Comments 61
Очень крутая статья, с глубоким пониманием и обьяснением того что происходит…
Рискую оказаться закиданным камнями — а платят за такую программную инжинерию, для которой нужно очень много знаний и понимания как по сравнению с разработками, например, под веб на фреймворках как?
Рискую оказаться закиданным камнями — а платят за такую программную инжинерию, для которой нужно очень много знаний и понимания как по сравнению с разработками, например, под веб на фреймворках как?
Сколько времени заняла разработка до первой стабильной версии?
Один вопрос… в какой программе рисовались диаграммы?
{kind=link}
Огромное спасибо, введение очень наглядное и понятное, буквально «на пальцах», но не пропущены технические детали (я хоть и не спец в этой области, но просветление настало). Да и Ваша реализация описана не хуже.
Побольше бы таких статей!
Побольше бы таких статей!
Нас этому (на других процессорах и на других ОС) учили 18 лет назад. Ностальгия. Никому из группы не потребовалось… :-(
Отличная статья!
Отличная статья!
Может правильнее написать «Никто из группы не решил / не смог воспользоваться полученными знаниями»?
Я понимаю, что в советское было целевое обучение, но считаю фразу «мне в школе преподавали много того, что в жизни не пригодится» некорректной.
Это сам ученик должен искать способ применить полученные знания. Иначе он выбран неправильное уч. заведение.
Я понимаю, что в советское было целевое обучение, но считаю фразу «мне в школе преподавали много того, что в жизни не пригодится» некорректной.
Это сам ученик должен искать способ применить полученные знания. Иначе он выбран неправильное уч. заведение.
Статья потрясающая, очень увлекательно, читается легко!
P.S. Слово же вроде бы обычно 2 байта, а 4 уже DWORD.
P.S. Слово же вроде бы обычно 2 байта, а 4 уже DWORD.
Спасибо за отзыв!
Насчет «слова» — этот термин, к сожалению, обозначает разные вещи. Здесь имеется в виду платформозависимая величина, равная разрядности регистров процессора. Процессор может обрабатывать значения размером в 1 слово за один такт (32-битный процессор может, например, за один такт сложить два 32-битных числа, в то время как 8-битному потребуется для этого гораздо больше тактов)
Wikipedia: Word (computer architecture)
Насчет «слова» — этот термин, к сожалению, обозначает разные вещи. Здесь имеется в виду платформозависимая величина, равная разрядности регистров процессора. Процессор может обрабатывать значения размером в 1 слово за один такт (32-битный процессор может, например, за один такт сложить два 32-битных числа, в то время как 8-битному потребуется для этого гораздо больше тактов)
Wikipedia: Word (computer architecture)
Дмитрий, это нереально круто. Вы всю работу проделали один?
Круто, действительно очень полезная работа и отличная статья. Я все ещё не рискую использоать ОС в своих разработках, так как даже опенсорсные системы — это большой черный ящик с непонятным количеством багов и непонятными прогнозами по производительности. А тратить пару месяцев только на освоение, как устроена и как работает RTOS — непозволительная роскошь для меня в данный период времени. Но такая статья вызывает желание все таки начать именно с вашей ОС.
Спасибо и вам за отзыв. Я постарался сделать документацию понятной (есть и Quick Guide, и примитивные примеры для разных платформ в репозитории), но если что — спрашивайте.
Дима, отличная статья!
Стоит уточнить, что PIC32MX. Но PIC32MZ нам, возможно, нужен будет в ближайшее время :)
В данный момент, ядро портировано на следующие архитектуры:
ARM Cortex-M cores: Cortex-M0/M0+/M1/M3/M4/M4F (supported toolchains: GCC, Keil RealView, clang, IAR)
Microchip: PIC32/PIC24/dsPIC
Стоит уточнить, что PIC32MX. Но PIC32MZ нам, возможно, нужен будет в ближайшее время :)
Статья неплохая, но хотелось бы увидеть карту распределения памяти. Мне после прочтения осталось не ясно, как именно выделяется память новым экземплярам структур, в который встраивается список при «Оба варианта неприемлемы. Поэтому используется вариант с встраиванием и, кстати, точно такой же подход используется в ядре Linux » без использования кучи в ядре.
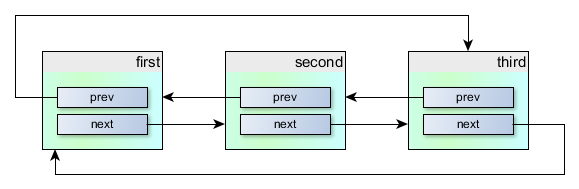
Хм. Так в статье ведь есть карта распределения памяти: вот. Приложение выделяет экземпляры объектов (т.е. MyBlock примера в статье) самостоятельно и как угодно (в моих приложениях, чаще всего, статически). И передает указатели на эти выделенные объекты ядру. И когда ядро должно добавить этот экземпляр в какой-нибудь список, то оно просто модифицирует несколько указателей, и все.
В случае же с отдельным (не встроенным)
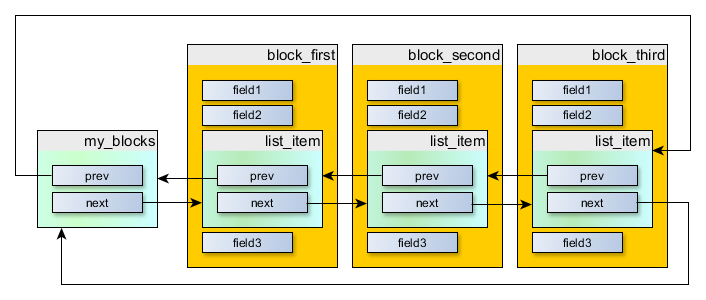{kind=link}
В случае же с отдельным (не встроенным)
TN_ListItem, для каждого добавляемого объекта в список, ядру пришлось бы отдельно где-то выделить этот TN_ListItem: работает гораздо дольше, нужно больше памяти, cache locality хуже.Я имел ввиду пример карты распределения всей памяти микроконтроллера в абсолютной адресации (ну или хотя бы файл карты памяти скомпилированного образа ОС например с тестами в виде пользовательского приложения, созданный самим компилятором). А про списки, правильно ли я понимаю, что при старте новой задачи память под новый экземпляр struct TN_Task выделяется приложением, а не ядром?
map-файл — это легко, вот: tn_pic32_example_basic.X.production.map (сгенерирован из примера в репозитории examples/basic/arch/pic32)
А вот насчет визуализации: я сам когда-то пытался найти инструмент, который сможет визуализировать map-файл, сгенерированный компилятором; очень полезно иногда было бы; когда, например, где-то память портится. Не нашел такого инструмента. Если знаете — поделитесь, пожалста.
См. tn_task_create(): первый аргумент
А вот насчет визуализации: я сам когда-то пытался найти инструмент, который сможет визуализировать map-файл, сгенерированный компилятором; очень полезно иногда было бы; когда, например, где-то память портится. Не нашел такого инструмента. Если знаете — поделитесь, пожалста.
А про списки, правильно ли я понимаю, что при старте новой задачи память под новый экземпляр struct TN_Task выделяется приложением, а не ядром?Да, правильно. Небольшое уточнение только: память выделяется не при старте задачи, а при ее создании (созданную задачу можно останавливать и запускать сколько угодно раз; правда, в реальной жизни мне это ни разу не пригождалось).
См. tn_task_create(): первый аргумент
struct TN_Task *task — это как раз указатель на дескриптор задачи, который приложение должно где-то выделить до вызова этого сервиса.девайс, анализирующий аналоговый сигнал с автомобильной свечи— уж не занимаетесь ли вы системами, оптимизирующими УОЗ через анализ функции тока плазмы от времени?
