 Это первая статья в цикле про создание и использование скриптов для веб-скрейпинга при помощи Node.js.
Это первая статья в цикле про создание и использование скриптов для веб-скрейпинга при помощи Node.js.
- Web scraping при помощи Node.js
- Web scraping на Node.js и проблемные сайты
- Web scraping на Node.js и защита от ботов
- Web scraping обновляющихся данных при помощи Node.js
Тема веб-скрейпинга вызывает всё больше интереса как минимум потому, что это неисчерпаемый источник небольших, но удобных и интересных заказов для фрилансеров. Естественно, что всё больше людей пытаются выяснить, что это такое. Однако, довольно трудно понять, что такое веб-скрейпинг по абстрактным примерам из документации к очередной библиотеке. Гораздо проще разобраться в этой теме наблюдая за решением реальной задачи шаг за шагом.
Обычно, задача для веб-скрейпинга выглядит так: есть данные, доступные только на веб-страницах, и их надо оттуда вытащить и сохранить в неком удобоваримом формате. Конечный формат не важен, так как конвертеры никто не отменял. По большей части речь о том, чтобы открыть браузер, пройтись мышкой по ссылкам и скопипейстить со страниц нужные данные. Ну, или сделать то же самое скриптом.
Цель этой статьи – показать весь процесс создания и использования такого скрипта от постановки задачи и до получения конечного результата. В качестве примера я рассмотрю реальную задачу вроде тех, какие часто можно найти, например, на биржах фриланса, ну, а в качестве инструмента для веб-скрейпинга будем использовать Node.js.
Постановка задачи
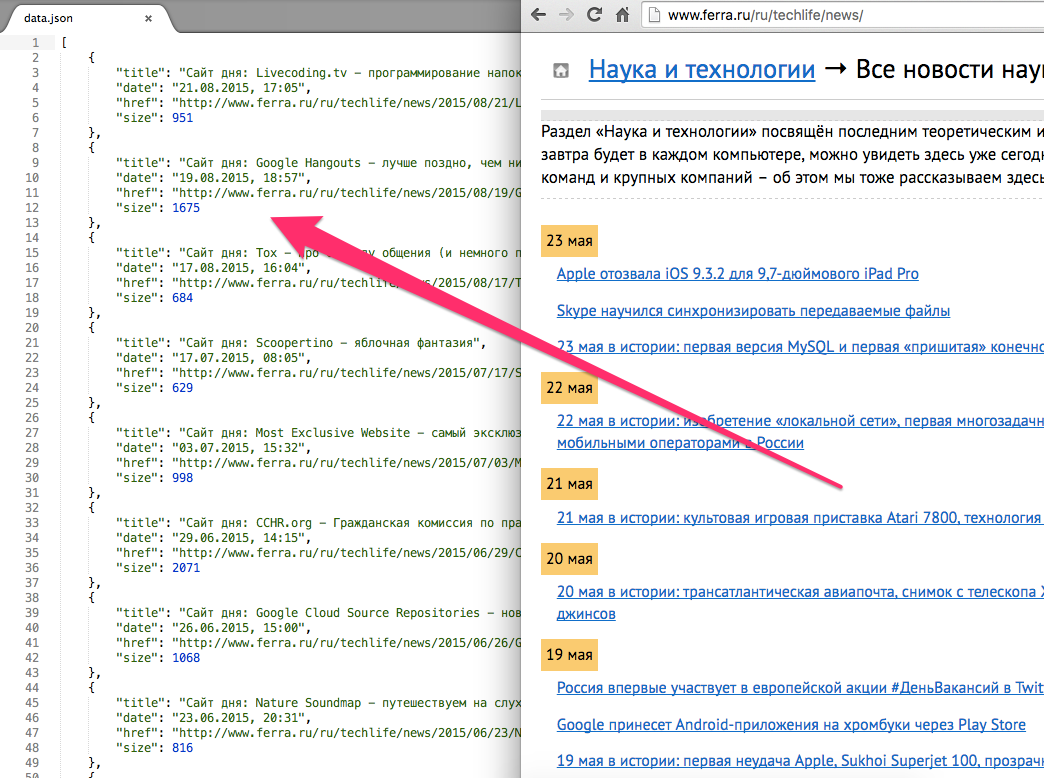 Допустим, я хочу получить список всех статей и заметок, которые я опубликовал на сайте Ferra.ru. Для каждой публикации я хочу получить заголовок, ссылку, дату и размер текста. Удобного API у этого сайта нет, так что придётся скрейпить данные со страниц.
Допустим, я хочу получить список всех статей и заметок, которые я опубликовал на сайте Ferra.ru. Для каждой публикации я хочу получить заголовок, ссылку, дату и размер текста. Удобного API у этого сайта нет, так что придётся скрейпить данные со страниц.
