В предыдущей части были описаны базовые операции и сопутствующие задачи при копировании сетевых словарей при помощи Node.js. В этой части описывается использование важного дополнительного инструмента для конвертирования веб-источников особого уровня сложности.
1. Чем сложнее структура веб-страниц словаря, тем больше оснований опереться на весь спектр возможностей, предоставляемый отточенным браузерным движком. JSDOM — довольно развитая библиотека, но даже она не сравнится с полным набором средств из Chromium.
2. Люди, занимающиеся созданием и конвертированием цифровых словарей, — в значительной мере гуманитарии, которых волей судьбы занесло в сферу IT. Иногда им комфортнее работать с GUI, чем с интерфейсом командной строки, особенно если они не пишут утилиты сами, а пользуются готовыми разработками коллег. NW.js предоставляет простые способы создания GUI к тривиальным приложениям для анализа, обработки и конвертирования веб-страниц.
Как пример для краткого описания этого инструмента я выбрал сайт www.wordspy.com. Word Spy — постоянно пополняющийся словарь английских неологизмов, которые уже успели стать частью языка. То есть не были созданы и однократно употреблены авторами для частных нужд (такие слова называются «окказионализмами»), но «засветились» в нескольких печатных и сетевых источниках разного происхождения. По сравнению с Urban Dictionary, послужившему иллюстрацией для первой статьи, у Word Spy есть два существенных отличия: содержимое страниц формируется асинхронной работой скриптов, а структура этих страниц в значительной степени непредсказуема и сложна (тогда как в Urban Dictionary для текста словарных статей использовался предельно малый набор тегов, а их порядок и сочетание были единообразны). Это и стало решающей причиной обратиться к NW.js.
Я не планирую повторять здесь части официальной документации, уже достаточно полной и систематической, — если вы ещё не знакомы с NW.js, лучше начать с неё (потом можно пролистать wiki-странички на GitHub — хотя многие из них уже устарели, там всё ещё попадается кое-что интересное, не упомянутое в основной документации). Ограничусь лишь заметками о применении проекта к выбранной задаче.
В основном, первый подготовительный скрипт будет во многом напоминать программу из первой статьи. Мы пока даже не будем подключать NW.js, поскольку нам нужно будет лишь повыдёргивать необходимые ссылки из страниц, а с этим успешно справится и JSDOM.
Обозначу лишь существенные различия.
а. Поскольку ко времени загрузки страницы и получения функцией, реагирующей на это событие, объектов
б. Word Spy содержит удобное двухступенчатое содержание всего словаря: 1) список всех тегов, разбитый на несколько тематических блоков; 2) ссылка на каждый из тегов открывает список всех вокабул, относящихся к этому тегу. Мы добавим к нашему словарю как первый список тегов, так и все списки вокабул под тегами. Для этого в наш первоначальный массив адресов (
в. Кое-что в нашей теперешней задаче упростится: Word Spy — словарь, на порядки меньший по объёму по сравнению с Urban Dictionary, поэтому и списки адресов, и словарные статьи у него одностраничные. Нам не придётся проверять наличие многостраничных продолжений ни в этом скрипте, ни в скрипте сохранения самого словаря, что упростит и построение URL, и соответствующие участки кода.
г. В функции
д. Поскольку в нашем коде появляется ещё один асинхронный момент, мы разделим прежнюю функцию
е. Обработка готовой страницы и извлечение нужных ссылок ничем существенным не отличается от описанных в первой статье, разве что мы позаботимся о внесении адреса с тематическим списком всех тегов также и в формируемый список URL словарных статей, чтобы это общее содержание потом сохранилось для удобства навигации в будущем словаре.
Поскольку структура страниц выбранного словаря отличается сложностью и предсказуема лишь до определённого уровня, мы попробуем добавить в процесс сохранения предварительный проход по всем нужным страницам, чтобы собрать информацию о видах и частоте используемых тегов. Для этого создадим скрипт, во многом похожий на скрипт сохранения словаря, разве что извлекать он пока будет предельно простую информацию (поэтому мы всё ещё ограничимся JSDOM).
Этот скрипт можно назвать частичным гибридом скрипта, знакомого нам по сохранению Urban Dictionary, и скрипта, описанного чуть выше: он будет читать готовый список адресов (сначала или с того места, на котором его остановили и которое он перед остановкой обозначил в специальном логе), загружать страницу, запускать её скрипты и ждать, пока они выстроят всё необходимое содержимое словарной статьи. Обозначим лишь несколько новых деталей.
а. При сохранении словаря мы создавали три файла: сам код словаря, лог процесса с записью сохранённых адресов и лог ошибок. В данном случае нам достаточно двух файлов: мы будем вести учёт тегов таким образом, чтобы файл с ними при необходимости мог играть и роль лога проделанной работы для восстановления после перерыва.
