А что если я скажу вам, что новый продукт можно сразу начинать писать на микросервисной архитектуре, а не заниматься распилом монолита? Это вообще нормально? Удобно? Хотите узнать ответ?
Задача: необходимо написать за выходные (время ограниченно 10-15 часами) сферический блог на микросервисах, на php, не используя никаких фреймворков. Можно пользоваться здравым смыслом. А еще забудем о том что такое фронтенд и вспомним что мы жить не можем без виртуализации. Выберем Docker. Интересно? Вперед под кат.

Микросервисы
Если вам интересен микросервисный подход, но вы не знаете с чего начать, начните с книги "Building Microservices" Сэма Ньюмена. Постараюсь немного описать основные моменты данного подхода, если у вас будут какие-то дополнения, пишите пожалуйста в комментариях. И вообще по любому поводу пишите, я не претендую на истинность какого-либо из описанных ниже подходов, особенно в Вашем конкретном случае.
Будем рассматривать все на примере вышеупомянутого блога. Безусловно, это задача ради задачи, но хочется отметить что даже в таком варианте, это работать будет и будет работать неплохо (быстро и без проблем).
Суть микросервисов легко понять в сравнении с монолитной архитектурой. Как у нас выглядит обычный движок для блога? Грубо говоря это просто одно приложение. Работа с статьями, комментариями, страницами, пользователями и прочими функциональными единицами заключена в едином пакете исходного кода, который не делится никак.

Где все связи между компонентами — это вызовы внутри кода, какие-то отношения между классами, паттерны и т.п. или даже просто говнокод, если нельзя отделить одно от другого.
Как будет выглядеть наш блог? Да примерно также, если честно.
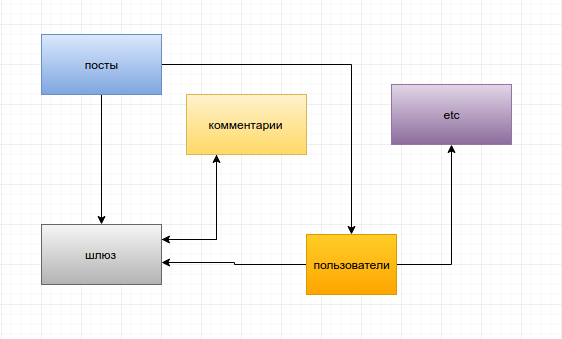
Единственное отличие, что квадратики с компонентами — это больше не компоненты заключенные в код одного приложения, а стрелочки — это больше не системные вызовы классов внутри этого кода. Теперь — это отдельные компоненты, а стрелочки — обычные запросы по http.
Зачем это нужно? Сразу определимся, что наверное, это нужно не всем. Это должно быть очень удобно, если вы — достаточно крупная компания, способная выделить по команде разработки на каждый сервис. Думаю, даже средним компаниям, если выделить по человеку на каждый сервис будет тоже неплохо. Впрочем, даже если ты один на всю компанию, ты сможешь найти в микросервисах что-то интересное.
Насколько большим должен быть сервис? Границы провести сложно, ошибка будет стоить вам дорого, но, если вкратце, то сервис это некая единица вашей системы, которую вы можете полностью переписать за короткое время. Эмпирически пусть за неделю вы или ваша команда должны справится с сервисом. Основная идея тут — сервисы должны быть небольшие. Они не должны превращаться в кучу монолитов.
Итак, позитивные вещи, которые я смог выделить для себя, в целом все они проходят под одним трендом: Невероятное удобство для разработки:
- Отказоустойчивость. Так как связи между сервисами больше не жесткие, сервис может умереть по чьей-то глупости (например сервис комментариев), но в целом на блоге это не скажется никак, кроме того что пропадут комментарии.
- Язык. Вы можете разработывать новый сервис на чем угодно. В общем выбор языка перестает напоминать поиск серебряной пули, для каждого компонента системы вы можете выбрать тот инструмент, который ей подходит больше всего в текущий момент времени. Почему? Потому что это больше не дорого для компании (сервис маленький), вы всегда можете выкатить старый сервис назад, вы даже можете использовать одновременно одинаковые сервисы написанные на разных языках, чтобы понять, что лучше. Цена ошибки неизмеримо меньше.
