Посетил Стенфордский симпозиум, посвященный пересечению deep learning и neurosciencе, получил массу удовольствия.

Рассказываю про интересное — например, доклад Дэна Яминса о применении нейросетей для моделирования работы зрительной коры головного мозга.
Disclaimer: пост написан на основе изрядно отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и уточняющие вопросы.
Вот линк на полный доклад, он клевый, но смотреть, пожалуй, лучше после чтения поста.
Дэн занимается computational neuroscience, т.е. пытается вычислительными методами помочь исследованию мозга. И там, как и везде, случается deep learning.
Вообще, устройство зрительной коры на высоком уровне мы чуть-чуть понимаем
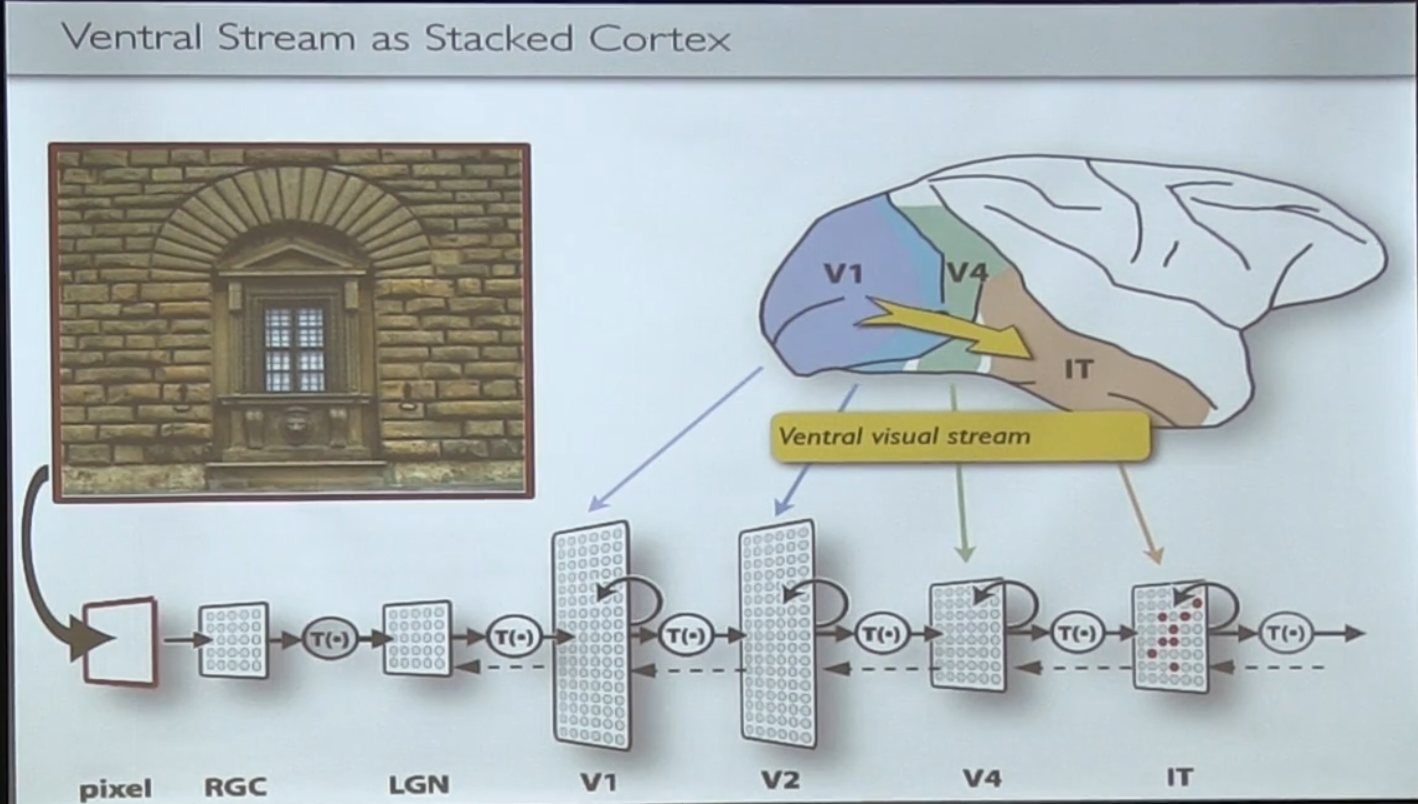
Когда мы видим какое-то изображение, глаз вызывает активации нейронов, активации проходят через разные участки мозга, которые выделяют из них все более высокоуровневое представление.