б. Массив ключевых селекторов
в. Чтобы не перегружать анализ лишней информацией, мы по грубой предварительной оценке определим некоторые элементы, которые не будем сохранять в словарь и которые тем самым можно сейчас не разбирать на теги: селекторы этих элементов мы сохраним в переменной
г. Анализ каждой страницы будет заключаться в извлечении всех тегов из интересующего нас элемента, регистрации их имён в суммирующем объекте
В остальном код программы не содержит ничего незнакомого.
Программы на NW.js состоят как минимум из двух файлов: служебного в формате JSON, описывающего основные параметры программы, и странички на HTML, описывающей GUI и содержащей скрипты. Последние можно вынести в отдельный файл (файлы) и сослаться на них по локальному или сетевому адресу.
1.
Вот минимальное содержимое нашего служебного файла:
Программы на NW.js при первом запуске создают в системной папке для пользовательских данных свою подпапку, и название её будет сформировано по названию программы из поля
Поле
Необязательный подраздел
Подробнее о формате и составляющих служебного файла можно прочитать в справке.
2.
Окно нашей программы будет относительно простым и кое в чём даже напоминать консольное приложение.
В заголовочную часть разметки, кроме необходимого минимума, можно добавить произвольный блок CSS. Здесь он носит чисто иллюстративный характер, и мы не будем на нём останавливаться.
Первыми элементами нашего GUI будут два поля для параметров, которые мы раньше задавали через ключи командной строки: вводный файл с адресами словарных страниц (раньше мы задавали папку с вводным файлом, а имя файла задавали в коде, чтобы ключ был короче — теперь в этом нет необходимости, и мы можем выбирать файл содержания напрямую) и папку, в которой будут создаваться выходные файлы — сам словарь, лог сохранённых страниц и лог ошибок. Подробнее об особенностях файловых полей в NW.js можно почитать здесь.
Далее следует кнопка, запускающая основное действие программы, а за ней — поле для вывода информации. При помощи CSS и некоторых скриптовых ухищрений мы сделаем его похожим на окно вывода консоли, чтобы сохранить связь с привычными консольными вариантами наших скриптов.
Невидимый элемент
Наконец, последний элемент будет играть ключевую роль «браузера» — в этот встроенный фрейм мы будем загружать наши странички для анализа и извлечения данных. Об особенностях фреймов в NW.js и некоторых связанных с ними предосторожностях можно почитать по уже знакомой нам ссылке.
Вид программы в начале и в конце процесса сохранения словаря можно оценить по скриншотам:

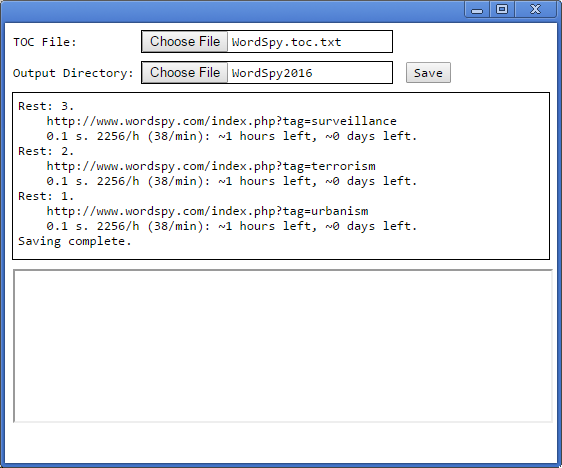
Скриптовую часть программы для удобства мы вынесли в отдельный файл. Ссылаться на него лучше в конце страницы, чтобы в момент запуска скрипт мог найти все необходимые элементы окна и начать с ними взаимодействовать.
3.
В комментариях я постараюсь остановиться только на отличиях и нововведениях по сравнению с консольным скриптом из предыдущей статьи, потому что и основная структура, и множество участков кода будут общими.
а. Первое отличие мы видим в начале вводной части. Появляются переменные для окна и документа самой программы (так нам будет легче не путать их с переменными окна и документа загружаемых страниц), а потом и для каждого элемента GUI. Поскольку пути к файлам будут строиться динамически (не раз и навсегда по ключам командной строки, а в ответ на действия пользователя), мы будем хранить их как изменяемые свойства объекта
б. При работе с GUI искушение не вовремя закрыть окно больше, чем при работе с консолью. Поэтому мы создадим чуть большую систему предохранителей от некорректного завершения программы. Для начала назначим обработчиком закрытия окна функцию
в. Как мы могли видеть из справки, стандартные предосторожности HTML 5 остались в силе, и мы не можем задавать конечные адреса файлов при помощи атрибутов или свойств наших файловых полей — это можно сделать только пользовательским действием через диалоговое окно. Но мы можем сократить время и усилия пользователя, сохраняя путь к папке, в которой пользователю предлагается выбрать файл (а если файл и есть папка, предварительный и конечный адрес чудом совпадут). Для этого мы воспользуемся ещё одним служебным файлом в формате JSON —
г. После проверки файла сохранённых настроек мы задаём обработчики событий для всех интерактивных элементов и запускаем первый из них принудительно, чтобы привести элементы в правильное начальное состояние.
д. Функция
е. Функция
ё. Функция
ж. В функции
з. Функция
и. Функция
й. Функция
к.
