Хочу представить вашему вниманию способ извлечения данных с документа word в виде картинок. Возможно, представленные идеи будут для кого-то примитивными и очевидными. Но мне пришлось провести пару бессонных ночей, прежде чем дойти до нормального решения. Итак, начинаю.
Было начало 2015-го. Зима. Я радовался хорошей погоде и восхищенно думал, что универ я наконец закончу (вру, сейчас поступаю в магистратуру). Свой диплом я недавно закончил, поэтому радовался еще сильнее. Однако вскоре, по натуре человеческой, состояние безмятежности плавно стало сменяться скукой. И тут, как будто специально, тишину сменил телефонный звонок.
«Алло, привет, как поживаешь?» — прозвучал голос знакомой.
Интуиция тут же определила, что скорее всего разговор будет на тему «тыжпрограммиста». Так оно и было. С унылым видом сначала я слушал про тяжкие времена знакомой и про все остальное, однако ее конечная просьба заставила меня заинтересоваться.
«Ты не мог мне помочь с дипломом? В общем, необходимо сделать сайт-тренажер по математике» — сказала она.
Это было интересно. Меня как раз увлекает разработка сложных фронтендов. Просьбу я тут же одобрил.
На реализацию тренажера ушло суммарно не более 2-х дней. Сайт-тренажер позволяет проходить тесты по высшей математике и просматривать теорию. Тесты можно проходить в двух режимах: в режиме тренировки с подсвечиванием ответов и в режиме тестирования с выводом результата в конце. Реализация была сделана на ReactJS и Bootstrap и сам процесс был достаточно приятным. Но это было только начало. Необходимо было как заполнить данными базу вопросов тестов, которые отнюдь не были в виде готовых упорядоченных данных.
Пока я удовлетворенно смотрел на результат работы, знакомая позвонила повторно. Она уведомила меня, что прислала мне небольшой архивчик с вопросами в *.doc файлах на почту. «Если что, я могу помочь перекинуть вопросы и ответы в БД» — добавила она.
Это немного подпортило мое настроение, ведь я не думал, что придется еще заполнять самостоятельно базу тестовых вопросов.
Ладно. Пошел я открывать свой GMail и тут:
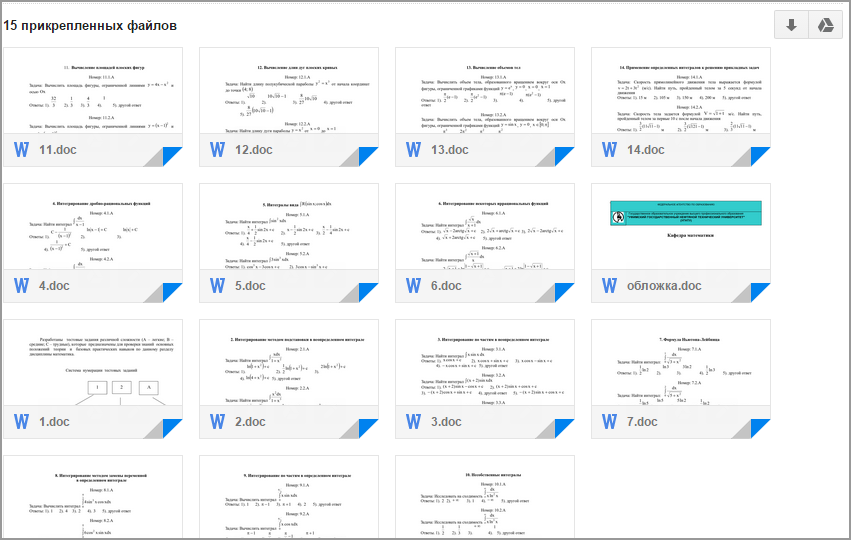
И в каждом файле ~50 тестовых заданий в виде:

Мда уж, вручную забивать все это в БД вряд ли получится. К слову, каждое тестовое задание в БД хранилось в виде одной картинки-вопроса, пяти картинок-ответов, уровня сложности (A, B, C) и номера верного ответа (1-5). Расстроенный, я решил пока что отложить этот вопрос на долгий ящик, благо времени было достаточно. Но через несколько дней на почту упало еще одно сообщение от знакомой, а потом еще… В итоге, набралось 4 раздела по высшей математике, каждый из разделов состоял из 14-23 подразделов, каждый подраздел содержал примерно 30-100 тестовых заданий. И тут я окончательно убедился, что вручную все это вбить в базу данных точно не получится.
