Comments 32
1С показывает любое количество записей в гриде, позволяет мгновенно перемещаться по нему в начало или конец, искать по первым буквам в любой колонке, курсор со строки никуда не девается и не перескакивает.
Насколько "любое"? Пару млн потянет? Открывается мгновенно при этом?
И работает там это именно через получение N записей на указанном смещении. Нормальная полоса прокрутки там отображается только когда вся таблица уже загружена в память (читай: БД не используется, документ открывается долго, но зато потом все летает). А при отображении списков объектов из БД полоса прокрутки понимает только три положения: «мы в самом начале», «мы в самом конце» и «мы непонятно где» (бегунок тупо зафиксирован на 50%) — при этом тормоза при подгрузке очередной порции данных из БД при очень больших таблицах весьма ощутимы.
В плане тематики статьи меня восхищают поисковые системы: они умудряются отрабатывать сложносочиненные запросы к базам в сотни терабайт, выдавая данные по указанному смещению. Причем смещения 20 и 1000020 отрабатываются одинаково быстро, явно безо всяких кеширований!
В плане тематики статьи меня восхищают поисковые системы: они умудряются отрабатывать сложносочиненные запросы к базам в сотни терабайт, выдавая данные по указанному смещению. Причем смещения 20 и 1000020 отрабатываются одинаково быстро, явно безо всяких кеширований!
Странно. В веб-версии, по крайней мере визуально, складывается ощущение, что подгрузка данных идет по значению сортировочных полей, а не по смещению. В этом случае даже на многомиллионных таблицах задержек быть не должно. При случае посмотрю под профайлером, что там творит 1С с запросами. Но в любом случае отсутствие бегунка — это ну слишком грубо для такого программного продукта, которым пользуется пол страны (если не больше).
Еще чуть подправлю. Поисковики обычно не отрабатывают смещение в 1000020. И не показывают, сколько записей соответствует запросу. Это исключительно затратные операции. Поисковики только последовательно отображают записи, соответствующие запросу. Это быстрые операции. Именно поэтому поисковики не тормозят.
Еще чуть подправлю. Поисковики обычно не отрабатывают смещение в 1000020. И не показывают, сколько записей соответствует запросу. Это исключительно затратные операции. Поисковики только последовательно отображают записи, соответствующие запросу. Это быстрые операции. Именно поэтому поисковики не тормозят.
Дискуссия об 1С — очень интересный результат статьи. Я абсолютно не учитывал, что от бегунка можно вообще отказаться.
Поэтому вопрос хочется исследовать до конца. Укажите, пожалуйста, о какой версии платформы 1С идет речь. Мы только что выяснили, что по крайней мере в 1С версии 8.2 (web-клиент) и в некоторых последующих версиях полоса прокрутки вообще не используется. Это и объясняет высокую скорость работы. И подтормаживания здесь быть не должно ни на 130 миллионах записей, ни на 130 миллиардах. Если база данных держит такую таблицу (это уже больше аппаратный вопрос), значит и считывание записей по ключевым полям не может тормозить. Возможно, в разных версиях 1С реализован разный алгоритм работы с СУБД.
А курсор сам по себе к производительности добавить ничего не может. Разве что кэшировать определенные данные. Дело курсора — слать правильные (быстрые, ресурсосберегающие) запросы к БД и обеспечивать удобство разработчика.
И насчет предков, Вы даже не представляете сколько людей не умеют правильно работать с СУБД. Не простая это вещь. Так что не "забытая", а недоступная для понимания скорее.
Поэтому вопрос хочется исследовать до конца. Укажите, пожалуйста, о какой версии платформы 1С идет речь. Мы только что выяснили, что по крайней мере в 1С версии 8.2 (web-клиент) и в некоторых последующих версиях полоса прокрутки вообще не используется. Это и объясняет высокую скорость работы. И подтормаживания здесь быть не должно ни на 130 миллионах записей, ни на 130 миллиардах. Если база данных держит такую таблицу (это уже больше аппаратный вопрос), значит и считывание записей по ключевым полям не может тормозить. Возможно, в разных версиях 1С реализован разный алгоритм работы с СУБД.
А курсор сам по себе к производительности добавить ничего не может. Разве что кэшировать определенные данные. Дело курсора — слать правильные (быстрые, ресурсосберегающие) запросы к БД и обеспечивать удобство разработчика.
