
При работе программных модулей, хранящих в оперативной памяти большое количество данных, способ их хранения оказывает сильное влияние на потребление памяти и быстродействие. Один из способов ускорения системы и экономии ресурсов может заключаться в использовании более примитивных структур данных – структур вместо классов и примитивных типов вместо структур. Конечно, такой подход ломает ООП и возвращает к использованию «старых» методов программирования. Однако, в некоторых случаях такая примитизация может решить множество проблем. Простой тест показал возможность сокращения потребляемой памяти более чем в три раза.
Затрагиваемые вопросы:
- Влияние программной архитектуры на потребление памяти и производительность;
- Различия при работе в 32 и 64 битных режимах;
- Различия между указателями и индексами массива;
- Влияние выравнивания данных внутри классов/структур;
- Влияние кеша процессора на производительность;
- Оценка стоимости поддержки ООП в языках высокого уровня;
- Признание факта необходимости учитывать низкоуровневые особенности платформы даже при разработке на языках высокого уровня.
Практическая задача
Впервые данную методику я применил при разработке поиска оптимального пути для портала www.GoMap.Az. Новый алгоритм использовал больше оперативной памяти и при установке на тестовый сервер приложение начинало серьезно заедать. Обновление железа в данном случае требовало нескольких дней, а ее решение оптимизацией структур данных позволило быстро решить проблему. Чтобы поделиться полученным опытом я решил в простой форме описать что было сделано и какие преимущества были получены.
Организация хранения большого количества структур данных и доступа к ним является неотъемлемой задачей для информационных систем работающих с картографическими данными. Подобные проблемы все чаще возникают также при создании других типов современных информационных систем.
Рассмотрим хранение данных и доступ к ним на примере дорог – рёбер графа. В упрощенном виде дорога может быть представлена классом Road, тогда как хранилище дорог классом RoadsContainer. Кроме того, имеется класс узла сети Node. Касательно Node – нам нужно просто знать что это — класс. Примем во внимание, что наши структуры данных не содержат методов и не участвуют в наследовании и т.п., то есть используются только для хранения и манипуляции с данными.
Мы будем рассматривать реальзацию метода на языке C#, хотя изначально она была применена на С++. Строго говоря проблема и ее решение находится несколько в области системного программирования. Однако, данное исследование также показывает насколько высокими могут быть затраты на поддержку ООП в высокоуровневом программировании. C# может лучшим способом показать эти скрытые затраты, не являясь языком системного программирования.
// Основная структура данных – класс Road
public class Road
{
public float Length;
public byte Lines ;
// Где-то описан класс Node и Road ссылается
// на два объекта этого класса
public Node NodeFrom;
public Node NodeTo;
// Другие члены класса
}
// Контейнер структур данных дорог
public class RoadsContainer
{
// Другие члены класса
// Выдача дорог, находящихся в указанном прямоугольнике
public Road[] getRoads(float X1, float Y1, float X1, float Y1)
{
// Реализация
}
// Другие члены класса
}
Память и производительность
При оценке потребляемой памяти и производительности следует учесть влияние особенностей архитектуры платформы, включая:
- Выравнивание данных. Выравнивание данных производится для правильного и быстрого доступа центрального процессора к ячейкам памяти. В зависимости от разрядности системы расположение классов/структур в памяти может начинаться с адресов кратных 32 или 64 битам. Внутри самих классов/структур поля также могут выравниваться по границе 32, 16 или 8 бит (например, поле Lines класса Road может занять в памяти не 1 байт, а 4). При этом возникают неиспользуемые пространства памяти, что увеличивает ее потери.;
- Кеш процессора. Как известно задача кеша – ускорить доступ к наиболее часто используемым ячейкам памяти. Размер кеша очень мал, так как это самая дорогая память. При обработке классов/структур неиспользуемые пространства памяти, возникшие в результате выравнивания данных также попадают в кеш процессора и засоряют его, так как не несут полезной информации. Как результат – снижение эффективности кеширования.;
- Размер указателей. В 32-битных системах указатель на объект в памяти также обычно 32-битный, что ограничивает возможности работы с оперативной памятью более 4Гб. 64- разрядные системы позволяют адресовать существенно большие объемы памяти, но используют 64-битные указатели. Объекты всегда имеют указатели на них (в противном случае это будет потеряная память или объект для удаления сборщиком мусора). В нашем примере поля NodeFrom и NodeTo в классе Road будут занимать по 8 байт каждый в 64-битной системе и по 4 байта в 32-битной.
Обычно компиляторы стараются создать наиболее эффективный код, однако достичь существенной эффективности выполнения можно только программно-архитектурными решениями.
Массивы объектов

