
Сегодня мы продолжаем цикл статей о сборщиках мусора, поставляемых с виртуальной машиной Oracle Java HotSpot VM. Мы уже изучили немного теории и рассмотрели, каким образом с кучей расправляются два базовых сборщика — Serial GC и Parallel GC. А в этой статье речь пойдет о сборщиках CMS GC и G1 GC, первостепенной задачей которых является минимизация пауз при наведении порядка в памяти приложений, оперирующих средними и большими объемами данных, то есть по большей части в памяти серверных приложений.
Два этих сборщика объединяют общим названием «mostly concurrent collectors», то есть «по большей части конкурентные сборщики». Это связано с тем, что часть своей работы они выполняют параллельно с основными потоками приложения, то есть в какие-то моменты конкурируют с ними за ресурсы процессора. Конечно, это не проходит бесследно, и в итоге они разменивают улучшение в части пауз на ухудшение в части пропускной способности. Хотя делают это по-разному. Давайте посмотрим, как.
CMS GC
Сборщик CMS (расшифровывается как Concurrent Mark Sweep) появился в HotSpot VM в одно время с Parallel GC в качестве его альтернативы для использования в приложениях, имеющих доступ к нескольким ядрам процессора и чувствительных к паузам STW. В то время существовала еще одна альтернатива — Incremental GC, но он не прошел естественный отбор за неимением явных преимуществ. А CMS выжил. И хотя пик его популярности, видимо, уже прошел, на его внутреннее устройство интересно будет взглянуть, так как некоторые заложенные в него идеи перекочевали в более современный G1 GC.
Использование CMS GC включается опцией
-XX:+UseConcMarkSweepGC.Принципы работы
Мы уже встречали слова Mark и Sweep при рассмотрении последовательного и параллельного сборщиков (если вы не встречали, то сейчас как раз самое время это сделать). Они обозначали два шага в процессе сборки мусора в старшем поколении: пометку выживших объектов и удаление мертвых объектов. Сборщик CMS получил свое название благодаря тому, что выполняет указанные шаги параллельно с работой основной программы.
При этом CMS GC использует ту же самую организацию памяти, что и уже рассмотренные Serial / Parallel GC: регионы Eden + Survivor 0 + Survivor 1 + Tenured и такие же принципы малой сборки мусора. Отличия начинаются только тогда, когда дело доходит до полной сборки. В случае CMS ее называют старшей (major) сборкой, а не полной, так как она не затрагивает объекты младшего поколения. В результате, малая и старшая сборки здесь всегда разделены. Одним из побочных эффектов такого разделения является то, что все объекты младшего поколения (даже потенциально мертвые) могут играть роль корней при определении статуса объектов в старшем поколении.
Важным отличием сборщика CMS от рассмотренных ранее является также то, что он не дожидается заполнения Tenured для того, чтобы начать старшую сборку. Вместо этого он трудится в фоновом режиме постоянно, пытаясь поддерживать Tenured в компактном состоянии.
Давайте рассмотрим, что из себя представляет старшая сборка мусора при использовании CMS GC.
Начинается она с остановки основных потоков приложения и пометки всех объектов, напрямую доступных из корней. После этого приложение возобновляет свою работу, а сборщик параллельно с ним производит поиск всех живых объектов, доступных по ссылкам из тех самых помеченных корневых объектов (эту часть он делает в одном или в нескольких потоках).
Естественно, за время такого поиска ситуация в куче может поменяться, и не вся информация, собранная во время поиска живых объектов, оказывается актуальной. Поэтому сборщик еще раз приостанавливает работу приложения и просматривает кучу для поиска живых объектов, ускользнувших от него за время первого прохода. При этом допускается, что в живые будут записаны объекты, которые на время окончания составления списка таковыми уже не являются. Эти объекты называются плавающим мусором (floating garbage), они будут удалены в процессе следующей сборки.
После того, как живые объекты помечены, работа основных потоков приложения возобновляется, а сборщик производит очистку памяти от мертвых объектов в нескольких параллельных потоках. При этом следует иметь в виду, что после очистки не производится упаковка объектов в старшем поколении, так как делать это при работающем приложении весьма затруднительно.