л.
м. Функция
н. В функции
Начинаем мы с чистки ненужных частей словарной статьи. Затем мы определяем ключевой её элемент, получаем список всех его текстовых частей (возможности XPath позволят нам получить именно чистые конечные текстовые узлы, без вложенных HTML-элементов, так что мы сможем изменять их содержимое без риска повредить структуру документа), а затем подвергаем все эти элементы упомянутой выше низкоуровневой чистке — таким образом мы с самого начала получаем экранирование спецсимволов во всём тексте статьи, и дальнейшее добавление DSL-тегов можно будет совершать уже безболезненно поверх этого текста.
Затем мы формируем заголовок будущей словарной статьи.
Если это обычная страница словаря, мы извлекаем из нужного элемента основной заголовок, а потом добавляем к нему варианты написания, формы и дериваты (мы сочли это необходимым, поскольку моделирование морфологии неологизмов в оболочке словаря может быть затруднено, лучше облегчить словарю эту работу). Здесь мы впервые встречаемся с одной из главных причин подключения NW.js: свойством элементов
Если же мы обрабатываем одну из страниц тегов, задача упрощается — мы сохраняем только основной заголовок, предваряя его сочетанием «# ». Таким образом, общий список тегов можно будет найти под вокабулой «# Tags by Category», а списки заголовков, объединённых одним тегом, — под вокабулами типа «# acronyms and abbreviations» и т.д.
Далее мы приступаем к извлечению и переоформлению основной части статьи. Список тегов, полученный на предварительном этапе, позволил нам набросать приблизительный план обработки, так чтобы мы могли свести неожиданности к минимуму. Эта обработка будет некоторым рискованным компромиссом: часть структуры статей можно предвидеть и уверенно использовать, от остальных сюрпризов можно лишь грубо перестраховаться.
При наших вставках и заменах мы будем пользоваться методом
Итак, сперва мы работаем с большими блоками статьи, так сказать, с макроструктурой: вставляем пустые строки между блоковыми элементами, чтобы после запроса свойства
Затем спускаемся чуть ниже по структуре. Заключаем цитаты в кавычки. Расставляем маркеры списков. Исправляем случайные ошибки разметки (например, в одной из статей псевдотеги
После этого мы начинаем облекать подходящие элементы в теги DSL.
Выделяем цветом и толщиной шрифта заголовки и подзаголовки. Выделяем курсивом и толщиной шрифта элементы, которые выделяются так на странице или по свойству самих тегов, или через CSS. При этом что-то мы можем предусмотреть заранее (и запросить при помощи селекторов с названиями тегов или их классов), а что-то нам придётся выяснять на лету: для этого мы будем запрашивать все элементы
Следующий шаг — и мы пометили все верхние и нижние индексы.
Потом обработали ссылки: сохранили, как есть, автоссылки на текущую страницу; внутрисайтовые ссылки превратили во внутрисловарные в формате DSL; внешние ссылки оформили как сетевые URL (при этом старались сохранить перед ссылкой и пометить подчёркиванием её читабельный текст, так как формат DSL не позволяет прятать за текстом сетевые адреса, объединяя всё в одно целое).
Также мы заменили изображения на их внешние ссылки (изображения на сайте попадаются довольно большие, поэтому мы не стали встраивать их в словарь — при необходимости пользователь сможет перейти по адресу на сайт).
Наконец, мы вставили дополнительные отступы для выделения цитат (т.е. примеров употребления для каждого неологизма).
В результате мы получили два в одном: полностью сохранённую разметку HTML, а внутри неё — разметку DSL, при этом без всякого конфликта между ними. И когда мы запросим свойство
Его мы и записываем в файл словаря после списка заголовков, не забывая подвергнуть окончательной обработке функцией
о. Функция
Программа на NW.js, как уже говорилось, создаёт в системной папке пользовательских данных свою подпапку, в чём-то подобную папке профиля браузера. Можно предположить, что в ней, в числе прочего, хранятся файлы кеша, ускоряющего загрузку однотипных страниц. В моём случае эта подпапка после сохранения словаря занимала 138 мегабайт. В конце работы её можно безболезненно удалить — следующий раз программа создаст её автоматически (разве что на это уйдёт какое-то время при первом запуске).
Скрипт сохранял словарь полтора часа, обработал за это время почти три с половиной тысячи страниц со всеми их ресурсами, при этом процессор ощутимо не нагружал. Расход памяти, а также объёмы чтения/записи к самому концу работы программы можно оценить по этому скриншоту.
Словарь (по состоянию сайта на 16.02.2016) выложен на rghost.net и drive.google.com. Архив включает DSL-исходники в кодировках UTF-8 и UTF-16, а также скомпилированные в LSD словари под три последние версии ABBYY Lingvo. Заголовков: 5827; карточек: 3419; примеров употребления: 9311.
Спасибо за внимание.
I. Зачем нам NW.js?
1. Чем сложнее структура веб-страниц словаря, тем больше оснований опереться на весь спектр возможностей, предоставляемый отточенным браузерным движком. JSDOM — довольно развитая библиотека, но даже она не сравнится с полным набором средств из Chromium.