Кстати про БД. Это MySQL с тремя таблицами: разделов, подразделов и тестовых вопросов. Картинки вопроса задания и пяти ответов хранятся непосредственно в БД, в столбце BLOB. Мне кажется так удобней, поскольку этих картинок очень много, к тому же весят они мало. И будут все они храниться в одном месте, вместе с другими данными.
Итак, что было необходимо? В наилучшем варианте нужно было из папки со всеми word файлами тестовых заданий получить готовые соответствующие записи в БД, что практически и было получено в конечном результате. Нас же интересует главное: непосредственно само извлечение картинок.
Входные данные: файл word с тестовыми заданиями.
Выходные данные (например): папка с изображениями PNG, где задание имеет имя вида 1.png, а ответы имеют имена 1.1.png, 1.2.png, 1.3.png, 1.4.png, 1.5.png, плюс к этому файл answers.txt, внутри которого i-я строка содержит число от 1 до 5, соответствующую правильному ответу i-го задания.
Я люблю Qt Creator. А с чего мне его любить? Скорее всего потому, что в универе нас натаскивают именно по нему, я сам не знаю. А еще во время пользования им я испытываю какой-то тихий восторг. Ну в общем вы поняли, на чем я стал писать программу-парсер.
Вначале я гадал, как же вообще взаимодействовать с этим вордом, чтобы как то уж выдергивать оттуда данные. На ум приходили всякие ужасные мысли наподобие конвертации word файла в HTML с последующей обработкой. Но гугление сразу же направило меня на адекватный путь, дав информацию о языке VBA. Я тут же был поражен обилием готовых функций, узнал, что такое параграфы, позиции и т.п., одновременно офигевая от сложности устройства дерева документа word.
Однако я был разочарован, поскольку так и не понял, как же превратить кусок текста в картинку. Сначала было хотел использовать что-либо наподобие text2png, предварительно выдернув нужный кусок текста. Но как же с формулами и картинками? Встроенной функции в VBA не было. В один момент у меня ненарком промелькнуло мыслишко, что вроде бы как я раньше вставлял в документ word ячейки из excel в виде картинок. Так и было! Называлось это «специальной вставкой» и позволяло вставлять любой участок документа в виде картинки. Допустим мы занесли в буфер обмена некий кусок документа, который необходимо сохранить в виде картинки. Но как эту картинку сохранить на диск? Гугление также помогло найти решение. Участок кода ниже сохраняет содержимое буфера обмена на диск в виде универсального векторного файла EMF.
Отлично. Однако что это за зверь такой, этот EMF? Необходимо было его превратить в PNG. Начал я искать конвертеры изображений. Перебрав кучу, так и не нашел адекватного. И тут опять (кто-нибудь верит в интуицию?) в голове начал вспоминаться какой-то навороченный просмотрщик изображений, который я ставил в школьные годы из диска с «Золотым софтом» забавы ради. Но вроде это был не конвертер. Однако необходимо было убедиться. В голове крутилось какое-то то ли «Ifran», то ли «Irfan», в общем программа была найдена. Бесплатная, с функцией пакетной обработки изображений, поддерживает командную строку! И самое главное, поддерживает EMF. Это было то, что надо. Исполняемый файл IrfanView с нужными DLL и ini-файлом параметров лежит в одной папке со скомпилированной программой (надеюсь это не нарушает лицензию) и используется через функцию вот так.
Теперь осталось копировать в буфер нужные куски из документа word. Для этого необходимо придумать алгоритм разбиения исходного текста на отдельные блоки с заданием, с ответами, с номером верного ответа и уровня сложности.
