Не очень хорошо помню, как я оказался в дебаггере DOSBox, и почему я ковырялся в 16-битном ассемблере, восстанавливая функцию распаковки ресурсных файлов MM3.CC – но это было здорово. Игра у меня появилась на какой-то из последних распродаж humble bundle, а потом в сети я наткнулся на страницу Джеффа Людвига, где описывались проблемы с модификацией игры, связанные с компрессией в MM3.CC. В частности, там было написано следующее:
Вызов был принят. В его статье расписано, как он пытался бороться с алгоритмом. Я же распишу, как это делал я сам, и в конце дам ссылку на утилиту с открытым кодом, которая умеет не только распаковывать, но и запаковывать файл MM3.CC file.
Посмотрев на MM3.EXE, я обнаружил, что это сжатый исполняемый файл DOS, с неким несжатым оверлеем, в начале которого стоит FBOV. Я ничего не знал про ДОСовские компрессоры, но я подсмотрел у Джеффа Людвига, что он использует вещь под названием “Universal Program Cracker” v1.11. Я нашёл версию 1.10 (выпущенную 25 июня 1997 года) и распаковал ехе. И мне удалось даже правильно обработать данные оверлея. И всё равно мне хотелось узнать название паковщика. Мне подсказали, что нужно использовать программу Detect It Easy, и действительно – она выдала:
Для любителей истории могу рекомендовать старые ветки обсуждений, касающихся этого софта – от 1991 и 1995 годов:
https://groups.google.com/forum/#!topic/comp.os.msdos.programmer/QsjHLY6Kb4s
https://groups.google.com/forum/#!topic/comp.compression/IAj2-VHbtl4
Распаковать ехе – хорошо, но правильно дизассемблировать его – ещё лучше. К сожалению, IDA на нём спотыкался. Он правильно определял оверлей, но не мог его загрузить. Просмотрев код, я понял, что анализ его без оверлея обернётся головной болью, поскольку в коде явно были пропущены участки (несмотря на то, что процедура распаковки хранится в ехе-файле). Во время поисков FBOV в гугле я наткнулся на исходники IDA DOS loader, которые подтверждали, что IDA должен без проблем уметь загружать этот оверлей. Я перекомпилировал дебаг-версию IDA DOS loader и отследил её работу через Visual Studio, чтобы понять, почему она не грузит оверлей. Для этого мне пришлось описать несколько внутренних параметров структуры FBOV. Заголовок описывается следующим образом:
exeinfo – офсет (абсолютный, с начала заголовка MZ header) массива структур, описывающих каждый сегмент, хранящийся в оверлее. segnum – количество сегментов. Они описываются такой структурой:
Это всё в теории, и в IDA DOS loader всё это реализовано в функции LoadCppOverlays(). Но с этим ехе теория перестаёт работать – правда, ошибаясь лишь на несколько байт. Во время дебага я понял, что exeinfo указывает на позицию сразу после упомянутого массива сегментов. Я добавил одну строчку в LoadCppOverlays():
И всё заработало. Документации по FBOV я не нашёл, поэтому не знаю точно, существует ли несколько реализаций этих оверлеев. Уверен, что в IDA DOS loader была реализована работа с правильной версией, потому что наверняка человек, писавший её, проверял её на живых примерах. Может быть, это была особая фишка разработчиков ММ3, кто знает.
Для поиска я использовал DOSBox debugger и набор точек останова по int 21h (стандартному прерыванию для работы с DOS API); особенно меня интересовали функции 3Dh (открыть файл), 3Fh (чтение файла) and 42h (поиск в файле). И достаточно быстро я нашёл то, что искал.