2. Люди, занимающиеся созданием и конвертированием цифровых словарей, — в значительной мере гуманитарии, которых волей судьбы занесло в сферу IT. Иногда им комфортнее работать с GUI, чем с интерфейсом командной строки, особенно если они не пишут утилиты сами, а пользуются готовыми разработками коллег. NW.js предоставляет простые способы создания GUI к тривиальным приложениям для анализа, обработки и конвертирования веб-страниц.
Как пример для краткого описания этого инструмента я выбрал сайт www.wordspy.com. Word Spy — постоянно пополняющийся словарь английских неологизмов, которые уже успели стать частью языка. То есть не были созданы и однократно употреблены авторами для частных нужд (такие слова называются «окказионализмами»), но «засветились» в нескольких печатных и сетевых источниках разного происхождения. По сравнению с Urban Dictionary, послужившему иллюстрацией для первой статьи, у Word Spy есть два существенных отличия: содержимое страниц формируется асинхронной работой скриптов, а структура этих страниц в значительной степени непредсказуема и сложна (тогда как в Urban Dictionary для текста словарных статей использовался предельно малый набор тегов, а их порядок и сочетание были единообразны). Это и стало решающей причиной обратиться к NW.js.
Я не планирую повторять здесь части официальной документации, уже достаточно полной и систематической, — если вы ещё не знакомы с NW.js, лучше начать с неё (потом можно пролистать wiki-странички на GitHub — хотя многие из них уже устарели, там всё ещё попадается кое-что интересное, не упомянутое в основной документации). Ограничусь лишь заметками о применении проекта к выбранной задаче.
II. Подготовительный этап
1. Получение списка адресов словарных статей
В основном, первый подготовительный скрипт будет во многом напоминать программу из первой статьи. Мы пока даже не будем подключать NW.js, поскольку нам нужно будет лишь повыдёргивать необходимые ссылки из страниц, а с этим успешно справится и JSDOM.
Код скрипта.Обозначу лишь существенные различия.
а. Поскольку ко времени загрузки страницы и получения функцией, реагирующей на это событие, объектов
window и document содержимое страницы ещё не готово, нам нужно будет ввести дополнительный цикл проверок (поскольку страница наполняется асинхронной работой скриптов, отслеживание события load нам ничего не даст; можно было бы повесить обработчики событий на изменения DOM, но в данной ситуации это кажется неоправданным усложнением). Проанализировав работу сайтовых скриптов, мы находим какой-нибудь показательный элемент страницы, наличие которого означает завершение постройки нужной нам структуры (в данном случае блока со списком ссылок на словарные статьи). Селектор этого элемента мы и определяем вдобавок к уже знакомым нам переменным (selectorsToCheck в начальном блоке кода; на тот будущий случай, когда для разных страниц потребуются разные проверочные элементы, мы сделаем эту переменную массивом). Вторым добавлением будет число миллисекунд, задающее периодичность проверки ключевого элемента (checkFrequency).б. Word Spy содержит удобное двухступенчатое содержание всего словаря: 1) список всех тегов, разбитый на несколько тематических блоков; 2) ссылка на каждый из тегов открывает список всех вокабул, относящихся к этому тегу. Мы добавим к нашему словарю как первый список тегов, так и все списки вокабул под тегами. Для этого в наш первоначальный массив адресов (
tocURLs), который станет источником списка словарных статей, мы добавим упомянутую отправную страничку с тегами. Так же, в отличие от скрипта из первой статьи, где этот массив назывался abc, мы сразу превратим его в список URL, а не будем формировать его на лету из алфавита, так как адрес с тегами не вписывается в единый шаблон URL.в. Кое-что в нашей теперешней задаче упростится: Word Spy — словарь, на порядки меньший по объёму по сравнению с Urban Dictionary, поэтому и списки адресов, и словарные статьи у него одностраничные. Нам не придётся проверять наличие многостраничных продолжений ни в этом скрипте, ни в скрипте сохранения самого словаря, что упростит и построение URL, и соответствующие участки кода.
г. В функции
getDoc немного меняется библиотечный запрос jsdom.env: Urban Dictionary был статичным словарём, здесь же нам придётся потребовать загрузку и исполнение скриптов на страницах, что отображается в опциях запроса.д. Поскольку в нашем коде появляется ещё один асинхронный момент, мы разделим прежнюю функцию
processDoc на две: в функции checkDoc мы будем проверять как возможные ошибки, так и окончание работы сайтовых скриптов, а обработку готового документа перенесём в отсроченную функцию processDoc. Цикл проверки совершает некоторое число итераций (скажем, пока не пройдёт 5 секунд). Если за это время появился проверочный элемент, мы переходим к функции обработки документа. Если элемента по прошествии тайм-аута нет, мы проверяем, не было ли переадресации: если нет, можно заподозрить заминку на сервере и повторить запрос, если сервер нас переадресовал куда-то, остаётся лишь выдать предупреждение пользователю и временно завершить работу программы. Опыт показал, что на отработку сайтовых скриптов в большинстве случаев требовалось 100-400 миллисекунд, хотя иногда задержка составляла и несколько секунд, и лишь изредка превышала тайм-аут (в таких случаях достаточно было одного повторного запроса).е. Обработка готовой страницы и извлечение нужных ссылок ничем существенным не отличается от описанных в первой статье, разве что мы позаботимся о внесении адреса с тематическим списком всех тегов также и в формируемый список URL словарных статей, чтобы это общее содержание потом сохранилось для удобства навигации в будущем словаре.