V1 еще называется primary visual cortex и он неплохо исследован — там есть нейроны, которые прогоняют некие фильтры над изображением, и активируются на линиях под разными углами и простеньких градиентах.
(кстати, паттерны, на которых нейроны активируются в этом участке часто похожи на первые выученные уровни в CNN, что само по себе очень круто)
Есть даже успехи в моделировании этой части — мол, придумать какую-то модель, посмотреть как нейроны активируются на входном изображении, зафиттитить, и потом эта модель вполне себе предсказывает активации этих нейронов на новых картинках.
С V4 и IT (более высокими уровнями обработки) так не получается.
Откуда вообще берутся данные про биологические нейроны?
Типичный эксперимент выглядит так — берется обезьянка, ей в некоторую часть мозга втыкаются электроды, которые снимают сигналы с нейронов, в которые они попали. Обезьянке показывают разные картинки и снимают сигнал с электродов. Так делают на нескольких сотнях нейронов — количество нейронов всего в исследуемых долях мозга огромно, меряют всего сотни.
Оказывается, если попытаться зафиттить модель на активацию биологических нейронов в V4 и IT, происходит оверфиттинг — данных мало и для новых картинок модель уже ничего не предсказывает.
Дэн-сотоварищи пробуют сделать по-другому
Давайте возьмем модель и натренируем ее на какую-то задачу распознавания, чтобы искусственные нейроны в ней распознавали что-то на этих картинках.
Вдруг они будут предсказывать активации биологических нейронов лучше?
Вот теперь внимательно следим за руками.
Они тренируют модели (CNNs и более простые модели из обычного computer vision) распознавать объекты на синтетических картинках.
Картинки вот такие:

Объект не коррелирует с бэкграундом — может быть и самолет на фоне озера, и голова на фоне какого-то дикого леса (я так понимаю, чтобы исключить prior в обучении).
Всего на картинках 8 категорий объектов — головы, машины, самолеты, что-то еще.
И вот тренируют модели разной структуры и глубины распознавать категорию объекта. В числе прочих моделей есть и CNNs pretrained на Imagenet, и они убирают из тренировочного датасета категории объектов, которые они использовали в своих синтетических картинках.
Далее, на основе натренированной CNN они "предсказывают" активации биологических нейронов следующим образом.
Берут некий training set (отдельные категории объектов), выбирают какой-то уровень в CNN и нейроны в какой-то части мозга и строят линейный классификатор, который предсказывает активации биологических нейронов на основе искусственных.
То есть, пробуют приблизить активацию биологического нейрона как линейную комбинацию из активаций искусственных нейронов в каком-то слое (ведь один к одному их точно никак не совместить, их совсем разное количество). А потом проверяют насколько оно обладает предсказательной силой на тестовом наборе, где были совсем другие объекты.
Надеюсь, объяснить получилось.
То есть у них в качестве выхода CNN — что-то типа идентификации биологического нейрона?
Нет! Выход CNN — это классификатор объектов на картинках.
CNN тренируется классифицировать изображения, про биологические нейроны она ничего не знает. Размеченные данные для сетки — это какой объект на картинке, без знания о биологических нейронах.
А потом зафиксировали веса в CNN, и фиттим активации биологических нейронов как линейную комбинацию активаций нейронов искусственных.
а почему линейная комбинация, а не еще одна сетка?
Предсказание биологических по искусственным хочется сделать как можно более простым, чтобы система не переучивалась и брала основной сигнал из активаций нейронов в CNN.
А потом на новых тестовых картинках проверяем, получилось ли у нас предсказать активацию в биологических нейронах.
Так вот, картинка c результатами!

Каждая точка на этом графике — это какая-то опробованная модель.
По оси X — насколько она хорошо классифицирует, по оси Y — насколько она хорошо предсказывает биологические нейроны.
