Подобного рода вопрос мне недавно задал один коллега, начинающий программировать на языке Си. И я подумал, что это хороший повод поделится своим пониманием данного вопроса. Потому, что даже опытные программисты не всегда имеют схожие точки зрения на этот счет.
Отчасти это дело вкуса, поэтому, кому интересно как это делаю я, добро пожаловать под кат.
Несмотря на то, что «вся правда» о h-файлах содержится в соответствующем разделе описания препроцессора gcc, позволю себе некоторые пояснения и иллюстрации.
Итак, если дословно, заголовочный файл (h-файл) — файл содержащий Си декларации и макро определения, предназначенные для использования в нескольких исходных файлах (с-файлах). Проиллюстрируем это.
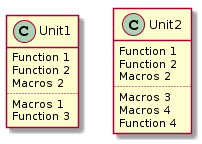
Легко заметить, что функции 1 и 2, а так же макрос 2, упомянуты в обоих файлах. И, поскольку, включение заголовочных файлов приводит к таким же результатам, как и копирование содержимого в каждый си-файл, мы можем сделать следующее:
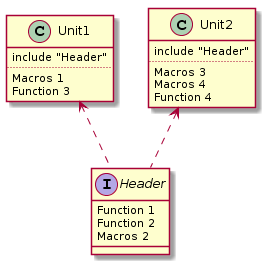
Таким образом мы просто выделили общую часть из двух файлов и поместили ее в заголовочный файл.
Но является ли заголовочный файл интерфейсом в данном случае?
Более того, действительно ли нам необходимо иметь два си-файла для реализации интерфейса, определенного в заголовочном файле? Или достаточно одного?
Ответ на этот вопрос зависит от деталей реализации интерфейсных функций и от их места реализации. Например, если сделать диаграммы более подробными, можно представить вариант, когда интерфейсные функции реализованы в разных файлах:
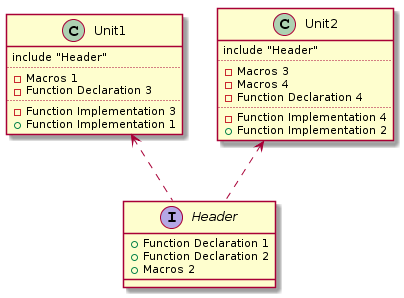
Такой вариант реализации приводит к высокой связности кода, низкой тестируемости и к сложности повторного использования таких модулей.
Для того, что бы не иметь таких трудностей, я всегда рассматриваю си-файл и заголовочный файл как один модуль. В котором,
Таким образом, если бы мне довелось реализовывать код, которому соответствует диаграмма приведенная выше, я бы постарался, добиться следующего (окончания _с и _h в именах файлов добавлены по причине невозможности использовать точку в инструменте, которым я пользовался для создания диаграмм):
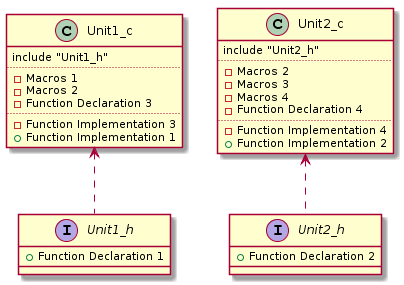
Из диаграммы видно, что на самом деле мы имеем дело с двумя независимыми модулями, у каждого из которых имеется свой интерфейс в виде заголовочного файла. Это дает возможность использовать только тот интерфейс, который действительно необходим в данном конкретном случае.Более того, эти модули могут быть протестированы независимо друг от друга.
Читатель, наверное, заметил, что макрос 2 из заголовочного файла снова вернулся в виде копии в оба си-файла. Конечно, это не очень удобно поддерживать. Но и делать данный макрос частью интерфейса не правильно.
В таких случаях, я предпочитаю делать отдельный заголовочный файл содержащий типы и макросы, необходимые нескольким си-файлам.