2. Составление списка тегов
Поскольку структура страниц выбранного словаря отличается сложностью и предсказуема лишь до определённого уровня, мы попробуем добавить в процесс сохранения предварительный проход по всем нужным страницам, чтобы собрать информацию о видах и частоте используемых тегов. Для этого создадим скрипт, во многом похожий на скрипт сохранения словаря, разве что извлекать он пока будет предельно простую информацию (поэтому мы всё ещё ограничимся JSDOM).
Код скрипта.Этот скрипт можно назвать частичным гибридом скрипта, знакомого нам по сохранению Urban Dictionary, и скрипта, описанного чуть выше: он будет читать готовый список адресов (сначала или с того места, на котором его остановили и которое он перед остановкой обозначил в специальном логе), загружать страницу, запускать её скрипты и ждать, пока они выстроят всё необходимое содержимое словарной статьи. Обозначим лишь несколько новых деталей.
а. При сохранении словаря мы создавали три файла: сам код словаря, лог процесса с записью сохранённых адресов и лог ошибок. В данном случае нам достаточно двух файлов: мы будем вести учёт тегов таким образом, чтобы файл с ними при необходимости мог играть и роль лога проделанной работы для восстановления после перерыва.
б. Массив ключевых селекторов
selectorsToCheck будет содержать теперь два элемента: для обычных страниц словаря и для страниц со списком тегов (или вокабул, объединённых одним тегом).в. Чтобы не перегружать анализ лишней информацией, мы по грубой предварительной оценке определим некоторые элементы, которые не будем сохранять в словарь и которые тем самым можно сейчас не разбирать на теги: селекторы этих элементов мы сохраним в переменной
selectorsToDelete, чтобы удалить ненужное перед началом парсинга.г. Анализ каждой страницы будет заключаться в извлечении всех тегов из интересующего нас элемента, регистрации их имён в суммирующем объекте
tags (с постоянным увеличением статистики по каждому тегу), записи в файл адреса страницы и списка тегов на ней. В конце работы скрипта в файл записывается также итоговый объект tags. Таким образом мы получаем как общую статистику тегов, так и распределение их по страницам, что даёт нам возможность посмотреть примеры употребления тега, открыв любой из адресов, под которым этот тег записан. Если работа скрипта прерывалась, по уже записанной в файл информации мы можем восстанавливать статистический объект tags. Эти два похожих процесса — чтение страниц и чтение выжимок из лога — мы видим в двух соответствующих местах скрипта: в начальной части (под строчкой console.log('Reading the tag file...');) и в функции processDoc.В остальном код программы не содержит ничего незнакомого.
III. Сохранение словаря
Программы на NW.js состоят как минимум из двух файлов: служебного в формате JSON, описывающего основные параметры программы, и странички на HTML, описывающей GUI и содержащей скрипты. Последние можно вынести в отдельный файл (файлы) и сослаться на них по локальному или сетевому адресу.
1. package.json
Вот минимальное содержимое нашего служебного файла:
{
"name": "NW.WordSpy.get_dic",
"main": "WordSpy.get_dic.html",
"window": {
"title": "Save WordSpy.com"
}
}Программы на NW.js при первом запуске создают в системной папке для пользовательских данных свою подпапку, и название её будет сформировано по названию программы из поля
name.Поле
main содержит путь к основному файлу с элементами GUI и главным скриптом программы.Необязательный подраздел
window содержит параметры создаваемого окна программы, и мы пока ограничимся заголовком.Подробнее о формате и составляющих служебного файла можно прочитать в справке.
2. WordSpy.get_dic.html
Окно нашей программы будет относительно простым и кое в чём даже напоминать консольное приложение.
Код HTML-странички.В заголовочную часть разметки, кроме необходимого минимума, можно добавить произвольный блок CSS. Здесь он носит чисто иллюстративный характер, и мы не будем на нём останавливаться.
Первыми элементами нашего GUI будут два поля для параметров, которые мы раньше задавали через ключи командной строки: вводный файл с адресами словарных страниц (раньше мы задавали папку с вводным файлом, а имя файла задавали в коде, чтобы ключ был короче — теперь в этом нет необходимости, и мы можем выбирать файл содержания напрямую) и папку, в которой будут создаваться выходные файлы — сам словарь, лог сохранённых страниц и лог ошибок. Подробнее об особенностях файловых полей в NW.js можно почитать здесь.