Первой попыткой реализации было следующее. Берем исходный документ, заменяем в нем текст вида ([1-5])\) на \n$1\), т.е. перед началом каждого ответа добавляем перевод строки. На VBA строки замены пишутся по-другому, я уже не помню. Теперь в параметрах документа ставим ширину страницы максимальной, а шрифт для всего документа уменьшаем. В результате получается, что в документе каждое задание будет занимать ровно 8 строк, причем:
Теперь после этой обработки ничего не остается, кроме как пройтись по массиву коллекции строк документа, заведя счетчик i, и в зависимости от i % 8 сохранять картинки задания/ответов или извлекать номер верного ответа с уровнем сложности.
Но это не подошло. Виноваты длинные задания, которые будучи написаны в одну строку, выглядят ужасно, мелко и не всегда вмещаются. К тому же иногда замена текста «1)» затрагивает другие места кроме номеров ответов. Опечаленный результатом, я вновь начал думать, что можно будет сделать в данном случае. И тут я вспомнил про конечные автоматы. Вспомнил про состояние, вспомнил про посимвольный ввод. Вспомнил синтаксический анализатор. Возможно это другим было очевидным решением, но я как человек далекий от сложных алгоритмов был безумно рад своей идее.
Теперь настал черед писать и пробовать код парсера на основе конечного автомата. Состояний у нас 7:
Реализуем, используя условия начала следующего состояния. После тестирования первой версии парсера все прошло великолепно. Картинки получались как в самом word документе, красивенько, крупно. Но тут… время от времени появлялись косяки, например в одной картинке захватывался лишний кусок до следующего блока задания. Значит парсер некорректно распознавал. В чем же дело? Все оказалось просто — задания в word документе набирались вручную и поэтому имел место человеческий фактор, например:
Это был кошмар. Благо основные ошибки были в написании номеров заданий, их худо-бедно учитывал парсер. Остальные ошибки после извлечения картинок обнаруживались беглым просмотром наиболее больших и маленьких по размеру картинок с последующим исправлением и повторным извлечением.
Итоговым куском парсера является код ниже. Он ужасен, просьба не судить строго. Для хранения VBA-объектов используется QAxObject.
Логика работы приведенного кода немного отличается от описанной выше. Она использует еще разбиение на абзацы. Но это не сильно меняет главную идею.
Вот таким вот образом получилось «победить» этот Word!
В итоге были извлечены все задания в количестве ~4 тыс. Нужная оболочка парсера была написана. Программа закачки заданий на удаленную БД и администрирования ею также была написана. Гонорар был получен, ее диплом защищен на отлично, мой также защищен на отлично.
Спасибо за внимание, надеюсь этот пост поможет кому нибудь в аналогичной проблеме. А может кто знает лучшую реализацию?
Update:
Было начало 2015-го. Зима. Я радовался хорошей погоде и восхищенно думал, что универ я наконец закончу (вру, сейчас поступаю в магистратуру). Свой диплом я недавно закончил, поэтому радовался еще сильнее. Однако вскоре, по натуре человеческой, состояние безмятежности плавно стало сменяться скукой. И тут, как будто специально, тишину сменил телефонный звонок.
«Алло, привет, как поживаешь?» — прозвучал голос знакомой.
Интуиция тут же определила, что скорее всего разговор будет на тему «тыжпрограммиста». Так оно и было. С унылым видом сначала я слушал про тяжкие времена знакомой и про все остальное, однако ее конечная просьба заставила меня заинтересоваться.
«Ты не мог мне помочь с дипломом? В общем, необходимо сделать сайт-тренажер по математике» — сказала она.
Это было интересно. Меня как раз увлекает разработка сложных фронтендов. Просьбу я тут же одобрил.
На реализацию тренажера ушло суммарно не более 2-х дней. Сайт-тренажер позволяет проходить тесты по высшей математике и просматривать теорию. Тесты можно проходить в двух режимах: в режиме тренировки с подсвечиванием ответов и в режиме тестирования с выводом результата в конце. Реализация была сделана на ReactJS и Bootstrap и сам процесс был достаточно приятным. Но это было только начало. Необходимо было как заполнить данными базу вопросов тестов, которые отнюдь не были в виде готовых упорядоченных данных.