Отдельный раздел на сайте я за долгие годы так и не удосужился организовать, так что все мои публикации лежат вперемешку с обычными новостями. Единственный известный мне способ выделить нужные мне публикации – фильтрация по автору. На страницах со списком новостей автор не указан, так что придётся проверять каждую новость на соответствующей странице. Я помню, что писал только в раздел “Наука и технологии”, так что искать можно не по всем новостям, а по одному разделу.
Вот, примерно в таком виде мне обычно поступают задачи для веб-скрейпинга. Ещё в таких задачах бывают разные сюрпризы и подводные камни, но сходу их не видно и приходится их обнаруживать и улаживать прямо в процессе. Начнём:
Анализ сайта
Нам будут нужны страницы с новостями, ссылки на которые собраны в паджинированном списке. Все нужные страницы доступны без авторизации. Посмотрев в браузере исходники страниц можно убедиться, что все данные содержатся прямо в HTML-коде. Довольно простая задача (собственно, я потому её и выбрал). Похоже, нам не придётся возиться с логином, хранением сессии, отправкой форм, отслеживанием AJAX-запросов, разбором подключённых скриптов и так далее. Бывают случаи, когда анализ целевого сайта занимает в разы больше времени, чем проектирование и написание скрипта, но не в этот раз. Может быть в следующих статьях...
Подготовка проекта
Думаю, нет смысла описывать создание каталога проекта (а в нём пустого файла index.js и простейшего файла package.json), установку Node.js и пакетного менеджера npm, а также установку и удаление модулей через npm.
В реальной жизни разработка проекта сопровождается ведением GIT-репозитория, но это выходит за рамки темы статьи, так что просто имейте в виду, что каждому значимому изменению кода в реальной жизни будет соответствовать отдельный коммит.
Получение страниц
Чтобы получить данные из HTML-кода страницы надо получить этот код с сайта. Это можно делать при помощи http-клиента из модуля http, встроенного в Node.js по умолчанию, однако для выполнения простых http-запросов удобнее использовать разные модули-обёртки над http самым популярным из которых является request так что попробуем его.
Первым делом стоит убедиться, что модуль request получит с сайта такой же HTML-код, какой приходит в браузер. С большинством сайтов это так и будет, но иногда попадаются сайты, отдающие браузеру одно, а скрипту с http-клиентом – другое. Раньше я первым делом проверял целевые страницы GET-запросом из curl, но однажды мне попался сайт, который в curl и в скрипт с request выдавал разные http-ответы, так что теперь я сразу пробую запускать скрипт. Примерно вот с таким кодом:
var request = require('request');
var URL = 'http://www.ferra.ru/ru/techlife/news/';
request(URL, function (err, res, body) {
if (err) throw err;
console.log(body);
console.log(res.statusCode);
});Запускаем скрипт. Если сайт лежит или с подключением проблемы, то вывалится ошибка, а если всё хорошо, то прямо в окно терминала вывалится длинная простыня исходного текста страницы, и можно убедиться, что он практически такой же, как и в браузере. Это хорошо, значит нам не понадобится устанавливать специальные куки или http-заголовки чтобы получить страницу.
Однако, если не полениться и промотать текст вверх до русскоязычного текста, то можно заметить, что request неправильно определяет кодировку. Русскоязычные заголовки новостей, например, выглядят вот так:
4,7-�������� iPhone 7 ���������� �� ����
PC-������ DOOM ������� ������ 4 �������� �����������
Проблема с кодировками сейчас встречается не так часто, как на заре интернета, но всё же достаточно часто (а на сайтах без API – особенно часто). В модуле request предусмотрен параметр encoding, но он поддерживает только кодировки принятые в Node.js для преобразования буфера в строку. Напомню, это ascii, utf8, utf16le (она же ucs2), base64, binary и hex, тогда как нам нужна windows-1251.
Самое распространённое решение для этой проблемы – в request устанавливать encoding в null, чтобы он помещал в body исходный буфер, а для его конвертации использовать модуль iconv или iconv-lite. Например вот так:
var request = require('request');
var iconv = require('iconv-lite');
var opt = {
url: 'http://www.ferra.ru/ru/techlife/news/',
encoding: null
}
request(opt, function (err, res, body) {
if (err) throw err;
console.log(iconv.decode(body, 'win1251'));
console.log(res.statusCode);
});Минус этого решения в том, что на каждом проблемном сайте придётся тратить время на выяснение кодировки. Если этот сайт – не последний, то стоит найти более автоматизированное решение. Если кодировку понимает браузер, то её должен понимать и наш скрипт. Путь для настоящих гиков – найти на GitHub модуль request и помочь его разработчикам внедрить поддержку кодировок из iconv. Ну, или сделать свой форк с блэкджеком и хорошей поддержкой кодировок. Путь для опытных практиков – поискать альтернативу модулю request.