А вообще, синхронизация внутри ISR-обработчиков ядра и в частности, реакция на вложенные прерывания — это очень тонкие места — надо быть реальным параноиком, чтобы а приори умозрительно отследить и выловить все нарушения синхронизации — чуть раньше разрешил общие прерывания или сбросил маску контроллера — и привет. Причем, тесты на целостность ядра средствами собственного кристалла (из-за синхронности счетной периферии с тактированием ядра CPU) могут не падать вообще — а интенсивные истинно асинхронные события — валить систему.
BTW, я подобное поведение видел даже в аппаратном (!) исполнении еще на 8085 в связке с ИС контроллера прерываний 8259 — множественные асинхронные запросы (например, от дребезга входа) переполняли стек, несмотря на гарантированный спекой аппаратный автосброс маски в самом контроллере. Помогла тогда только явная синхронизация запросов с системным клоком через D-триггер )
Очень здорово.
А не было желания создать свой целый курс «Пишем свою ОС с нуля за16 32 64 дня» попутно рассказывая принципы работы микропроцессоров и ОС в деталях? Основная суть была бы в том, чтобы создавать конкретную работающую вещь, под конкретный тип/типы процессоров и видеть работу на реальных железках.
А не было желания создать свой целый курс «Пишем свою ОС с нуля за
Какая прелесть!
Отличное изложение контекста проблемы, описание решений и код очень качественный…
Спасибо!
Отличное изложение контекста проблемы, описание решений и код очень качественный…
Спасибо!
Хорошая статья, спасибо. Попробую запустить вашу ОС на Kinetis'e (Cortex M4).
pdf не доступны.
pdf не доступны.
интересно, у вас есть динамическая приоритезация задач? Что будет, если высокоприоритетная задача A ждет семафора, открываемого низкоприоритетной задачей B, которая не получает квант от планировщика ввиду низкого приоритета?
Конечно, есть. То, о чем вы говорите — это инверсия приоритетов. Только для этого нужно использовать не семафор, а мютекс. Ядро поддерживает два метода обхода инверсии приоритетов: priority ceiling и priority inheritance (и, кстати, это работало криво в TNKernel: с помощью юнит-тестов я нашел две простые ситуации, когда инверсия приоритетов не обрабатывается корректно. Подробнее тут: Bugs of TNKernel 2.7)
Вообще, эти термины, мютекс и семафор, очень часто путают, даже в серьезных библиотеках и РТОСах. Насчет отличий семафоров и мютексов крайне рекомендую к прочтению две ссылки:
Вкратце:
Мютекс
Когда задача захватывает мютекс, она им владеет. И только она может его разблокировать. Кроме прочего, именно то, что мютекс «принадлежит» задаче, позволяет обойти инверсию приоритетов, о которой вы говорили. Поэтому мютексы нужно использовать именно для защиты разделяемых ресурсов: задача блокирует мютекс, работает с каким-либо ресурсом, разблокирует мютекс. По этой же причине, мютексы нельзя использовать в прерываниях (т.к. у мютекса должна быть задача-владелец).
Семафор
С семафором картина совершенно иная: его не блокируют или разблокируют, а ждут и сигналят. И эти действия производятся в разных потоках: например, поток А должен сделать какую-то работу, после которой поток Б может делать свою. Тогда поток Б ждет семафор, а поток А сигналит ему: типа, у меня все готово, теперь давай ты. Также сигналить семафором можно из прерывания.
По ссылкам выше можно найти более подробное объяснение.
Конечно, можно использовать семафоры вместо мютексов, работать кое-как будет (без обработки инверсии приоритетов). Но можно и саморезы в стену гвоздями забивать, держаться будут.
И еще раз подчеркну: эти термины очень часто путают, даже в серьезных продуктах. Так что если кто-то работал в какой-то среде, где мютексы назывались семафорами — я нисколько не удивлюсь.
Вообще, эти термины, мютекс и семафор, очень часто путают, даже в серьезных библиотеках и РТОСах. Насчет отличий семафоров и мютексов крайне рекомендую к прочтению две ссылки:
- Mutexes and Semaphores Demystified by Michael Barr
- Вопрос на SO: Difference between binary semaphore and mutex
Вкратце:
Мютекс
Когда задача захватывает мютекс, она им владеет. И только она может его разблокировать. Кроме прочего, именно то, что мютекс «принадлежит» задаче, позволяет обойти инверсию приоритетов, о которой вы говорили. Поэтому мютексы нужно использовать именно для защиты разделяемых ресурсов: задача блокирует мютекс, работает с каким-либо ресурсом, разблокирует мютекс. По этой же причине, мютексы нельзя использовать в прерываниях (т.к. у мютекса должна быть задача-владелец).
Семафор
С семафором картина совершенно иная: его не блокируют или разблокируют, а ждут и сигналят. И эти действия производятся в разных потоках: например, поток А должен сделать какую-то работу, после которой поток Б может делать свою. Тогда поток Б ждет семафор, а поток А сигналит ему: типа, у меня все готово, теперь давай ты. Также сигналить семафором можно из прерывания.
По ссылкам выше можно найти более подробное объяснение.
Конечно, можно использовать семафоры вместо мютексов, работать кое-как будет (без обработки инверсии приоритетов). Но можно и саморезы в стену гвоздями забивать, держаться будут.
И еще раз подчеркну: эти термины очень часто путают, даже в серьезных продуктах. Так что если кто-то работал в какой-то среде, где мютексы назывались семафорами — я нисколько не удивлюсь.
Я написал «семафор», как наиболее базовое определение синхронизационного примитива, который опирается непосредственно либо на машинную реализацию атомарных команд «проверка-изменение», либо на синтетически созданную атомарность (запрещение прерываний)
Мьютекс — тот же двоичный семафор плюс тэг ID процесса, в данный момент его удерживающего, обновляемый атомарно со значением самого семафора. С точки зрения же пользовательского кода мьютекс — просто более частное и более удобное средство межпоточной синхронизации по сравнению с бинарным семафором для *конкретных* применений — и все, так как он а) защищен от повторных входов тем же тредом, б) защищен от случайных или злонамеренных действий других процессов, ну и c) может быть проверен перед захватом (не уверен, что эта возможность есть во всех реализациях)
Например, мы можем точно так же написать ожидание семафора в начале критической секции и просигналить освобождение его в конце, как и захватить и освободить мьютекс. Проблема инверсии приоритетов для семафоров тоже будет проявляться точно так же:
LowPriA прошел семафор
HighPriC встал на ожидание семафора, пройденного А
MiddlePriB вытеснил A
Вместо «прошел семафор» можно написать «захватил мьютекс» — суть от этого не поменяется. ЕМНИП (здесь могу ошибаться) эта проблема была описана еще Дийкстрой как раз на примере семафоров, а мьютексов у него тогда еще даже не было
Мьютекс — тот же двоичный семафор плюс тэг ID процесса, в данный момент его удерживающего, обновляемый атомарно со значением самого семафора. С точки зрения же пользовательского кода мьютекс — просто более частное и более удобное средство межпоточной синхронизации по сравнению с бинарным семафором для *конкретных* применений — и все, так как он а) защищен от повторных входов тем же тредом, б) защищен от случайных или злонамеренных действий других процессов, ну и c) может быть проверен перед захватом (не уверен, что эта возможность есть во всех реализациях)
Например, мы можем точно так же написать ожидание семафора в начале критической секции и просигналить освобождение его в конце, как и захватить и освободить мьютекс. Проблема инверсии приоритетов для семафоров тоже будет проявляться точно так же:
LowPriA прошел семафор
HighPriC встал на ожидание семафора, пройденного А
MiddlePriB вытеснил A
Вместо «прошел семафор» можно написать «захватил мьютекс» — суть от этого не поменяется. ЕМНИП (здесь могу ошибаться) эта проблема была описана еще Дийкстрой как раз на примере семафоров, а мьютексов у него тогда еще даже не было
Снимаю шляпу перед вами за такой подробный и насыщенный пост! Необходимо титанические усилия для таких деяний – огромное спасибо.