Далее следует кнопка, запускающая основное действие программы, а за ней — поле для вывода информации. При помощи CSS и некоторых скриптовых ухищрений мы сделаем его похожим на окно вывода консоли, чтобы сохранить связь с привычными консольными вариантами наших скриптов.
Невидимый элемент
audio будет служить для привлечения пользовательского внимания — раньше мы пользовались для этого консольным плеером. Адрес звукового файла может быть любым другим, я использовал один из системных файлов стандартной звуковой схемы событий.Наконец, последний элемент будет играть ключевую роль «браузера» — в этот встроенный фрейм мы будем загружать наши странички для анализа и извлечения данных. Об особенностях фреймов в NW.js и некоторых связанных с ними предосторожностях можно почитать по уже знакомой нам ссылке.
Вид программы в начале и в конце процесса сохранения словаря можно оценить по скриншотам:
Скриптовую часть программы для удобства мы вынесли в отдельный файл. Ссылаться на него лучше в конце страницы, чтобы в момент запуска скрипт мог найти все необходимые элементы окна и начать с ними взаимодействовать.
3. WordSpy.get_dic.js
Код скрипта.В комментариях я постараюсь остановиться только на отличиях и нововведениях по сравнению с консольным скриптом из предыдущей статьи, потому что и основная структура, и множество участков кода будут общими.
а. Первое отличие мы видим в начале вводной части. Появляются переменные для окна и документа самой программы (так нам будет легче не путать их с переменными окна и документа загружаемых страниц), а потом и для каждого элемента GUI. Поскольку пути к файлам будут строиться динамически (не раз и навсегда по ключам командной строки, а в ответ на действия пользователя), мы будем хранить их как изменяемые свойства объекта
io, а не как разрозненный набор констант. Ещё одно отличие — наборы селекторов разного назначения для более удобных манипуляций со сложной структурой документа (они нам уже знакомы по предыдущему скрипту для анализа тегов). Наконец, поскольку интерактивность возрастает, в конце вводной части мы создадим несколько переменных-индикаторов для текущего состояния программы и пользовательских команд.б. При работе с GUI искушение не вовремя закрыть окно больше, чем при работе с консолью. Поэтому мы создадим чуть большую систему предохранителей от некорректного завершения программы. Для начала назначим обработчиком закрытия окна функцию
onExit(), о действиях которой скажем позже.в. Как мы могли видеть из справки, стандартные предосторожности HTML 5 остались в силе, и мы не можем задавать конечные адреса файлов при помощи атрибутов или свойств наших файловых полей — это можно сделать только пользовательским действием через диалоговое окно. Но мы можем сократить время и усилия пользователя, сохраняя путь к папке, в которой пользователю предлагается выбрать файл (а если файл и есть папка, предварительный и конечный адрес чудом совпадут). Для этого мы воспользуемся ещё одним служебным файлом в формате JSON —
config.json, в котором будем хранить объект с двумя свойствами, по числу нужных нам путей. В начале работы программа будет проверять наличие этого файла: если он есть, она прочитает содержимое в объект config и запишет в свойства nwworkingdir для обоих полей нужные пути. Если файла нет, объект будет пустым и начальный каталог будет определён обычным для браузера образом.г. После проверки файла сохранённых настроек мы задаём обработчики событий для всех интерактивных элементов и запускаем первый из них принудительно, чтобы привести элементы в правильное начальное состояние.
д. Функция
checkDirs() проверяет определение всех нужных путей: если хотя бы один из них не определён, она выводит сообщение в информационный блок, в противном случае записывает данные в файл сохраняемых настроек и снимает блокировку с кнопки запуска основного процесса.е. Функция
onStop() реагирует на команду прерывания основного процесса: она всего лишь переводит индикатор этой команды во включённое положение, чтобы процесс мог потом быть прерван в удобный момент.ё. Функция
onExit() реагирует на попытку закрыть окно программы. Если в это время происходит сохранение словаря, она задаёт проверочный вопрос. При подтверждении индикаторы прерывания процесса и выхода из программы переводятся во включённое положение для последующих действий в удобное время. Если пользователь не подтверждает действие, оно игнорируется. Если сохранение не производится, программа закрывается без лишних вопросов.ж. В функции
setSpeedInfo() значительное изменение коснулось лишь звукового сигнала. Я пока оставил частоту обновления и формат информации о скорости работы на прежнем уровне (раз в час), но при необходимости их можно подкорректировать (ведь Urban Dictionary сохранялся много дней, а Word Spy — около полутора часов, так что частоту пересчёта и единицы измерения можно повысить до минут).з. Функция
updateInfo(str) отвечает за уподобление информационного блока консоли. Мы задаём размер буфера в 10 строк и обрубаем лишние строки сначала (там самая старая информация), прокручивая блок до последней строчки. Через эту функцию мы выводим постоянно текущую информацию в процессе сохранения. При небольших словарях такое поведение можно отключить (тогда сохранится весь протокол рипа), но при длинном процессе подобные ограничения экономят память и удаляют избыточность (тем более что всё нужное пишется в логи).и. Функция
logError(evt) призвана реагировать на событие error внутри окна встроенного фрейма. У меня она пока ни разу не сработала.й. Функция
secureLow(str) служит низкоуровневой обработке текста загружаемых страниц для приведения его к требованиям DSL, а именно для экранирования спецсимволов. Тогда как secureHigh служит для обработки текстовых блоков (удаление лишних пробелов, вставка отступов перед телом словарных статей DSL, специальная вставка для сохранения пустых строк). В консольном варианте из первой статьи мы обходились одной функцией, но здесь наш порядок извлечения и оформления информации несколько изменится, и нам придётся эту обработку разделить.к.