Данные могут храниться в различных контейнерах – списках, хеш таблицах, и т.п. Хранение в виде массива возможно самый простой и понятный способ, поэтому остановимся на рассмотрении этого способа. Другие контейнеры могут быть анализированы аналогично.
В C# массивы объектов в реальности хранят ссылки на объекты, в то время как каждый объект занимает свое отдельное адресное пространство в куче. В этом случае, очень удобно манипулировать наборами объектов, так как в действительности приходится работать с указателями, а не с объектами целиком. Например, в нашеи примере функция getRoads класса RoadsContainer передает набор определенных объектов класса Road – не копиями объектов, а ссылками. Такое поведение возникает ввиду того что объекты в C# — это ссылочные типы данных.
Недостатки хранения данных в виде массивов объектов – это прежде всего затраты на хранение самих указателей и выравнивание объектов в куче. В 64-разрядных системах каждый указатель забирает 8 байт памяти и каждый объект выравнивается по адресу кратному 8 байтам.
Массивы структур

Классы хранения дорог и узлов сети могут быть преобразованы в структуры (как было упомянуто в нашем примере на это нет ограничений со стороны ООП). Вместо указателей на них могут быть использованы целочисленные индексы. Код, который при этом получится может иметь вид:
public struct Road
{
public float Length;
byte Lines ;
Int32 NodeFrom;
Int32 NodeTo;
// Другие поля
}
public class RoadsContainer
{
// Другие члены класса
// Дороги будем хранить в массиве, а не в куче
Road[] Roads;
// Выдача дорог, находящихся в указанном прямоугольнике
public Int32[] getRoads(float X1, float Y1, float X1, float Y1)
{
// Реализация
}
// Выдача дороги по индексу
public Road getRoad(Int32 Index)
{
return Roads[Index];
}
// Другие члены класса
}
// По аналогии с хранилищем дорог
// устроено хранилище узлов
public class NodesContainer
{
// Другие члены класса
Node []Nodes;
// Выдача узла по индексу
public Node getNode (Int32 Index)
{
return Nodes[Index];
}
// Другие члены класса
}
Что нам это дало? Рассмотрим подробно.
Структуры данных дорог хранятся уже как программные структуры ( structs в C# ), а не как объекты. Для их хранения использован массив Roads в классе RoadsContainer. Для доступа к отдельным структурам используется функция getRoad того же класса. 32-битный целочисленный индекс принимает на себя роль указателя на структуру данных определенной дороги. Таким же образом преобразованы узлы и представлен фрагмент класса-хранилища узлов NodesContainer.
Использование 32-разрядного индекса вместо 64-разрядного указателя облегчает как используемую им память так и операции манипулирования им. Использование индексов для ссылки на узлы NodeFrom и NodeTo в структуре Road сокращает размер потребляемой ею памяти на 8 байт ( при выравнивании в 32, 16, или 8 бит ).
Выделение памяти ( посредством вызова оператора new ) для хранения дорог происходит за один раз. При этом резервируется только массив структур Road в котором все структуры создаются за раз. В случае хранения ссылок на объекты каждый объект должен создаваться отдельно. На создание отдельного объекта не только уходит время, но также расходуется некоторый объем служебной памяти на выравнивание, регистрирование объекта в куче и системе сбора мусора.
Недостаток использования структур вместо объектов — это строго говоря невозможность использования указателей на структуру ( структура – это тип «по значению», а класс тип «по ссылке» ). Данный факт приводит к ограничению возможности манипулировать наборами объектов. Ввиду этого, функция getRoads класса RoadsContainer теперь возвращает индексы соответствющих структур в массиве. При этом получить саму структуру можно функцией getRoad. Однако, данная функция приведет к копированию возвращаемой структуры целиком, что приведет к расходу памяти и времени процессора.
Массивы данных примитивных типов

Массивы структур могут быть преобразованы в отдельные массивы полей этой структуры. Иными словами, структуры могут быть декапсулированы и упразднены. К примеру после декапсуляции и упразднения структуры Road мы получим следующий код:
public class RoadsContainer
{
// Другие члены класса
// Поля структуры данных Road
float[] Lengths;
byte[] Lines;
Int32[] NodesFrom;
Int32[] NodesTo;
// Другие члены класса
// Выдача дорог, находящихся в указанном прямоугольнике
public Int32[] getRoads(float X1, float Y1, float X1, float Y1)
{
// Реализация
}
// Выдача длины дороги по индексу
public float getRoadLengt(Int32 Index)
{
return Lengths[Index];
}
// Выдача количества полос дороги по индексу
public byte getRoadLines(Int32 Index)
{
return Lines[Index];
}
// Выдача начального узла дороги по индексу
public Int32 getRoadNodeFrom(Int32 Index)
{
return NodesFrom[Index];
}
// Выдача конечного узла дороги по индексу
public Int32 getRoadNodeTo(Int32 Index)
{
return NodesTo[Index];
}
// Другие члены класса
}
Что мы получили? Рассмотрим подробно.
Вместо хранения программных структур в одном массиве, поля этой структуры хранятся по отдельности в разных массивах. Доступ к полям также производится раздельно по индексу.
Пустой расход памяти на выравнивание полей внутри структуры устраняется, так как поля структуры примитивных типов хранятся вплотную друг к другу. Память запрашивается у системы не одним большим куском для хранения всех структур сразу, а несколькими кусками для хранения массивов полей соответственно. В некотором смысле такое разбиение полезно, так как системе часто легче предоставить несколько относительно небольших непрерывных участков памяти, чем один большой непрерывный участок.
Доступ к каждому полю каждый раз требует использование индекса, в то время как для доступа к струтуре целиком требуется использование индекса только один раз. В реальности данная особенность может рассматриваться и как недостаток и как преимущество. Дело в том, что при обращении только к части полей, например только трем полям Lengths, NodesFrom и NodesTo структуры Road в случае их расположения в отдельных массивах можно получить более оптимальное использование кеша процессора. Использование всех преимуществ кеша зависит от алгоритма доступа к данным, но в любом случае выигрыш может быть заметным.
Сборка мусора и управление памятью

