Comments 32
Статья есть на английском? Хочется видеть её тут — https://spring.io/blog
Кирилл, спасибо за отзыв! Очень жду ваших докладов на JPoint.
На счет пишут ли там не свои — вроде как тоже заметил, что там только «свои» статьи. Но ведь всегда можно быть первым.
Я бы пошел сюда https://gitter.im/spring-cloud/spring-cloud и задал вопрос Dave Syer (@dsyer) о том как это сделать или обратился в твиттере к @starbuxman. Они нормально идут на контакт)
Что я в этой схеме не понимаю? Как можно делать быстрые приложения на микросервисах с синхронными внутренними запросами?
Коммуникация между сервисами также существенно упрощена: используются только синхронные rest-запросы.
Как можно делать быстрые приложения на микросервисах с синхронными внутренними запросами?
Мне не известны способы сделать цепочку синхронных запросов быстрой, ведь оверхэд на сеть будет всегда.
Другой вопрос, что все стремятся сделать взаимодействие максимально асинхронным. В случае, если для страницы UI вам необходимо дернуть 5 сервисов для сбора контента — есть возможность распараллелить такой запрос сразу в API Gateway, это одна из его основных задач. Существует стремительно развивающаяся дисциплина — реактивное программирование (посмотрите Akka, RxJava). Есть немало материала на этот счет, в том числе на хабре. Короткая статья Netflix как раз на эту тему.
С другой стороны, стоит помнить, что существует два разных подхода к взаимодействию — оркестрация и хореография:
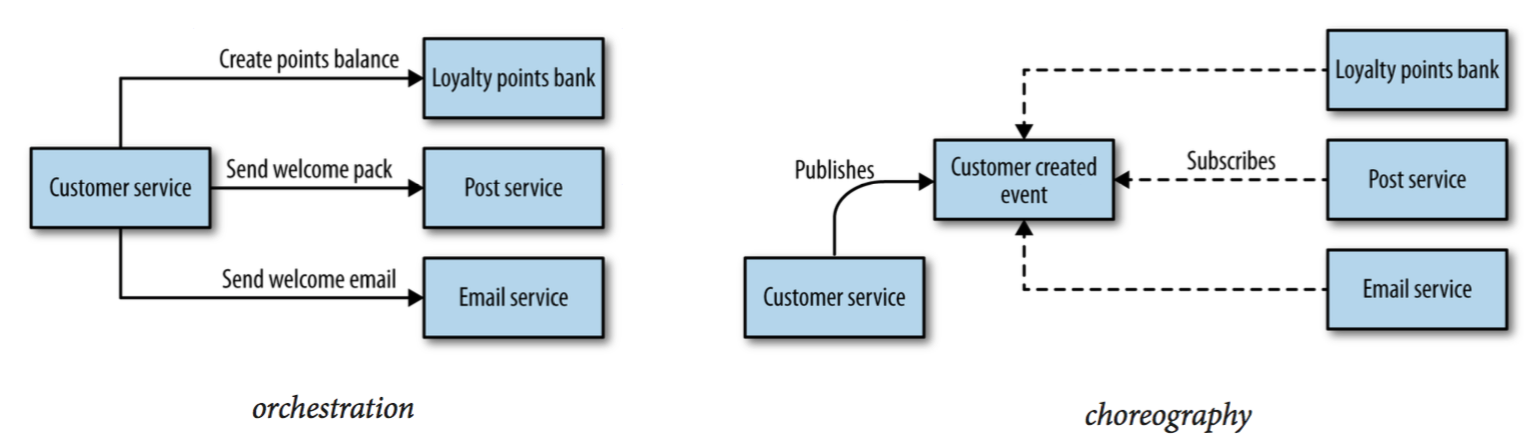
Последний позволяет решить много проблем в распределенной системе, делая узлы менее связанными, со всеми вытекающими плюсами.
Тут важно то, что это Latency можно сохранять с увеличивающейся нагрузкой. Т.е если к пришло 100rps и задержки были 300мс. То распределенную систему можно быстро отмасштабировать на работу с 10000rps при тех же 300мс. Мне кажется, упор именно на это.
Меня немного пугает сложность администрирования все этого «хозяйства». Представим что мы не имеем права на single point of failure, тогда нам нужно как минимум по 2 инстанса каждого сервиса, в итоге даже на таком примере у нас уже десяток серверов приложений и баз данных.
Также рекомендую статью все того же Мартина Microservice Trade-Offs
А single point of failure — о другом, это грех классического монолита или расшаренной между сервисами базой данных. Выдуманный пример: в некоторый момент на вход начинают поступать данные, вызывающие критическую ошибку в Statistics Service, приводящую к падению всего приложения. В случае монолита это последовательно уронит все инстансы, пользователи не смогут доступится к приложению вообще. В случае микросервисов нет единой точки отказа — Account Service и Notification Service продолжают фунционировать (все загружается и сохраняется, разве что на UI не работает график про статистику), а после исправления дефекта поднятые инстансы Statistics Service разберут накопившиеся очереди.