Очень круто!
Спасибо, было интересно.
А вы проводили какое-нибудь исследование этой области? Просто таких систем пруд-пруди, та же ChibiOS имеет все описанные свойства (про контроль стека не уверен), а заявленных для поддержки платформ там на порядок больше. Поэтому создание с нуля еще одной ни с чем не совместимой системы выглядит как удовлетворение собственных амбиций за счет работодателя. Может вы еще какие-то проблемы решали? С IP например?
Если вы читали статью, то, может быть, заметили: был нужен API, по-максимуму совместимый с TNKernel, чтобы без проблем перенести существующие проекты (оставлять на старой ОС нельзя). Так что изначальный план был — улучшить TNKernel, ну а получилось так глобально в итоге. Это первое.
Второе: с грустью глядя на найденные баги в TNKernel (которая достаточно популярна, и используется давно), я уже не очень хотел доверять другим РТОСам. Может, конечно, ChibiOS и другие тестируются очень хорошо и подробно — я же не знаю.
Третье: пока я этим занимался, я неплохо разобрался в матчасти, так что это, в некоторой степени, вклад в будущее. Самообучение для вас — тоже «удовлетворение амбиций»? Ну и, кстати, с работодателем мы в доле: пока я работал над ядром, я реально горел, так что работал по 12 часов в сутки, включая некоторые выходные. И, конечно, в целом работодатели вкладываются в обучение своих сотрудников, это нормально.
Тон вашего комментария, конечно, такой, малоприятный. К сожалению, когда подобные комментарии оставляют у моих статей, я вынужден отвечать и на них.
Второе: с грустью глядя на найденные баги в TNKernel (которая достаточно популярна, и используется давно), я уже не очень хотел доверять другим РТОСам. Может, конечно, ChibiOS и другие тестируются очень хорошо и подробно — я же не знаю.
Третье: пока я этим занимался, я неплохо разобрался в матчасти, так что это, в некоторой степени, вклад в будущее. Самообучение для вас — тоже «удовлетворение амбиций»? Ну и, кстати, с работодателем мы в доле: пока я работал над ядром, я реально горел, так что работал по 12 часов в сутки, включая некоторые выходные. И, конечно, в целом работодатели вкладываются в обучение своих сотрудников, это нормально.
Тон вашего комментария, конечно, такой, малоприятный. К сожалению, когда подобные комментарии оставляют у моих статей, я вынужден отвечать и на них.
Насчет тестирования критических мест — попробуйте а) добавить внешний генератор событий, асинхронный по отношению к тестируемому SoC, генерируя события как по внутренним таймерам, так и по edge-activated interrupts от этого генератора; b) искусственно расширить критичные области, хотя бы добавив NOPов под условной компиляцией — чтобы увеличить вероятность сбоев синхронизации на них — поскольку тестирование корректности работы многопоточных систем методом интенсивной генерации событий — вещь вероятностная, и если вы ошибочно «приоткрылись» всего на одну команду — ошибка при синхронном с тактированием ядра режиме на процессорах синхронной же архитектуры может не вылезти вообще никогда. Искусственное же расширение критических секций позволяет не только увеличить вероятность сталкивания потоков на критических местах, но и сымитировать состояние ядра, близкое к насыщению внешними событиями, и выявить ошибки, возникающие при приближении интенсивности запросов на прерывания к этому пределу
Вещи правильные говорите, спасибо, я и сам об этом уже думал, но не знаю, когда смогу добраться. Идей больше, чем времени.
В идеале, мне хотелось бы следующего: для всех поддерживаемых платформ иметь однотипные девайсы, которые я смогу подключить по USB все сразу к какой-нибудь машине, и эта машина при появлении новых коммитов должна собрать прошивки с юнит-тестами для каждого устройства, залить их, прогнать и выдать результат, чтобы я сразу видел, появились ли проблемы. После чего непрерывно гонять текущую прошивку с асинхронными событиями, как вы говорите. Пусть хоть месяцами подряд. Ну и если когда-нибудь что-то всплывет, то я об этом должен узнать.
Это, конечно, все классно, но пока выделить столько времени нет возможности.
Подробные формализованные тесты написаны — уже очень хорошо; а эти вероятностные вещи приходится гонять на реальных устройствах, где асинхронных событий сколько хочешь. За последний год проблем не было, так что пока считаю, что все хорошо.
В идеале, мне хотелось бы следующего: для всех поддерживаемых платформ иметь однотипные девайсы, которые я смогу подключить по USB все сразу к какой-нибудь машине, и эта машина при появлении новых коммитов должна собрать прошивки с юнит-тестами для каждого устройства, залить их, прогнать и выдать результат, чтобы я сразу видел, появились ли проблемы. После чего непрерывно гонять текущую прошивку с асинхронными событиями, как вы говорите. Пусть хоть месяцами подряд. Ну и если когда-нибудь что-то всплывет, то я об этом должен узнать.
Это, конечно, все классно, но пока выделить столько времени нет возможности.
Подробные формализованные тесты написаны — уже очень хорошо; а эти вероятностные вещи приходится гонять на реальных устройствах, где асинхронных событий сколько хочешь. За последний год проблем не было, так что пока считаю, что все хорошо.
У автора ChibiOS, кстати, многоплатформенное тестирование построено хоть и синхронно (то есть средствами встроенной периферии), но по выходу нового коммита сразу пачками для всех платформ и надолго — где-то на его сайте chibios.org была инфа об этом. BTW, как вы решали проблему вложенности запрета/разрешения прерываний при вызовах функций ядра из разных «колец» — обычного процесса, ISR и изнутри самого ядра?
И еще — вроде бы ваша оценка стека ISR — порядка 1Kбайт — почему так много?
Позволяете ли вы вызывать из ISR все вызовы RTOS, или только подмножество?
Как код переноса SP в область ISR после входа (и по все видимости, сохранения минимального контекста — флагов и IP) обрабатывает ситуацию вложенных прерываний? Насколько он эффективен (какая латентность привносится в обработчик прерываний до пользовательского кода)?
И еще — вроде бы ваша оценка стека ISR — порядка 1Kбайт — почему так много?
Позволяете ли вы вызывать из ISR все вызовы RTOS, или только подмножество?
Как код переноса SP в область ISR после входа (и по все видимости, сохранения минимального контекста — флагов и IP) обрабатывает ситуацию вложенных прерываний? Насколько он эффективен (какая латентность привносится в обработчик прерываний до пользовательского кода)?
Для вложенного запрета/разрешения прерываний есть сервисы tn_arch_sr_save_int_dis() / tn_arch_sr_restore(), а также макросы TN_INT_DIS_SAVE() / TN_INT_RESTORE(), которые, будучи макросами, имеют шансы быть реализованными более эффективно, чем вызов функции.
1 кБ для ISR — как я написал, это полностью зависит от приложения. Может, где-то и 200 байт достаточно будет. Как минимум, есть 128 байт для контекста, плюс нужно для каждого приоритета прерывания предположить, что все вложенные прерывания вызывались в самом худшем случае. Точно высчитывать, сколько стека нужно, и выделять ровно-ровно — вообще дело неблагодарное, только в крайнем случае можно этим заняться, когда RAM ну вообще нет больше. Я обычно просто смотрю, сколько испачкано, и оставляю раза в два больше, на всякий случай.
