Сегодня, когда во всех деревнях и сёлах идёт нейрореволюция, мы всё больше убеждаемся, что нейросети — это чистая магия и манна-небесная. Их стали использовать везде и всюду, и даже встроили в Excel. Неявно, при виде сложной задачи многим представляется следующая картина:

И сегодня мы займёмся совмещением приятного с полезным: разберём интересную (практическую) аналитическую задачу и заодно проанализируем ряд факторов, определяющих (не-)применимость нейронных сетей к аналитическим задачам.
Представьте, вы работаете аналитиком в какой-нибудь компании, которой важен её облик на Хабре (условно назовём её Почта.com). И тут к вам приходит девушка из PR-отдела и говорит: "Мы с менеджерами определили в качестве важного KPI нашего бренда Хабра-рейтинг компании. У нас есть бюджет и мы хотим понять, как его распределить, чтобы максимизировать Хабра-индекс. Нам нужно, чтобы ты определил ключевые факторы, которые на него влияют и вывел наиболее разумную стратегию. Попробуй там какие-нибудь нейросети".
Во время этой речи у вас начинает дергаться глаз, но спустя пару минут составляете список вопросов для анализа:
Структура статьи
Если взглянуть на профиль компании, то в глаза бросаются следующие возможные кандидаты:
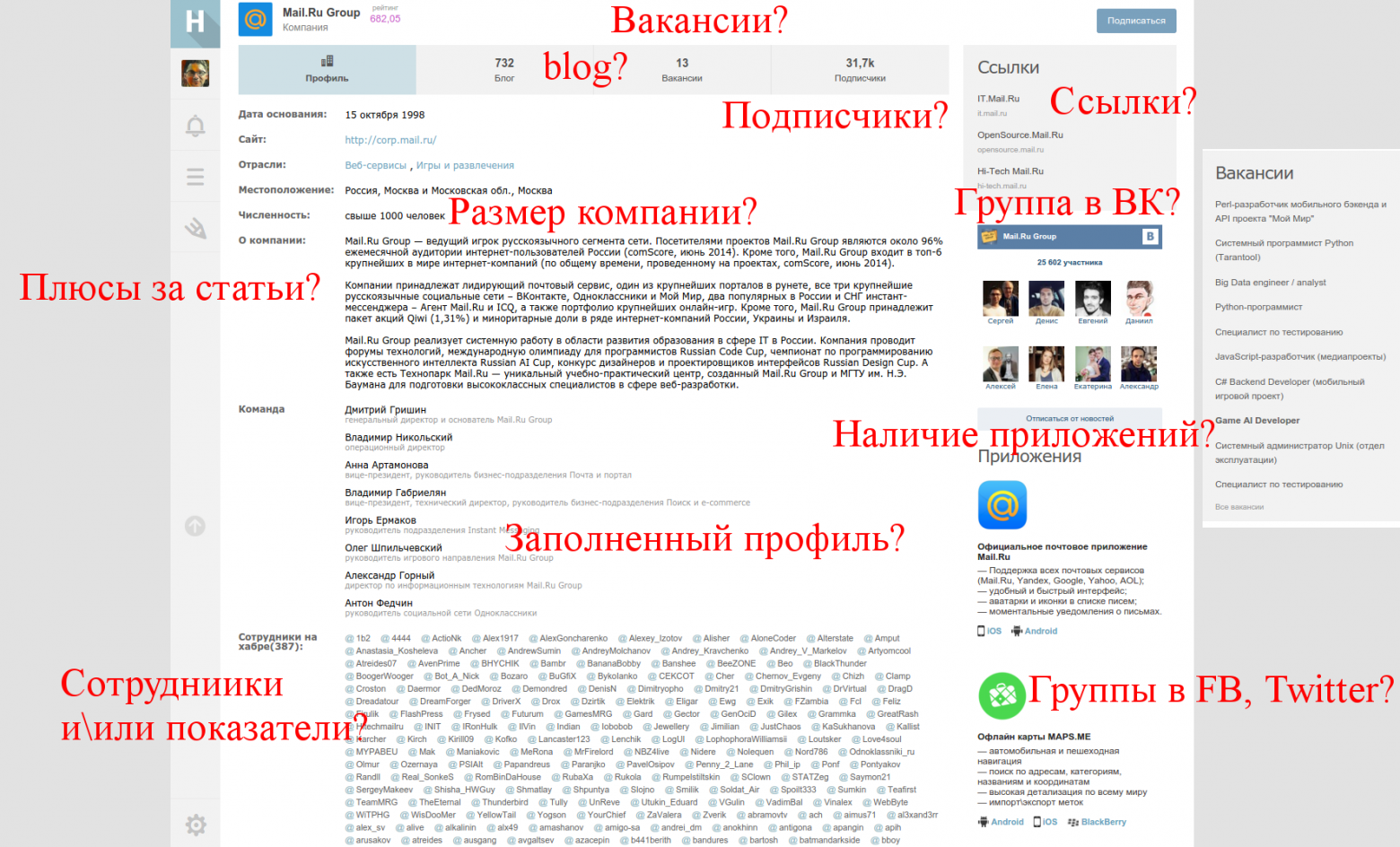
Причем параметры могут состоять из целой группы переменных: карма и рейтинг сотрудников, количество просмотров, избранного, плюсов у статей, а также их количество, etc.
И тут самый интересный момент: feature construction, а что собственно является фактором определяющим Хабра-индекс? И почему это столь важно? Например, чтобы алгоритм машинного обучения "выучил" настоящую исходную функцию, нужно чтобы исходная функция была определена в правильном пространстве, которого у нас нет!
В некотором смысле это порочный круг — нужно знать, что пространство (или подпространство) содержит ключевые факторы, чтобы восстановить зависимость. Но в данной ситуации, если известны ключевые факторы (или их надмножество), то задача фактически решена.
Чуть более формально, это можно описать так: локальные закономерности присутствуют в нашем представлении данных, то есть у нас "верное представление" всех параметров функции, которую мы хотим выучить. Если настоящая функция f(X,Y,Z), а в нашем представлении есть только X и Y, то мы ищем функцию в заведомо неверном классе F(X,Y), не учитывающем Z. Этим реальные задачи существенно отличаются от Kaggle, нам ничего не дано.
Как определить, что фактор важен? Мы знаем, что зависимость детерминированная, то есть есть некоторая аналитическая функция, по которой ТМ однозначно считает индекс. Обозначим, функцию индекса за f, тогда f зависит от фактора xi, тогда и только тогда когда для любых xi верно что:

и с мы будем называть величиной эффекта.
Данное определение не предполагает независимости между переменными. Если переменные зависимы, значит, что c для i-го фактора может меняться в зависимости от остальных переменных.
Также мы знаем, из нашего опыта, что функция обязана удовлетворять граничному условию:

Важный момент: интеграция сильных априорных представлений о том, какой должна быть функция в нейронные сети — задача совершенно нетривиальная.
Таким образом ключевое наблюдение в вопросе Q1: необходимо адекватным образом трансформировать данные из профиля компании (например, перечисленные выше) и произвести замер эффекта, по одному удаляя искажающие факторы (confounding variables). Также необходимо будет проверить условие факторизации, то есть, что переменные независимы друг от друга:

Отправляемся по адресу: https://habrahabr.ru/companies/ на самую последнюю страницу и видим, ценнейший материал:

Это набор компаний, с нулём публикаций и небольшим числом сотрудников (один-два) и небольшим числом подписчиков. Выбрав две компании — xPrecision и Покет ДС с одинаковым числом сотрудников и разницей в одного подписчика, мы нашли ненулевую разницу в Хабра-индексе.
Бинго: первый фактор определяющий Хабра-индекс число подписчиков! Заметим, что рост явно не линейный — достаточно взглянуть на компании в начале, середине и конце списка. Логично, что функция должна насыщаться при достаточном числе подписчиков, чтобы не было накруток и вообще фактор подписчиков не доминировал сами статьи. Значит функция, должна расти медленно и в какой-то момент выходить почти на константу. Хм, логарифм!
log(2) = 0.69
log(4) = 1.39
log(5) = 1.61
.....
Итого, убеждаемся, что функция имеет вид:

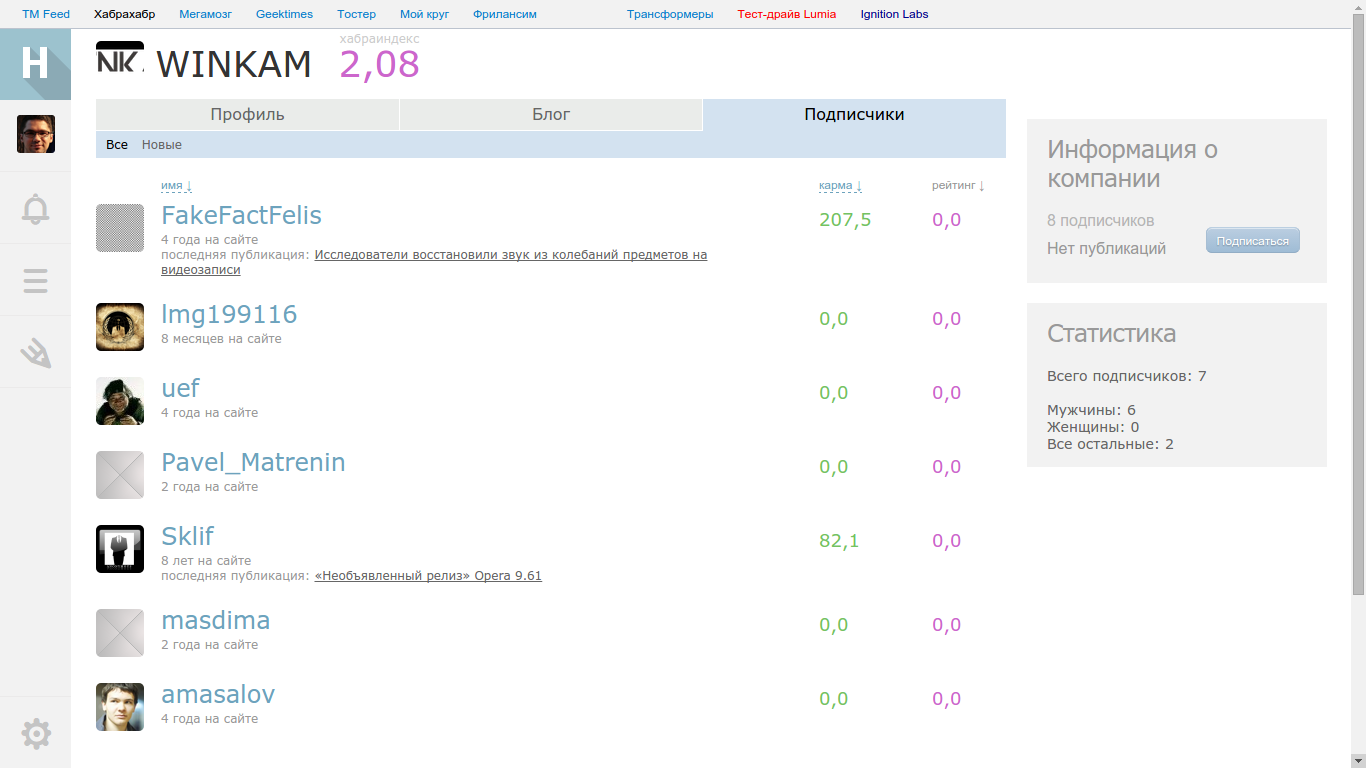
Заметим, что функция не зависит от кармы подписчиков, так как log(8) = 2.08:
Причем коэффициент равен 1, если у компании нет публикаций, и равен 3, если есть (как показал дальнейший анализ).
Рассмотрим 15ую страницу и возьмем две компании с одинаковым числом подписчиков и разным числом сотрудников:
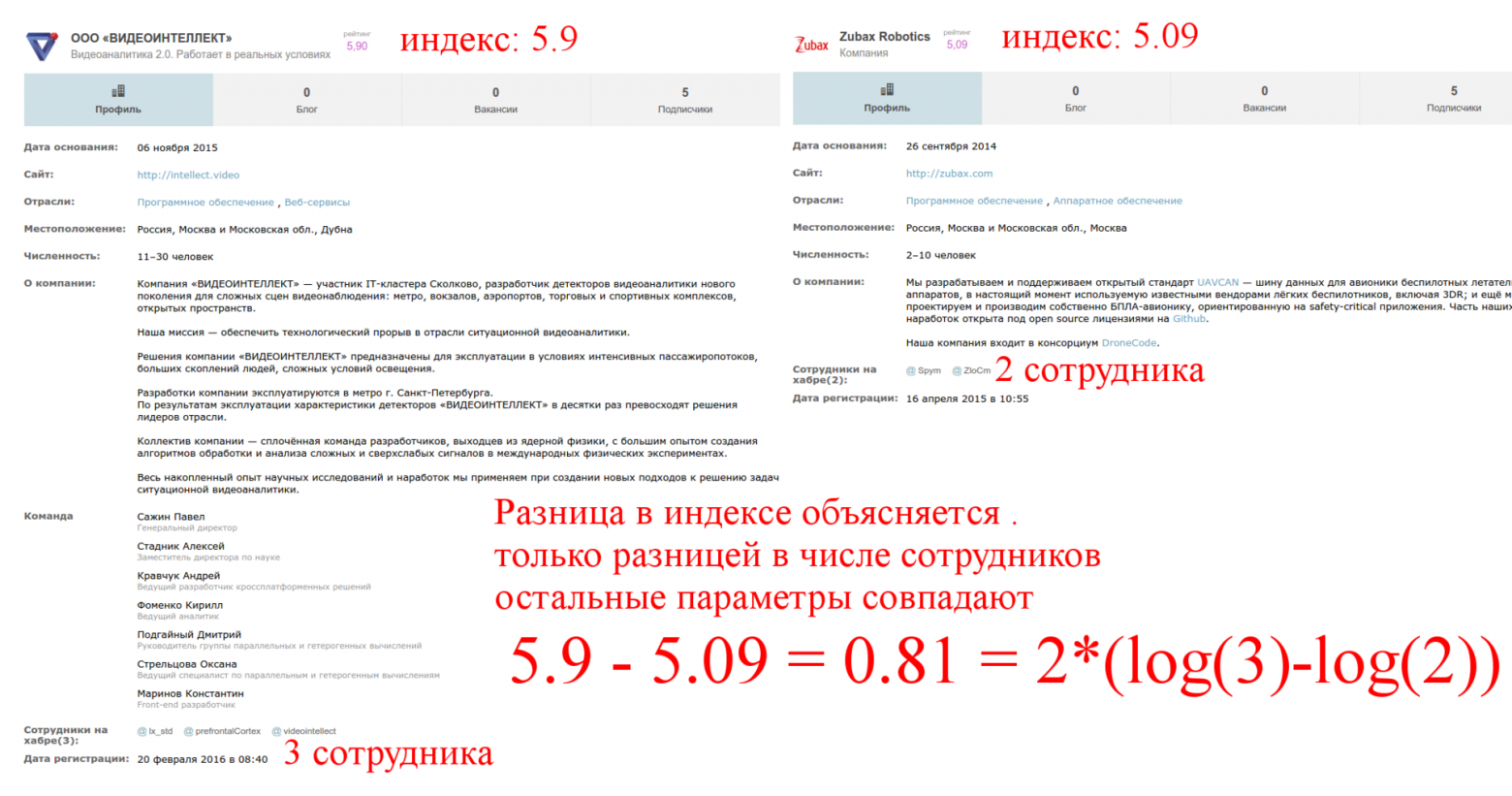
Второй фактор: логарифм числа сотрудников. Опять же это логично, нельзя, чтобы наличие сотрудников доминировало над статьями. Причём, множитель перед логарифмом тоже зависит от других параметров.
Формула приобретает вид:

Плюсы за старые статьи (~ больше месяца) влияния на рейтинг не оказывают:
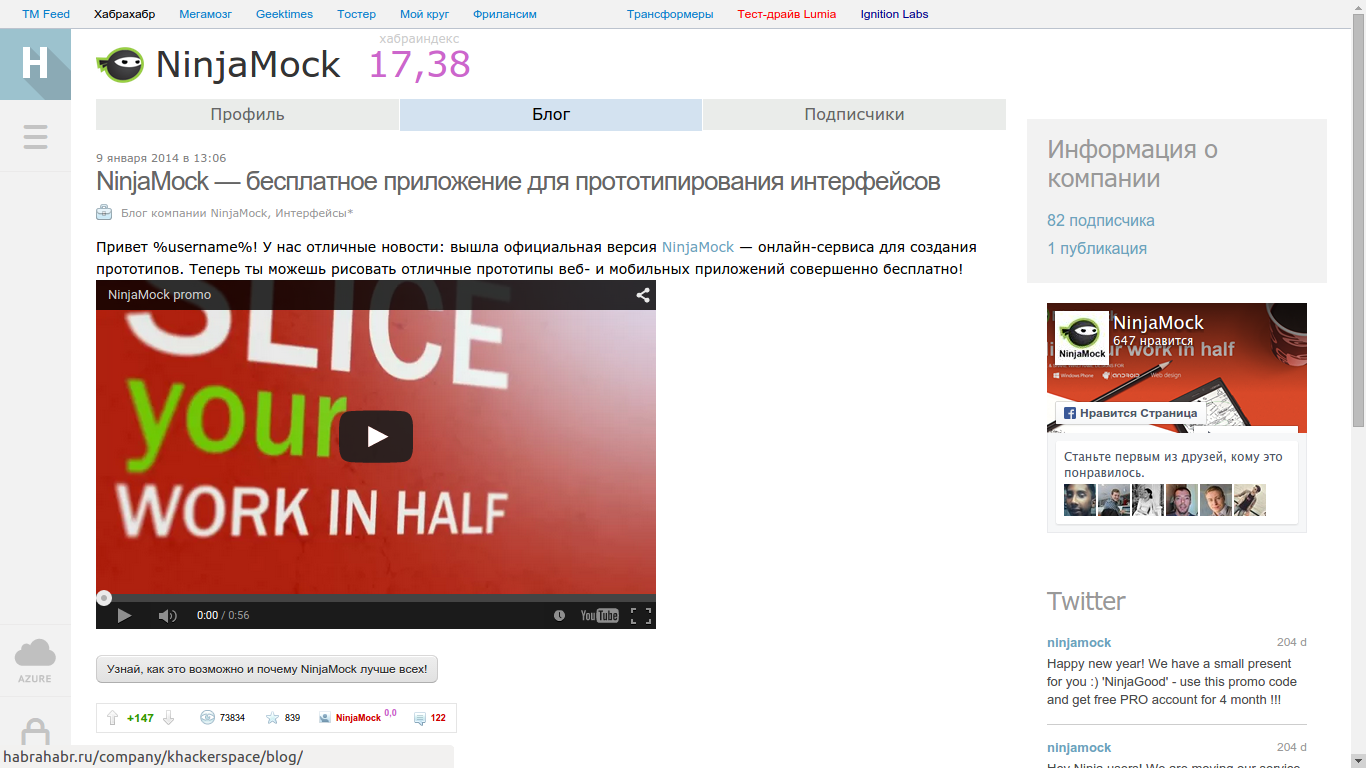
Как мы видим старые статьи, даже в большом плюсе влияния не оказывают
Важнейшим условием применения нейросетей является наличие существенного объема данных, в котором "сигнал сильнее шума", причем пространство фич должно быть соотвествующим. То есть даже если у нас было много шумовых точек, имеющиеся закономерности бы определились сквозь шум. Как можно заметить, у нас фактически нет данных вообще, тем более явно демонстрирующих закономерности. А пространство особенностей небольшое и имеет какую-то несложную структуру (практически факторизуется). Таким образом Q2 подсказывает нам, что не стоит применять нейросети, если у вас нет большого количества адекватно размеченных данных.
Вывод: данные необходимо откуда-то достать. Пусть и в очень небольших количествах, но они нужны для точного формирования гипотез.
Где можно достать качественные исторические данные, когда их нет? Internet Time Machine!
Например, определяем, что временная константа для рейтинга корпоративных блогов порядка месяца, заглянув в историю компании:
http://web.archive.org/web/20151220201116/http://habrahabr.ru/company/oda/
Также мы хотим понять, как влияют плюсы к статьям. Для этого нам нужно узнать рейтинг компании сразу после того, как плюсы за статьи перестают учитываться — найти такие данные среди имеющихся в списке компаний фактически невозможно, так как должны совпасть практически все параметры, кроме плюсов к статье.

Таким образом формула принимает вид:

Причем, если мы произведем анализ рейтинга до появления поста и после, мы поймём, что если у компании есть хотя бы один пост, то рейтинг от подписчиков и работников увеличивается втрое и коэффициенты имеют следующий вид:

Заметим, что оценка коэффициента линейного члена примерная, но нам скорее важен сам характер зависимости, нежели абсолютно точное значение коэффициента.
Для анализа данного эффекта нужно собрать столь нетривиальные данные, что тут даже Машина Времени Интернета бессильна. Но не будем отчаиваться, у меня как раз оказался доступ к панели управления одной компании и там виден рейтинг во времени:

Эти точки соотвествуют моменту, когда у меня поднялся рейтинг от других статей. Значит рейтинг работников влияет на Хабра-индекс, анализ показывает, что снова логарифмически, с коэффициентом примерно равным 9:

Эффект от кармы сотрудников мы замеряем следующим образом, мы знаем, что посты Мосигры написаны одним человеком и карма им получена именно на этих постах, поэтому я замерил показатели в тот момент, когда у них не было активных статей (что было совсем не тривиально) и получил следующее:
Карма автора составляла порядка ~850, отсюда зависимость от кармы полученной на этих постах также логарифмическая с коэффициентом примерно равным ~3.
Как можно заметить, собиралась также информация по размеру компании. Воздействие размера компании на индекс получилось нулевым.

Отсюда видно, что рост также логарифмический по рейтингу подписчиков, причем коэффициент равный трём, наблюдаемый ранее при наличии статей, появляется и здесь:

Отсюда, формула для случая с публикациями имеет вид:

Причем коэффициент перед большой скобкой (где сумма всех логарифмов) равен 3, если у компании есть публикации и 1 если нет. Плюсы к постам считаются так же, как и плюсы к постам пользователей (то есть держатся в течении 30 дней).
При беглом просмотре статьи может показаться, что сбор данных — это исключительно второстепенный шаг. На самом деле, это фактически ключевой шаг в решении задачи, он позволил существенно сузить пространство гипотез и избавиться от второстепенных факторов, не влияющих на индекс.
Именно данных от Internet Time Machine и панели временного ряда компании мне не хватило, когда предпринял первую попытку анализа зависимости Хабра-индекса (~ в августе 2015го), чтобы вывести ключевые факторы. Например, взаимодействие параметров: коэффициент, зависящий от наличия статей, влияет сразу на группу параметров.
Краткий список важных пунктов, по которым можно распознать, что задача может быть потенциально решена нейросетями:
В разобранной нами задаче ни одно из этих условий не выполнено.
Имея формулу с основными факторами, определяющими Хабра-индекс, мы можем ответить на вопрос Q3 — оценить эффективность различных стратегий ведения блога.
Важное наблюдение: линейный член легко мажорирует остальные логарифмические члены, даже при небольших значениях порядка +10. Нужно иметь 25 тысяч подписчиков, чтобы получить эффект сходный с одной статьёй в 10 плюсов (или зарегистрировать 150 сотрудников). Эффекта статьи от +20 одними подписчиками получить фактически невозможно.
Стратегия первая: регулярно писать много маленьких статей на ~+10, например каждую неделю. Тогда, рейтинг компании получает плюс ~ 3*5*10 ~= 150 и легко проходит на первую страницу, при условии, что остальные параметры имеют хоть сколько-нибудь реалистичные значение (например, 5 сотрудников и 100 подписчиков): данная стратегия достаточна эффективна, см. стратегию Microsoft, который сейчас на первом месте по рейтингу. Стратегия выглядит разумной, если вы большая компания и у вас много инфоповодов.
Стратегия вторая: писать одну-две вдумчивые статьи в месяц на 50-100 плюсов. Вы гарантировано попадаете в топ и первую страницу компаний. Минус стратегии — писать статьи такого качества в таком количестве невероятно сложно. С этим, например, справляются в Мосигре, см. визуализацию ниже.
Попытки накрутить подписчиков особо эффективной стратегией не являются, так как логарифм быстро выходит на константу (для любых разумных значений числа подписчиков). Зарегистрировать всех работников в блоге имеет смысл, но также имеет исключительно ограниченный эффект, даже у Яндекса, у которого здесь 577 сотрудников, эффект сравним с одной "постоянной" статьёй на +12-13.
И сегодня мы займёмся совмещением приятного с полезным: разберём интересную (практическую) аналитическую задачу и заодно проанализируем ряд факторов, определяющих (не-)применимость нейронных сетей к аналитическим задачам.
Представьте, вы работаете аналитиком в какой-нибудь компании, которой важен её облик на Хабре (условно назовём её Почта.com). И тут к вам приходит девушка из PR-отдела и говорит: "Мы с менеджерами определили в качестве важного KPI нашего бренда Хабра-рейтинг компании. У нас есть бюджет и мы хотим понять, как его распределить, чтобы максимизировать Хабра-индекс. Нам нужно, чтобы ты определил ключевые факторы, которые на него влияют и вывел наиболее разумную стратегию. Попробуй там какие-нибудь нейросети".
Во время этой речи у вас начинает дергаться глаз, но спустя пару минут составляете список вопросов для анализа:
- Q1: Какие ключевые факторы влияют на Хабра-индекс компании?
- Q2: Где найти данные?
- Q3: Какой будет оптимальная стратегия согласно восстановленной эмпирической зависимости?
Структура статьи
- Определяем потенциальные факторы
- Сбор данных
- Эффект кармы и рейтинга подписчиков и работников
- Финальная формула
- Анализ применимости нейросетей
- Анализ оптимальной стратегии
Желтый оффтопик: нешуточные страсти вокруг Хабра-блогов компаний
Иногда разворачиваются целые дебаты по поводу того, как нужно везти корпоративные блоги, например вот такое старое обсуждение.
Изначальный комментарий:
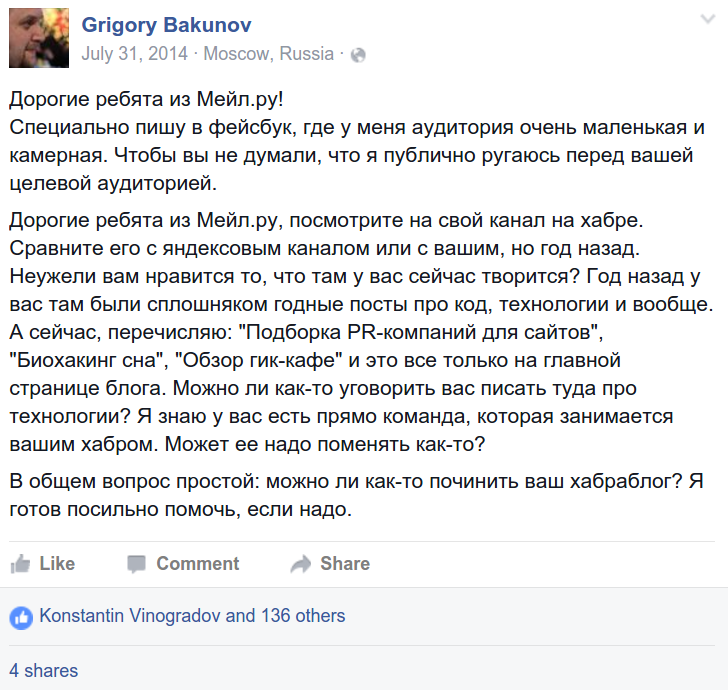
И ответ (отсюда):

Вообще, серьёзность подхода видна уже по презентациям компании на тему:

Изначальный комментарий:
И ответ (отсюда):
Вообще, серьёзность подхода видна уже по презентациям компании на тему:
Определяем потенциальные факторы
Если взглянуть на профиль компании, то в глаза бросаются следующие возможные кандидаты:

Причем параметры могут состоять из целой группы переменных: карма и рейтинг сотрудников, количество просмотров, избранного, плюсов у статей, а также их количество, etc.
И тут самый интересный момент: feature construction, а что собственно является фактором определяющим Хабра-индекс? И почему это столь важно? Например, чтобы алгоритм машинного обучения "выучил" настоящую исходную функцию, нужно чтобы исходная функция была определена в правильном пространстве, которого у нас нет!
В некотором смысле это порочный круг — нужно знать, что пространство (или подпространство) содержит ключевые факторы, чтобы восстановить зависимость. Но в данной ситуации, если известны ключевые факторы (или их надмножество), то задача фактически решена.
Верное представление пространства характеристик (feature space)
Чуть более формально, это можно описать так: локальные закономерности присутствуют в нашем представлении данных, то есть у нас "верное представление" всех параметров функции, которую мы хотим выучить. Если настоящая функция f(X,Y,Z), а в нашем представлении есть только X и Y, то мы ищем функцию в заведомо неверном классе F(X,Y), не учитывающем Z. Этим реальные задачи существенно отличаются от Kaggle, нам ничего не дано.
Научный метод тыка
Как определить, что фактор важен? Мы знаем, что зависимость детерминированная, то есть есть некоторая аналитическая функция, по которой ТМ однозначно считает индекс. Обозначим, функцию индекса за f, тогда f зависит от фактора xi, тогда и только тогда когда для любых xi верно что:

и с мы будем называть величиной эффекта.
Данное определение не предполагает независимости между переменными. Если переменные зависимы, значит, что c для i-го фактора может меняться в зависимости от остальных переменных.
Также мы знаем, из нашего опыта, что функция обязана удовлетворять граничному условию:
Важный момент: интеграция сильных априорных представлений о том, какой должна быть функция в нейронные сети — задача совершенно нетривиальная.
Таким образом ключевое наблюдение в вопросе Q1: необходимо адекватным образом трансформировать данные из профиля компании (например, перечисленные выше) и произвести замер эффекта, по одному удаляя искажающие факторы (confounding variables). Также необходимо будет проверить условие факторизации, то есть, что переменные независимы друг от друга:

Сбор данных
Отправляемся по адресу: https://habrahabr.ru/companies/ на самую последнюю страницу и видим, ценнейший материал:
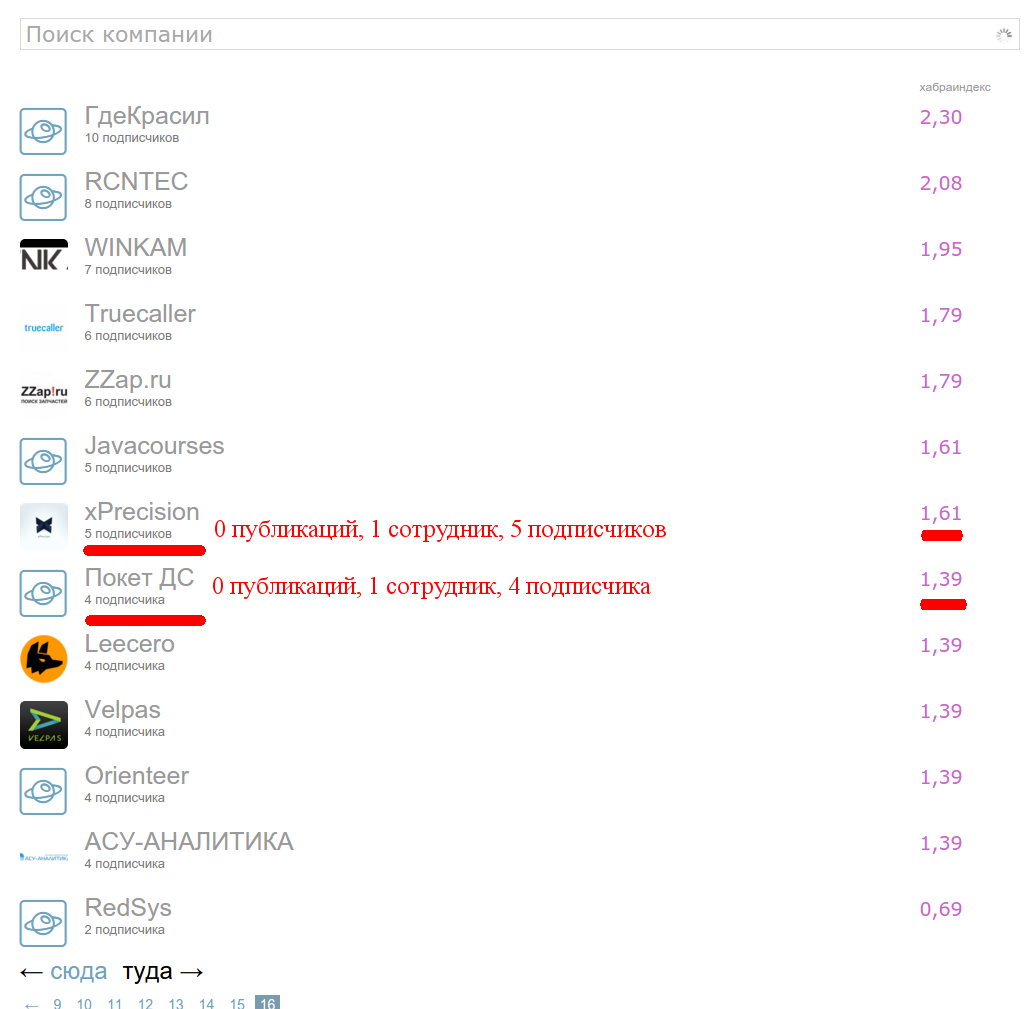
Подписчики
Это набор компаний, с нулём публикаций и небольшим числом сотрудников (один-два) и небольшим числом подписчиков. Выбрав две компании — xPrecision и Покет ДС с одинаковым числом сотрудников и разницей в одного подписчика, мы нашли ненулевую разницу в Хабра-индексе.
Бинго: первый фактор определяющий Хабра-индекс число подписчиков! Заметим, что рост явно не линейный — достаточно взглянуть на компании в начале, середине и конце списка. Логично, что функция должна насыщаться при достаточном числе подписчиков, чтобы не было накруток и вообще фактор подписчиков не доминировал сами статьи. Значит функция, должна расти медленно и в какой-то момент выходить почти на константу. Хм, логарифм!
log(2) = 0.69
log(4) = 1.39
log(5) = 1.61
.....
Итого, убеждаемся, что функция имеет вид:
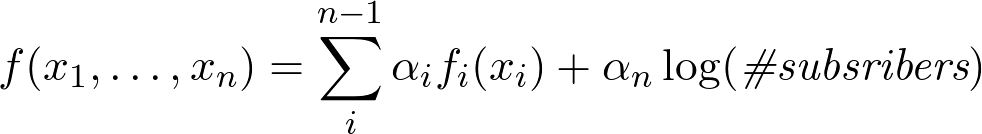
Заметим, что функция не зависит от кармы подписчиков, так как log(8) = 2.08:
Причем коэффициент равен 1, если у компании нет публикаций, и равен 3, если есть (как показал дальнейший анализ).
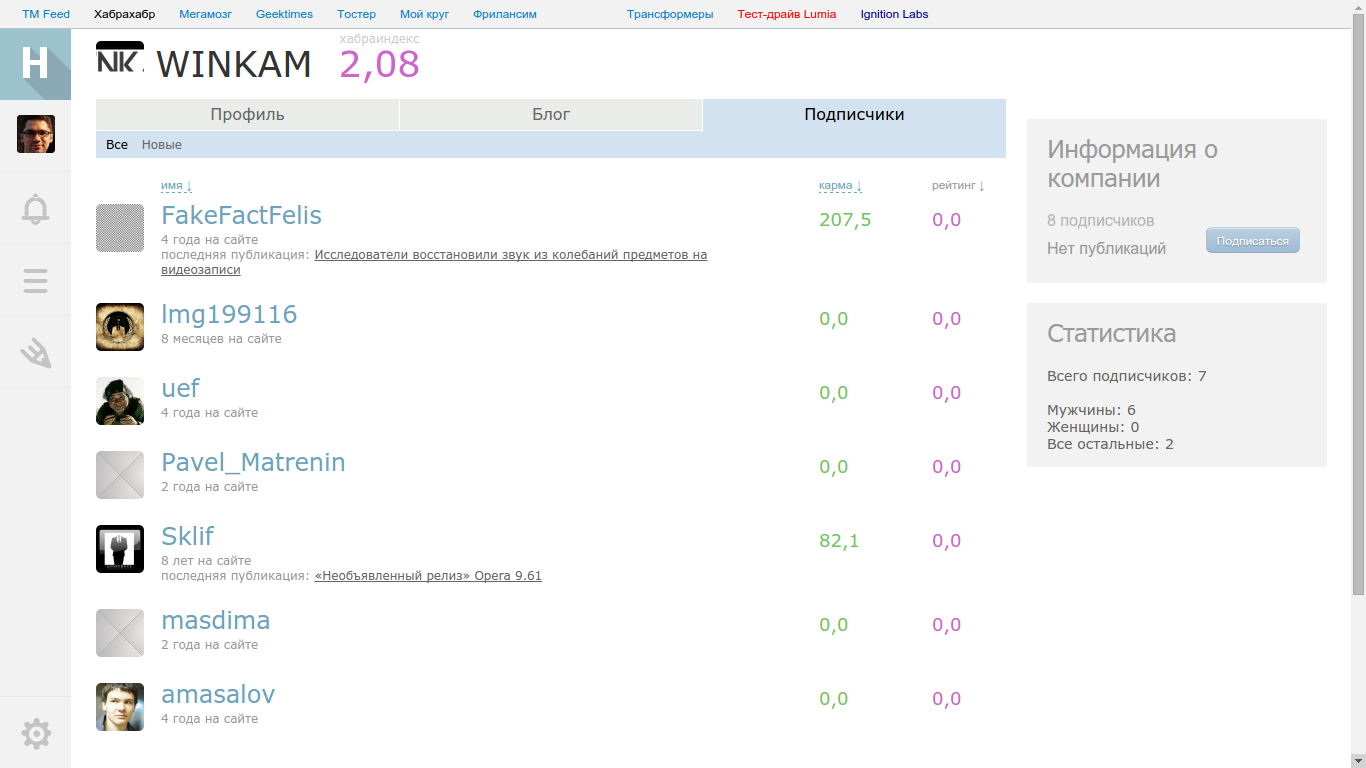
Сотрудники
Рассмотрим 15ую страницу и возьмем две компании с одинаковым числом подписчиков и разным числом сотрудников:
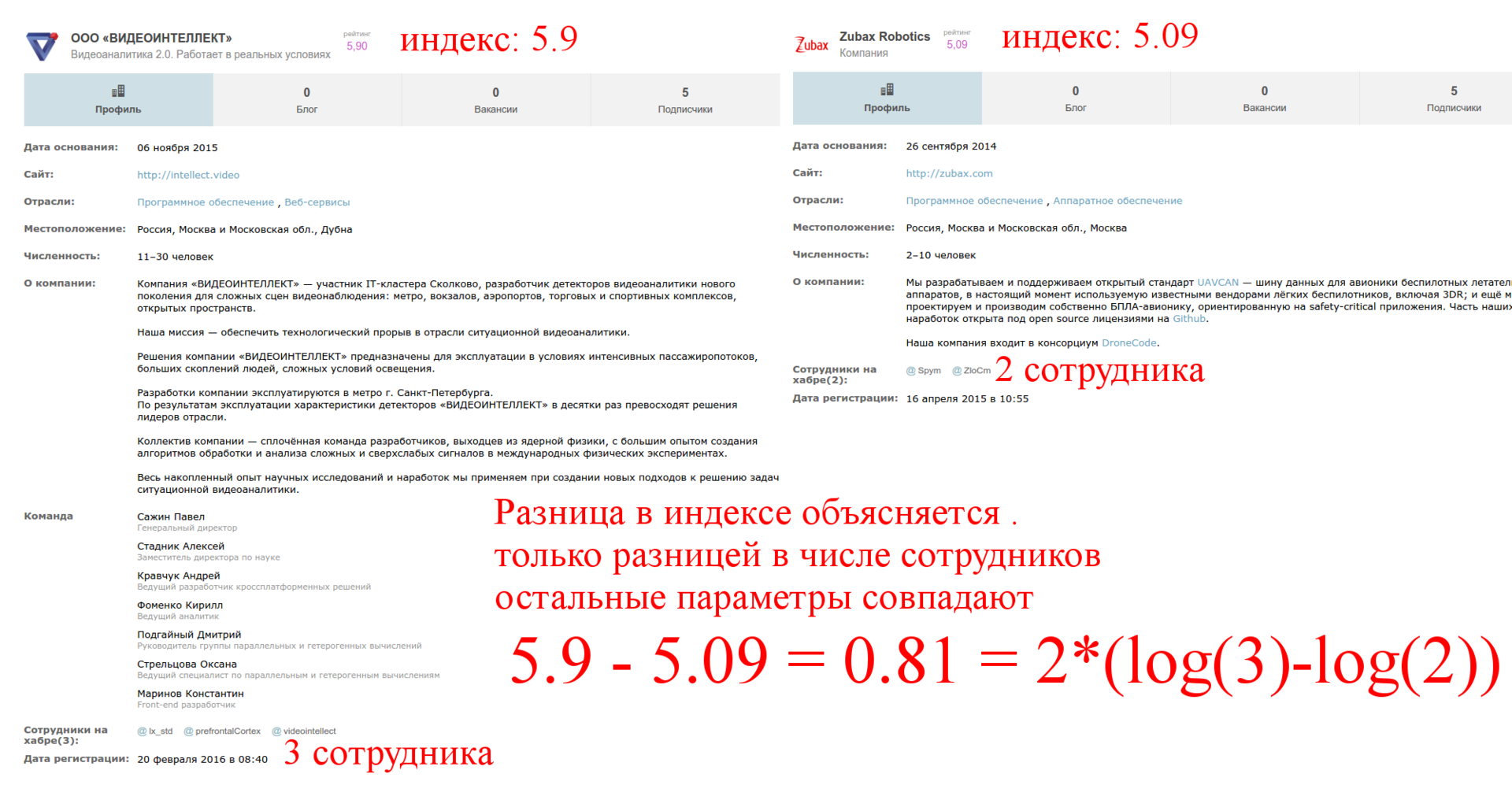
Второй фактор: логарифм числа сотрудников. Опять же это логично, нельзя, чтобы наличие сотрудников доминировало над статьями. Причём, множитель перед логарифмом тоже зависит от других параметров.
Формула приобретает вид:
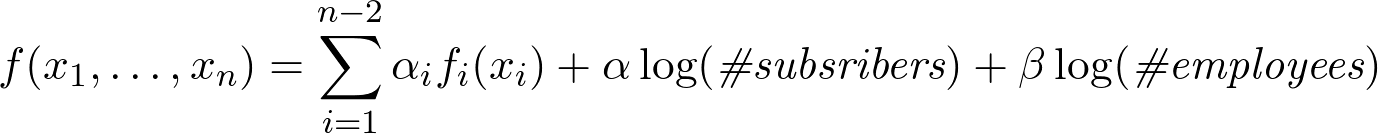
Влияние старых заслуг (по статьям)
Плюсы за старые статьи (~ больше месяца) влияния на рейтинг не оказывают:
Как мы видим старые статьи, даже в большом плюсе влияния не оказывают
Нехватка данных
Важнейшим условием применения нейросетей является наличие существенного объема данных, в котором "сигнал сильнее шума", причем пространство фич должно быть соотвествующим. То есть даже если у нас было много шумовых точек, имеющиеся закономерности бы определились сквозь шум. Как можно заметить, у нас фактически нет данных вообще, тем более явно демонстрирующих закономерности. А пространство особенностей небольшое и имеет какую-то несложную структуру (практически факторизуется). Таким образом Q2 подсказывает нам, что не стоит применять нейросети, если у вас нет большого количества адекватно размеченных данных.
Вывод: данные необходимо откуда-то достать. Пусть и в очень небольших количествах, но они нужны для точного формирования гипотез.
Где можно достать качественные исторические данные, когда их нет? Internet Time Machine!
Например, определяем, что временная константа для рейтинга корпоративных блогов порядка месяца, заглянув в историю компании:
http://web.archive.org/web/20151220201116/http://habrahabr.ru/company/oda/
Также мы хотим понять, как влияют плюсы к статьям. Для этого нам нужно узнать рейтинг компании сразу после того, как плюсы за статьи перестают учитываться — найти такие данные среди имеющихся в списке компаний фактически невозможно, так как должны совпасть практически все параметры, кроме плюсов к статье.
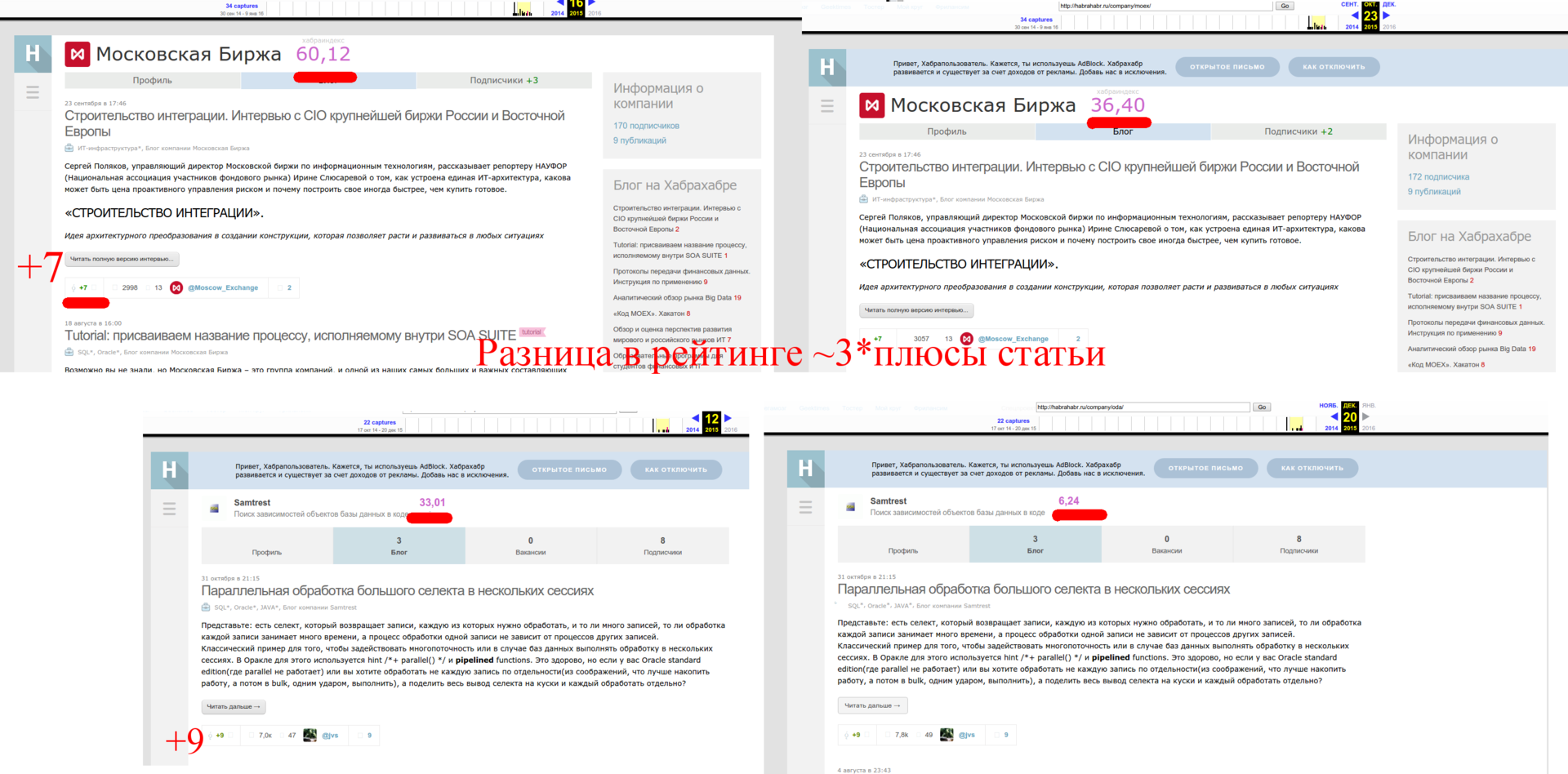
Таким образом формула принимает вид:
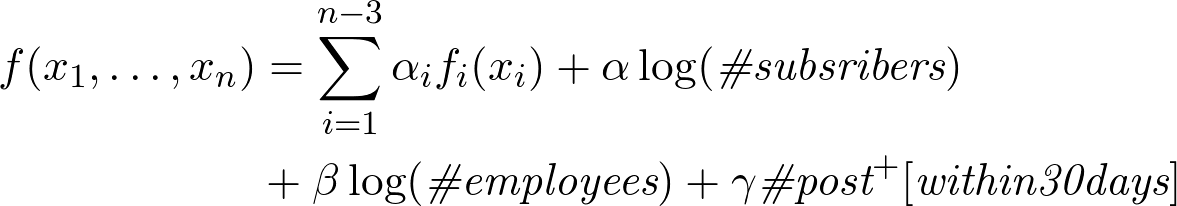
Причем, если мы произведем анализ рейтинга до появления поста и после, мы поймём, что если у компании есть хотя бы один пост, то рейтинг от подписчиков и работников увеличивается втрое и коэффициенты имеют следующий вид:

Заметим, что оценка коэффициента линейного члена примерная, но нам скорее важен сам характер зависимости, нежели абсолютно точное значение коэффициента.
Определяем эффект кармы и рейтинга подписчиков и работников
Рейтинг сотрудника
Для анализа данного эффекта нужно собрать столь нетривиальные данные, что тут даже Машина Времени Интернета бессильна. Но не будем отчаиваться, у меня как раз оказался доступ к панели управления одной компании и там виден рейтинг во времени:
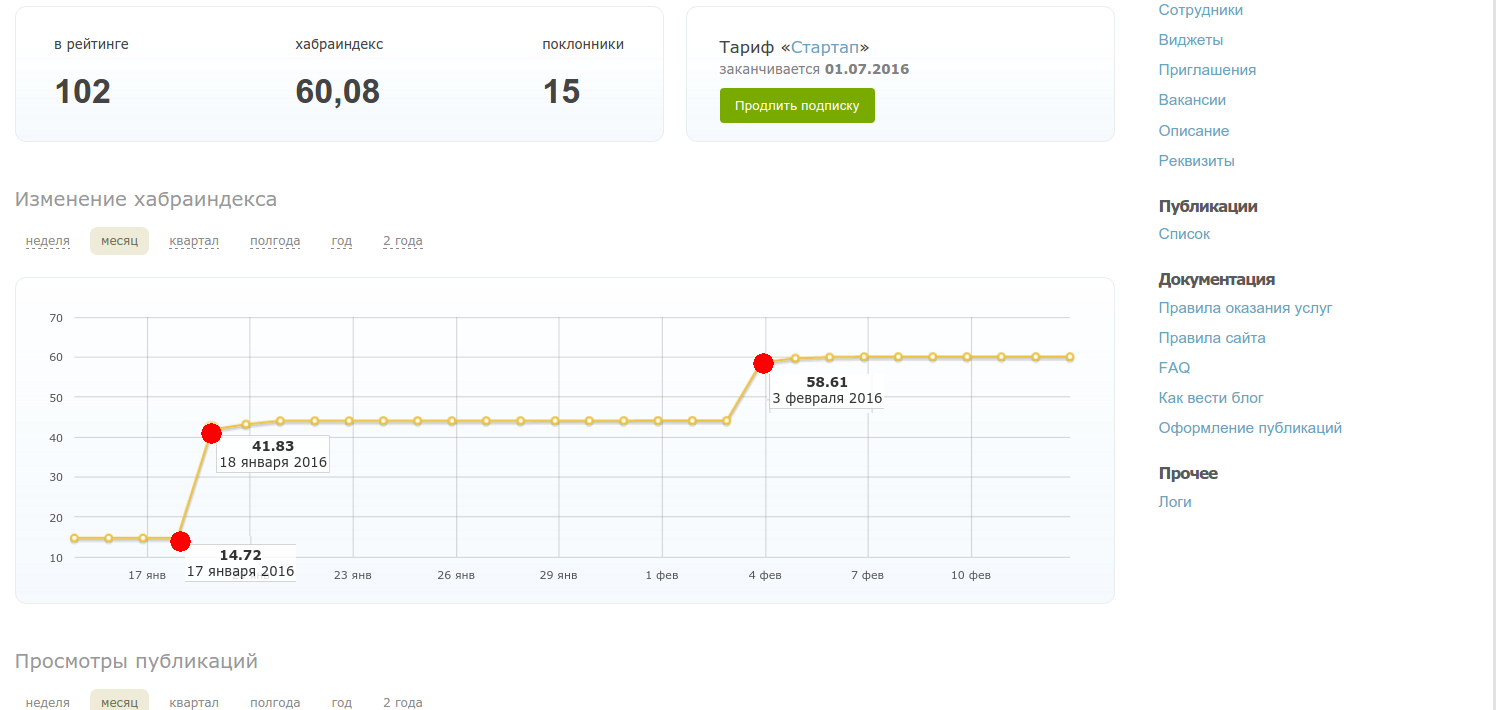
Эти точки соотвествуют моменту, когда у меня поднялся рейтинг от других статей. Значит рейтинг работников влияет на Хабра-индекс, анализ показывает, что снова логарифмически, с коэффициентом примерно равным 9:
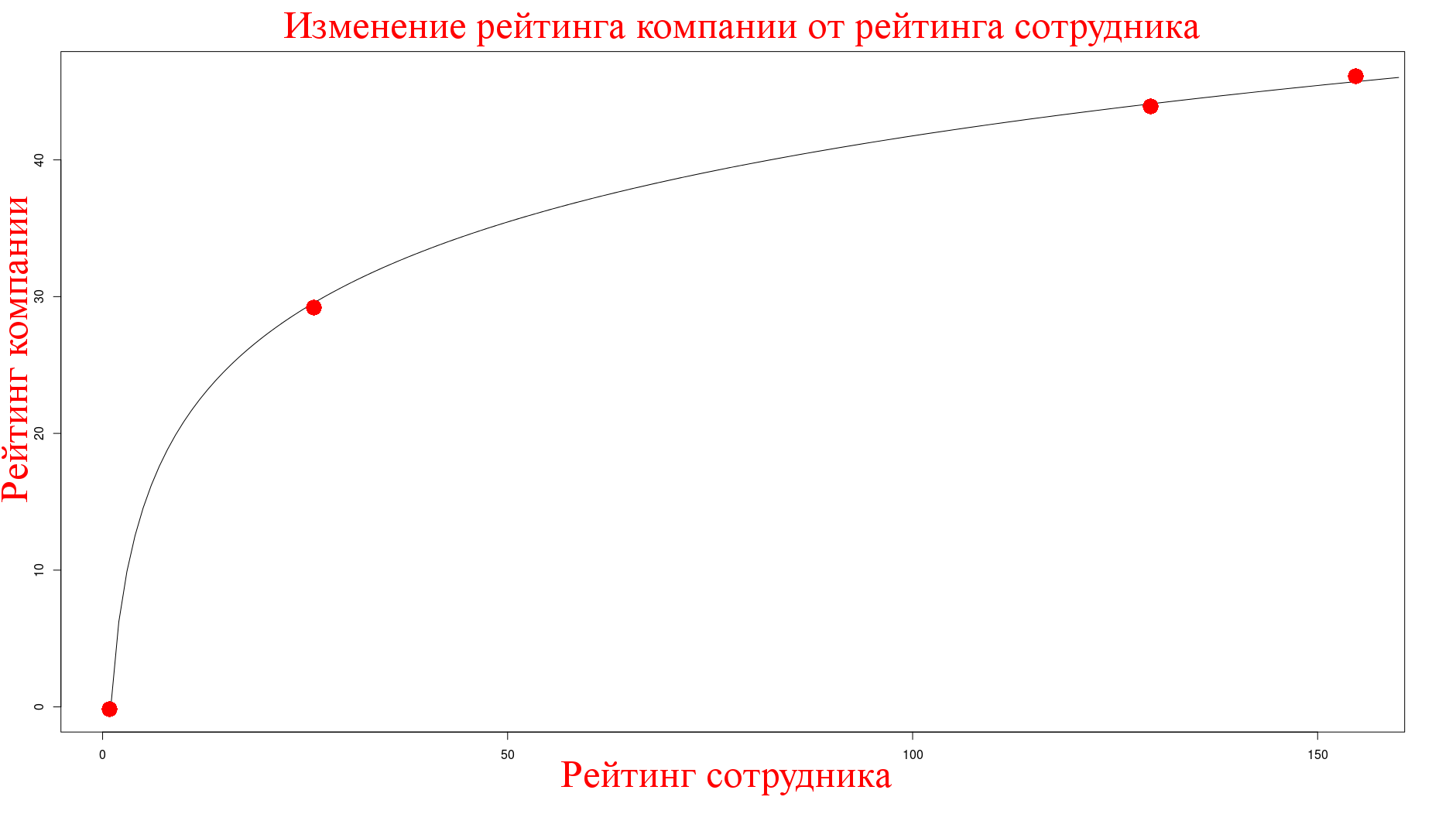
Карма сотрудников, полученная на корпоративных постах
Эффект от кармы сотрудников мы замеряем следующим образом, мы знаем, что посты Мосигры написаны одним человеком и карма им получена именно на этих постах, поэтому я замерил показатели в тот момент, когда у них не было активных статей (что было совсем не тривиально) и получил следующее:
name,blog,employees,subscribers,rating,size
.....
mos_igra,115,10,4877,59.48,101_200Карма автора составляла порядка ~850, отсюда зависимость от кармы полученной на этих постах также логарифмическая с коэффициентом примерно равным ~3.
Как можно заметить, собиралась также информация по размеру компании. Воздействие размера компании на индекс получилось нулевым.
Рейтинг подписчиков