- Маштабируемость. Приложение тормозит и не справляется? Нужен новый огромный сервер для всего приложения, а лучше 10? Забудьте. Теперь вы можете масштабировать сервисы. Просто добавьте побольше сервисов :)
- В целом высокая скорость работы, как результат всего что выше.
Что должно уметь наше приложение? Так то не очень много.
Четыре страницы:
- Список постов
- Открытый пост с комментариями
- Добавление поста
- Авторизация
Функционал простой:
- Авторизованный пользователь может добавить пост
- Кто угодно может его комментировать.
Docker

Все, не будем больше о теории, давайте пилить приложение. Оно у нас будет на докере. Настолько распределенное приложение разрабатывать на одной машине без виртуализации почти невозможно. Описание работы докера будет представлено обрывками, поскольку выходит за тему данной статьи. Предполагается, что вы о нем что-то знаете.
Кстати, вот ссылка на репу, из которой вы можете скачать и запустить блог, посмотреть что-то по коду ниже. https://github.com/gregory-vc/blog
Сколько будет контейнеров в нашем простейшем блоге? Контейнер, это кстати по сути виртуализация отдельного сервера, который общается по сети с другими контейнерами, правда если проводить жесткую аналогию контейнер=сервер, от некоторых контейнеров нужно будет отказаться, но тем не менее. Для простейшей реализации блога на микросервисах я насчитал 24 контейнера. Давайте посмотрим.
- Общие контейнеры: база для сервиса авторизации, основная база блога, редис.
- Сервис-шлюз: php, контейнер для исходного кода, nginx.
- Сервис для работы с постами: (php, контейнер для исходного кода, nginx) х 2
- Сервис для работы с комментариями: тоже х 2
- Сервис авторизации и аутентификации: тоже х 2
Зачем на по две копии некоторых сервисов? Потому что с одной будет не интересно и не понятно.
Файл docker-compose, который развернет все это одной командой выглядит вот так:
https://github.com/gregory-vc/blog/blob/master/host/docker-compose.yml
Из самого интересного рассмотрим настройки php контейнера нашего шлюза.
'php_gate':
image: 'tattoor/blog_php'
container_name: 'php_gate'
volumes_from: ['source_gate']
volumes: ['./logs/php/gate/:/var/log/dev_php']
links:
- nginx_post_1:post1.blog
- nginx_post_2:post2.blog
- nginx_comment_1:comment1.blog
- nginx_comment_2:comment2.blog
- nginx_auth_1:auth1.blog
- nginx_auth_2:auth2.blog
- redis
environment:
- POST_1_HOST=post1.blog
- POST_1_PORT=80
- POST_2_HOST=post2.blog
- POST_2_PORT=80
- COMMENT_1_HOST=comment1.blog
- COMMENT_1_PORT=80
- COMMENT_2_HOST=comment2.blog
- COMMENT_2_PORT=80
- AUTH_1_HOST=auth1.blog
- AUTH_1_PORT=80
- AUTH_2_HOST=auth2.blog
- AUTH_2_PORT=80Раздел описания контейнера links, это по сути просто редактирование /etc/hosts/
docker exec php_gate cat /etc/hosts
172.17.0.36 auth1.blog 86b8b266477d nginx_auth_1
172.17.0.36 nginx_auth_1 86b8b266477d
172.17.0.21 comment1.blog 836bacb42e78 nginx_comment_1
172.17.0.19 comment2.blog c554a8888801 nginx_comment_2
172.17.0.20 post2.blog 37f81921419c nginx_post_2
172.17.0.7 redis a1932016be87
172.17.0.37 auth2.blog 5715045a213b nginx_auth_2
172.17.0.37 nginx_auth_2 5715045a213b
172.17.0.21 nginx_comment_1 836bacb42e78
172.17.0.19 nginx_comment_2 c554a8888801
172.17.0.22 nginx_post_1 1cc1ef5ab896
172.17.0.22 post1.blog 1cc1ef5ab896 nginx_post_1
172.17.0.20 nginx_post_2 37f81921419c
172.17.0.23 fafe93f31a67Где по обозначенному хосту мы просто имеем доступ к другому контейнеру через внутреннюю сеть докера.