И насчет предков, Вы даже не представляете сколько людей не умеют правильно работать с СУБД. Не простая это вещь. Так что не "забытая", а недоступная для понимания скорее.
Как работает гугл при отображении картинок можно примерно догадаться, подергав интерфейс. При загрузке страницы данных (для поиска картинок их всего две, вторую можно открыть, промотав до конца первую) из базы данных начинается последовательное вытягивание ссылок на картинки, которые попадают в экранную область. Далее подгружаются сами картинки. На этом гугл пока останавливает работу с сервером. Если далее промотать сразу до конца страницы, то последовательно догружаются остальные ссылки на картинки. Именно последовательно, без перепрыгиваний (иначе быть не может: так работают СУБД — в данном случае очень специфическая но все же СУБД — почему так, поясняется в начале статьи). Это хорошо видно, т.к. гугл, в при резком переходе виснет на несколько секунд. И, даже если потом быстро промотать страницу наверх, мы увидим что все серые квадраты под картинки отображаются мгновенно и соответствуют размерам еще незагруженных картинок. При этом, хотя ссылки все уже подгружены, сами картинки загружаются только те, что попадают в экранную область (с зазором). Это уже к работе с базой данных не имеет отношения, а делается для экономии канала передачи данных.
Возможно, там еще какие-то хитрости применены, но, думаю, примерно алгоритм описан верно.
Возможно, там еще какие-то хитрости применены, но, думаю, примерно алгоритм описан верно.
Нехитрое в гриде без полосы прокрутки или с полосой прокрутки, максимум которой соответствует последней подгруженной записи. В статье же речь шла о том, как обеспечить полосу прокрутки, которая позволяет быстро перемещаться по всей таблице. Показано, что это можно сделать с минимальным штрафом на производительность сервера даже при работе с выборками, содержащими миллионы записей. Показано, что offset при этом лучше не применять.
- В версии 7.x, насколько я помню, 1С тянула полную таблицу. Собственно, эта была одна из причин исключительно медленной работы.
- В версии 8.2, по крайней мере в веб-реализации (см. http://trade.demo.1c.ru/trade/ru_RU/) бегунок по сути отключен.Если мы на первой записи, то бегунок в верхнем положении, если на последней — в нижнем. При выделении любой другой записи бегунок находится посередине. Я не считаю полное отключение бегунка лучшей реализацией работы с таблицей (хотя оно допустимо), поэтому об этом случае я даже не писал.
- В данном случае быстрота запросов обеспечивается тем, что мы вообще не знаем положение записи в совокупности. Мы просто получаем от СУБД записи на основании значений полей, по которым осуществляется сортировка (разумеется, по этим полям должен быть построен индекс — иначе даже 1С не поможет).
- К сожалению, отображение данных исключительно зависит от возможностей СУБД (принципиальных, а не конкретной реализации). И применение любого метода — это ряд компромиссов. В данном случае — отказ от бегунка. Интересно было бы узнать, есть ли еще продукты, кроме 1С, реализующие данный метод.
В одном из следующих релизов вообще бегунка не будет, вместо него — кнопки.
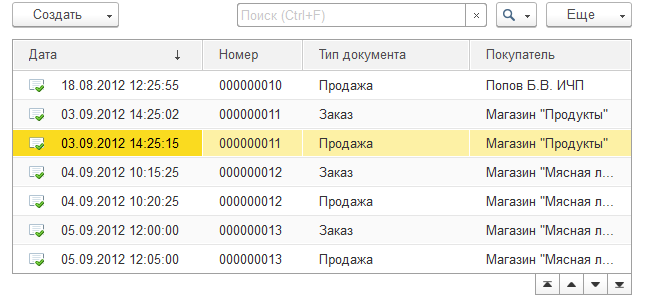
ХитрО и лаконично. Исповедовать принцип YAGNI особенно легко, когда ты монополист и на тебе сидит полстраны :-)
Спасибо за скриншот. Как раз в предыдущем посте хотел написать, что полосу прокрутки вообще бы надо в таком случае убирать. Только место занимает. Очень радикально 1С действует. Особенно учитывая то, что в данном случае можно обойтись и без радикализма. Даже если не идти на компромиссы в части производительности, хоть какую-то полосу прокрутки можно обеспечить.