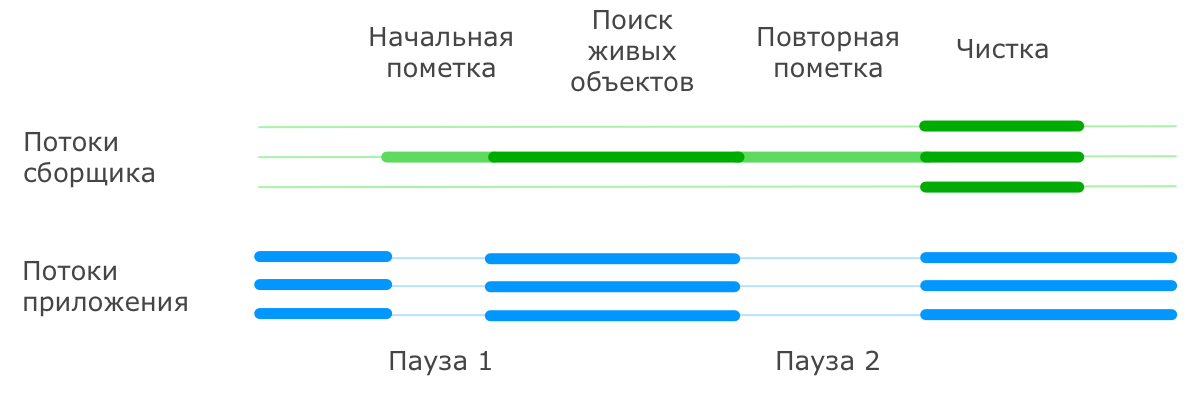
Сборщик CMS достаточно интеллектуальный. Например, он старается разносить во времени малые и старшие сборки мусора, чтобы они совместно не создавали продолжительных пауз в работе приложения (дополнительные подробности об этом разнесении в комментариях). Для этого он ведет статистику по прошедшим сборкам и исходя из нее планирует последующие.
Отдельно следует рассмотреть ситуацию, когда сборщик не успевает очистить Tenured до того момента, как память полностью заканчивается. В этом случае работа приложения останавливается, и вся сборка производится в последовательном режиме. Такая ситуация называется сбоем конкурентного режима (concurrent mode failure). Сборщик сообщает нам об этих сбоях при включенных опциях
-verbose:gc или -Xloggc:filename.У CMS есть один интересный режим работы, называемый Incremental Mode, или i-cms, который заставляет его временно останавливаться при выполнении работ параллельно с основным приложением, чтобы на короткие периоды высвобождать ресурсы процессора (что-то вроде АБС у автомобиля). Это может быть полезным на машинах с малым количеством ядер. Но данный режим уже помечен как не рекомендуемый к применению и может быть отключен в будущих релизах, поэтому подробно его разбирать не будем.
Ситуации STW
Из всего сказанного выше следует, что при обычной сборке мусора у CMS GC существуют следующие ситуации, приводящие к STW:
- Малая сборка мусора. Эта пауза ничем не отличается от аналогичной паузы в Parallel GC.
- Начальная фаза поиска живых объектов при старшей сборке (так называемая initial mark pause). Эта пауза обычно очень короткая.
- Фаза дополнения набора живых объектов при старшей сборке (известная также как remark pause). Она обычно длиннее начальной фазы поиска.
В случае же возникновения сбоя конкурентного режима пауза может затянуться на достаточно длительное время.
Настройка
Так как подходы к организации памяти у CMS аналогичны используемым в Serial / Parallel GC, для него применимы те же опции определения размеров регионов кучи, а также опции автоматической подстройки под требуемые параметры производительности.
Обычно CMS, основываясь на собираемой статистике о поведении приложения, сам определяет, когда ему выполнять старшую сборку, но у него также есть порог наполненности региона Tenured, при достижении которого должна обязательно быть инициирована старшая сборка. Этот порог можно задать с помощью опции
-XX:CMSInitiatingOccupancyFraction=? Достоинства и недостатки
Достоинством данного сборщика по сравнению с рассмотренными ранее Serial / Parallel GC является его ориентированность на минимизацию времен простоя, что является критическим фактором для многих приложений. Но для выполнения этой задачи приходится жертвовать ресурсами процессора и зачастую общей пропускной способностью.
Вспомним еще, что данный сборщик не уплотняет объекты в старшем поколении, что приводит к фрагментации Tenured. Этот факт в совокупности с наличием плавающего мусора приводит к необходимости выделять приложению (конкретно — старшему поколению) больше памяти, чем потребовалось бы для других сборщиков (Oracle советует на 20% больше).
Ну и долгие паузы при потенциально возможных сбоях конкурентного режима могут стать неприятным сюрпризом. Хотя они не частые, и при наличии достаточного объема памяти CMS’у удается их полностью избегать.
Тем не менее, такой сборщик может подойти приложениям, использующим большой объем долгоживущих данных. В этом случае некоторые его недостатки нивелируются. Но в любом случае, не стоит принимать решение о его использовании пока вы не познакомились с еще одним сборщиком в обойме Java HotSpot VM.
G1 GC
Вот мы и добрались до последнего и наверняка самого интересного для многих сборщика мусора — G1 (что является сокращением от Garbage First). Интересен он прежде всего тем, что не является явным продолжением линейки Serial / Parallel / CMS, добавляющим параллельность еще в какую-нибудь фазу сборки мусора, а использует уже существенно отличающийся подход к задаче очистки памяти.