Отсюда видно, что рост также логарифмический по рейтингу подписчиков, причем коэффициент равный трём, наблюдаемый ранее при наличии статей, появляется и здесь:

Финальная формула
Отсюда, формула для случая с публикациями имеет вид:
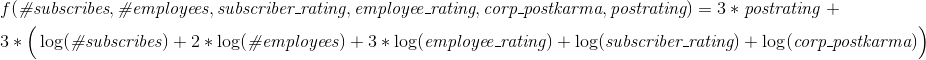
Причем коэффициент перед большой скобкой (где сумма всех логарифмов) равен 3, если у компании есть публикации и 1 если нет. Плюсы к постам считаются так же, как и плюсы к постам пользователей (то есть держатся в течении 30 дней).
О важности сбора качественных данных
При беглом просмотре статьи может показаться, что сбор данных — это исключительно второстепенный шаг. На самом деле, это фактически ключевой шаг в решении задачи, он позволил существенно сузить пространство гипотез и избавиться от второстепенных факторов, не влияющих на индекс.
Именно данных от Internet Time Machine и панели временного ряда компании мне не хватило, когда предпринял первую попытку анализа зависимости Хабра-индекса (~ в августе 2015го), чтобы вывести ключевые факторы. Например, взаимодействие параметров: коэффициент, зависящий от наличия статей, влияет сразу на группу параметров.
Анализ применимости нейросетей
Краткий список важных пунктов, по которым можно распознать, что задача может быть потенциально решена нейросетями:
- Имеется собранный (размеченный) датасет, существенного размера (тот в котором явно "сигнал сильнее шума*)
- Пространство особенностей существенного размера (представьте, что каждый пиксель вместе с цветом на картинке — это одна входная особенность, а также комбинация и суперпозиция, совокупно речь идет о 1M+ параметров модели)
- Особенности и закономерности имеют иерархическую структуру — представьте анализ цифр: точки собираются в прямые, комбинация прямых в закорючку, закорючки в циферку (упрощенно можно думать о сети, как о некотором сжимающем отображении)
- Отсутствуют существенные априорные представления о характере зависимости, если мы знаем, что зависимость линейная (квадратичная, сезонная, вообще не слишком варирующаяся функция), то возможно стоит сразу искать решения в этом классе
- Не требуется анализ полученной зависимости. Когда мы хотим получить черный ящик предсказывающий действия — это вполне неплохое решение — "вот этот ход в ГО интуитивно хорош", но если нам требуется произвести анализ зависимости, то это превращается в случае нейросетей в совершенно нетривиальную задачу (например, см. вот эту статью)
В разобранной нами задаче ни одно из этих условий не выполнено.
Всё-таки при чём здесь таблетки для похудения?
Это не более чем аллюзия к "магической пилюле", которая придет на помощь и решит проблему. Соль в том, что в реальной жизни задачи многогранны и не решаются одним универсальным молотком, а требуют анализа и выбора правильного инструмента. Даже если симптомы в двух случаях совпадают, причинно-следственная связь может быть различной и может потребовать двух совершенно разных решений.
Иначе, всё это начинает напоминать подход кальсонных гномов

Иначе, всё это начинает напоминать подход кальсонных гномов
Анализ оптимальной стратегии
Имея формулу с основными факторами, определяющими Хабра-индекс, мы можем ответить на вопрос Q3 — оценить эффективность различных стратегий ведения блога.
Важное наблюдение: линейный член легко мажорирует остальные логарифмические члены, даже при небольших значениях порядка +10. Нужно иметь 25 тысяч подписчиков, чтобы получить эффект сходный с одной статьёй в 10 плюсов (или зарегистрировать 150 сотрудников). Эффекта статьи от +20 одними подписчиками получить фактически невозможно.
Стратегия первая: регулярно писать много маленьких статей на ~+10, например каждую неделю. Тогда, рейтинг компании получает плюс ~ 3*5*10 ~= 150 и легко проходит на первую страницу, при условии, что остальные параметры имеют хоть сколько-нибудь реалистичные значение (например, 5 сотрудников и 100 подписчиков): данная стратегия достаточна эффективна, см. стратегию Microsoft, который сейчас на первом месте по рейтингу. Стратегия выглядит разумной, если вы большая компания и у вас много инфоповодов.
Стратегия первая: несколько небольших статей

Стратегия вторая: писать одну-две вдумчивые статьи в месяц на 50-100 плюсов. Вы гарантировано попадаете в топ и первую страницу компаний. Минус стратегии — писать статьи такого качества в таком количестве невероятно сложно. С этим, например, справляются в Мосигре, см. визуализацию ниже.
Стратегия вторая: одна-две развёрнутые статьи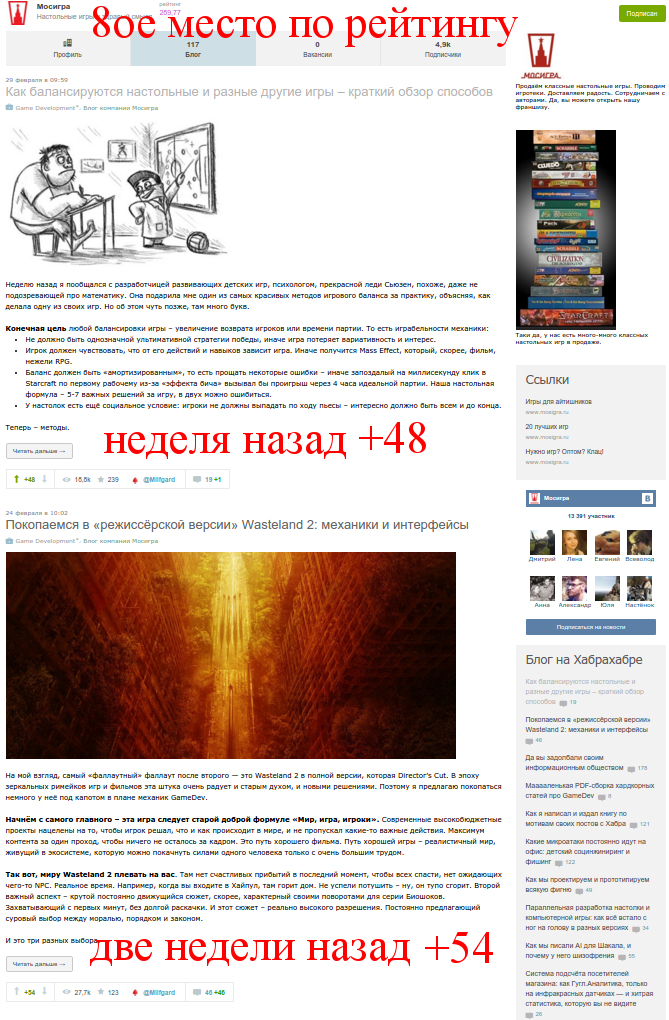

Попытки накрутить подписчиков особо эффективной стратегией не являются, так как логарифм быстро выходит на константу (для любых разумных значений числа подписчиков). Зарегистрировать всех работников в блоге имеет смысл, но также имеет исключительно ограниченный эффект, даже у Яндекса, у которого здесь 577 сотрудников, эффект сравним с одной "постоянной" статьёй на +12-13.