Просто хотелось бы поделиться достаточно быстро отыскиваемыми примерами с js реализацией, быть может кому-то пригодится.
w2ui.com/web/blog/7/JavaScript-Grid-with-One-Million-Records
www.treegrid.com/ExamplesGantt/Html/Gantt/GanttBig.html
Они мало отражают специфику работы с БД, но наглядно показывают о чем идет речь с точки зрения больших таблиц, а не лент сообщений в соцсетях.
w2ui.com/web/blog/7/JavaScript-Grid-with-One-Million-Records
www.treegrid.com/ExamplesGantt/Html/Gantt/GanttBig.html
Они мало отражают специфику работы с БД, но наглядно показывают о чем идет речь с точки зрения больших таблиц, а не лент сообщений в соцсетях.
Лично мне кажется, что оптимальнее для небольших таблиц (до, скажем, 40 записей), загружать их на клиент сразу (вплоть до кеширования, если данные редко меняются). А для больших таблиц иметь возможность «переставить ползунок примерно на середину из миллиона записей» — очень сомнительное решение. Ну тоесть, я понимаю, что пользователи когда видят ползунок — хотят им покрутить, но по факту они осуществляют операцию фильтрации, только крайне неоптимальную. Удобнее было бы предоставить интерфейс, скажем так, «умной» фильтрации. Что бы при надобности — показывало и соседние записи. И выполняло нечеткий поиск (в том же PostgreSQL пачка функций для этого, в отличие от некоторых мелких и мягких). А скроллить массив данных более какого-то Х (думаю, не ошибусь, если предположу, что во внимание пользователя за раз врядли уместится больше 20-40 записей) — это неэффективное использование инструмента и времени. Осталось это донести пользователям :)
Скажем так, между 40 записями и одним миллионом есть 999 960 вариантов. И на 10 000 записей, а иногда и на 100 000 очень удобно пользоваться полосой прокрутки.
Идея умной фильтрации интересная. Выбираем запись и далее просим отобразить соседние. Интересно было бы посмотреть реализацию. Хотя, на вскидку, может слишком сложно для пользователя получиться. С нечетким поиском не совсем понял. Но в любом случае нечеткий поиск (пробовал в том же PostgreSQL) — вещь не быстрая.
Идея умной фильтрации интересная. Выбираем запись и далее просим отобразить соседние. Интересно было бы посмотреть реализацию. Хотя, на вскидку, может слишком сложно для пользователя получиться. С нечетким поиском не совсем понял. Но в любом случае нечеткий поиск (пробовал в том же PostgreSQL) — вещь не быстрая.
Ну да, 900 000 тысяч вариантов есть, но я же предлагаю взглянуть на проблему под другим углом. Суть задачи — пользователь ищет информацию. Смотрите сами, когда нужен скролл в повседневной жизни? Когда вы не знаете, что ищете или когда просто листаете ленту новостей/котиков. Тут скролл удобен, потому что вы не нацелены ни на что конкретное. А теперь давайте смотреть вариант, когда пользователь ищет что-то. Ведь что такое "поместить скролл примерно на середину"? Это значит, что пользователь примерно знает что хочет. Найти, скажем, Петрова в списке. Тогда поьзователь знает что примерно на середину скролла если ткнуть, то наверное +-200 записей попадет на Петрова. Тыцнул, видит, что петрова нету, начинает скроллить вверх-вниз в поисках. То есть, что такое "пользователь скроллит"? Это пользователь выполняет визуальную фильтрацию. Которая, мало всего прочего, еще и подводить может. Банально скроллил и не заметил нужную строчку. Получается, что пользователь использует некий алгоритм поиска, но он крайне неоптимален, так как человеку свойственно ошибаться, не замечать чего-то и так далее. Потому поиск информации с помощью скролла — неэффективный путь. Его может использовать только человек, который не знает (или не хочет знать) других способов, более удобных. Элементарная строка поиска, в которой пользователя не заставляют выбирать "по какому полю фильтровать. теперь введите значение", а в котором он просто вводит часть искомой информации и получает результат уже будет на голову выше, чем скроллинг в неизвестность )
Что касается реализации "отобразим соседние". Ну тут все просто. Что такое "соседние"? Это значит, что информация упорядочена по каким-то признакам и тогда мы можем определить соседние записи. Дальшк, если в лоб решать, простой запрос с юнионом: селект, который выбирает нужную запись + 2 селекта для предыдущих 5 и последующих 5 (order by asc/desc по признакам + top/limit 5).