saveDic() — основная функция программы, запускаемая при нажатии на кнопку сохранения словаря. Она во многом отвечает начальной, процедурной части нашего консольного скрипта из первой статьи, но есть и ряд отличий. Первым делом мы включаем переменную-индикатор процесса сохранения и изменяем вид и поведение главной кнопки: теперь она будет отвечать за прерывание процесса. Также отключаем исполнившие свою роль файловые поля. Затем производим уже знакомые манипуляции с файлами: проверяем наличие списка адресов, создаём заготовки словаря и отчётов, читаем список адресов, читаем информацию об уже сохранённых страницах при её наличии в логе сохранения и по необходимости сокращаем задачу, наконец начинаем цикл сохранения, запрашивая первую страницу в списке. Новым на этом отрезке кода будет задание обработчиков событий load и error для окна встроенного фрейма, необходимых для работы нашего цикла.л.
getDoc(url) — отправное звено круговой цепочки сохранения. Эту функцию мы вызываем в начале цикла и после обработки каждой страницы. Начинается она с проверки индикатора прерывания: если он был включён, цикл прерывается и запускается остановка процесса. Если он выключен, после знакомых нам операций мы меняем адрес фрейма, заставляя его загрузить новую страницу.м. Функция
checkDoc() запускается автоматически в ответ на полную загрузку страницы в наш встроенный браузер. Она частично знакома нам по предыдущим скриптам этой статьи. Только теперь мы начинаем её с создания переменных, позволяющих нам не путать главные объекты окна программы и окна загруженной страницы. Затем следует знакомый нам цикл проверок на готовность содержимого страницы. В зависимости от его результатов мы или переходим к обработке информации, или перезагружаем страницу, или завершаем работу с сообщением о неведомой ошибке.н. В функции
processDoc(iWin, iDoc, iLoc, iter) содержится извлечение, обработка и сохранение словарных данных страницы. Она наиболее отличается от соответствующей консольной части кода — и в силу отличий словаря, и по причине особенностей нового инструмента.Начинаем мы с чистки ненужных частей словарной статьи. Затем мы определяем ключевой её элемент, получаем список всех его текстовых частей (возможности XPath позволят нам получить именно чистые конечные текстовые узлы, без вложенных HTML-элементов, так что мы сможем изменять их содержимое без риска повредить структуру документа), а затем подвергаем все эти элементы упомянутой выше низкоуровневой чистке — таким образом мы с самого начала получаем экранирование спецсимволов во всём тексте статьи, и дальнейшее добавление DSL-тегов можно будет совершать уже безболезненно поверх этого текста.
Затем мы формируем заголовок будущей словарной статьи.
Если это обычная страница словаря, мы извлекаем из нужного элемента основной заголовок, а потом добавляем к нему варианты написания, формы и дериваты (мы сочли это необходимым, поскольку моделирование морфологии неологизмов в оболочке словаря может быть затруднено, лучше облегчить словарю эту работу). Здесь мы впервые встречаемся с одной из главных причин подключения NW.js: свойством элементов
innerText. Оно не было доступным для JSDOM (объяснение причин), в распоряжении библиотеки было лишь свойство textContent, очень неудобное для извлечения текста из сложных элементов (из-за смешения текста разметки (кода HTML) и отображаемого текста). Свойство innerText обеспечивает нам необходимую для сложных страниц уверенность: каково бы ни было строение словарной статьи или её частей, мы извлечём именно полезный читабельный текст (который мы бы получили, копируй мы информацию из окна страницы системными средствами через буфер обмена). Это же свойство позволяет нам временно исключать лишний текст перед извлечением (так мы, например, убираем грамматические пометы перед помещением форм слова в список заголовков): стоит нам скрыть ненужные элементы, и их текст не попадает в состав свойства (потом мы включаем отображение, и пометы остаются в составе тела статьи).Если же мы обрабатываем одну из страниц тегов, задача упрощается — мы сохраняем только основной заголовок, предваряя его сочетанием «# ». Таким образом, общий список тегов можно будет найти под вокабулой «# Tags by Category», а списки заголовков, объединённых одним тегом, — под вокабулами типа «# acronyms and abbreviations» и т.д.
Далее мы приступаем к извлечению и переоформлению основной части статьи. Список тегов, полученный на предварительном этапе, позволил нам набросать приблизительный план обработки, так чтобы мы могли свести неожиданности к минимуму. Эта обработка будет некоторым рискованным компромиссом: часть структуры статей можно предвидеть и уверенно использовать, от остальных сюрпризов можно лишь грубо перестраховаться.