Рассматриваемая проблема относится к технологиям управления памятью. Ведь именно от расположения объектов в памяти в первую очередь зависит скорость доступа к ним. В настоящее время имеется огромное количество способов организации управления памятью, включая системы автоматической сборки мусора. Эти автоматические системы не только следят за чисткой памяти, но и проводят дефрагментацию ( подобно файловой системе ).
Системы управления памяти в основном работают с указателями на объекты, расположенные в куче. В случае использования массивов структур или полей системы управления памяти не смогут работать с элементами этих массивов и вся работа по их созданию и уничтожению ляжет на плечи программиста. Таким образом, использование массивов структур или полей в определенном смысле деактивирует сборщика мусора для них. Это ограничение в зависимости от задачи может рассматриваться как преимущество (если требуется экономия ресурсов) или как недостаток (если требуется упрощение кола и труда программиста).
Замеры

Как видно наиболее расточительным для хранения является массив объектов. При этом на 64-битной системе издержки на хранение резко возрастают. Хранение в виде массивов структур или полей в целом одинаково затратно для 32 и 64-битного режима. Хранение в виде полей имеет некоторый выигрыш в размере занимаемой памяти, однако этот выигрыш не критический. Этот выигрыш включает издержки выравнивания данных внутри структур.
Память
Занимаемая память, 32 битный режим
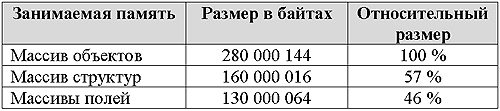
Занимаемая память, 64 битный режим

Как видно наиболее расточительным для хранения является массив объектов. При этом на 64-битной системе издержки на хранение резко возрастают. Хранение в виде массивов структур или полей в целом одинаково затратно для 32 и 64-битного режима. Хранение в виде полей имеет некоторый выигрыш в размере занимаемой памяти, однако этот выигрыш не критический. Этот выигрыш включает издержки выравнивания данных внутри структур.
Время доступа
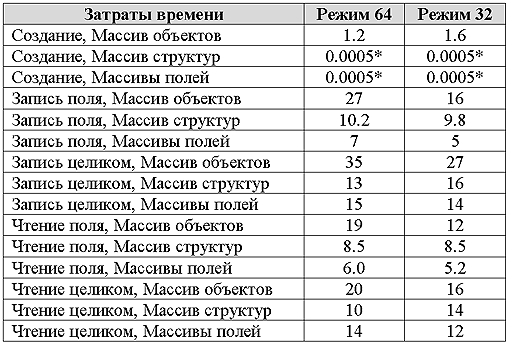
Примечания:
* — число слишком мало в сравнении с точностью теста.
Время доступа к структурам данных при хранении в массиве объектов показывает самые высокие затраты времени. Также наблюдается более быстрый доступ к полям в случае их расположения в отдельных массивах. Это ускорение является результатом более эффективного использования кеша процессора. Следует упомянуть что в тесте доступ осуществляется последовательным перебором элементов массива и в этом случае использование кеша близко к оптимальному.
Итоги
Этот небольшой обзор позволяет создать представление о проблеме и сделать первые выводы:
- Отказ от использования ООП в работе с большими объемами данных может привести к 3-х кратной экономии оперативной памяти на 64-битных системах и 2-х кратной экономии на 32-битных системах. Данная проблема возникает из-за особенностей аппаратной архитектуры, поэтому в той или иной степени она актуальна для всех языков программирования.
- Время доступа в С# к структурам данных посредством индекса массива существенно меньше времени доступа посредством указателя.
- Повышение уровня технологии программирования требует затрат ресурсов. Низкий уровень ( системный ) и работа с примитивными данными ( получаемыми после декапсуляции классов/структур ) использует меньше всего ресурсов, но требуют больше строк исходного кода и времени программиста.
- Переход к работе с примитивными типами является этапом оптимизации кода. Поэтому такая архитектура может быть использована не как начальный дизайн, а как меры в случае необходимости сокращать потребление ресурсов.
- В C++ многие описанные проблемы могут быть решены прозрачно, в то время как в C# многое скрыто в ниже-лежащей реализации. Помимо того при изучении C# влияние платформы рассматривается далеко не на первых порах.
- При разработке в C# там где это возможно, нужно использовать структуры, а не классы.
Ссылки:
Исходники тестов на GitHub
Пример успешного коммерческого использования методики — портал GoMap.Az
Разница между структурами и объектами (MSDN)
Хорошая статья о структурах «Mastering C# structs»
Статья на похожую проблематику «Храним 300 миллионов объектов в CLR процессе»