В общем, много текста, резюмируем: суть в том, что пользователю не надо пиу-пиу-скролл. Пользователю нужна та информация, которую он пытается найти. Скроллинг в этом деле — плохой помощник. Поисковый запрос — хороший.
Что касается реализации "отобразим соседние". Ну тут все просто. Что такое "соседние"? Это значит, что информация упорядочена по каким-то признакам и тогда мы можем определить соседние записи. Дальшк, если в лоб решать, простой запрос с юнионом: селект, который выбирает нужную запись + 2 селекта для предыдущих 5 и последующих 5 (order by asc/desc по признакам + top/limit 5).
В общем, много текста, резюмируем: суть в том, что пользователю не надо пиу-пиу-скролл. Пользователю нужна та информация, которую он пытается найти. Скроллинг в этом деле — плохой помощник. Поисковый запрос — хороший.
С одной стороны я плюсую Ваш комментарий, согласен с Вашими доводами. С другой стороны, Вы правы, да не во всём. Тут вверху есть скриншот от свежей версии 1С, где изложенное Вами вроде бы в точности и реализовано. Да, скролл вроде как не нужен. И тем не менее, его отсутствие раздражает.
Потому что мы используем грид не только для того, чтобы найти интересующую информацию: для этого было бы достаточно форм-карточек. Мы скроллируем таблицу, чтобы посмотреть на разнообразие встречающихся записей. Перейдя (с помощью поиска) к Петрову, мы хотим по позиции движка понять, где примерно находится Петров в общем перечне. Много ли Петровых в перечне? (подвигаем вверх-вниз) А как насчёт Пётровых и Питровых, попадаются ли? На скольких Петровых приходится один Петросян?
Скролл — это естественная для пользователя метафора "полной распечатки таблицы". Это психологически очень важная зацепка за реальный мир. Поэтому нужен он пользователю. Можно, конечно, совсем без него оставить, как в пресловутом скриншоте сверху, и пользователь работать будет. Но гораздо более счастливым и продуктивным пользователь будет со скроллом.
Главное-то дело, задача имеет решение.
Потому что мы используем грид не только для того, чтобы найти интересующую информацию: для этого было бы достаточно форм-карточек. Мы скроллируем таблицу, чтобы посмотреть на разнообразие встречающихся записей. Перейдя (с помощью поиска) к Петрову, мы хотим по позиции движка понять, где примерно находится Петров в общем перечне. Много ли Петровых в перечне? (подвигаем вверх-вниз) А как насчёт Пётровых и Питровых, попадаются ли? На скольких Петровых приходится один Петросян?
Скролл — это естественная для пользователя метафора "полной распечатки таблицы". Это психологически очень важная зацепка за реальный мир. Поэтому нужен он пользователю. Можно, конечно, совсем без него оставить, как в пресловутом скриншоте сверху, и пользователь работать будет. Но гораздо более счастливым и продуктивным пользователь будет со скроллом.
Главное-то дело, задача имеет решение.
Ну по поводу подвигаем ввехр-вниз — я тут не отрицал необходимости ползунка. Поискать в окрестностях как раз укладывается в какое-то небольшое количество записей, которые можно глазом и мозгом охватить, я об этом выше писал. Понять где в списке примерно находится Петров, много ли Петровых в перечне — ну я понимаю, что Вы хотели какой-то пример привести, но согласитесь, он не очень удачный) Я пока не придумал задачу, для решения которой нужен был бы глобальный скролл. В пределах 20-40 записей — запросто (любой небольшой выпадающий спискок сюда так же относится). А вот скроллить на большем количестве записей какая может быть необходимость — пока не представляю.