Я в подобной ситуации нашёл модуль needle, и остался настолько доволен, что больше request не использую. С настройками по умолчанию needle определяет кодировку точно также, как это делает браузер, и автоматически перекодирует текст http-ответа. И это не единственное, в чём needle лучше, чем request.
Попробуем получить нашу проблемную страницу при помощи needle:
var needle = require('needle');
var URL = 'http://www.ferra.ru/ru/techlife/news/';
needle.get(URL, function(err, res){
if (err) throw err;
console.log(res.body);
console.log(res.statusCode);
});Теперь всё замечательно. Для очистки совести стоит попробовать то же самое со страницей отдельной новости. Там тоже всё будет хорошо.
Краулинг
Теперь нам нужно получить страницу каждой новости, проверить на ней имя автора, и при совпадении сохранить нужные данные. Так как у нас нет готового списка ссылок на страницы новостей, мы получим его рекурсивно пройдя по паджинированному списку. Как краулеры поисковиков, только более прицельно. Таким образом нам нужно, чтобы наш скрипт брал ссылку, отправлял её на обработку, полезные данные (если найдутся) где-нибудь сохранял, а новые ссылки (на новости или на следующие страницы списка) ставил в очередь на такую же обработку.
Поначалу может показаться, что краулинг проще осуществлять в несколько проходов. Например, сначала рекурсивно собрать все страницы паджинированного списка, затем получить с них все страницы новостей, а затем – обработать каждую новость. Такой подход помогает новичку удержать в голове процесс скрейпинга, но на практике единая одноуровневая очередь для запросов всех типов – это, как минимум, проще и быстрее в разработке.
Для создания такой очереди можно использовать функцию queue из знаменитого модуля async, однако я предпочитаю использовать модуль tress, который обратно совместим с async.queue, но намного меньше, так как не содержит остальных функций модуля async. Маленький модуль хорош не тем, что занимает меньше места (это ерунда), а тем, что его проще быстренько допилить, если это понадобится для особо сложного краулинга.
Очередь из tress работает примерно так:
var tress = require('tress');
var needle = require('needle');
var URL = 'http://www.ferra.ru/ru/techlife/news/';
var results = [];
// `tress` последовательно вызывает наш обработчик для каждой ссылки в очереди
var q = tress(function(url, callback){
//тут мы обрабатываем страницу с адресом url
needle.get(url, function(err, res){
if (err) throw err;
// здесь делаем парсинг страницы из res.body
// делаем results.push для данных о новости
// делаем q.push для ссылок на обработку
callback(); //вызываем callback в конце
});
});
// эта функция выполнится, когда в очереди закончатся ссылки
q.drain = function(){
require('fs').writeFileSync('./data.json', JSON.stringify(results, null, 4));
}
// добавляем в очередь ссылку на первую страницу списка
q.push(URL);Стоит отметить, что наша функция каждый раз будет выполнять http-запрос, и пока он выполняется скрипт будет простаивать. Так скрипт будет работать довольно долго. Чтобы его ускорить можно передать tress вторым параметром количество ссылок, которые можно обрабатывать параллельно. При этом скрипт продолжит работать в одном процессе и в одном потоке, а параллельность будет обеспечиваться за счёт неблокирующих операций ввода/вывода в Node.js.
Парсинг
Тот код, который у нас уже есть, можно использовать как основу для скрейпинга. Фактически, мы создали простейший минифреймворк, который можно понемногу дорабатывать каждый раз, как нам попадётся очередной сложный сайт, а для простых сайтов (которых большинство) можно просто писать фрагмент кода, отвечающий за парсинг. Смысл этого фрагмента будет всегда один и тот же: на входе – тело http-ответа, а на выходе – пополнение массива результатов и очереди ссылок. Инструменты для парсинга на остальной код повлиять не должны.
Гуру парсинга знают, что наиболее мощный и универсальный способ парсинга страниц – это регулярные выражения. Они позволяют парсить страницы с очень нестандартной и крайне антисемантической вёрсткой. В общем случае, если данные можно безошибочно скопипейстить с сайта не зная его язык, то их можно распарсить регулярками.
Однако, большая часть HTML-страниц легко разбирается DOM-парсерами, которые намного удобнее и легче читаются. Регулярки стоит использовать только если DOM-парсеры не справляются. В нашем случае DOM-парсер отлично подойдёт. В настоящий момент среди DOM-парсеров под Node.js уверенно лидирует cheerio – серверная версия культового JQuery.