Конечно, от архитектуры зависит. На MIPS — 6-10 лишних инструкций до и после ISR, на PIC24/dsPIC — 3-5 инструкций. А вот Кортекс я люблю за то, что эта платформа была спроектирована «with OS in mind», так что она все делает за меня. Ядро ничего особенного не делает, когда происходит прерывание.
1 кБ для ISR — как я написал, это полностью зависит от приложения. Может, где-то и 200 байт достаточно будет. Как минимум, есть 128 байт для контекста, плюс нужно для каждого приоритета прерывания предположить, что все вложенные прерывания вызывались в самом худшем случае. Точно высчитывать, сколько стека нужно, и выделять ровно-ровно — вообще дело неблагодарное, только в крайнем случае можно этим заняться, когда RAM ну вообще нет больше. Я обычно просто смотрю, сколько испачкано, и оставляю раза в два больше, на всякий случай.
Позволяете ли вы вызывать из ISR все вызовы RTOS, или только подмножество?Как можно все сервисы RTOS вызывать из прерывания? В прерывании нельзя вызывать любой сервис, который может ждать. Пока что, по образу и подобию TNKernel и других РТОС, для прерываний существует отдельный набор сервисов, но вообще-то, как минимум на поддерживаемых в данный момент архитектурах, можно было бы просто позволить вызывать любые сервисы, которые не могут ждать. Но пока, как наследие от TNKernel, есть отдельный набор сервисов. Доп. инфу см. тут, тут.
Как код переноса SP в область ISR после входа (и по все видимости, сохранения минимального контекста — флагов и IP) обрабатывает ситуацию вложенных прерываний? Насколько он эффективен (какая латентность привносится в обработчик прерываний до пользовательского кода)?
Конечно, от архитектуры зависит. На MIPS — 6-10 лишних инструкций до и после ISR, на PIC24/dsPIC — 3-5 инструкций. А вот Кортекс я люблю за то, что эта платформа была спроектирована «with OS in mind», так что она все делает за меня. Ядро ничего особенного не делает, когда происходит прерывание.
Давайте не будем обижаться, а рассмотрим вашу работу с точки зрения общества. Вы ж не в «я пиарюсь» блог пишете.
На данный момент, по вашему же опыту, стоит проблема выбора системы для своих проектов. Неверный выбор чреват значительной потерей времени и никто не гарантирует, что положительные отзывы означают стабильную работу с вашем конкретном случае.
Как я понял, TNKernel вас долгое время всем устраивала, пока вы не нашли критический баг. Принцип OpenSource подразумевает, что каждый может внести посильную лепту в создание и поддержание проекта. Что ж, возможно, в случае с TNKernel вариант «все переписать» действительно проще, чем «исправить». И мне сразу понравилась ваша первоначальная идея сохранить API. Но что же сообщество в конце концов получило? На мой взгляд, еще одну систему, несовместимую или малосовместимую с родителем, и чей статус так же неочевиден для будущих инженеров, как и статус TNKrrnel, ChibiOS и прочих с гораздо более громкими именами.
Вы упоминаете, что не доверяете другим проектам из-за потенциальных проблем. Сомнительный аргумент. Вы же не будете утверждать, что считаете свой код безупречным? Согласен, всегда важно досконально разбираться в работе приложения, которое используешь. Но RTOS в большинстве случаев — не rocket science. И в принципе, каждый уважающий себя эмбедер раз в жизни пишет свой вариант планироващика. Вот только полезность для окружающих такого действия сомнительна. В тоже время разобраться в работе существующих систем до уровня «знаю как сам писал» не вызывает сложности. И на мой взгляд, было бы гораздо полезнее довести вашу первоначальную идею до ума. Полезнее для общества, не для ваших конкретных проектов. Поэтому я и задал вопрос: а какие еще задачи вы решали, создавая свою систему? Может для PIC32 нет такого широкого рынка RTOS как для Cortex? Или АПИ TNKErnel такой необычный, что слезть с него очень тяжело?
Кстати, если тон комментариев вас не устраивает, то отвечать вовсе и не обязательно. Мы ж не лицом к лицу беседуем.
На данный момент, по вашему же опыту, стоит проблема выбора системы для своих проектов. Неверный выбор чреват значительной потерей времени и никто не гарантирует, что положительные отзывы означают стабильную работу с вашем конкретном случае.
Как я понял, TNKernel вас долгое время всем устраивала, пока вы не нашли критический баг. Принцип OpenSource подразумевает, что каждый может внести посильную лепту в создание и поддержание проекта. Что ж, возможно, в случае с TNKernel вариант «все переписать» действительно проще, чем «исправить». И мне сразу понравилась ваша первоначальная идея сохранить API. Но что же сообщество в конце концов получило? На мой взгляд, еще одну систему, несовместимую или малосовместимую с родителем, и чей статус так же неочевиден для будущих инженеров, как и статус TNKrrnel, ChibiOS и прочих с гораздо более громкими именами.
Вы упоминаете, что не доверяете другим проектам из-за потенциальных проблем. Сомнительный аргумент. Вы же не будете утверждать, что считаете свой код безупречным? Согласен, всегда важно досконально разбираться в работе приложения, которое используешь. Но RTOS в большинстве случаев — не rocket science. И в принципе, каждый уважающий себя эмбедер раз в жизни пишет свой вариант планироващика. Вот только полезность для окружающих такого действия сомнительна. В тоже время разобраться в работе существующих систем до уровня «знаю как сам писал» не вызывает сложности. И на мой взгляд, было бы гораздо полезнее довести вашу первоначальную идею до ума. Полезнее для общества, не для ваших конкретных проектов. Поэтому я и задал вопрос: а какие еще задачи вы решали, создавая свою систему? Может для PIC32 нет такого широкого рынка RTOS как для Cortex? Или АПИ TNKErnel такой необычный, что слезть с него очень тяжело?
Кстати, если тон комментариев вас не устраивает, то отвечать вовсе и не обязательно. Мы ж не лицом к лицу беседуем.
Для того, чтобы обществу (и в первую очередь, мне самому) было проще переносить на TNeo существующие TNKernel-овские проекты, существует режим совместимости: выключаем рекурсивные мютексы, включаем совместимость с евентами. После этого, чтобы перенести проект с TNKernel на TNeo, потребуются тривиальные изменения в приложении, если вообще потребуются. Обеспечить полную совместимость не удастся как минимум потому, что порты TNKernel под разные платформы уже несовместимы между собой: по-разному выделяется память под системные задачи, по-разному система стартует, по-разному задачи создаются. Все отличия API перечислены на страничке Differences from TNKernel API.
Более того, в «официальном» TNKernel под Cortex есть архитектурные особенности, сохранять совместимость с которыми нет никакого желания:
RTOS для PIC32, пожалуй, поменьше, чем для Cortex, но хватает. API TNKernel не то чтобы уж необычный, но, тем не менее, перенести проект с TNKernel на TNeo — задача тривиальная, в то время как перенести с TNKernel на FreeRTOS — посложнее. Но ничего невозможного, конечно, нет.
Ну и насчет полезности обществу — простите, если, написав TNeo, я не был достаточно полезным для вас. Я, кстати, думал про блог «я пиарюсь», но решил все-таки написать сюда, т.к. статья, как мне кажется, содержит достаточное количество информации, которая может быть интересна даже тем, кому ни с TNeo, ни с FreeRTOS работать в жизни не придется.