Постановка задачи
Пока я удовлетворенно смотрел на результат работы, знакомая позвонила повторно. Она уведомила меня, что прислала мне небольшой архивчик с вопросами в *.doc файлах на почту. «Если что, я могу помочь перекинуть вопросы и ответы в БД» — добавила она.
Это немного подпортило мое настроение, ведь я не думал, что придется еще заполнять самостоятельно базу тестовых вопросов.
Ладно. Пошел я открывать свой GMail и тут:
И в каждом файле ~50 тестовых заданий в виде:
Мда уж, вручную забивать все это в БД вряд ли получится. К слову, каждое тестовое задание в БД хранилось в виде одной картинки-вопроса, пяти картинок-ответов, уровня сложности (A, B, C) и номера верного ответа (1-5). Расстроенный, я решил пока что отложить этот вопрос на долгий ящик, благо времени было достаточно. Но через несколько дней на почту упало еще одно сообщение от знакомой, а потом еще… В итоге, набралось 4 раздела по высшей математике, каждый из разделов состоял из 14-23 подразделов, каждый подраздел содержал примерно 30-100 тестовых заданий. И тут я окончательно убедился, что вручную все это вбить в базу данных точно не получится.
Кстати про БД. Это MySQL с тремя таблицами: разделов, подразделов и тестовых вопросов. Картинки вопроса задания и пяти ответов хранятся непосредственно в БД, в столбце BLOB. Мне кажется так удобней, поскольку этих картинок очень много, к тому же весят они мало. И будут все они храниться в одном месте, вместе с другими данными.
Итак, что было необходимо? В наилучшем варианте нужно было из папки со всеми word файлами тестовых заданий получить готовые соответствующие записи в БД, что практически и было получено в конечном результате. Нас же интересует главное: непосредственно само извлечение картинок.
Входные данные: файл word с тестовыми заданиями.
Выходные данные (например): папка с изображениями PNG, где задание имеет имя вида 1.png, а ответы имеют имена 1.1.png, 1.2.png, 1.3.png, 1.4.png, 1.5.png, плюс к этому файл answers.txt, внутри которого i-я строка содержит число от 1 до 5, соответствующую правильному ответу i-го задания.
Реализация
Я люблю Qt Creator. А с чего мне его любить? Скорее всего потому, что в универе нас натаскивают именно по нему, я сам не знаю. А еще во время пользования им я испытываю какой-то тихий восторг. Ну в общем вы поняли, на чем я стал писать программу-парсер.
Вначале я гадал, как же вообще взаимодействовать с этим вордом, чтобы как то уж выдергивать оттуда данные. На ум приходили всякие ужасные мысли наподобие конвертации word файла в HTML с последующей обработкой. Но гугление сразу же направило меня на адекватный путь, дав информацию о языке VBA. Я тут же был поражен обилием готовых функций, узнал, что такое параграфы, позиции и т.п., одновременно офигевая от сложности устройства дерева документа word.
Однако я был разочарован, поскольку так и не понял, как же превратить кусок текста в картинку. Сначала было хотел использовать что-либо наподобие text2png, предварительно выдернув нужный кусок текста. Но как же с формулами и картинками? Встроенной функции в VBA не было. В один момент у меня ненарком промелькнуло мыслишко, что вроде бы как я раньше вставлял в документ word ячейки из excel в виде картинок. Так и было! Называлось это «специальной вставкой» и позволяло вставлять любой участок документа в виде картинки. Допустим мы занесли в буфер обмена некий кусок документа, который необходимо сохранить в виде картинки. Но как эту картинку сохранить на диск? Гугление также помогло найти решение. Участок кода ниже сохраняет содержимое буфера обмена на диск в виде универсального векторного файла EMF.