G1 — самый молодой в составе сборщиков мусора виртуальной машины HotSpot. Он изначально позиционировался как сборщик для приложений с большими кучами (от 4 ГБ и выше), для которых важно сохранять время отклика небольшим и предсказуемым, пусть даже за счет уменьшения пропускной способности. На этом поле он конкурировал с CMS GC, хотя изначально и не так успешно, как хотелось бы. Но постепенно он исправлялся, улучшался, стабилизировался и, наконец, достиг такого уровня, что Oracle говорит о нем как о долгосрочной замене CMS, а в Open JDK даже серьезно рассматривают его на роль сборщика по умолчанию для серверных конфигураций в 9-й версии.
Это все явно стоит того, чтобы разобраться с его устройством. Не будем же откладывать.
G1 включается опцией Java
-XX:+UseG1GC Принципы работы
Первое, что бросается в глаза при рассмотрении G1 — это изменение подхода к организации кучи. Здесь память разбивается на множество регионов одинакового размера. Размер этих регионов зависит от общего размера кучи и по умолчанию выбирается так, чтобы их было не больше 2048, обычно получается от 1 до 32 МБ. Исключение составляют только так называемые громадные (humongous) регионы, которые создаются объединением обычных регионов для размещения очень больших объектов.
Разделение регионов на Eden, Survivor и Tenured в данном случае логическое, регионы одного поколения не обязаны идти подряд и даже могут менять свою принадлежность к тому или иному поколению. Пример разделения кучи на регионы может выглядеть следующим образом (количество регионов сильно приуменьшено):

Малые сборки выполняются периодически для очистки младшего поколения и переноса объектов в регионы Survivor, либо их повышения до старшего поколения с переносом в Tenured. Над переносом объектов трудятся несколько потоков, и на время этого процесса работа основного приложения останавливается. Это уже знакомый нам подход из рассмотренных ранее сборщиков, но отличие состоит в том, что очистка выполняется не на всем поколении, а только на части регионов, которые сборщик сможет очистить не превышая желаемого времени. При этом он выбирает для очистки те регионы, в которых, по его мнению, скопилось наибольшее количество мусора и очистка которых принесет наибольший результат. Отсюда как раз название Garbage First — мусор в первую очередь.
А с полной сборкой (точнее, здесь она называется смешанной (mixed)) все немного хитроумнее, чем в рассмотренных ранее сборщиках. В G1 существует процесс, называемый циклом пометки (marking cycle), который работает параллельно с основным приложением и составляет список живых объектов. За исключением последнего пункта, этот процесс выглядит уже знакомо для нас:
- Initial mark. Пометка корней (с остановкой основного приложения) с использованием информации, полученной из малых сборок.
- Concurrent marking. Пометка всех живых объектов в куче в нескольких потоках, параллельно с работой основного приложения.
- Remark. Дополнительный поиск не учтенных ранее живых объектов (с остановкой основного приложения).
- Cleanup. Очистка вспомогательных структур учета ссылок на объекты и поиск пустых регионов, которые уже можно использовать для размещения новых объектов. Первая часть этого шага выполняется при остановленном основном приложении.
Следует иметь в виду, что для получения списка живых объектов G1 использует алгоритм Snapshot-At-The-Beginning (SATB), то есть в список живых попадают все объекты, которые были таковыми на момент начала работы алгоритма, плюс все объекты, созданные за время его выполнения. Это, в частности, означает, что G1 допускает наличие плавающего мусора, с которым мы познакомились при рассмотрении сборщика CMS.
После окончания цикла пометки G1 переключается на выполнение смешанных сборок. Это значит, что при каждой сборке к набору регионов младшего поколения, подлежащих очистке, добавляется некоторое количество регионов старшего поколения. Количество таких сборок и количество очищаемых регионов старшего поколения выбирается исходя из имеющейся у сборщика статистики о предыдущих сборках таким образом, чтобы не выходить за требуемое время сборки. Как только сборщик очистил достаточно памяти, он переключается обратно в режим малых сборок.
Очередной цикл пометки и, как следствие, очередные смешанные сборки будут запущены тогда, когда заполненность кучи превысит определенный порог.