Сейчас почти всё ковыряние упаковщиков/распаковщиков делается через Hex-Rays Decompiler, который не представляет особых сложностей. Однако, он не работает с ассемблером 16-bit x86, и вряд ли когда заработает. Я будто бы вернулся назад в 2005 год, когда я написал свой первый статический распаковщик. Это было время IDA 4.9, тогда даже не существовало режима интерактивного просмотра блок-схем, который появился в марте 2006. Я упоминаю это потому, что для меня эта технология стала прорывной, и резко ускорила реверс-инжиниринг алгоритмов. Предлагаю вам графическое представление распаковщика:
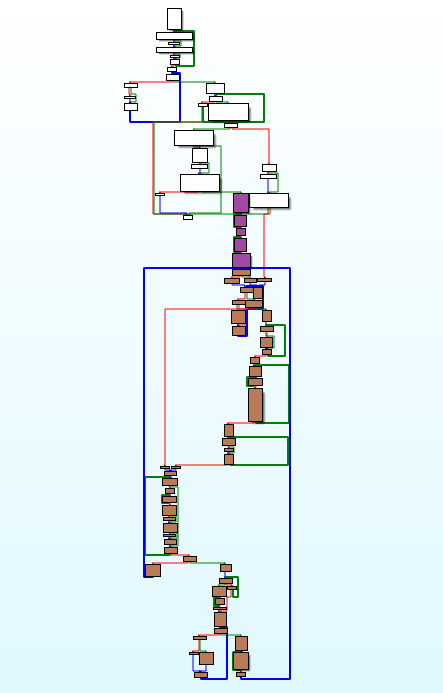
Фиолетовые блоки – инициализация алгоритма, коричневые – основной цикл распаковки, белые – работа с памятью и структурой CC-файла. Выцепление алгоритма из ассемблера обычно проходит в несколько шагов.
1. Сбор данных. Сложность зависит от сложности алгоритма. Нужно собрать информацию о входных и выходных буферах, временных буферах, переменных (локальных и глобальных) и константах, которые могут использоваться при подсчётах. Чтобы упростить работу, нужно назначать регистрам CPU переменные, имена которых похожи на имя регистра (_ax, _bx, _cx и т.д.). Тип переменной должен соответствовать размеру регистра – в нашем случае это uint16_t. В некоторых случаях лучше представлять регистры в виде объединений (union), чтобы упростить доступ к 8-битным частям регистров. Работа с локальными и глобальными переменными довольно сложна, особенно поначалу, поскольку не всегда понятно, обычного ли это типа переменная, занимающая 1,2,4 байта, или же это массив. Если встречается достаточно много доступов к адресам памяти, находящимся поблизости друг от друга, можно предположить, что это массив, а позже можно разделить их на отдельные переменные, если к ним обращались, не как к массиву. Это особенно удобно при работе с локальными переменными, поэтому все доступы к esp/ebp нужно обрабатывать через массивы (для простоты назовём это _stack). В этой фазе очень важно проинициализировать все известные данные.
2. Поиск циклов – это для меня самое интересное. Интерактивное графическое представление в IDA – один из лучших инструментов для этого. Удобно начинать с простейших внутренних циклов, и идти наверх. Каждый цикл можно окрасить в разные цвета и сгруппировать. Группировка циклов упрощает графическое представление, а сокрытие внутренних циклов помогает найти циклы следующего уровня, и так далее.
3. Переписывание кода – самая утомительная часть. Переписывать каждый opcode или группу opcode в выражения на языке более высокого уровня, блок за блоком. Если все циклы были правильно найдены, это не очень сложно сделать – но, как и любая нудная работа, эта часть подвержена ошибкам. Оставшаяся логика – это условные выражения, которые легко транслировать в язык высокого уровня. Удобно отмечать обработанные блоки другим цветом, чтобы не запутаться в них.
4. Проверка правильности. В большинстве случаев с первого раза у вас ничего не заработает. Ошибки, допущенные на первых трёх стадиях, распространены, и труднонаходимы. Их исправление обычно подразумевает запуск двух дебаггеров одновременно – для оригинального кода и для вашей версии.
5. Украшение кода. После того, как всё заработало, хорошо пройтись по коду и разобраться со всеми переменными, массивами и константами, которые до этого не были однозначно идентифицированы. Также хорошо дать переменным нормальные имена и избавиться от необязательных конструкций, имитирующих ассемблер. В идеале после этого не должно остаться переменных, названных в честь регистров х86 или массивов, имитирующих стек. Всё должно выглядеть, как нормальный код высокого уровня.
