Недавно я попробовал pthreads и был приятно удивлен — это расширение, которое добавляет в PHP возможность работать с несколькими самыми настоящими потоками. Никакой эмуляции, никакой магии, никаких фейков — все по-настоящему.

Я рассматриваю такую задачу. Есть пул заданий, которые надо побыстрее выполнить. В PHP есть и другие инструменты для решения этой задачи, тут они не упоминаются, статья именно про pthreads.
Стоит отметить, что автор расширения, Joe Watkins, в своих статьях предупреждает, что многопоточность — это всегда не просто и надо быть к этому готовым.
Кто не испугался, идем далее.
Что такое pthreads
Pthreads — это объектно-ориентированное API, которое дает удобный способ для организации многопоточных вычислений в PHP. API включает в себя все инструменты, необходимые для создания многопоточных приложений. PHP-приложения могут создавать, читать, писать, исполнять и синхронизировать потоки с помощью объектов классов Threads, Workers и Threaded.
Что внутри pthreads
Иерархия основных классов, которые мы только что упомянули, представлена на диаграмме.
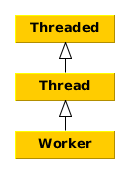
Threaded — основа pthreads, дает возможность параллельного запуска кода. Предоставляет методы для синхронизации и другие полезные методы.
Thread. Можно создать поток, отнаследовавшись от Thread и реализовав метод run(). Метод run() начинает выполняться, причем в отдельном потоке, в момент, когда вызывается метод start(). Это можно инициировать только из контекста, который создает поток. Объединить потоки можно тоже только в этом-же контексте.
Worker. Персистентное состояние, которое в большинстве случаев используется разными потоками. Доступно, пока объект находится в области видимости или до принудительного вызова shutdown().
Помимо этих классов есть еще класс Pool. Pool — пул (контейнер) Worker-ов можно использовать для распределения Threaded объектов по Worker-ам. Pool — наиболее простой и эффективный способ организовать несколько потоков.
Не будем сильно грустить над теорией, а сразу попробуем все это на примере.
Пример
Можно решать разные задачи в несколько потоков. Мне было интересно решить одну конкретную и как мне кажется весьма типовую задачу. Напомню ее еще раз. Есть пул заданий, их надо побыстрее выполнить.
Так давайте приступим. Для этого создадим провайдер данных MyDataProvider (Threaded), он будет один и общий для всех потоков.
/**
* Провайдер данных для потоков
*/
class MyDataProvider extends Threaded
{
/**
* @var int Сколько элементов в нашей воображаемой БД
*/
private $total = 2000000;
/**
* @var int Сколько элементов было обработано
*/
private $processed = 0;
/**
* Переходим к следующему элементу и возвращаем его
*
* @return mixed
*/
public function getNext()
{
if ($this->processed === $this->total) {
return null;
}
$this->processed++;
return $this->processed;
}
}Для каждого потока у нас будет MyWorker (Worker), где будет храниться ссылка на провайдер.
/**
* MyWorker тут используется, чтобы расшарить провайдер между экземплярами MyWork.
*/
class MyWorker extends Worker
{
/**
* @var MyDataProvider
*/
private $provider;
/**
* @param MyDataProvider $provider
*/
public function __construct(MyDataProvider $provider)
{
$this->provider = $provider;
}
/**
* Вызывается при отправке в Pool.
*/
public function run()
{
// В этом примере нам тут делать ничего не надо
}
/**
* Возвращает провайдера
*
* @return MyDataProvider
*/
public function getProvider()
{
return $this->provider;
}
}Сама обработка каждой задачи пула, (пусть это будет некая ресурсоемкая операция), наше узкое горлышко, ради которого мы и затеяли многопоточность, будет в MyWork (Threaded).
/**
* MyWork это задача, которая может выполняться параллельно
*/
class MyWork extends Threaded
{
public function run()
{
do {
$value = null;
$provider = $this->worker->getProvider();
// Синхронизируем получение данных
$provider->synchronized(function($provider) use (&$value) {
$value = $provider->getNext();
}, $provider);
if ($value === null) {
continue;
}
// Некая ресурсоемкая операция
$count = 100;
for ($j = 1; $j <= $count; $j++) {
sqrt($j+$value) + sin($value/$j) + cos($value);
}
}
while ($value !== null);
}
}Обратите внимание, что данные из провайдера забираем в synchronized(). Иначе есть вероятность часть данных обработать более 1 раза, или пропустить часть данных.
Теперь заставим все это работать с помощью Pool.
require_once 'MyWorker.php';
require_once 'MyWork.php';
require_once 'MyDataProvider.php';
$threads = 8;
// Создадим провайдер. Этот сервис может например читать некие данные
// из файла или из БД
$provider = new MyDataProvider();
// Создадим пул воркеров
$pool = new Pool($threads, 'MyWorker', [$provider]);
$start = microtime(true);
// В нашем случае потоки сбалансированы.
// Поэтому тут хорошо создать столько потоков, сколько процессов в нашем пуле.
$workers = $threads;
for ($i = 0; $i < $workers; $i++) {
$pool->submit(new MyWork());
}
$pool->shutdown();
printf("Done for %.2f seconds" . PHP_EOL, microtime(true) - $start);Получается довольно элегантно на мой взгляд. Этот пример я выложил на гитхаб.
Вот и все! Ну почти все. На самом деле есть то, что может огорчить пытливого читателя. Все это не работает на стандартном PHP, скомпилированным с опциями по умолчанию. Чтобы насладиться многопоточностью, надо, чтобы в вашем PHP был включен ZTS (Zend Thread Safety).
Настройка PHP
В документации сказано, что PHP должен быть скомпилирован с опцией --enable-maintainer-zts. Я не пробовал сам компилировать, вместо этого нашел пакет для Debian, который и установил себе.
sudo add-apt-repository ppa:ondrej/php-zts
sudo apt update
sudo apt-get install php7.0-zts php7.0-zts-devТаким образом у меня остался прежний PHP, который запускается из консоли обычным образом, с помощью команды php. Соответственно, веб сервер использует его-же. И появился еще один PHP, который можно запускать из консоли через php7.0-zts.
После этого можно ставить расширение pthreads.
git clone https://github.com/krakjoe/pthreads.git
./configure
make -j8
sudo make install
echo "extension=pthreads.so" > /etc/pthreads.ini
sudo cp pthreads.ini /etc/php/7.0-zts/cli/conf.d/pthreads.iniВот теперь все. Ну… почти все. Представьте, что вы написали мультипоточный код, а PHP на машине у коллеги не настроен соответствующим образом? Конфуз, не правда ли? Но выход есть.
pthreads-polyfill
Тут снова спасибо Joe Watkins за пакет pthreads-polyfill. Суть решения такова: в этом пакете содержатся те-же классы, что и в расширении pthreads, они позволяют выполниться вашему коду, даже если не установлено расширение pthreads. Просто код будет выполнен в один поток.
Чтобы это заработало, вы просто подключаете через composer этот пакет и больше ни о чем не думаете. Там происходит проверка, установлено ли расширение. Если расширение установлено, то на этом работа polyfill заканчивается. Иначе подключаются классы-”заглушки”, чтобы код работал хотя бы в 1 поток.
Проверим
Давайте теперь посмотрим, действительно ли обработка происходит в несколько потоков и оценим выигрыш от использования этого подхода.
Я буду менять значение $threads из примера выше и смотреть, что получается.
Информация о процессоре, на котором запускал тесты
$ lscpu
CPU(s): 8
Потоков на ядро: 2
Ядер на сокет: 4
Model name: Intel(R) Core(TM) i7-4700HQ CPU @ 2.40GHz
Посмотрим диаграмму загрузки ядер процессора. Тут все соответствует ожиданиям.
$threads = 1