Более того, в «официальном» TNKernel под Cortex есть архитектурные особенности, сохранять совместимость с которыми нет никакого желания:
- Там есть Timer Task, который не привносит ничего, кроме оверхеда по производительности и памяти. Подробнее тут, тут.
- Память для системных вещей (стек для Idle task, Timer task) выделяется статически на этапе компиляции ядра, т.е. нет возможности собрать TNKernel как отдельную библиотеку и просто подключать ее к приложению: надо обязательно собирать TNKernel в составе приложения
- Поведение макроса MAKE_ALIG не соответствует даже официальной документации. Подробности тут
- Прочее, изложенное на Differences from TNKernel API
RTOS для PIC32, пожалуй, поменьше, чем для Cortex, но хватает. API TNKernel не то чтобы уж необычный, но, тем не менее, перенести проект с TNKernel на TNeo — задача тривиальная, в то время как перенести с TNKernel на FreeRTOS — посложнее. Но ничего невозможного, конечно, нет.
Ну и насчет полезности обществу — простите, если, написав TNeo, я не был достаточно полезным для вас. Я, кстати, думал про блог «я пиарюсь», но решил все-таки написать сюда, т.к. статья, как мне кажется, содержит достаточное количество информации, которая может быть интересна даже тем, кому ни с TNeo, ни с FreeRTOS работать в жизни не придется.
Это точно. Если вы уж меня — Sharepoint-разработчика, далекого от системного программирования настолько, насколько вообще разработчик может, смогли так заинтересовать (я вообще интересуюсь high performance, но статья это нечто), то что уж говорить про людей сколько-нибудь в теме. Так что никаких «Я пиарюсь», всё правильно. Отличная техническая статья для хабры, так и должно быть.
Как Таненбаума перечитал
Насчет связных списков в структуре дескрипторов потоков — а не быстрее ли будет использовать циклический буфер и массив индексов дескрипторов в буфере? Адресная арифметика же в МК обычно совсем неразвитая, кроме того, ссылки на предка и потомка занимают больше, чем сам дескриптор. Итерация простым сложением вместе с каким-нибудь битом отсутствия дескриптора в массиве по данному индексу в переводе на ассемблер имхо видится гораздо компактнее и быстрее, чем реализация двусвязного списка.
По-моему, в контроллерах, на которых вообще имеет смысл использовать вытесняющую РТОС, все в порядке с адресной арифметикой. Например, на том же PIC32 (т.е. MIPS), имея в регистре адрес, загрузить слово по данному адресу с 16-битным знаковым смещением — одна инструкция (и один такт). На Cortex-M — тоже. Это в простых 8-битниках, конечно, все плохо с подобными вещами, но там и вообще вытесняющей РТОС делать нечего.
Что именно вы предлагаете, я так и не понял. Насколько понял — должен быть какой-то отдельный буфер, который будет заранее рассчитан на определенное количество задач. Уже это мне не нравится — гораздо лучше иметь просто связанный список, в который можно динамически добавлять/убирать сколько угодно дескрипторов.
Что именно вы предлагаете, я так и не понял. Насколько понял — должен быть какой-то отдельный буфер, который будет заранее рассчитан на определенное количество задач. Уже это мне не нравится — гораздо лучше иметь просто связанный список, в который можно динамически добавлять/убирать сколько угодно дескрипторов.
Я исходил из того, что в закрытых системах создавать потоки в рантайме практически всегда лишено смысла, так как конфигурация железа и реализуемый устройством функционал задан жестко — соответственно, еще в дизайн-тайме можно определить потоковую архитектуру системы — кто за что отвечает. Создание же потоков в рантайме может понадобиться, например, в plug-n-play конфигурациях, когда устройство обнаруживает у себя, скажем N активных UART-передатчиков, и для обслуживания каждого выделяет поток динамически. Но тогда возникает следующий вопрос — что с этим делать остальному коду — где брать *смысловое* значение того или иного потока, как им взаимодействовать с остальной частью системы, условно говоря — «на что хардкодиться?» Проблему можно (частично) решить метаданными, но они в эмбеде не в почете — так как требуют большого оверхеда на их трансляцию в бизнес-действия. Способ же, когда поток создается под какое-то однообразное действие, и по завершении убивается, тоже очень дорог — для этой цели проще и быстрее рестартить статически созданный поток.
Если это так, то динамический список можно заменить простым массивом дескрипторов известного в дизайн-тайме размера, а вместо перешивки указателей при упорядочивании задач к запуску использовать простой массив байт, содержащий индексы дескрипторов задач. Циклический индекс этого массива будет «указателем» на текущую выполняемую задачу, а индекс следующей к выполнению будет лежать в следующей (по модулю N) ячейке этого массива. Планировщик будет упорядочивать лишь этот вспомогательный массив, ставя, например, -1 в случае, если передачу кванта некоторой задаче нужно пропустить (по причине wait или freeze)
Если это так, то динамический список можно заменить простым массивом дескрипторов известного в дизайн-тайме размера, а вместо перешивки указателей при упорядочивании задач к запуску использовать простой массив байт, содержащий индексы дескрипторов задач. Циклический индекс этого массива будет «указателем» на текущую выполняемую задачу, а индекс следующей к выполнению будет лежать в следующей (по модулю N) ячейке этого массива. Планировщик будет упорядочивать лишь этот вспомогательный массив, ставя, например, -1 в случае, если передачу кванта некоторой задаче нужно пропустить (по причине wait или freeze)
Кстати, у ChibiOS в версии 3.0 (я, правда, пока экспериментировал только с 2.6.2 на STM32) заявлено разделение на автономные модули RTOS и HAL, причем RTOS для сложных построений можно использовать более богатую на фичи (ChibiOS/RT — список фич здесь) и минимальную (ChibiOS/NIL — список фич и сравнение с RT). NIL при этом не использует динамики вообще, легко работает на 8-битных ядрах, и весит всего порядка 1кБайт.
Мне тут у английской версии статьи оставил комментарий некто Алекс. Т.к. там — только по-английски, то я оттуда удалил, скопирую сюда, и отвечу.
Видел статью на хабре, но не зарегистрирован там… и тем не менее.
Такая реализация как у вас, довольно наивна. (комментирую статью на хабре)
у вас какие-то архитектурные недостатки видны.
ну например зачем спасать контекст треда если обрабатывается прерывание? если вы хотите переключить треды в результате обработки этого прерывания, это надо сделать позже.
треды должны быть изолированы и нельзя чтобы один тред останавливал другой. это в большинстве случаев сделать корректно нельзя. все что может сделать один тред по отношению к другому — запустить тред, послать сообщение в очередь. все. чтобы тред остановить надо посылать ему в очередь сообщение об остановке. поскольку корректно извне тред не остановишь в общем случае.
далее. надо изолировать треды и прерывания вообще. треды ничего не могут знать про прерывания, а прерывания не могут вызывать тредовые функции. обработчики прерываний лишь берут данные(или не берут ничего) по внешнему событию, и кладут их в очереди, кольцевые буферы, и сигналят неким способом о событии в “мир тредов”. такая штука надывается каналом(обычно кольцевой буфер). Кернел с разделенными мирами прерываниий и тредов запрещает прерывания всего в паре мест
при занесии данных в канал, и выборе из него. При переключении тредов и всех реализации всех функций из мира тредов, как то — локи мьютексов, всякие слипы и проч. вплоть до переключения тредов — не запрещаются прерывания вообще. тогда система не теряет событий. Наивная же реализация, когда прерывания везде запрещены-разрешены приводит к тому что на частых событиях происходит потеря данных.