#include <windows.h>
void clipboardDataToEmfFile(QString fileName){
OpenClipboard(0);
GetEnhMetaFileBits((HENHMETAFILE)GetClipboardData(14),0,0);
HENHMETAFILE returnValue = CopyEnhMetaFileA((HENHMETAFILE)GetClipboardData(14),
QDir::toNativeSeparators(fileName).toStdString().c_str());
EmptyClipboard();
CloseClipboard();
DeleteEnhMetaFile(returnValue);
}
Отлично. Однако что это за зверь такой, этот EMF? Необходимо было его превратить в PNG. Начал я искать конвертеры изображений. Перебрав кучу, так и не нашел адекватного. И тут опять (кто-нибудь верит в интуицию?) в голове начал вспоминаться какой-то навороченный просмотрщик изображений, который я ставил в школьные годы из диска с «Золотым софтом» забавы ради. Но вроде это был не конвертер. Однако необходимо было убедиться. В голове крутилось какое-то то ли «Ifran», то ли «Irfan», в общем программа была найдена. Бесплатная, с функцией пакетной обработки изображений, поддерживает командную строку! И самое главное, поддерживает EMF. Это было то, что надо. Исполняемый файл IrfanView с нужными DLL и ini-файлом параметров лежит в одной папке со скомпилированной программой (надеюсь это не нарушает лицензию) и используется через функцию вот так.
void convertEmfsToPng(QString inFolder, QString outFolder){
QProcess proc;
QString exeStr = "\"" + QDir::toNativeSeparators(QDir::currentPath()+"/i_view32.exe") + "\"";
QString inFilesStr = "\"" + QDir::toNativeSeparators(inFolder + "*.emf") + "\"";
QString outFilesStr = "\"" + QDir::toNativeSeparators(outFolder + "*.png") + "\"";
QString iniFolderStr = "\"" + QDir::toNativeSeparators(QDir::currentPath()) + "\"";
proc.start(exeStr + " " + inFilesStr + " /advancedbatch /ini=" + iniFolderStr + " /convert=" + outFilesStr);
proc.waitForFinished(30*60*1000);
}
Теперь осталось копировать в буфер нужные куски из документа word. Для этого необходимо придумать алгоритм разбиения исходного текста на отдельные блоки с заданием, с ответами, с номером верного ответа и уровня сложности.
Первой попыткой реализации было следующее. Берем исходный документ, заменяем в нем текст вида ([1-5])\) на \n$1\), т.е. перед началом каждого ответа добавляем перевод строки. На VBA строки замены пишутся по-другому, я уже не помню. Теперь в параметрах документа ставим ширину страницы максимальной, а шрифт для всего документа уменьшаем. В результате получается, что в документе каждое задание будет занимать ровно 8 строк, причем:
- строка 8*i — это текст с номером верного ответа и уровнем сложности
- строка 8*i+1 — это задание
- строка 8*i+2 — это вариант ответа №1
- ...
- строка 8*i+6 — это вариант ответа №5
- строка 8*i+7 — пустая
Повторно, как выглядят задания
Теперь после этой обработки ничего не остается, кроме как пройтись по массиву коллекции строк документа, заведя счетчик i, и в зависимости от i % 8 сохранять картинки задания/ответов или извлекать номер верного ответа с уровнем сложности.
Но это не подошло. Виноваты длинные задания, которые будучи написаны в одну строку, выглядят ужасно, мелко и не всегда вмещаются. К тому же иногда замена текста «1)» затрагивает другие места кроме номеров ответов. Опечаленный результатом, я вновь начал думать, что можно будет сделать в данном случае. И тут я вспомнил про конечные автоматы. Вспомнил про состояние, вспомнил про посимвольный ввод. Вспомнил синтаксический анализатор. Возможно это другим было очевидным решением, но я как человек далекий от сложных алгоритмов был безумно рад своей идее.
Теперь настал черед писать и пробовать код парсера на основе конечного автомата. Состояний у нас 7:
- считывание пространства между заданиями, начинается с пустой строки
- считывание строки с номером задания, в котором номер верного ответа и уровень сложности, начинается с «Номер»
- считывание текста задания, начинается с «Задача»
- считывание текста ответа №1, начинается с «Ответы: 1).»