Смешанная сборка мусора в приведенном выше примере кучи может пройти вот так:
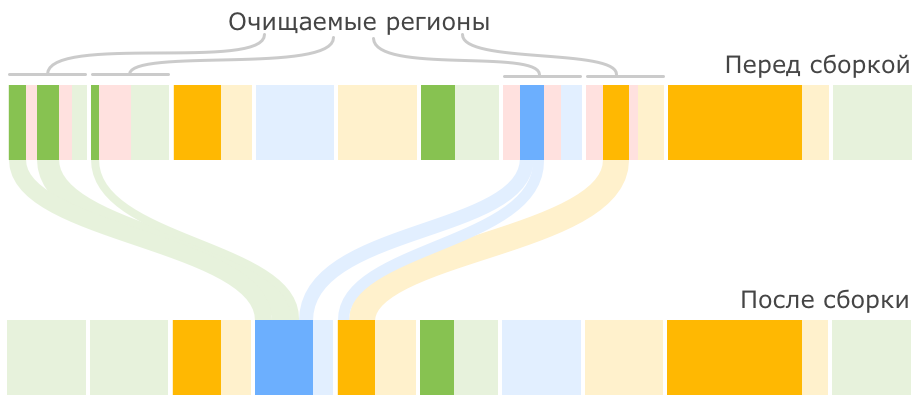
Может оказаться так, что в процессе очистки памяти в куче не остается свободных регионов, в которые можно было бы копировать выжившие объекты. Это приводит к возникновению ситуации allocation (evacuation) failure, подобие которой мы видели в CMS. В таком случае сборщик выполняет полную сборку мусора по всей куче при остановленных основных потоках приложения.
Опираясь на уже упомянутую статистику о предыдущих сборках, G1 может менять количество регионов, закрепленных за определенным поколением, для оптимизации будущих сборок.
Гиганты
В начале рассказа о G1 я упомянул о существовании громадных регионов, в которых хранятся так называемые громадные объекты (humongous objects). С точки зрения JVM любой объект размером больше половины региона считается громадным и обрабатывается специальным образом:
- Он никогда не перемещается между регионами.
- Он может удаляться в рамках цикла пометки или полной сборки мусора.
- В регион, занятый громадным объектом, больше никого не подселяют, даже если в нем остается свободное место.
Вообще, эти пункты иногда имеют далеко идущие последствия. Объекты большого размера, особенно короткоживущие, могут доставлять много неудобств всем типам сборщиков, так как не удаляются при малых сборках, а занимают драгоценное пространство в регионах старшего поколения (помните объекты-акселераты, обсуждавшиеся в предыдущей главе?) Но G1 оказывается более уязвимым к их негативному влиянию в силу того, что для него даже объект в несколько мегабайт (а в некоторых случаях и 500 КБ) уже является громадным. В комментарии к предыдущей статье как раз приводится пример такой проблемы у Solr.
В продолжении данного цикла статей мы посмотрим, как с этим можно бороться.
Ситуации STW
Если резюмировать, то у G1 мы получаем STW в следующих случаях:
- Процессы переноса объектов между поколениями. Для минимизации таких пауз G1 использует несколько потоков.
- Короткая фаза начальной пометки корней в рамках цикла пометки.
- Более длинная пауза в конце фазы remark и в начале фазы cleanup цикла пометки.
Настройка
Так как основной целью сборщика G1 является минимизация пауз в работе основного приложения, то и главной опцией при его настройке можно считать уже встречавшуюся нам
-XX:MaxGCPauseMillis=? Опции
-XX:ParallelGCThreads=? -XX:ConcGCThreads=? Если вас не устраивает автоматический выбор размера региона, вы можете задать его вручную с помощью опции
-XX:G1HeapRegionSize=? -XX:G1HeapRegionSize=16m При желании можно изменить порог заполненности кучи, при достижении которого инициируется выполнение цикла пометок и переход в режим смешанных сборок. Это делается опцией
-XX:InitiatingHeapOccupancyPercent=? Если же вы решите залезть в дебри настроек G1 по-глубже, то можете включить дополнительные функции опциями
-XX:+UnlockExperimentalVMOptions -XX:+AggressiveOpts Достоинства и недостатки
 В целом считается, что сборщик G1 более аккуратно предсказывает размеры пауз, чем CMS, и лучше распределяет сборки во времени, чтобы не допустить длительных остановок приложения, особенно при больших размерах кучи. При этом он лишен и некоторых других недостатков CMS, например, он не фрагментирует память.
В целом считается, что сборщик G1 более аккуратно предсказывает размеры пауз, чем CMS, и лучше распределяет сборки во времени, чтобы не допустить длительных остановок приложения, особенно при больших размерах кучи. При этом он лишен и некоторых других недостатков CMS, например, он не фрагментирует память.Расплатой за достоинства G1 являются ресурсы процессора, которые он использует для выполнения достаточно большой части своей работы параллельно с основной программой. В результате страдает пропускная способность приложения. Целевым значением пропускной способности по умолчанию для G1 является 90%. Для Parallel GC, например, это значение равно 99%. Это, конечно, не значит, что пропускная способность с G1 всегда будет почти на 10% меньше, но данную особенность следует всегда иметь в виду.
Часть 4 — Сборщик ZGC →
Часть 5 — Сборщик Epsilon GC →
Часть 6 — Сборщик Shenandoah GC →
Ранее:
← Часть 2 — Сборщики Serial GC и Parallel GC
← Часть 1 — Введение