Вообще рилтайм эт оне вполне — немедля запустить тред обработки ивента с железа, а немедля забрать у железа данные и положить в буфер для обработки, — это как минимум.
таймеры у вас какие-от странные — там просто сортированная очередь обьектов(двусвязный список) — ближе к голове — наиболее ранний по срабатыванию… а у вас там какой-то наворот, даже не стал разбираться.
таймеры надо делать — жесткие и мягкие. жесткие могут работать прямо из контекста таймерного прерывания, а мягкие — запускаются текущим тредом, например при ближайшем переключении тредов. жесткие для жесткого рантайма, мягкие — для каких-то не сильно рантаймовых действия, например светодиодом помигать и так далее.
обработку прерываний можно разбить на два этапа — isr и dsr. dsr — просто активируемые из isr хуки постобрабтоки данных из прерывания, работающие в контексте текущего треда или собственном стеке, например(поскольку в isr вообще не видят тредов и не знают что это такое(в системе строгого разделения прерываний и тредов))…
ну и так далее…
критические секции лучше не давать юзеру, любой слип или ожидание в них заблокируют систему. синхронизация делается мьютексом.
критическая секция это не запрет прерываний(это убийственно для рантаймовой системы), а запрет переключений тредов. запрет прерываний это вообще стоит особенной секцией оформлять.
как вы взаимную блокировку там обнаруживаете — непонятно, она может глубоко косвенной, через цепь тредов, когда они по кольцу захватили мьютексы и не отдают.
все опреации дложны быть с таймаутом, потому дедлоки там в принципе невозможны… дедлоки это у студентов в учебниках.
вообщем вот так.
Прежде всего, скажу следующее: существует два подхода к обработке прерываний в РТОС: «Unified» и «Segmented». (не знаю, есть ли устоявшиеся русские термины, так что пишу их на английском). Вот тут есть отличная статья про это: RTOS Interrupt Architectures.
Подход, о котором вы говорите, как о «правильном» (в противоположность моему, «наивному») — это как раз Segmented aproach, когда обработка прерываний разделена на два этапа. В ядре Linux эти два этапа называют top half и bottom half. Тогда, действительно, можно сделать так, что РТОС никогда не запрещает прерывания (как, например, AVIX-RT или Q-kernel).
Но написание приложения под эти два разных типа РТОС существенно отличается (под «Segmented» писать сложнее, подробности в статье по ссылке выше), и, поскольку мне нужна РТОС, максимально совместимая с TNKernel, то этот вариант я не особо рассматривал.
Я не сомневаюсь, что существуют приложения жесткого realtime, где запрещение прерываний недопустимо. В таких проектах, конечно, нужно использовать что-то вроде AVIX-RT. Но мне, честно говоря, несколько десятков тактов под запрещенными прерываниями никогда не мешали, и таких приложений, по-моему, большинство. Плюс к этому, «Segmented» добавляет оверхед к переключению задач. Процитирую заключение из статьи:
Можно было бы и закончить, но на некоторые вещи отвечу отдельно:
При обработке прерывания, TNeo сохраняет только «callee-saved» регистры, т.е. те, которые должна сохранять вызываемая функция, если эти регистры ей нужны. Если не сохранить их при обработке прерывания, то данные в них будут потеряны. На MIPS TNeo сохраняет их самостоятельно, а, например, Cortex-M делает все за меня, там ядро вообще ничего не делает при обработке прерывания.
Тут я с вами соглашусь, и даже вот дам вам ссылку на мой собственный пост на форуме Microchip, где я выражаю ту же идею. Но, первое: как мне там ответил товарищ andersm, эта функциональность довольно стандартна. И второе: мне эта функциональность не мешает, хоть я ее никогда и не использую, так что, чтобы не ломать без надобности совместимость с TNKernel, эти сервисы были оставлены.
Ну так, data queue именно для этого и нужны, да.
Ну то, что вы не стали разбираться и написали об этом, по-моему, вам чести не делает. А реализация таймеров, тем временем, описана даже в статье выше: основная идея позаимствована из ядра Linux, и она более эффективна, чем «просто сортированная очередь».
В TNeo есть жесткие таймеры. А мягких (пока) нет, т.к. лишняя задача в контексте вытесняющей ОС — это, как минимум, два переключения контекста каждый раз, и еще, как минимум, несколько сотен байт для ее стека. RAM в моих проектах — очень дорогой ресурс. Может, в будущем добавлю опционально, но пока мне ни разу не было нужно. Если нужно по таймеру разбудить какую-нибудь задачу, то можно из «жесткого» таймерного коллбэка семафором посигналить, или сообщение в очередь отправить.
Насчет этого ответил в самом начале комментария.
После прочтения этого, стало ясно, что мы с вами, возможно, совсем о разных классах систем говорим. Смартфон на Андроиде — это ведь эмбеддинг, и тупой экранчик в заряднике, на камне с 1 кБ RAM — тоже эмбеддинг.
Что значит «лучше не давать юзеру»? В эмбеддинге, РТОС и код приложения очень часто выполняется с одинаковым приоритетом — приоритетом ядра. Так что нет никакой защиты памяти, ничего такого. Это не тот класс систем. Можно, конечно, и на тостер Linux ставить, но это слишком дорого. Так что тут юзер имеет все возможности выстрелить в ногу, и никто ему не поможет.
Синхронизация делается мютексом — отлично. Только не всегда разумно: если нам нужно произвести очень короткое действие (пусть, например, банально поработать с GPIO), то мютекс — это просто колоссальный оверхед, в десятки раз превышающий длительность полезной работы. Мютексом можно ограничивать только сравнительно длительные операции (работа с внешней флешкой, например).
Именно так, через цепь тредов и проверяется, что непонятного. Да, это занимает время, и именно поэтому я это использую только в отладочной сборке. Осознание того, что у меня там лишние пару десятков тактов будут потрачены на это, меня не пугает — скорости хватает. Будет не хватать — выключу эту опцию в сборке.
«дедлоки это у студентов в учебниках» — да уж, рубанули с плеча. Дедлок возникает, если блокировать несколько ресурсов в разной последовательности. В условиях ограниченных ресурсов микроконтроллеров, часто бывает более разумно просто спроектировать систему так, чтобы задачи там блокировали ресурсы только в одной и той же последовательности, вместо того, чтобы обрабатывать ситуацию, когда мы не можем захватить очередной мютекс, поэтому нужно освобождать захваченный в данный момент, и т.д.
Если это правило нарушается, то может возникнуть дедлок, и ядро мне об этом тут же скажет. На сегодняшний день, эта возможность помогла мне ровно один раз (помогла быстро найти ошибку) — что ж, уже неплохо.
Если почувствуете необходимость ответить — пишите на почту (у меня на сайте есть адрес), я скопирую сюда.
Подход, о котором вы говорите, как о «правильном» (в противоположность моему, «наивному») — это как раз Segmented aproach, когда обработка прерываний разделена на два этапа. В ядре Linux эти два этапа называют top half и bottom half. Тогда, действительно, можно сделать так, что РТОС никогда не запрещает прерывания (как, например, AVIX-RT или Q-kernel).
Но написание приложения под эти два разных типа РТОС существенно отличается (под «Segmented» писать сложнее, подробности в статье по ссылке выше), и, поскольку мне нужна РТОС, максимально совместимая с TNKernel, то этот вариант я не особо рассматривал.