- считывание текста ответа №2, начинается с «2).»
- ...
- считывание текста ответа №5, начинается с «5).»
Реализуем, используя условия начала следующего состояния. После тестирования первой версии парсера все прошло великолепно. Картинки получались как в самом word документе, красивенько, крупно. Но тут… время от времени появлялись косяки, например в одной картинке захватывался лишний кусок до следующего блока задания. Значит парсер некорректно распознавал. В чем же дело? Все оказалось просто — задания в word документе набирались вручную и поэтому имел место человеческий фактор, например:
- вместо «Задача» писалось «Задание»
- вместо «Ответы» писалось «Ответ»
- вместо «1).» писалось «1 ).» или «1)» или вообще «1) .»
Это был кошмар. Благо основные ошибки были в написании номеров заданий, их худо-бедно учитывал парсер. Остальные ошибки после извлечения картинок обнаруживались беглым просмотром наиболее больших и маленьких по размеру картинок с последующим исправлением и повторным извлечением.
Итоговым куском парсера является код ниже. Он ужасен, просьба не судить строго. Для хранения VBA-объектов используется QAxObject.
Разъяснения имен переменных, состояния автомата, используемых дополнительных функций
- status — состояние автомата:
- -3 — между заданиями
- -2 — внутри номера задания
- -1 — внутри задания
- 0 — после слова Ответы
- 1 — внутри ответа 1
- 2 — внутри ответа 2
- 3 — внутри ответа 3
- 4 — внутри ответа 4
- 5 — внутри ответа 5
- startind — позиция начала текущего блока (задание, ответ, строка с номером верного ответа и уровнем сложности)
- n — порядковый номер задания
- nstr — строка порядкового номера задания с ведущими нулями до трехзначного
- str — строка текущего блока до текущей позиции
- lineStart, lineEnd — номера позиций начала и конца текущего абзаца
- lines — объект коллекции абзацев документа
- tline — объект текущего абзаца
- line — объект Range текущего абзаца
- ipar — номер текущего абзаца
- tmpObj — объект Range текущего символа
- currChar — текущий символ
- outdir — строка пути выходной папки картинок
- функция getAnswerLine(QString) — возвращает строку из двух чисел: уровень сложности (1-3) и номер верного ответа (1-5), например 24 — это задание с уровнем сложности B и правильным ответом под номером 4
- функция rangeToEmfFile(QString fname, int start, int end, QAxObject *activeDoc) — сохраняет кусок документа между позициями start и end документа activeDoc как EMF-файл с именем fname
Ужасный, длинный код
QAxObject *activeDoc = wordApp->querySubObject("ActiveDocument");
int status = -3;
int startind = 0;
int n=0;
QString nstr;
QString str = "";
int lineStart, lineEnd;
QAxObject *lines = activeDoc->querySubObject("Paragraphs");
if (onlyAsnwers)
for (int ipar = 1; ipar <= lines->property("Count").toInt(); ipar++){
QAxObject *tline = lines->querySubObject("Item(QVariant)", ipar);
QAxObject *line = tline->querySubObject("Range");
QString str = line->property("Text").toString();
line->clear(); delete line;
tline->clear(); delete tline;
int ind = str.indexOf("Номер:");
if (ind != -1){
str = str.mid(ind+6);
answersTxt << getAnswerLine(str);
}
}
else
for (int ipar = 1; ipar <= lines->property("Count").toInt(); ipar++){
QAxObject *tline = lines->querySubObject("Item(QVariant)", ipar);
QAxObject *line = tline->querySubObject("Range");
lineStart = line->property("Start").toInt();
lineEnd = line->property("End").toInt();
line->clear(); delete line;
tline->clear(); delete tline;
str = "";