Сами сейчас копаем в сторону Yandex.Cocaine, поэтому было особо интересно посмотреть, как в другом мире обстоят дела.
Есть эталонный проект от spring-cloud — brewery sample. В нем есть тесты, можно посмотреть. Если речь про интеграционные или приемочные тесты, то тестируется же примерно так же как и монолит. Но при этом вы имеете дополнительные возможности в тестировании отдельных частей.
Хочтелось бы продолжения данной темы, с ответами на следующие вопросы:
1. Деплой приложения «одной кнопкой» без даунтайма (после обновления одного\нескольких компонентов).
2. Бекапы и развертывание приложения из бекапов после падения серевра(ов) (ситуация, типа «взрыв в датацентре»)
3. Наращивание количества серверов в случае роста нагрузки и распределение запросов между новыми серверами. Желательно, чтобы процедура добавления\удаления сервера из кластера реализовывалась также «одной кнопкой».
Если я бы сейчас выбирал стек фреймворков и библиотек для самостоятельной реализации облака микросервисов — в первую очередь смотрел бы в сторону спринга.
Спасибо за отзыв, но кажется вы не понимаете ряд важных моментов.
В .yml файлах из конфиг-сервиса ничего не захардкожено — там указаны порты, на которых должны подниматься спринговые приложения (это никак не связано с портами, которые торчат наружу). Порты здесь указаны они для удобства, ибо по умолчанию порт один — 8080 и если вы решите запустить их на одном хосте (из IDE, например) — будет конфликт. Но при запуске в контейнерах это вообще не важно — можете поменять их на стандартные, если хочется. Каждый контейнер со спринговым приложением будет экспоузить 8080, каждый со своего хоста внутри докер-нетворка.
В продакшн моде наружу из докер нетворка выставляется только часть служебных сервисов (типа rabbitmq managment, eureka dashboard, мониторинг и конечно gateway на 80 порту), чем меньше тем лучше. Смотрите докер-компоуз файлы.
Когда поднимается какой-нибудь account-service, он понятия не имеет где находится notification-serice — это нигде не прописано и ему предстоит узнать адрес у Eureka. Вы можете провести простой эксперимент — после запуска всей системы сделайте
docker-compose scale notification-service=2. Поднимется еще один инстанс notification-service, зарегистрируется в Eureka и клиентские балансировщики у всех остальных сервисов будут раунд робином стучать в два имеющихся notification-service. Просто смотрите логиdocker-compose logs notification-serviceи стучите в него через gateway:curl -X GET -H "Authorization: Bearer XXXX" http://127.0.0.1/notifications/recipients/current
- Часть служебных сервисов являются фиксированными точками. Такие точки каждый из сервисов знает наизусть (без Service Discovery):
- Очевидно сам сервер Eureka — http://registry:8761
- Конфиг сервер — http://config:8888. Этот адрес прописан прямо в bootstrap.yml каждого из микросервисов, ибо это первое, куда им нужно обратиться при старте — "Config First" mode. См. документацию.
- Авторизационный сервер — http://auth-service:5000. Вот его хотелось бы регистрировать в Service Discovery, но пока это невозможно из коробки. См. тикет на гитхабе.
Как видно, ко всем ним можно обращаться по алиасам внутри докер нетворка, что делается с помощью встроенного dns-сервера (компоуз запускает контейнеры с командой --net-alias, в результате имя в сети = имени сервиса) — см. документацию
В случае, скажем, со стеком Consul/Consul template/Gliderlabs registrator/Nginx — service registry консула сформирован на основе информации об открытых портах докер контейнеров, таким образом service discovery заточен, если можно так выразиться: на инфраструктуру, а не на код.
Если я правильно понимаю суть Eureka — в реестре сервисов хранится информация о хостах и портах spring boot (в нашем случае) приложений. Эти порты, смапленные на порты хостов (хостов может быть множество, также как и каждый логический сервис может иметь несколько инстансов в рамках одного хоста), не всегда будут равны портам самих приложений.
Та же связка consul/registrator здесь хороша тем, что service registry хранит информацию о портах уже контейнеров, а не приложений.
Как эта проблема решается Netflix OSS стеком?
Теперь понял о чем вы. Проблема встает если выставлять Service Discovery наружу из докер нетворка и регистрировать сервисы извне (не делал так). Решается очевидно тем же способом, кстати в gliderlabs/registrator, о котором вы говорите, я вижу свежий пулл-реквест для поддержки Eureka. Кроме того, во всем этом стеке Eureka можно заменить на Consul достаточно безболезненно. Ну и если докер соберется сделать вот этот тикет, проблема будет решена окончательно.
Beats процессы запускаются в каждом контейнере сервиса?
Или как-то можно перенаправить логи средствами докера?
Микросервисная архитектура, Spring Cloud и Docker