А раздел environment — это просто обозначение переменных, которые мы сможем достать с вами внутри приложения через getenv(). Сделано так, чтобы файл docker-compose был единой точкой входа для настройки всего приложения.
В то время как структура наших сервисов выглядит как просто директории лежащие рядом,
- Auth
- Comment
- Gate
- Post
Но, на самом деле, при запуске докера хостов, каждая из этих директорий оказывается внутри отдельного изолированного соответствующего контейнера. Делается это как-то так:
'source_post_1':
volumes: ['../Services/Post:/home/gregory/source/']То есть, хоть сейчас они и рядом, при запуске не будет возможности из одного сервиса проинклудить класс другого сервиса или что-то типа того. Рядом они исключительно из удобства, в реальной жизни они должны быть каждый в своем репозитории, вообще не касаясь друг друга.
Сервис Gate

Этот сервис будет являтся точкой входа на наш блог, именно он будет рендерить шаблоны, отображать результат и дергать нужные ему сервисы. Кстати существуют разные подходы, например можно отказаться от единой точки входа и реализовать все на фронтенде. То есть браузер сам будет ходить в нужные сервисы и собирать результат прямо в браузере. Что сказать, все зависит от вашего конкретного случая и там и там есть свои плюсы и минусы.
Итак, у нас есть php и больше ничего. Хотя, давайте возьмем хотя бы composer, куда без него. Создадим еще две директории, одну с нашим микрофреймворком, который мы сейчас напишем, вторую для public скриптов, js, и прочих ресурсов.
Выглядит так:
- My
- public
- composer.json
В composer просто укажем, откуда осуществлять autoload, чтобы нам самим с этим не заморачиваться, и подключим сгенеренный autoload в public/index.php
Так, что-то у нас уже есть, давайте определимся что нам вообще еще будет надо?
- MVC, а значит контроллеры
- Место для бизнес логики
- Шаблоны
- Шаблонизатор
Неплохо, что еще?
- Немного di, самый простой, ввиде хранилища объектов.
- Само хранилище
- Запрос
- Ответ
- Роутинг, о да, с него стоит начать.
- Сессии и прочее по мелочи.
Напишем вот такое хранилище объектов, чтобы не создавать их где попало, а иметь возможность получить доступ (inject) к уже созданным в любой точке приложения со всем нужными зависимостями (dependency). Мы не будем развлекаться с Reflection и прочими интересными штуками, время у нас жестко ограничено.
Storage::set('Request', new Request());
Storage::set('Router', new Router());
Storage::set('Redirect', new Redirect());
Storage::set('App', new App());В Di, используя это хранилище просто добавляем все объекты что нам нужны.
В паблике стартуем Di, получаем роутер, регистрируем все урлы что нам пригодятся, получаем приложение и стартуем его.
$router->get('/logout/', 'AuthController@logout');
$router->get('/404', 'SystemController@notFound');
$router->post('/post/add_request/', 'PostController@add')В приложении получаем request, маппим в роутере существующий экшен существующего контроллера по этому реквесту, одновременно еще записываем в request все пост или гет переменные, что нам пришли.
Выполняем метод контроллера, получаем response, рендерим response и показываем результат нашей работы, все.
