы должны были бы использовать общепринятые решения для таких задач, такие как Resque, Sidekiq, SQS, и т.д… Этот список большой, так как существует масса способов решить нашу задачу.
И нашей второй попыткой было создание буферизированного канала, в котором мы могли поместить очередь задач, и загружать их на S3, а так как мы можем контролировать максимальное количество объектов в нашей очереди, и у нас есть куча RAM, чтобы держать все в памяти, мы решили, что будет достаточно просто буферизировать задачи в канале очереди.
var Queue chan Payload
func init() {
Queue = make(chan Payload, MAX_QUEUE)
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
...
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
Queue <- payload
}
...
}А затем, собственно, чтобы вычитывать задачи из очереди и обрабатывать их, мы использовали что-то подобное этому коду:
func StartProcessor() {
for {
select {
case job := <-Queue:
job.payload.UploadToS3() // <-- STILL NOT GOOD
}
}
}Честно говоря, я понятия не имею, о чём мы тогда думали. Это, видимо, было поздней ночью, с кучей выпитых Red-Bull-ов. Этот подход не дал нам никакого выигрыша, мы просто обменяли плохую конкурентность на буферизированный канал и это просто откладывало проблему. Наш синхронный обработчик очереди загружал лишь одну пачку данных на S3 за единицу времени, и поскольку частота входящих запросов была намного больше возможности обработчика загружать их на S3, наш буферизированный канал очень быстро достигал своего лимита и блокировал возможность добавлять в очередь новые задачи.
Мы молча проигнорировали проблему и запустили обратный отсчет краха нашей системы. Время отклика (latency) увеличивалось по наростающей уже через несколько минут после того, как мы задеплоили эту глючную версию.
Лучшее решение
Мы решили использовать популярный паттерн работы с каналами в Go, чтобы создать двухуровневую систему каналов, одна — для работы с очередью каналов, другую для контроля за количеством обработчиков задач, работающих с очередью одновременно.
Идея была в том, чтобы распараллелить загрузку на S3, контролируя этот процесс, чтобы не перегрузить машину и не упираться в ошибки соединения с S3. Поэтому мы выбрали Job/Worker паттерн. Для тех, кто знаком с Java, C#, etc, считайте это Go-способом реализации Worker Thread-Pool, используя каналы.
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
// Job represents the job to be run
type Job struct {
Payload Payload
}
// A buffered channel that we can send work requests on.
var JobQueue chan Job
// Worker represents the worker that executes the job
type Worker struct {
WorkerPool chan chan Job
JobChannel chan Job
quit chan bool
}
func NewWorker(workerPool chan chan Job) Worker {
return Worker{
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool)}
}
// Start method starts the run loop for the worker, listening for a quit channel in
// case we need to stop it
func (w Worker) Start() {
go func() {
for {
// register the current worker into the worker queue.
w.WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
// we have received a work request.
if err := job.Payload.UploadToS3(); err != nil {
log.Errorf("Error uploading to S3: %s", err.Error())
}
case <-w.quit:
// we have received a signal to stop
return
}
}
}()
}
// Stop signals the worker to stop listening for work requests.
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}Мы изменили наш хендлер запросов так, чтобы он создавал объект типа Job с данными, и отправлял его в канал JobQueue, чтобы далее его подхватывали обработчики задач.
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
// let's create a job with the payload
work := Job{Payload: payload}
// Push the work onto the queue.
JobQueue <- work
}
w.WriteHeader(http.StatusOK)
}Во время инициализации сервера мы создаем Dispatcher и вызываем Run() чтобы создать пул воркеров (pool of workers) и начать слушать входящие задачи в JobQueue.
dispatcher := NewDispatcher(MaxWorker)
dispatcher.Run()Ниже приведён наш код реализации диспатчера:
type Dispatcher struct {
// A pool of workers channels that are registered with the dispatcher
WorkerPool chan chan Job
}
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool}
}
func (d *Dispatcher) Run() {
// starting n number of workers
for i := 0; i < d.maxWorkers; i++ {
worker := NewWorker(d.pool)
worker.Start()
}
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
// a job request has been received
go func(job Job) {
// try to obtain a worker job channel that is available.
// this will block until a worker is idle
jobChannel := <-d.WorkerPool
// dispatch the job to the worker job channel
jobChannel <- job
}(job)
}
}
}Заметьте, что мы указываем количество обработчиков, которые будут запущены и добавлены в пул. Поскольку мы использовали Amazon Elasticbeanstalk для этого проекта и докеризированное Go-окружение, и всегда старались следовать двенадцатифакторной методологии, чтобы конфигурировать наши системы в продакшене, то мы читаем эти значения из переменных окружения. Таким образом мы можем контролировать количество обработчиков и максимальный размер очереди, чтобы быстро подтюнить эти параметры без редеплоя всего кластера.
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)Мгновенный результат
Сразу же после того, как мы задеплоили последнее решение, мы увидели, что время отклика упало до незначительных цифр и наша возможность обрабатывать запросы выросла радикально.
Через несколько минут после разогрева Elastic Load Balancer-ов, мы увидели что наше ElasticBeanstalk приложение обрабатывает порядка 1 миллиона запросов в минуту. У нас есть обычно несколько часов утром, когда пики трафика достигают более 1 миллиона запросов в минуту.
Как только мы задеплоили новый код, количество необходимых серверов значительно упало, со 100 до примерно 20 серверов.
После того, как мы настроили наш кластер и настройки авто-масштабирования, мы смогли уменьшить их количество еще больше — до 4-х EC c4.large инстансов и Elastic Auto-Scaling запускал новый инстанс, если использование CPU превышало 90% в течении 5 минут.
Выводы
Я глубоко уверен, что простота всегда побеждает. Мы могли создать сложную систему с кучей очередей, фоновыми процессами, сложным деплоем, но вместо всего этого мы решили воспользоваться силой авто-масштабирования ElasticBeanstalk и эффективностью и простотой подхода к конкурентности, которую Golang даёт из коробки.
Не каждый день вы видите кластер из всего 4х машин, которые даже слабее, чем мой нынешний Macbook Pro, обрабатывающие POST-запросы, пишущие на Amazon S3 бакет 1 миллион раз каждую минуту.
Всегда есть правильный инструмент для задачи. И для тех случаев, когда ваша Ruby on Rails система нуждается в более мощном веб-обработчике, выйдите немного из экосистемы ruby для более простых, при этом более мощных решений.