Но с другой стороны абсолютно с Вами согласен по поводу "психологической зацепки". А даже, скорее, привычки. Так сложилось. Кто-то придумал там в конце 60-х табличное отображение и подумал, что нужно ж просматривать таблицу, значит нужен скролл. С тех пор так оно и копируется и пользователи привыкли. И я запросто могу представить себе немолодого бухгалтера, который скроллит таблицу из нескольких тысяч записей в поисках счета по номеру. Счастлив ли пользователь при этом? Возможно. Продуктивен? Врядли :)
Я бы сравнил (не аналогия, а так, сравнение для "поулыбаться") скролл с дисковым номеронабирателем. Всем нравилось, палец засунешь в технологическое отверстие и наяриваешь диск этот, а он так трещит, когда назад крутится, красота. А, главное, — детям нравится). Пальцы иногда застревали, но удобно ж, а не нужно телефониста просить соединить вас с абонентом, все можно делать самому. И бабушки не хотели переходить на кнопочные телефоны, потому что ж неудобно и непонятно, а диск — психологическая зацепка.
Но когда номера были 5-значные, то скорость работы с диском и с кнопками была сравнима. А сейчас бы понакручивать диск для дозвона внуку на мобилку — уже и невесело как-то ).
По поводу 1С — ну они экспериментируют с интерфейсом (как некоторые с меню Пуск). Не скажу, что мне нравится их реализация (напоминает контрол из Делфы для пробегания по записям), но наличие простого поиска — это определенно шаг вперед. Хотя не знаю как он там у них реализован, может ищет только по одному полю и только 100% совпадения, не сталкивался с 1С, но можно ожидать подвоха.
В общем дополним резюме из предыдущего коммента (там я только о больших обьемах данных говорил):
Для небольших наборов записей скролл — хорошее решение. Скроллить большие обьемы данных — бессмысленная (имхо, конечно же) трата времени. Сначала минимизируем выборку фильтрацией, потом скроллим.
П.С. за ссылку спасибо, интересная работа, славно потрудились!
Но с другой стороны абсолютно с Вами согласен по поводу "психологической зацепки". А даже, скорее, привычки. Так сложилось. Кто-то придумал там в конце 60-х табличное отображение и подумал, что нужно ж просматривать таблицу, значит нужен скролл. С тех пор так оно и копируется и пользователи привыкли. И я запросто могу представить себе немолодого бухгалтера, который скроллит таблицу из нескольких тысяч записей в поисках счета по номеру. Счастлив ли пользователь при этом? Возможно. Продуктивен? Врядли :)
Я бы сравнил (не аналогия, а так, сравнение для "поулыбаться") скролл с дисковым номеронабирателем. Всем нравилось, палец засунешь в технологическое отверстие и наяриваешь диск этот, а он так трещит, когда назад крутится, красота. А, главное, — детям нравится). Пальцы иногда застревали, но удобно ж, а не нужно телефониста просить соединить вас с абонентом, все можно делать самому. И бабушки не хотели переходить на кнопочные телефоны, потому что ж неудобно и непонятно, а диск — психологическая зацепка.
Но когда номера были 5-значные, то скорость работы с диском и с кнопками была сравнима. А сейчас бы понакручивать диск для дозвона внуку на мобилку — уже и невесело как-то ).
По поводу 1С — ну они экспериментируют с интерфейсом (как некоторые с меню Пуск). Не скажу, что мне нравится их реализация (напоминает контрол из Делфы для пробегания по записям), но наличие простого поиска — это определенно шаг вперед. Хотя не знаю как он там у них реализован, может ищет только по одному полю и только 100% совпадения, не сталкивался с 1С, но можно ожидать подвоха.
В общем дополним резюме из предыдущего коммента (там я только о больших обьемах данных говорил):
Для небольших наборов записей скролл — хорошее решение. Скроллить большие обьемы данных — бессмысленная (имхо, конечно же) трата времени. Сначала минимизируем выборку фильтрацией, потом скроллим.
П.С. за ссылку спасибо, интересная работа, славно потрудились!
Это даже не психологический вопрос, а общефилософский. Полоса прокрутки — инструмент, который дает определенные возможности. Насколько они нужны? А нужна ли полоса прокрутки при работе с большими файлами в Word. Если еще радикальнее, то Бетховену для написания 9-й симфонии слух оказался не нужен. А Алехину для одновременной игры на 32 досках — зрение.
Но это экстремумы. Резюме правильное. Примерно то же самое — в выводах статьи. Я бы еще добавил, что надо пытаться создавать интерфейсы, которые естественным образом не предполагают возможность пользователю получать большие выборки.
Но это экстремумы. Резюме правильное. Примерно то же самое — в выводах статьи. Я бы еще добавил, что надо пытаться создавать интерфейсы, которые естественным образом не предполагают возможность пользователю получать большие выборки.