for (int j=lineStart; j<lineEnd; j++){
QAxObject *tmpObj = activeDoc->querySubObject("Range(QVariant,QVariant)", j, j+1);
QString currChar = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
str += currChar;
switch (status){
case -3:
if (j>=4 && str.right(5) == "Номер"){
status = -2;
startind = j+1;
}
break;
case -2:
if (str.right(6) == "Задача"){
n++; nstr = QString::number(n); while (nstr.length() < 3) nstr = "0" + nstr;
status = -1;
QAxObject *tmpObj = activeDoc->querySubObject("Range(QVariant,QVariant)", startind, j-6);
QString tmp = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
answersTxt << getAnswerLine(tmp);
startind = j+2;
} else if (str.right(7) == "Задание"){
n++; nstr = QString::number(n); while (nstr.length() < 3) nstr = "0" + nstr;
status = -1;
QAxObject *tmpObj = activeDoc->querySubObject("Range(QVariant,QVariant)", startind, j-7);
QString tmp = tmpObj->property("Text").toString();
tmpObj->clear(); delete tmpObj;
answersTxt << getAnswerLine(tmp);
startind = j+2;
}
break;
case -1:
if (str.right(7) == "Ответы:"){
status = 0;
rangeToEmfFile(outdir+nstr+".emf", startind, j-7, activeDoc);
startind = j+1;
} else if (str.right(6) == "Ответ:"){
status = 0;
rangeToEmfFile(outdir+nstr+".emf", startind, j-6, activeDoc);
startind = j+1;
}
break;
case 0:
if (str.right(2) == "1)" || str.right(3) == "1 )"){
status = 1;
startind = j+2;
}
break;
case 1:
if (str.right(2) == "2)"){
rangeToEmfFile(outdir+nstr+".1.emf", startind, j-2, activeDoc);
status = 2;
startind = j+2;
} else if (str.right(3) == "2 )"){
rangeToEmfFile(outdir+nstr+".1.emf", startind, j-3, activeDoc);
status = 2;
startind = j+2;
}
break;
case 2:
if (str.right(2) == "3)"){
rangeToEmfFile(outdir+nstr+".2.emf", startind, j-2, activeDoc);
status = 3;
startind = j+2;
} else if (str.right(3) == "3 )"){
rangeToEmfFile(outdir+nstr+".2.emf", startind, j-3, activeDoc);
status = 3;
startind = j+2;
}
break;
case 3:
if (str.right(2) == "4)"){
rangeToEmfFile(outdir+nstr+".3.emf", startind, j-2, activeDoc);
status = 4;
startind = j+2;
} else if (str.right(3) == "4 )"){
rangeToEmfFile(outdir+nstr+".3.emf", startind, j-3, activeDoc);
status = 4;
startind = j+2;
}
break;
case 4:
if (str.right(2) == "5)"){
rangeToEmfFile(outdir+nstr+".4.emf", startind, j-2, activeDoc);
status = 5;
startind = j+2;
} else if (str.right(3) == "5 )"){
rangeToEmfFile(outdir+nstr+".4.emf", startind, j-3, activeDoc);
status = 5;
startind = j+2;
}
break;
case 5:
if (j>=4 && str.right(5) == "Номер"){
rangeToEmfFile(outdir+nstr+".5.emf", startind, j-5, activeDoc);
status = -2;
str = "Номер";
} else if (lineEnd-lineStart < 2){
rangeToEmfFile(outdir+nstr+".5.emf", startind, j, activeDoc);
status = -3;
}
break;
}
}
if (status == 5)
rangeToEmfFile(outdir+nstr+".5.emf", startind, lineEnd, activeDoc);
}
lines->clear(); delete lines;
activeDoc->clear(); delete activeDoc;
Логика работы приведенного кода немного отличается от описанной выше. Она использует еще разбиение на абзацы. Но это не сильно меняет главную идею.
Вот таким вот образом получилось «победить» этот Word!
Заключение
В итоге были извлечены все задания в количестве ~4 тыс. Нужная оболочка парсера была написана. Программа закачки заданий на удаленную БД и администрирования ею также была написана. Гонорар был получен, ее диплом защищен на отлично, мой также защищен на отлично.
Спасибо за внимание, надеюсь этот пост поможет кому нибудь в аналогичной проблеме. А может кто знает лучшую реализацию?
Update:
Пара картинок результата