В случае Might and Magic III я прошёл все стадии, и получил в конце работающий распаковщик. Чтобы избежать ошибок из п.4, я работал с дебаггером оригинального кода, и проверял каждый переписанный простой блок на генерацию идентичного ассемблерного кода. Пройдясь по всем сжатым потокам MM3.CC, я обнаружил, что одно из ответвлений алгоритма не задействуется, поэтому пока оставил его пустым. Красные блоки на графике показывают ту часть, которая не выполняется на игровых файлах.
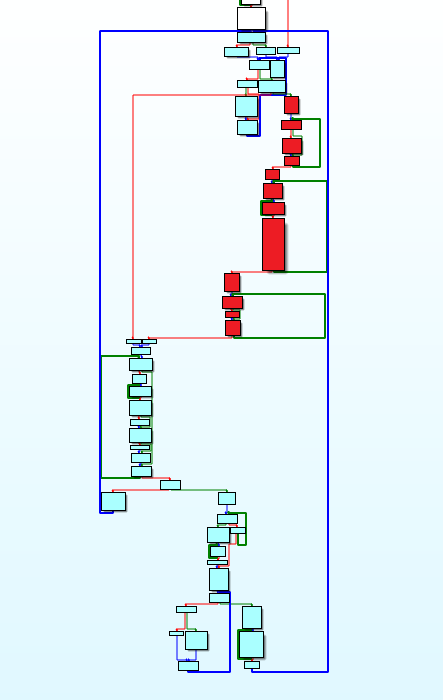
Потом я начал гуглить название алгоритма. Я искал 16-ричные константы, найденные в коде, и слово “decompress”:
«0x13A» decompress
«0x4E6» decompress
«0x274» decompress
«0x139» decompress
«0xFC4» decompress < — успех
Я нашёл исходники распаковщика какого-то старого формата от Amiga. Кроме этой константы там были также и константы-таблицы, представленные и в MM3. Оказалось, что MM3 использует алгоритм LZHUF. Узнав это, я ещё больше причесал полученный мною код, и скопировал недостающие части алгоритма (красные блоки) из этого исходника. Версия MM3 идентична оригинальной реализации LZHUF за небольшим исключением – вместо использования значения 0x20 для инициализации словаря, она использует значение, полученное из аргумента. 8-битное значение у всех сжатых потоков в файле MM3.CC разное. Я догадался, что это в каждом случае был наиболее часто встречающийся в данных байт.
Закончить титанический труд я решил нормальной утилитой, которую сможет использовать кто-то ещё. Формат CC-файла описывается в Xeen Wiki, но это описание работает только для СС-файлов из Might and Magic IV и V. А у MM3.CC структура файлов схожа, но зато отличается хэширование имён файлов и сжатие. Заголовок файла и таблица содержимого точно такие же, как описано в Xeen Wiki:
Массив FileEntries шифруется нижеприведённым алгоритмом (тем же, что указан в Xeen Wiki):
Файлы в СС-контейнере идентифицируются по 16-битному хэшу (FileEntry.hash):
Первые два файла – особые. Это несжатые тексты, и их размер прямо прописан в ехе-файле, поэтому лучше их не менять. Все остальные – сжатые блоки данных с небольшим дескриптором в начале каждого блока:
decompressionInitializer мог быть uint8_t, поскольку он всегда хранит 8-битное значение в верхних и нижних 8 битах. Не знаю, почему он хранится именно так. decompressedSize хранится в значении big-endian, что тоже странно. Ещё одна странность – после повторного сжатия при помощи моей утилиты файл MM3.CC уменьшился на 33 Кб. Также я подготовил список имён файлов, собранный из MM3.EXE, чтобы при распаковке получились правильные имена файлов (список неполный – 15 из 556 имён файлов я пропустил). Вот почти и всё – привожу ссылку на репозиторий github, где лежит упаковщик/распаковщик файлов MM3.CC
github.com/rwfpl/rewolf-mm3-dumper
Сжатие взято из стандартного LZHUF с небольшими изменениями, распаковка – результат трёхдневного реверс-инжиниринга. Сжималка и разжималка не проверяют буферы, поэтому для серьёзных вещей их использовать не рекомендуется. Использовать их просто:
Оказалось, что этот алгоритм довольно сложно взломать, и пока ещё никто не научился распаковывать эти данные.