Картинка, конечно, что надо.
Прямо… Окружили, демоны.
Прямо… Окружили, демоны.
Ответ на вопросы простой — №1 и №2 — это плохо!
Правильный вопрос №3: как построить интерфейс с быстрой загрузкой и правильной полосой прокрутки?
Ответ: за один раз не запрашивать все данные, а только их часть (порядка 100~300).
Например, список документов:
Последние 100 (по-умолчанию)
Фильтр по периоду
… по клиенту
… по дате
… (и прочее, что нужно пользователям).
Правильный вопрос №3: как построить интерфейс с быстрой загрузкой и правильной полосой прокрутки?
Ответ: за один раз не запрашивать все данные, а только их часть (порядка 100~300).
Например, список документов:
Последние 100 (по-умолчанию)
Фильтр по периоду
… по клиенту
… по дате
… (и прочее, что нужно пользователям).
Подход "последние 100 записей" как раз не позволит показать правильную полосу прокрутки. Откуда же взять общее количество записей? И как быстро и минимально затратно получить записи, например, от 100 до 200 с конца или, хуже с 1000 по 1100-ю. В вопросе 2 как раз и показан способ, как построить интерфейс с быстрой загрузкой, правильной полосой прокрутки и минимальным штрафом на СУБД.
"Последние 100 записей" — это вполне определённое подмножество.
А теперь проверим логику: "Откуда же взять общее количество записей?" и "хуже с 1000 по 1100-ю" — это совершенно неопределённое подмножество. К тому же в БД нет номеров записей — есть определённая запросом последовательность, поэтому актуален только вопрос №3.
А теперь проверим логику: "Откуда же взять общее количество записей?" и "хуже с 1000 по 1100-ю" — это совершенно неопределённое подмножество. К тому же в БД нет номеров записей — есть определённая запросом последовательность, поэтому актуален только вопрос №3.
Обратите внимание, в статье в принципе рассматриваются только подходы, которые предполагают, что из базы данных считывается только часть данных.
Мысль насчет 100 записей я не совсем понял. ОК, отобразили мы их. Бегунок, разумеется, в конце. Далее сдвинули мы бегунок в середину. Какой с Вашей точки зрения запрос должен пойти в базу данных?
Мысль насчет 100 записей я не совсем понял. ОК, отобразили мы их. Бегунок, разумеется, в конце. Далее сдвинули мы бегунок в середину. Какой с Вашей точки зрения запрос должен пойти в базу данных?
Если вы ограничиваете количество записей в выборке вменяемым количеством, то расчёт параметров (всех: первый, последний, соотношение высоты курсора) полосы прокрутки не занимает заметное время.
"Бегунок, разумеется, в конце." — в начале, если вы не перемещаете указатель до визуализации таблицы.
Вообще статья имеет чисто академическое направление. Рассматриваемый в ней вопрос уже давно решён системами промежуточного уровня, например, ADO.
Вообще статья имеет чисто академическое направление. Рассматриваемый в ней вопрос уже давно решён системами промежуточного уровня, например, ADO.
Спасибо за комменты. Вы предлагаете проектировать решения, которые не дают пользователю делать большие выборки. Это звучало и в других комментариях. Как проектировщик полностью с Вами согласен. Но, например, 1С-проектировщики этим не очень заморачиваются. Не заморачиваются этим, например, во ВКонтакте. Обычно, создать удобные решения, использующие ограниченные выборки, можно, но не так просто. Поэтому сейчас интерфейсы, предполагающие просмотр больших таблиц, используются очень часто.
ADO (как и любой другой API работы с СУБД) позволяет реализовать любой вариант работы с табличными данными, в т.ч. все варианты, описанные в статье, вариант, используемый в 1С (есть в комментах) и любой другой вариант.
И, что удивительно, все используют разные варианты — кто во что горазд. Так что вопрос условно решен: всеми по-разному.
ADO (как и любой другой API работы с СУБД) позволяет реализовать любой вариант работы с табличными данными, в т.ч. все варианты, описанные в статье, вариант, используемый в 1С (есть в комментах) и любой другой вариант.
И, что удивительно, все используют разные варианты — кто во что горазд. Так что вопрос условно решен: всеми по-разному.
Sign up to leave a comment.
Интерфейс работы с таблицей: быстро/неудобно — медленно/удобно