$current_request = $this->router->getCurrent();
$controller = new $current_request->controller;
$response = $controller->{$current_request->method}();
$response->render();Каркас есть, теперь нам надо работать с сервисами, создаем директорию с сервисами, создаем класс каждого сервиса, описываем точки доступа к каждому из сервисов. Наследуем их от основного класса сервисов, где реализуем варианты запросов.
https://github.com/gregory-vc/blog/blob/master/Services/Gate/My/Engine/Service.php
static public function get($method, $params = [])
{
$service = new static;
return $service->executeGet($method, $params);
}
static public function post($method, $params = [])
{
$service = new static;
return $service->executePost($method, $params);
}Там внутри при запросе выбираем рандомны коннектор из предоставляемых сервисом, как-то так
$rand_connector = rand(0, $count_connector) % $count_connector;Делаем запрос, из контроллера и рендерим, вот так:
$posts = Post::get('all');
return $this->response->html('posts', $posts);Нам нужно отрендерить, но как? Шаблонизаторов у нас нет. Писать свой? Ну нет. Просто используем php.
ob_start();
require_once($layout_template);
$contents = ob_get_contents();
ob_end_clean();
$this->content = $contents;Черезвычайно мощный шаблонизатор размером с 4 строчки.
Сервис post и comment
Что дальше? Теперь мы можем делать запросы и рендерить результат, теперь нам нужно написать сервисы отдающие ответ. Все просто копируем наш новый движок в другие сервисы, меняем урлы и пишем работу с моделями и бд, вместо удаленных сервисов.
Реализуем работу с моделями, стандартно findAll, findBy, add, save:
https://github.com/gregory-vc/blog/blob/master/Services/Auth/My/Engine/Model.php
Итак? Если честно, это почти все, что нам нужно, не считая авторизации.
Мы можем делать запросы gate на любой сервис, с любого другого сервиса на любой другой.
Сервис авторизации
Схема проста: мы имеем юзеров и их доступы на сервере авторизации, мы делаем из шлюза запрос на авторизацию, генерируем токен, возвращаем его шлюзу и еще юзера, кладем юзера и токен в сессию и все. Незабываем посылать токен вместе с запросом на добавление поста, потому что что? Правильно, сервис постов пойдет в сервис авторизации и спросит, а правда ли что этот токен хорош? В зависимости от результата генерим разные эксепшены.
public function login($user, $password) {
$hash = hash('sha256', $password);
$user = User::findBy([
'login' => $user,
'password' => $hash
]);
if (!empty($user) && is_array($user)) {
$user = current($user);
$user['token'] = bin2hex(random_bytes(30));
User::save($user);
return [
'login' => $user['login'],
'token' => $user['token']
];
} else {
throw new \Exception('Not found user');
}
}Результат
Вообще, можете скачать и развернуть его одной командой, напомню репозиторий: https://github.com/gregory-vc/blog
Где подходило по смыслу — я вывел для наглядности какой именно нодой был сгенерен тот или иной блок.
Еще меня впечатлило время генерации странички. Это 5-9 мс для странички с постом и несколькими комментариями (!). Да, все это необъективно, да, все это попугаи, да, микросервисы тут не при чем, да, смотря с чем сравнивать. Но. Тот же ларавель генерит свою страничку, вообще без запросов и данных, просто приветствие, за 90 мс, на моей же машине. Это в 10-20 раз дольше.
Я понимаю, что там происходит куда больше всего, не сравнить, но тем не менее, попытаюсь выразить мысль: для конкретно текущей задачи отдельного изолированного микросервиса всего этого и не надо. Для сервиса комментов я выкинул класс работы с сервисами по сети. Для сервиса шлюза я выкинул класс работы с базой. Для каждого конретного сервиса я собрал лишь то, что ему надо. А правильном сервису надо совсем чуть-чуть :)
А главное это невероятный потенциал для масштабирования этого блога под просто невероятные нагрузки. Никто не помешает например потом взять и переписать сервис комментариев на Go.
Проблемы
Сетевые накладные расходы
Не зная о том как работает другой сервис, мы можем вполне попасть в ситуацию, когда, он не то что работает плохо, и портит нам все, он еще и использует наш сервис (!) чтобы нам же отдать наши результаты.
Напомню как все это попробовать
Clone
git clone https://github.com/gregory-vc/blog.git .
Install Docker:
wget -qO- https://get.docker.com/ | sh
sudo usermod -aG docker user
sudo apt-get install python-pip
sudo pip install docker-compose
Compile
chmod 744 compile
./compile
chmod 744 upload_db
./upload_db
Run
http://gate.blog:30001/
admin
admin