Вызов был принят. В его статье расписано, как он пытался бороться с алгоритмом. Я же распишу, как это делал я сам, и в конце дам ссылку на утилиту с открытым кодом, которая умеет не только распаковывать, но и запаковывать файл MM3.CC file.
DOS Packer
Посмотрев на MM3.EXE, я обнаружил, что это сжатый исполняемый файл DOS, с неким несжатым оверлеем, в начале которого стоит FBOV. Я ничего не знал про ДОСовские компрессоры, но я подсмотрел у Джеффа Людвига, что он использует вещь под названием “Universal Program Cracker” v1.11. Я нашёл версию 1.10 (выпущенную 25 июня 1997 года) и распаковал ехе. И мне удалось даже правильно обработать данные оверлея. И всё равно мне хотелось узнать название паковщика. Мне подсказали, что нужно использовать программу Detect It Easy, и действительно – она выдала:
EXECUTRIX-COMPRESSOR(-)[by Knowledge Dynamics Corp]
Borland TLINK(2.0)[-]
Для любителей истории могу рекомендовать старые ветки обсуждений, касающихся этого софта – от 1991 и 1995 годов:
https://groups.google.com/forum/#!topic/comp.os.msdos.programmer/QsjHLY6Kb4s
https://groups.google.com/forum/#!topic/comp.compression/IAj2-VHbtl4
IDA DOS loader
Распаковать ехе – хорошо, но правильно дизассемблировать его – ещё лучше. К сожалению, IDA на нём спотыкался. Он правильно определял оверлей, но не мог его загрузить. Просмотрев код, я понял, что анализ его без оверлея обернётся головной болью, поскольку в коде явно были пропущены участки (несмотря на то, что процедура распаковки хранится в ехе-файле). Во время поисков FBOV в гугле я наткнулся на исходники IDA DOS loader, которые подтверждали, что IDA должен без проблем уметь загружать этот оверлей. Я перекомпилировал дебаг-версию IDA DOS loader и отследил её работу через Visual Studio, чтобы понять, почему она не грузит оверлей. Для этого мне пришлось описать несколько внутренних параметров структуры FBOV. Заголовок описывается следующим образом:
#define FB_MAGIC 0x4246
#define OV_MAGIC 0x564F
struct fbov_t
{
ushort fb; // = FB_MAGIC
ushort ov; // = OV_MAGIC
uint32 ovrsize;
uint32 exeinfo;
int32 segnum;
};
exeinfo – офсет (абсолютный, с начала заголовка MZ header) массива структур, описывающих каждый сегмент, хранящийся в оверлее. segnum – количество сегментов. Они описываются такой структурой:
struct seginfo_t
{
ushort seg;
ushort maxoff;
ushort flags;
ushort minoff;
};
Это всё в теории, и в IDA DOS loader всё это реализовано в функции LoadCppOverlays(). Но с этим ехе теория перестаёт работать – правда, ошибаясь лишь на несколько байт. Во время дебага я понял, что exeinfo указывает на позицию сразу после упомянутого массива сегментов. Я добавил одну строчку в LoadCppOverlays():
fbov.exeinfo -= fbov.segnum*sizeof(seginfo_t);
И всё заработало. Документации по FBOV я не нашёл, поэтому не знаю точно, существует ли несколько реализаций этих оверлеев. Уверен, что в IDA DOS loader была реализована работа с правильной версией, потому что наверняка человек, писавший её, проверял её на живых примерах. Может быть, это была особая фишка разработчиков ММ3, кто знает.
Ищем распаковщик
Для поиска я использовал DOSBox debugger и набор точек останова по int 21h (стандартному прерыванию для работы с DOS API); особенно меня интересовали функции 3Dh (открыть файл), 3Fh (чтение файла) and 42h (поиск в файле). И достаточно быстро я нашёл то, что искал.