$threads = 2

$threads = 4
$threads = 8
А теперь самое главное, ради чего все это. Сравним время выполнения.
| $threads | Примечание | Время выполнения, секунд |
|---|---|---|
| PHP без ZTS | ||
| 1 | без pthreads, без polyfill | 265.05 |
| 1 | polyfill | 298.26 |
| PHP с ZTS | ||
| 1 | без pthreads, без polyfill | 37.65 |
| 1 | 68.58 | |
| 2 | 26.18 | |
| 3 | 16.87 | |
| 4 | 12.96 | |
| 5 | 12.57 | |
| 6 | 12.07 | |
| 7 | 11.78 | |
| 8 | 11.62 | |
Из первых двух строк видно, что при использовании polyfill мы потеряли примерно 13% производительности в этом примере, это относительно линейного кода на совсем простом PHP “без всего”.
Далее, PHP с ZTS. Не обращайте внимание на такую большую разницу во времени выполнения в сравнении с PHP без ZTS (37.65 против 265.05 секунд), я не пытался привести к общему знаменателю настройки PHP. В случае без ZTS у меня включен XDebug например.
Как видно, при использовании 2-х потоков скорость выполнения программы примерно в 1.5 раза выше, чем в случае с линейным кодом. При использовании 4-х потоков — в 3 раза.
Можно обратить внимание, что хоть процессор и 8-ядерный, время выполнения программы почти не менялось, если использовалось более 4 потоков. Похоже, это связано с тем, что физических ядра у моего процессора 4. Для наглядности изобразил табличку в виде диаграммы.
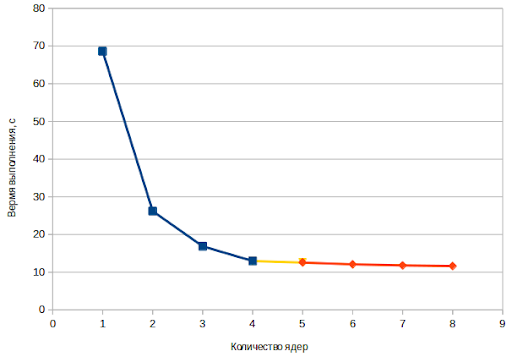
Резюме
В PHP возможна вполне элегантная работа с многопоточностью с использованием расширения pthreads. Это дает ощутимый прирост производительности.