Я не сомневаюсь, что существуют приложения жесткого realtime, где запрещение прерываний недопустимо. В таких проектах, конечно, нужно использовать что-то вроде AVIX-RT. Но мне, честно говоря, несколько десятков тактов под запрещенными прерываниями никогда не мешали, и таких приложений, по-моему, большинство. Плюс к этому, «Segmented» добавляет оверхед к переключению задач. Процитирую заключение из статьи:
While both Segmented and Unified Interrupt Architecture RTOSes enable deterministic real-time management of an embedded system, there are significant differences between them with regard to the efficiency and simplicity of the resulting system. Segmented RTOSes can accurately claim that they never disable interrupts within system services. However, in order to achieve this, they instead must delay application threads, introducing a possibly worse consequence. The segmented approach also adds measurable overhead to the context switch process, and complicates application development. In the end, a unified interrupt architecture RTOS demonstrates clear advantages for use in real-time embedded systems development.
Можно было бы и закончить, но на некоторые вещи отвечу отдельно:
ну например зачем спасать контекст треда если обрабатывается прерывание? если вы хотите переключить треды в результате обработки этого прерывания, это надо сделать позже.
При обработке прерывания, TNeo сохраняет только «callee-saved» регистры, т.е. те, которые должна сохранять вызываемая функция, если эти регистры ей нужны. Если не сохранить их при обработке прерывания, то данные в них будут потеряны. На MIPS TNeo сохраняет их самостоятельно, а, например, Cortex-M делает все за меня, там ядро вообще ничего не делает при обработке прерывания.
треды должны быть изолированы и нельзя чтобы один тред останавливал другой. это в большинстве случаев сделать корректно нельзя. все что может сделать один тред по отношению к другому — запустить тред, послать сообщение в очередь. все. чтобы тред остановить надо посылать ему в очередь сообщение об остановке. поскольку корректно извне тред не остановишь в общем случае.
Тут я с вами соглашусь, и даже вот дам вам ссылку на мой собственный пост на форуме Microchip, где я выражаю ту же идею. Но, первое: как мне там ответил товарищ andersm, эта функциональность довольно стандартна. И второе: мне эта функциональность не мешает, хоть я ее никогда и не использую, так что, чтобы не ломать без надобности совместимость с TNKernel, эти сервисы были оставлены.
надо изолировать треды и прерывания вообще. треды ничего не могут знать про прерывания, а прерывания не могут вызывать тредовые функции. обработчики прерываний лишь берут данные(или не берут ничего) по внешнему событию, и кладут их в очереди, кольцевые буферы, и сигналят неким способом о событии в “мир тредов”. такая штука надывается каналом(обычно кольцевой буфер)
Ну так, data queue именно для этого и нужны, да.
таймеры у вас какие-от странные — там просто сортированная очередь обьектов(двусвязный список) — ближе к голове — наиболее ранний по срабатыванию… а у вас там какой-то наворот, даже не стал разбираться.
Ну то, что вы не стали разбираться и написали об этом, по-моему, вам чести не делает. А реализация таймеров, тем временем, описана даже в статье выше: основная идея позаимствована из ядра Linux, и она более эффективна, чем «просто сортированная очередь».
таймеры надо делать — жесткие и мягкие. жесткие могут работать прямо из контекста таймерного прерывания, а мягкие — запускаются текущим тредом, например при ближайшем переключении тредов. жесткие для жесткого рантайма, мягкие — для каких-то не сильно рантаймовых действия, например светодиодом помигать и так далее.
В TNeo есть жесткие таймеры. А мягких (пока) нет, т.к. лишняя задача в контексте вытесняющей ОС — это, как минимум, два переключения контекста каждый раз, и еще, как минимум, несколько сотен байт для ее стека. RAM в моих проектах — очень дорогой ресурс. Может, в будущем добавлю опционально, но пока мне ни разу не было нужно. Если нужно по таймеру разбудить какую-нибудь задачу, то можно из «жесткого» таймерного коллбэка семафором посигналить, или сообщение в очередь отправить.
обработку прерываний можно разбить на два этапа — isr и dsr…
Насчет этого ответил в самом начале комментария.
критические секции лучше не давать юзеру, любой слип или ожидание в них заблокируют систему. синхронизация делается мьютексом.
После прочтения этого, стало ясно, что мы с вами, возможно, совсем о разных классах систем говорим. Смартфон на Андроиде — это ведь эмбеддинг, и тупой экранчик в заряднике, на камне с 1 кБ RAM — тоже эмбеддинг.
Что значит «лучше не давать юзеру»? В эмбеддинге, РТОС и код приложения очень часто выполняется с одинаковым приоритетом — приоритетом ядра. Так что нет никакой защиты памяти, ничего такого. Это не тот класс систем. Можно, конечно, и на тостер Linux ставить, но это слишком дорого. Так что тут юзер имеет все возможности выстрелить в ногу, и никто ему не поможет.
Синхронизация делается мютексом — отлично. Только не всегда разумно: если нам нужно произвести очень короткое действие (пусть, например, банально поработать с GPIO), то мютекс — это просто колоссальный оверхед, в десятки раз превышающий длительность полезной работы. Мютексом можно ограничивать только сравнительно длительные операции (работа с внешней флешкой, например).
как вы взаимную блокировку там обнаруживаете — непонятно, она может глубоко косвенной, через цепь тредов, когда они по кольцу захватили мьютексы и не отдают.
Именно так, через цепь тредов и проверяется, что непонятного. Да, это занимает время, и именно поэтому я это использую только в отладочной сборке. Осознание того, что у меня там лишние пару десятков тактов будут потрачены на это, меня не пугает — скорости хватает. Будет не хватать — выключу эту опцию в сборке.
все опреации дложны быть с таймаутом, потому дедлоки там в принципе невозможны… дедлоки это у студентов в учебниках.
«дедлоки это у студентов в учебниках» — да уж, рубанули с плеча. Дедлок возникает, если блокировать несколько ресурсов в разной последовательности. В условиях ограниченных ресурсов микроконтроллеров, часто бывает более разумно просто спроектировать систему так, чтобы задачи там блокировали ресурсы только в одной и той же последовательности, вместо того, чтобы обрабатывать ситуацию, когда мы не можем захватить очередной мютекс, поэтому нужно освобождать захваченный в данный момент, и т.д.
Если это правило нарушается, то может возникнуть дедлок, и ядро мне об этом тут же скажет. На сегодняшний день, эта возможность помогла мне ровно один раз (помогла быстро найти ошибку) — что ж, уже неплохо.
Если почувствуете необходимость ответить — пишите на почту (у меня на сайте есть адрес), я скопирую сюда.
Продолжение:
Ваши доводы насчет таймеров звучат разумно, спасибо. И если включен динамический тик, используется именно такая реализация (потому что там уже и нет периодических тиков, чтобы в них что-то декрементить).
Через год, я уже не очень хорошо помню, почему решил сделать статические таймеры именно так. Возможно, я был просто под впечатлением от реализации в Linux, и хотел сделать похожим образом. Может, переделаю в будущем.
посмотрел по вашим таймерам. вот вопрос — зачем вообще модифицировать что-то в списке таймеров каждый тик???
делается так.
на системном тике сидит isr который просто инкрементит счетчик системных тиков. при старте он равен 0.
есть общий сортированный по времени срабатывания двусвязный список таймеров.
в начале он пуст.
при запуске таймера высчитывается его время срабатывания = текущее значение счетчика тиков+интервал срабатывания заданный таймеру. то есть вы храните не сам интервал(который декрементите там) а сразу значение счетчике систиков когда сработать(вам больше никакие декременты не нужны).