Анализ алгоритма
Сейчас почти всё ковыряние упаковщиков/распаковщиков делается через Hex-Rays Decompiler, который не представляет особых сложностей. Однако, он не работает с ассемблером 16-bit x86, и вряд ли когда заработает. Я будто бы вернулся назад в 2005 год, когда я написал свой первый статический распаковщик. Это было время IDA 4.9, тогда даже не существовало режима интерактивного просмотра блок-схем, который появился в марте 2006. Я упоминаю это потому, что для меня эта технология стала прорывной, и резко ускорила реверс-инжиниринг алгоритмов. Предлагаю вам графическое представление распаковщика:
Фиолетовые блоки – инициализация алгоритма, коричневые – основной цикл распаковки, белые – работа с памятью и структурой CC-файла. Выцепление алгоритма из ассемблера обычно проходит в несколько шагов.
1. Сбор данных. Сложность зависит от сложности алгоритма. Нужно собрать информацию о входных и выходных буферах, временных буферах, переменных (локальных и глобальных) и константах, которые могут использоваться при подсчётах. Чтобы упростить работу, нужно назначать регистрам CPU переменные, имена которых похожи на имя регистра (_ax, _bx, _cx и т.д.). Тип переменной должен соответствовать размеру регистра – в нашем случае это uint16_t. В некоторых случаях лучше представлять регистры в виде объединений (union), чтобы упростить доступ к 8-битным частям регистров. Работа с локальными и глобальными переменными довольно сложна, особенно поначалу, поскольку не всегда понятно, обычного ли это типа переменная, занимающая 1,2,4 байта, или же это массив. Если встречается достаточно много доступов к адресам памяти, находящимся поблизости друг от друга, можно предположить, что это массив, а позже можно разделить их на отдельные переменные, если к ним обращались, не как к массиву. Это особенно удобно при работе с локальными переменными, поэтому все доступы к esp/ebp нужно обрабатывать через массивы (для простоты назовём это _stack). В этой фазе очень важно проинициализировать все известные данные.
2. Поиск циклов – это для меня самое интересное. Интерактивное графическое представление в IDA – один из лучших инструментов для этого. Удобно начинать с простейших внутренних циклов, и идти наверх. Каждый цикл можно окрасить в разные цвета и сгруппировать. Группировка циклов упрощает графическое представление, а сокрытие внутренних циклов помогает найти циклы следующего уровня, и так далее.
3. Переписывание кода – самая утомительная часть. Переписывать каждый opcode или группу opcode в выражения на языке более высокого уровня, блок за блоком. Если все циклы были правильно найдены, это не очень сложно сделать – но, как и любая нудная работа, эта часть подвержена ошибкам. Оставшаяся логика – это условные выражения, которые легко транслировать в язык высокого уровня. Удобно отмечать обработанные блоки другим цветом, чтобы не запутаться в них.
4. Проверка правильности. В большинстве случаев с первого раза у вас ничего не заработает. Ошибки, допущенные на первых трёх стадиях, распространены, и труднонаходимы. Их исправление обычно подразумевает запуск двух дебаггеров одновременно – для оригинального кода и для вашей версии.
5. Украшение кода. После того, как всё заработало, хорошо пройтись по коду и разобраться со всеми переменными, массивами и константами, которые до этого не были однозначно идентифицированы. Также хорошо дать переменным нормальные имена и избавиться от необязательных конструкций, имитирующих ассемблер. В идеале после этого не должно остаться переменных, названных в честь регистров х86 или массивов, имитирующих стек. Всё должно выглядеть, как нормальный код высокого уровня.
В случае Might and Magic III я прошёл все стадии, и получил в конце работающий распаковщик. Чтобы избежать ошибок из п.4, я работал с дебаггером оригинального кода, и проверял каждый переписанный простой блок на генерацию идентичного ассемблерного кода. Пройдясь по всем сжатым потокам MM3.CC, я обнаружил, что одно из ответвлений алгоритма не задействуется, поэтому пока оставил его пустым. Красные блоки на графике показывают ту часть, которая не выполняется на игровых файлах.