При наших вставках и заменах мы будем пользоваться методом
insertAdjacentHTML(), потому что он наиболее щадящий по отношению к структуре разметки.Итак, сперва мы работаем с большими блоками статьи, так сказать, с макроструктурой: вставляем пустые строки между блоковыми элементами, чтобы после запроса свойства
innerText мы получили более читабельный текст; заменяем теги hr на символьные псевдолинии; заменяем встроенные фреймы (с видео или, например, твитами) на предупреждения с приглашением ознакомиться с ними на сайте.Затем спускаемся чуть ниже по структуре. Заключаем цитаты в кавычки. Расставляем маркеры списков. Исправляем случайные ошибки разметки (например, в одной из статей псевдотеги
smirk и flame случайно превращаются из части цитируемого кода в разметку и исчезают из отображаемого текста). Вставляем в текст содержимое, добавляемое на страницу при помощи CSS и тем самым не включаемое в свойство innerText. После этого мы начинаем облекать подходящие элементы в теги DSL.
Выделяем цветом и толщиной шрифта заголовки и подзаголовки. Выделяем курсивом и толщиной шрифта элементы, которые выделяются так на странице или по свойству самих тегов, или через CSS. При этом что-то мы можем предусмотреть заранее (и запросить при помощи селекторов с названиями тегов или их классов), а что-то нам придётся выяснять на лету: для этого мы будем запрашивать все элементы
span внутри статьи, проверять их вычисляемые стилистические параметры и при необходимости добавлять теги. При этом мы постараемся не дублировать одни и те же оформляющие теги внутри друг друга (в отличие от HTML, в DSL такое не допускается) — для этого мы станем помечать обработанные элементы специальным атрибутом, а потом проверяем его наличие вверх по дереву DOM.Следующий шаг — и мы пометили все верхние и нижние индексы.
Потом обработали ссылки: сохранили, как есть, автоссылки на текущую страницу; внутрисайтовые ссылки превратили во внутрисловарные в формате DSL; внешние ссылки оформили как сетевые URL (при этом старались сохранить перед ссылкой и пометить подчёркиванием её читабельный текст, так как формат DSL не позволяет прятать за текстом сетевые адреса, объединяя всё в одно целое).
Также мы заменили изображения на их внешние ссылки (изображения на сайте попадаются довольно большие, поэтому мы не стали встраивать их в словарь — при необходимости пользователь сможет перейти по адресу на сайт).
Наконец, мы вставили дополнительные отступы для выделения цитат (т.е. примеров употребления для каждого неологизма).
В результате мы получили два в одном: полностью сохранённую разметку HTML, а внутри неё — разметку DSL, при этом без всякого конфликта между ними. И когда мы запросим свойство
innerText, от HTML останется лишь структурированный читабельный текст, облечённый в теги DSL, готовый для непосредственного сохранения в качестве словарного кода.Его мы и записываем в файл словаря после списка заголовков, не забывая подвергнуть окончательной обработке функцией
secureHigh. Затем мы обновляем лог сохранения и блок информации в окне программы (мы решили добавлять в него отладочную информацию о том, как скоро формируется содержимое страницы асинхронными скриптами), очищаем список заголовков перед следующей итерацией, проверяем массив адресов и либо запрашиваем следующую страницу, либо переходим к завершению цикла.о. Функция
endSaving() вызывается или в конце цикла сохранения, или в результате его прерывания по требованию пользователя либо после ошибки. В ней мы закрываем дескрипторы файлов, очищаем переменные путей ввода/вывода, отменяем ставшие ненужными обработчики событий, возвращаем начальный вид элементам интерфейса. Если включён флаг выхода из программы, в конце функции мы принудительно закрываем основное окно.4. Ресурсы
Программа на NW.js, как уже говорилось, создаёт в системной папке пользовательских данных свою подпапку, в чём-то подобную папке профиля браузера. Можно предположить, что в ней, в числе прочего, хранятся файлы кеша, ускоряющего загрузку однотипных страниц. В моём случае эта подпапка после сохранения словаря занимала 138 мегабайт. В конце работы её можно безболезненно удалить — следующий раз программа создаст её автоматически (разве что на это уйдёт какое-то время при первом запуске).
Скрипт сохранял словарь полтора часа, обработал за это время почти три с половиной тысячи страниц со всеми их ресурсами, при этом процессор ощутимо не нагружал. Расход памяти, а также объёмы чтения/записи к самому концу работы программы можно оценить по этому скриншоту.
Словарь (по состоянию сайта на 16.02.2016) выложен на rghost.net и drive.google.com. Архив включает DSL-исходники в кодировках UTF-8 и UTF-16, а также скомпилированные в LSD словари под три последние версии ABBYY Lingvo. Заголовков: 5827; карточек: 3419; примеров употребления: 9311.
Спасибо за внимание.

{kind=link}