(Кстати, на Ferra.ru используется JQuery. Это довольно надёжный признак того, что cheerio с таким сайтом справится)
Поначалу может показаться, что удобнее написать отдельный парсер для каждого типа страниц (в нашем случае их два – списки и новости). На деле можно просто искать на странице каждую разновидность данных. Если нужных данных на странице нет, то они просто не найдутся. Иногда приходится подумать, как избежать путаницы если разные данные одинаково выглядят на страницах разного типа, но я ни разу не встречал сайта, где это было бы сложно. Зато я встречал много сайтов, где разные типы данных произвольно сочетались на одних и тех же страницах, так что стоит сразу привыкать писать единый парсер для всех страниц.
Итак, списки ссылок на новости у нас располагаются внутри элемента div с классом b_rewiev. Там есть и другие ссылки, которые нам не нужны, но правильные ссылки легко отличить, так как только у таких ссылок родитель – элемент p. Ссылка на следующую страницу паджинации у нас располагается внутри элемента span с классом bpr_next, и она там одна. На страницах новостей и на последней странице списка такого элемента нет. Стоит учесть, что ссылки в паджинаторе – относительные, так что их надо не забыть привести к абсолютным. Имя автора спрятано в глубине элемента div с классом b_infopost. На страницах списка такого элемента нет, так что если автор совпадает – можно тупо собирать данные новости.
Не стоит забывать и о битых ссылках (спойлер: в разделе, который мы скрейпим, таких ссылок целая одна). Как вариант, можно у каждого запроса проверять код ответа, но бывают сайты, которые отдают страницу битой ссылки с кодом 200 (даже если пишут на ней “404”). Другой вариант – посмотреть в коде такой страницы те элементы, которые мы собираемся искать парсером. В нашем случае таких элементов на странице битой ссылки нет, так что парсер такие страницы просто проигнорирует.
Добавим в наш код парсинг при помощи cheerio:
var tress = require('tress');
var needle = require('needle');
var cheerio = require('cheerio');
var resolve = require('url').resolve;
var fs = require('fs');
var URL = 'http://www.ferra.ru/ru/techlife/news/';
var results = [];
var q = tress(function(url, callback){
needle.get(url, function(err, res){
if (err) throw err;
// парсим DOM
var $ = cheerio.load(res.body);
//информация о новости
if($('.b_infopost').contents().eq(2).text().trim().slice(0, -1) === 'Алексей Козлов'){
results.push({
title: $('h1').text(),
date: $('.b_infopost>.date').text(),
href: url,
size: $('.newsbody').text().length
});
}
//список новостей
$('.b_rewiev p>a').each(function() {
q.push($(this).attr('href'));
});
//паджинатор
$('.bpr_next>a').each(function() {
// не забываем привести относительный адрес ссылки к абсолютному
q.push(resolve(URL, $(this).attr('href')));
});
callback();
});
}, 10); // запускаем 10 параллельных потоков
q.drain = function(){
fs.writeFileSync('./data.json', JSON.stringify(results, null, 4));
}
q.push(URL);В принципе, мы получили скрипт для веб-скрейпинга, который решает нашу задачу (для желающих код на gist). Однако отдавать заказчику я бы такой скрипт не стал. Даже с параллельными запросами этот скрипт выполняется долго, а значит ему как минимум нужно добавить индикацию процесса выполнения. Также сейчас, даже при недолгом перебое со связью, скрипт упадёт не сохранив промежуточных результатов, так что надо сделать либо чтобы скрипт сохранял промежуточные результаты перед падением, либо чтобы он не падал, а вставал на паузу. Ещё я бы от себя добавил возможность принудительно прервать работу скрипта, а потом продолжить с того же места. Это излишество, по большому счёту, но такие “вишенки на торте” очень укрепляют отношения с заказчиками.
Однако если заказчик попросил один раз заскрейпить ему данные и просто прислать файл с результатами, то ничего этого можно и не делать. Всё и так работает (23 минуты в 10 потоков, найдено 1005 публикаций и одна битая ссылка). Если совсем обнаглеть, то можно было бы не делать рекурсивный проход по паджинатору, а сгенерировать по шаблону ссылки на страницы списка за тот период, когда я работал на Ferra.ru. Тогда и скрипт не так долго работал бы. Поначалу это раздражает, но выбор вот таких решений – это тоже важная часть задачи по веб-скрейпингу.
Заключение
В принципе, умея писать подобные скрейперы можно брать заказы на биржах фриланса и неплохо жить. Однако тут есть пара проблем. Во-первых, многие заказчики хотят не конечные данные, а скрипт, который они сами смогут беспроблемно использовать (и у них бывают очень специфические требования). Во-вторых, на сайтах бывают сложности, которые обнаруживаются только когда заказ уже взят и половина работы уже сделана, и приходится либо терять деньги и репутацию, либо совершать умственные подвиги.
В ближайшей перспективе я планирую статьи про более сложные случаи (сессии, AJAX, глюки на сайте и так далее) и про доведение веб-скрейперных скриптов до товарного вида. Вопросы и пожелания приветствуются.