Потом я начал гуглить название алгоритма. Я искал 16-ричные константы, найденные в коде, и слово “decompress”:
«0x13A» decompress
«0x4E6» decompress
«0x274» decompress
«0x139» decompress
«0xFC4» decompress < — успех
Я нашёл исходники распаковщика какого-то старого формата от Amiga. Кроме этой константы там были также и константы-таблицы, представленные и в MM3. Оказалось, что MM3 использует алгоритм LZHUF. Узнав это, я ещё больше причесал полученный мною код, и скопировал недостающие части алгоритма (красные блоки) из этого исходника. Версия MM3 идентична оригинальной реализации LZHUF за небольшим исключением – вместо использования значения 0x20 для инициализации словаря, она использует значение, полученное из аргумента. 8-битное значение у всех сжатых потоков в файле MM3.CC разное. Я догадался, что это в каждом случае был наиболее часто встречающийся в данных байт.
MM3.CC Packer/Unpacker
Закончить титанический труд я решил нормальной утилитой, которую сможет использовать кто-то ещё. Формат CC-файла описывается в Xeen Wiki, но это описание работает только для СС-файлов из Might and Magic IV и V. А у MM3.CC структура файлов схожа, но зато отличается хэширование имён файлов и сжатие. Заголовок файла и таблица содержимого точно такие же, как описано в Xeen Wiki:
struct FileEntry;
struct FileHeader
{
uint16_t NumberOfFileEntries
FileEntry FileEntries[NumberOfFileEntries];
};
struct FileEntry
{
uint16_t hash;
uint16_t offsetLo;
uint8_t offsetHi;
uint16_t compressedSize; // includes 4 bytes header
uint8_t padding;
};
Массив FileEntries шифруется нижеприведённым алгоритмом (тем же, что указан в Xeen Wiki):
void encryptHeader(uint8_t* buf, size_t size)
{
uint8_t key = 0xAC;
for (size_t i = 0; i < size; i++)
{
buf[i] = _rotr8(buf[i] - key, 2);
key += 0x67;
}
}
void decryptHeader(uint8_t* buf, size_t size)
{
uint8_t key = 0xAC;
for (size_t i = 0; i < size; i++)
{
buf[i] = _rotl8(buf[i], 2) + key;
key += 0x67;
}
}
Файлы в СС-контейнере идентифицируются по 16-битному хэшу (FileEntry.hash):
uint16_t hashFileName(const char* fileName)
{
uint16_t hash = 0;
while (0 != *fileName)
{
uint8_t c = ((*fileName & 0x7F) < 0x60) ? *fileName : *fileName - 0x20;
hash = _rotl16(hash, 9); // xchg bl, bh | rol bx, 1
hash += c;
fileName++;
}
return hash;
}
Первые два файла – особые. Это несжатые тексты, и их размер прямо прописан в ехе-файле, поэтому лучше их не менять. Все остальные – сжатые блоки данных с небольшим дескриптором в начале каждого блока:
{
uint16_t decompressionInitializer;
uint16_t decompressedSize;
}
decompressionInitializer мог быть uint8_t, поскольку он всегда хранит 8-битное значение в верхних и нижних 8 битах. Не знаю, почему он хранится именно так. decompressedSize хранится в значении big-endian, что тоже странно. Ещё одна странность – после повторного сжатия при помощи моей утилиты файл MM3.CC уменьшился на 33 Кб. Также я подготовил список имён файлов, собранный из MM3.EXE, чтобы при распаковке получились правильные имена файлов (список неполный – 15 из 556 имён файлов я пропустил). Вот почти и всё – привожу ссылку на репозиторий github, где лежит упаковщик/распаковщик файлов MM3.CC
github.com/rwfpl/rewolf-mm3-dumper
Сжатие взято из стандартного LZHUF с небольшими изменениями, распаковка – результат трёхдневного реверс-инжиниринга. Сжималка и разжималка не проверяют буферы, поэтому для серьёзных вещей их использовать не рекомендуется. Использовать их просто:
x:\mm3>mm3_cc_dumper.exe
Might and Magic III CC file packer/unpacker v1.0
Copyrigh (c) 2015 ReWolf
http://blog.rewolf.pl
Usage:
Unpack: mm3_cc_dumper.exe dump input_file.cc
Pack: mm3_cc_dumper.exe pack input_directory output_file.cc