Синее облако — это модели, которые или не тренировались вообще, или тренировались с нуля и там много не очень глубоких, а красные точки вверху справа — это модели pretrained на imagenet и тотальный deep learning.
Видно, что то, насколько хорошо модель классифицирует, крепко коррелирует с тем, насколько она хорошо предсказывает биологические активации. То есть, поставив ограничение, что модель должна быть еще и функциональна — получается лучше приблизить модель активации биологических нейронов.
Вопрос может в сторону, но все же. А нельзя ли тогда учить модель классифицировать что-то, используя в качестве учителя — нейроны в мозгу? Типа показали картину + взяли данные из мозга и скормили это в CNN?
Это то самое, о чем я говорил раньше — так как нейронов ты знаешь мало, такая модель начинает оверфиттить и предсказательной силой не обладает.
То есть, обучение на активациях нейронов не генерализируется, а обучение на выделении объектов — это значительно более мощный constraint.
А теперь термояд.
Можно посмотреть как разные уровни нейросети предсказывают активации разных участков мозга:
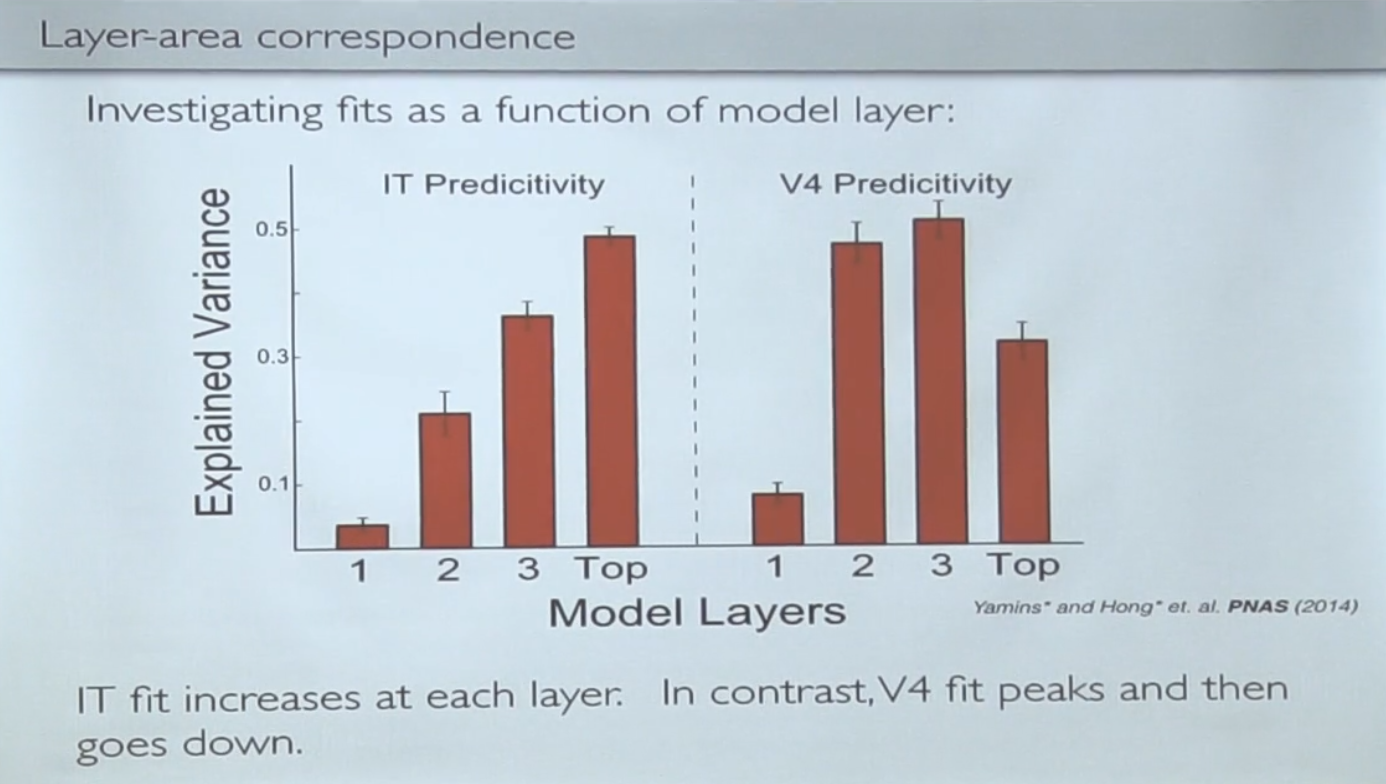
Оказывается, что последние уровни хорошо предсказывают IT (последнюю стадию), но не V4 (промежуточную). А V4 лучше всего предсказывают промежуточные уровни сети.