обьект с посчитанным временем срабатывания заносится в сортированный список. те кто раньше — те в голове.
isr тамера не просто икрементит счетчик тиков, но после этого смотрит — не больше или равен текущий счетчик, тому значению, при котором должен сработать первый в списке(самый ранний таймер). если текущий счетчик больше — первый таймер извлекается и запускается его хук(или что там у вас). если текущий счетчик меньше времени у первого таймера, то ни один таймер еще не созрел. ибо далее в списке — более поздние.
псевдокод иср
на самом деле если таймеров разумное количесвто — не тыщщи, таймерная иср только проверит первый в списке таймер на готовность и выйдет.void timerISR(){ ++__SysCLocks; //это типа системное время в тиках while(!__TImers.empty() && (__TImers.first()._clocks<__SysClocks)){ //есть созревший таймер TImer *lt = __Timers.removeFirst(); // lt->timerAction(); //тут зависит от реализации как реализуется периодичский таймер. //сам ли он себя обратно вставляет в список таймеров, или это делает данная функция //а этом псевдокоде таймер однократный //заметим, что посольку тут while - будут в цикле извлекаьтся все таймеры что созрели к данному тику. } }
к чему огород со специальными списками — непонятно.
остается только в момент старта таймера его поставить в нужное место в списке таймеров(сортировка по времени срабатывания в тиках ).
псевдокод startTimer(Timer* ft, int fticks){ ft->_clocks=__SysClocks+fticks; //вычисляем таймеру абс.время его сраатывания в тиках Timers.addSorted(ft); }
для оптимизации можно организовать несколько списков таймеров. например для которых квант времени 1 мс, 8 мс, 64 мс… если есть опасение что таймеров будет много… но в релаьном устройстве их, активных ну не более 10. в моей практике всегда одного списка хватало в силу небольшого количества запущенных таймеров.
Ваши доводы насчет таймеров звучат разумно, спасибо. И если включен динамический тик, используется именно такая реализация (потому что там уже и нет периодических тиков, чтобы в них что-то декрементить).
Через год, я уже не очень хорошо помню, почему решил сделать статические таймеры именно так. Возможно, я был просто под впечатлением от реализации в Linux, и хотел сделать похожим образом. Может, переделаю в будущем.
TNeo сохраняет только «callee-saved» регистры, т.е. те, которые должна сохранять вызываемая функция, если эти регистры ей нужны
Сорри, конечно, имелось в виду, наоборот: сохраняются только «caller-saved» регистры, т.е. те, которые должна сохранять вызывающая функция. А о «callee-saved» регистрах как раз позаботится сам ISR.
Монументально, полезно. Если когда-нибудь дорасту до 16битных хотя бы MCU, обязательно возьму. По API и доке — реально ТЧДП, в отличие от FreeRTOS и некоторых других систем, что я тыкал палочкой.
Присоединюсь к общим восторгам по поводу проделанной работы. Особенно радует перенос ядра на Cortex-M3, поскольку сейчас как раз осваиваю эту платформу. И в связи с этим небольшой вопрос — использовали ли вы при переносе кода ядра некоторые приятные особенности ядра Cortex, в частности bit banding для атомарных операций над битовыми полями (для тех же мьютексов, например), или атомарность реализована стандартной оберткой disable_interrupt();… enable_interrupt();?
использовать в кортексах disable_interrupt() и enable_interrupt() не очень хорошая практика: после запрещения прерываний шанс возникновения прерывания всё равно остаётся, от двух и более инструкций (по длинне конвеера).
Тем более часто enable_interrupt и disable_interrupt делают инлайновыми.
С этим делом надо очень осторожно быть читая все даташиты а аппноты арм консорциума.
например
infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dai0321a/BIHGJICF.html
Тем более часто enable_interrupt и disable_interrupt делают инлайновыми.
С этим делом надо очень осторожно быть читая все даташиты а аппноты арм консорциума.
например
infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dai0321a/BIHGJICF.html
Находятся даже люди, которые не используют никаких ОС в микроконтроллерах, но я не считаю это хорошей практикой: если железо позволяет мне использовать ОС, я ее использую.
Я например не использую ОС вообще.
Так получилось что например:
В шлюзе очень критичен реалтайм, и места в флеша и озу там оставалось мало а запас для развития и доработок с костылями любой себя уважающий инженер обязан оставить. Хоть там и 192к ОЗУ и 1М флеша. но очень многое уже использовано. Да и реалтайм свёл почти все задачи в одно прерывание с последовательным вызовом функций обработки FSK, DTMF, выдачи звука, приёма звука, фильтрации, анти-эхо (занимает 90% всего времени).
В часиках требования суровее, 4к ОЗУ и 16к флеша, 8Мгц, реализован плавный интерфейс с многозадачностью окон (само так вышло), файловая система, монитор загруженности проца с отладчиком (показ событий), полная самодиагностика каждого вывода с измерением его физ параметров и проверкой функционирования. И вся эта мишура опять без ОС, т.к. например в Вашем примере на одни только стеки ОС занимают больше 4к. И в этом случае я не использовал даже прерывания. И умудрился опять таки оставить инженерный запас как по частоте так и по занятому озу с флешем. Плюс добавил многоязычную поддержку и разные шрифты и кодировки (поэтому подробностей не будет ещё долго по часам и не просите). В купе всех этих факторов ОС тут ну никак не впихнуть.
А на простых проектах так же умудряюсь делать просто даже кодя в лоб. Тут тоже ОС — уже rocket science, и другим наверное тоже особо не нужна, например — скетчи в ардуино (надеюсь не отстал от жизни и они туда ос не добавили).
И в итоге потребности в ОС вообще не было, и даже мысли не возникало.
Но всё равно: работа просто монстроидальная, респект и уважуха! большое спасибо, добавил в избранное!
Сама по себе ОС не нужна, но при наличии ресурсов ОС позволяет не изобретать велосипеды в каждой новой разработке, а начинать разработку уже с некоторой форой. Не выдумывать каждый раз как совместить две или три задачи которые выполняться должны одновременно долго продумывая как это реализовать на однозадачном камне. Она экономит время, за счет аппаратных ресурсов.
То что вы делаете, относится скорей всего к категории искусства которое не каждый сможет увидеть и оценить. Потребителю едва ли будет дело до красоты внутреннего инженерного решения, скрытого от глаз.
А так-то да, сам страдаю такой фигнёй.
То что вы делаете, относится скорей всего к категории искусства которое не каждый сможет увидеть и оценить. Потребителю едва ли будет дело до красоты внутреннего инженерного решения, скрытого от глаз.
А так-то да, сам страдаю такой фигнёй.
Спустя довольно много времени после публикации во время разговора с коллегами вспомнил про Вашу статью.
И пока бегло перечитывал — сам заинтересовался моментом:
Можете объяснить этот момент? Я не улавливаю, как таймаут N приводит к тому, что добавление происходит в текущий tick-список.
И пока бегло перечитывал — сам заинтересовался моментом:
Внимательный читатель может задаться вопросом: почему мы используем только (N — 1) tick-списков, когда у нас вообще-то есть N списков? Это из-за того, что мы как раз хотим иметь возможность модифицировать таймеры из таймерных коллбэков. Если бы мы использовали N списков, и пользователь добавляет таймер с таймаутом, равным N, то новый таймер будет добавлен именно в тот список, который мы проходим в данный момент. Этого делать нельзя.
Если же мы используем (N — 1) списков, то мы гарантируем, что новый таймер не может быть добавлен в tick-список, который мы проходим в данный момент (кстати, таймер может быть убран из этого списка, но это не создаст проблем).
Можете объяснить этот момент? Я не улавливаю, как таймаут N приводит к тому, что добавление происходит в текущий tick-список.
Sign up to leave a comment.
Как я, в итоге, написал новую RTOS, протестированную и стабильную