Надеюсь, мне удалось обозначить те сущности, которые нуждаются в том, что бы быть помещенными в заголовочные файлы. А так же, показать разницу между интерфейсам и файлами, содержащими декларации и макросы, необходимые нескольким си-файлам.
Спасибо за внимание к материалу.
Отчасти это дело вкуса, поэтому, кому интересно как это делаю я, добро пожаловать под кат.
Несмотря на то, что «вся правда» о h-файлах содержится в соответствующем разделе описания препроцессора gcc, позволю себе некоторые пояснения и иллюстрации.
Итак, если дословно, заголовочный файл (h-файл) — файл содержащий Си декларации и макро определения, предназначенные для использования в нескольких исходных файлах (с-файлах). Проиллюстрируем это.
Легко заметить, что функции 1 и 2, а так же макрос 2, упомянуты в обоих файлах. И, поскольку, включение заголовочных файлов приводит к таким же результатам, как и копирование содержимого в каждый си-файл, мы можем сделать следующее:
Таким образом мы просто выделили общую часть из двух файлов и поместили ее в заголовочный файл.
Но является ли заголовочный файл интерфейсом в данном случае?
- Если нам нужно использовать функциональность, которую реализуют функции 1 и 2 где то еще, то Да
- Если макрос 2, предназначен только для использования в файлах Unit1.c и Unit2.c, то ему не место в интерфейсном файле
Более того, действительно ли нам необходимо иметь два си-файла для реализации интерфейса, определенного в заголовочном файле? Или достаточно одного?
Ответ на этот вопрос зависит от деталей реализации интерфейсных функций и от их места реализации. Например, если сделать диаграммы более подробными, можно представить вариант, когда интерфейсные функции реализованы в разных файлах:
Такой вариант реализации приводит к высокой связности кода, низкой тестируемости и к сложности повторного использования таких модулей.
Для того, что бы не иметь таких трудностей, я всегда рассматриваю си-файл и заголовочный файл как один модуль. В котором,
- заголовочный файл содержит только те декларации функций, типов, макросов, которые являются частью интерфейса данного модуля.
- Си-файл, в свою очередь, должен содержать реализацию всех функций, декларированных в h- файле, а также приватные типы, макросы и функции, которые нужны для реализации интерфейса.
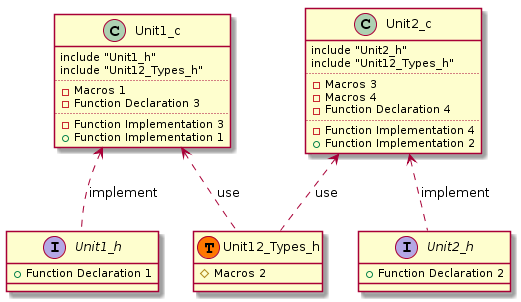
Таким образом, если бы мне довелось реализовывать код, которому соответствует диаграмма приведенная выше, я бы постарался, добиться следующего (окончания _с и _h в именах файлов добавлены по причине невозможности использовать точку в инструменте, которым я пользовался для создания диаграмм):
Из диаграммы видно, что на самом деле мы имеем дело с двумя независимыми модулями, у каждого из которых имеется свой интерфейс в виде заголовочного файла. Это дает возможность использовать только тот интерфейс, который действительно необходим в данном конкретном случае.Более того, эти модули могут быть протестированы независимо друг от друга.
Читатель, наверное, заметил, что макрос 2 из заголовочного файла снова вернулся в виде копии в оба си-файла. Конечно, это не очень удобно поддерживать. Но и делать данный макрос частью интерфейса не правильно.
В таких случаях, я предпочитаю делать отдельный заголовочный файл содержащий типы и макросы, необходимые нескольким си-файлам.
Надеюсь, мне удалось обозначить те сущности, которые нуждаются в том, что бы быть помещенными в заголовочные файлы. А так же, показать разницу между интерфейсам и файлами, содержащими декларации и макросы, необходимые нескольким си-файлам.
Спасибо за внимание к материалу.