Таким образом, иерархическое представление фич в нейросети "соприкасается" не только в конце, но и в середине процессинга, что снова наталкивает на мысль, что есть какая-то общность того, что происходит там и там.
То есть у них нейронная сеть выглядит примерно так же, как биологические нейроны в мозгу?
Скорее, есть что-то похожее в том, через какие этапы проходит процесс распознавания.
Сказать, что "архитектура" та же, конечно, нельзя (разумеется, это нисколько нельзя считать доказательством, итд итп)
Следующий этап — ну ок, предположим получили возможность моделировать неизвестно как работающий мозг какой-то другой непонятно как работающей коробкой. Какая в этом радость?
Дальнейшая работа — как можно это использовать, чтобы что-то новое понять про работу мозга.
Я расскажу про один пример, в самом выступлении есть еще два.
Давайте попробуем вытащить не только классификацию, а еще какие-то сигналы из картинки — угол наклона, размер, позицию итд.

Казалось бы, это более "низкоуровневые" фичи, чем класс объекта, и можно ожидать, что они определяются на более низких уровнях распознавания в мозгу — давайте проверим это на модели.
Оказывается, фиг там!
Даже вот такие "низкоуровневые" фичи лучше коррелируют с высокоуровневыми активациями, а не низкоуровневыми. Потом они провели дополнительные эксперименты на живом мозге и увидели то же самое — те линии и уголки, которые мы привыкли видеть в паттернах первых слоев не имеют отношения к "линиям" ориентации высокоуровневых объектов.
Информация о позиции и взаимном расположении объектов вполне себе доходит до высокого уровня.
Это подтверждает уже до этого существующую теорию, что последняя стадия (IT) — работает со сформированной высокоуровневой моделью, где есть объекты, их расположение, взаимные отношения итд итп и преобразует их во что-то нужное мозгу дальше.
(другие примеры, если кому интересно, про проверку гипотезы про выделенное место в мозгу для распознавания лиц через тренировку виртуального мозга, который никогда в жизни лиц не видел, и про распознавание звуков)
(Продолжаем дилетантские вопросы) А они в своей CNN использовали модель с таким же количество слоев? Ну то есть, а если уменьшить количество слоев эффекты похожести исчезают?
Нет, количество "слоев" в мозге штука сложная — там есть и сквозные связи, и фидбек. Количество слоев в CNN принципиально меньше, чем в мозге.
А как тогда идет разговор про IT и V4?
Ну, в мозгу IT и V4 — это много-много уровней, а в нейросети уровней мало. Биологические нейроны из IT и V4 — это те, в которые попал электрод. Из какого "биологического лейера" внутри них получилось — из того получилось.
Интересно еще следующее. Если верить Рамачандрану, то visual cortex — это не просто feed-forward сеть, все слои общаются со всеми слоями в обоих направлениях. Есть даже пример, когда можно зрительную систему вывести из равновесия через разного рода оптические иллюзии.
То есть никто не гарантирует, что активация биологических нейронов как-то связана с самим процессом распознавания, а не с тем, что из-за вида самолетика у обезьяны начинает чесаться нога, а нейроны уже реагируют на то, что у нее нога чешется?
Нет, это нейроны из области, которая известно, что связана с visual cortex (эту часть про мозг мы худо-бедно знаем — почесаться там быть не может, это дальше по стеку).
Подытожив — прямое направление работ скорее про использование новых моделей для изучения работы мозга, но есть некие непрямые намеки, что как-то это слишком хорошо работает, возможно есть общие механизмы.
Надеемся, сойдутся в сингулярность!
