В стандартной библиотеке Python 3.4 в своё время появился модуль asyncio, позволивший удобно и быстро писать асинхронный код. А уже к Python 3.5 в синтаксис были добавлены конструкции async/await, окончательно оформившие асинхронность «из коробки» как красивую и гармоничную часть языка.

Хотя asyncio сам по себе и позволяет писать высоконагруженные веб-приложения, оптимизация производительности не была приоритетом при создании модуля.
Один из авторов упомянутого PEP-492 (async/await) Юрий Селиванов (на Хабре — 1st1, его твиттер) взялся за разработку альтернативной реализации цикла событий для asyncio — uvloop. Вчера вышла первая альфа-версия модуля, о чём автор написал развёрнутый пост.
Если вкратце, то uvloop работает примерно в 2 раза быстрее Node.js и практически не уступает программам на Go.
uvloop написан на Cython и построен на базе libuv.
Установить модуль можно стандартно (Windows в данный момент не поддерживается):
Использовать тоже не сложно:
Теперь любой вызов asyncio.get_event_loop() будет возвращать экземпляр uvloop.
Подробнее про бенчмарки (методику проведения и выводы) можно почитать в оригинале, ниже только итоговые графики.
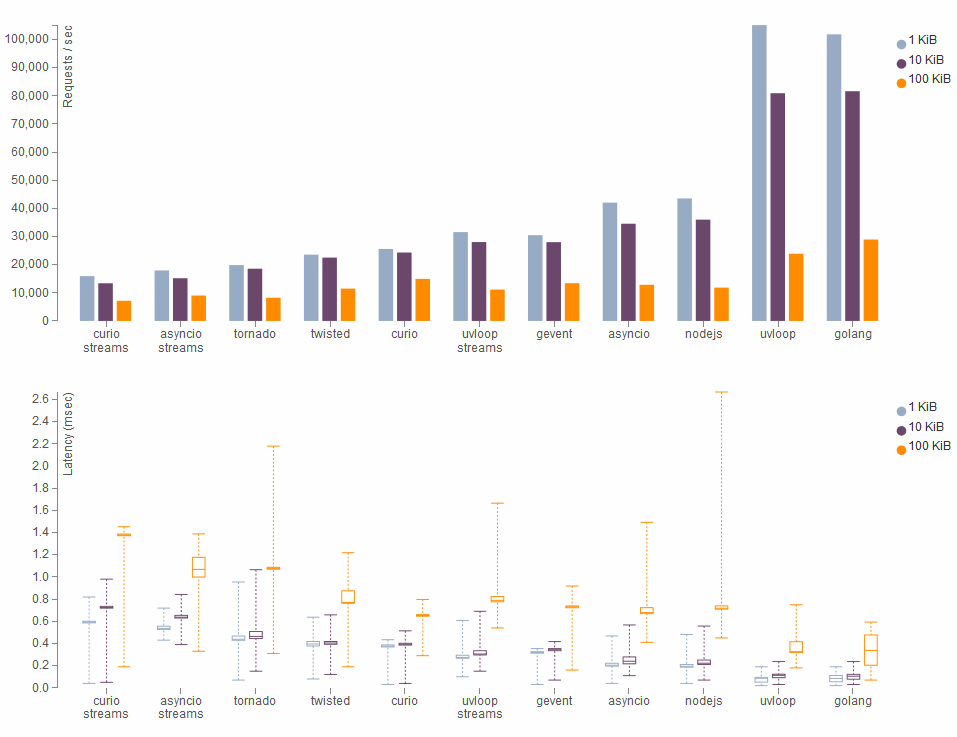
Результаты для простых TCP запросов разного размера:
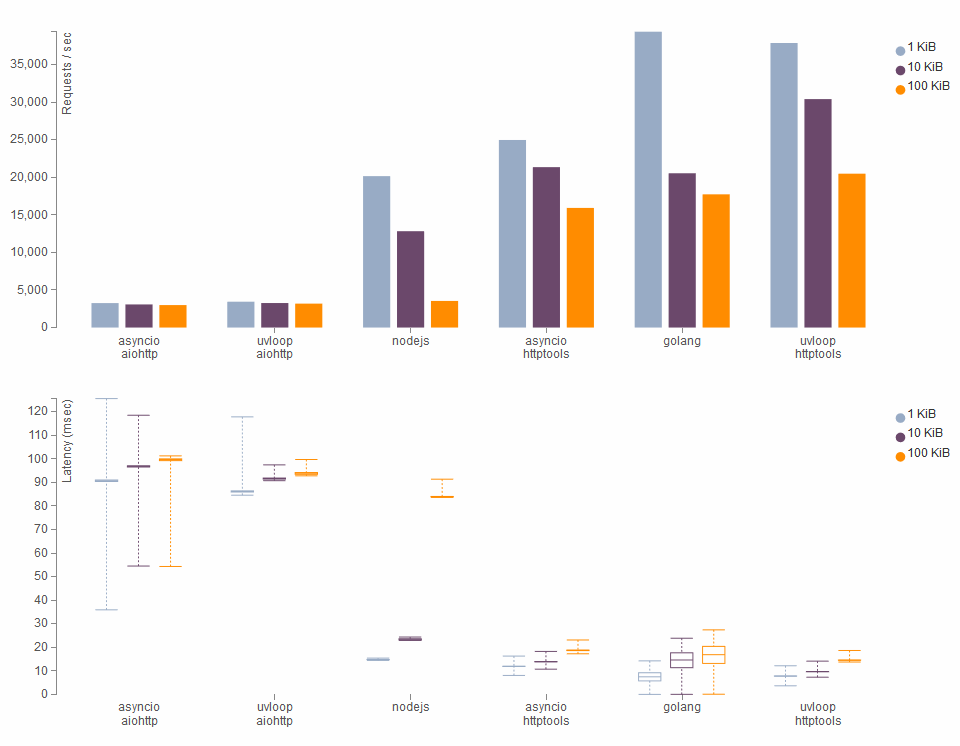
HTTP запросы:
Хотя asyncio сам по себе и позволяет писать высоконагруженные веб-приложения, оптимизация производительности не была приоритетом при создании модуля.
Один из авторов упомянутого PEP-492 (async/await) Юрий Селиванов (на Хабре — 1st1, его твиттер) взялся за разработку альтернативной реализации цикла событий для asyncio — uvloop. Вчера вышла первая альфа-версия модуля, о чём автор написал развёрнутый пост.
Если вкратце, то uvloop работает примерно в 2 раза быстрее Node.js и практически не уступает программам на Go.
Использование
uvloop написан на Cython и построен на базе libuv.
Установить модуль можно стандартно (Windows в данный момент не поддерживается):
pip install uvloop
Использовать тоже не сложно:
import asyncio
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
Теперь любой вызов asyncio.get_event_loop() будет возвращать экземпляр uvloop.
Производительность
Подробнее про бенчмарки (методику проведения и выводы) можно почитать в оригинале, ниже только итоговые графики.
Результаты для простых TCP запросов разного размера:
HTTP запросы:
