В этой короткой статье я попробую показать, почему ваш HL7 CDA документ, скорее всего, не соответствует стандарту, а также предположить, что с этим делать.
Что такое Clinical Document Architecture (CDA) я уже, также кратко, описывал в другом посте — habrahabr.ru/post/255879
Сразу замечу, что «полное» описание CDA займёт целую книжку объёмом страниц так на 300, одна из существующих так и называется "The CDA Book". Поэтому нет ни какой возможности в одной статье рассказать про все особенности данного стандарта.
Напомню, Clinical Document Architecture – один из 20-ти доменов стандарта HL7v3. Если вы знакомы с v3, а я надеюсь большинство читателей хоть немного представляют, что это такое, то знаете, что в данной версии все артефакты строятся на основе HL7 Reference Information Model (RIM).
Чтобы дальнейшее объяснение было понятнее давайте разберёмся как строятся модели в HL7v3. Начать стоит с RIM, который выглядит следующим образом:

Как не трудно заметить, RIM основан на 4 базовых классах: Entity, Role, Participation и Act, и двух дополнительных классах для описания отношений: Role Link и Act Relationship. Понятие «класс» для тех, кто хоть раз сталкивался с разработкой программного обеспечения, наверняка наводит на мысль об объектно-ориентированной структуре RIM и, надо сказать, это почти верно. Почему почти, потому что RIM следует основным принципам наследования в ООП. В стандарте явно указаны:
А вот дальше начинаются разночтения. Для получения требуемых сообщений, HL7v3 используется refinement process (процесс уточнения) что приводит к созданию нескольких Domain Message Information Model (D-MIM) для доменов и множества Refined Message Information Model (R-MIM) в каждом из них. Из R-MIM, следуя тем же правилам, получаются конечные Hierarchical Message Descriptions (HMD) из которых, в свою очередь, и строятся сообщения.
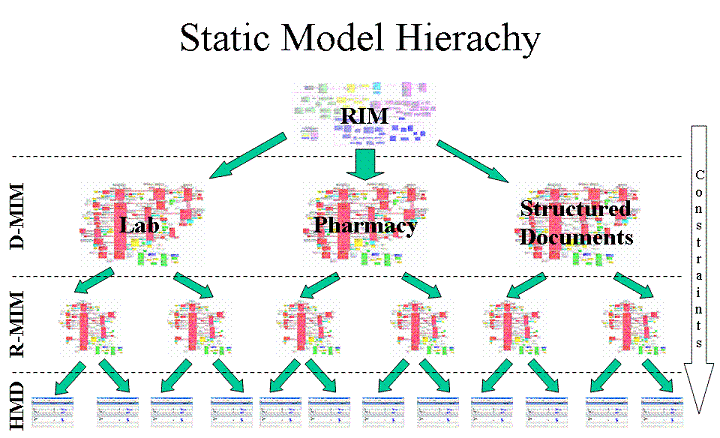
Процесс уточнения (refinement) основывается на constraint process (ограничениях) и localization process (локализация). Как видно из названия, процесс ограничения не предполагает дальнейшего расширения или переопределения классов, наоборот, класс-наследник может включать все или некоторые свойства своего класса-родителя, но не более. Процесс локализации предполагает, что некоторые модели не в полной мере соответствуют бизнес требованиям и нуждаются в дополнении. Такие дополнения, чаще всего реализованные в виде extensions (расширений) в последующем, возможно, станут частью модели. Хотя гораздо чаще можно услышать, что если вам нужны расширения, то, вероятно, вы неправильно описывается ваши бизнес-процессы.
И так, немного разобравшись в процессе реализации моделей HL7v3, давайте вернёмся обратно к CDA, а именно к CDA R-MIM, к той части, которая описывает тело документа.

Все классы для выбора в clinicalStatement наследуются от класса Act. Например, для приведённого класса Observation, основное описание стоит искать не в секции Universal Domains -> Clinical Document Architecture (хотя там тоже имеет смысл, но чтобы узнать о каких-то дополнительных особенностях использования этого класса), а в Foundation -> Reference Information Model -> Classes -> Observation.

Аналогично для entryRelationship. Если воспользоваться только описанием в самом домене Clinical Document Architecture, то можно понять, что «CDA has identified and modeled various link and reference scenarios», а также особенности использования entryRelationship.inversionInd и entryRelationship.contextConductionInd.
Однако, как можно заметить, entryRelationship наследует и другие атрибуты от своего класса-родителя, ActRelationship. В том числе ActRelationship.seperatableInd, который по умолчанию «true» и используется для «an indication that the source Act is intended to be interpreted independently of the target Act. Indicates the author's desire and willingness to attest to the content of the source Act if separated from the target Act.» (источник HL7 NE)
Таким образом, если ваш шаблон CDA секции, вероятнее всего, использует entryRelationship для описания клинических состояний, например: тип аллергической реакции — аллергические агенты – аллерген — степень проявления, то посколько ActRelationship.seperatableInd = true по умолчанию, то по закону наследования, все ваши описания независимы друг от друга. Т.е., аллерген существует в документе сам по себе, он ни с кем не связан и ни кого не определяет. Также как и «степень проявления» непонятно чего существует сама по себе в непонятно каких условиях.
Если же цель, чтобы «the target (для внутреннего класса Observation) cannot stand by itself without knowledge of the source act (для внешнего класса Act), then this class attribute should be set to “false”». (источник «The CDA Book», с моими добавлениями в скобках)
Т.е. чтобы все вложения несли тот смысл, который в них был первоначально заложен, в каждом случае должен быть entryRelationship.seperatableInd = false в явном виде.
Однако, вы едва ли найдёте хоть один пример использования этого атрибута в реальном CDA документе или шаблоне документа CDA.
Что же делать?
Извечный вопрос. Скорее всего ни чего. Ждать пока HL7 поправит модель, либо описание в одной из следующих версий HL7v3 Normative Edition, где этот атрибут будет false по умолчанию.
Либо самим сделать такие исправления в XML схеме POCD_MT000040.EntryRelationship.
Либо добавить одну строчку в свою спецификацию обозначив, что по умолчанию данный атрибут всегда false.
Update: Я рад, что кто-то минусует. Но от того, что вы минусуете, эта, а также множество других проблем, связанных с CDA conformance tests, не исчезает.
Update2: А кто-то обратил внимание, что C-CDA R2.1 в некоторых случаях требует (SHALL) использовать CD.qualifier элемент, который в XML схеме представлен как:
<xs:element name=«qualifier» type=«CR» minOccurs=«0» maxOccurs=«0»/>
Что такое Clinical Document Architecture (CDA) я уже, также кратко, описывал в другом посте — habrahabr.ru/post/255879
Сразу замечу, что «полное» описание CDA займёт целую книжку объёмом страниц так на 300, одна из существующих так и называется "The CDA Book". Поэтому нет ни какой возможности в одной статье рассказать про все особенности данного стандарта.
Напомню, Clinical Document Architecture – один из 20-ти доменов стандарта HL7v3. Если вы знакомы с v3, а я надеюсь большинство читателей хоть немного представляют, что это такое, то знаете, что в данной версии все артефакты строятся на основе HL7 Reference Information Model (RIM).
Чтобы дальнейшее объяснение было понятнее давайте разберёмся как строятся модели в HL7v3. Начать стоит с RIM, который выглядит следующим образом:
Как не трудно заметить, RIM основан на 4 базовых классах: Entity, Role, Participation и Act, и двух дополнительных классах для описания отношений: Role Link и Act Relationship. Понятие «класс» для тех, кто хоть раз сталкивался с разработкой программного обеспечения, наверняка наводит на мысль об объектно-ориентированной структуре RIM и, надо сказать, это почти верно. Почему почти, потому что RIM следует основным принципам наследования в ООП. В стандарте явно указаны:
- Generalization (обобщение) — когда класс-наследник включает все свойства класса-родителя.
- Specialization (специализация) — класс-наследник переопределяет некоторые функции родителя, а также определяет дополнительные свойства для ещё большей специализации.
А вот дальше начинаются разночтения. Для получения требуемых сообщений, HL7v3 используется refinement process (процесс уточнения) что приводит к созданию нескольких Domain Message Information Model (D-MIM) для доменов и множества Refined Message Information Model (R-MIM) в каждом из них. Из R-MIM, следуя тем же правилам, получаются конечные Hierarchical Message Descriptions (HMD) из которых, в свою очередь, и строятся сообщения.
Процесс уточнения (refinement) основывается на constraint process (ограничениях) и localization process (локализация). Как видно из названия, процесс ограничения не предполагает дальнейшего расширения или переопределения классов, наоборот, класс-наследник может включать все или некоторые свойства своего класса-родителя, но не более. Процесс локализации предполагает, что некоторые модели не в полной мере соответствуют бизнес требованиям и нуждаются в дополнении. Такие дополнения, чаще всего реализованные в виде extensions (расширений) в последующем, возможно, станут частью модели. Хотя гораздо чаще можно услышать, что если вам нужны расширения, то, вероятно, вы неправильно описывается ваши бизнес-процессы.
И так, немного разобравшись в процессе реализации моделей HL7v3, давайте вернёмся обратно к CDA, а именно к CDA R-MIM, к той части, которая описывает тело документа.
Все классы для выбора в clinicalStatement наследуются от класса Act. Например, для приведённого класса Observation, основное описание стоит искать не в секции Universal Domains -> Clinical Document Architecture (хотя там тоже имеет смысл, но чтобы узнать о каких-то дополнительных особенностях использования этого класса), а в Foundation -> Reference Information Model -> Classes -> Observation.
Аналогично для entryRelationship. Если воспользоваться только описанием в самом домене Clinical Document Architecture, то можно понять, что «CDA has identified and modeled various link and reference scenarios», а также особенности использования entryRelationship.inversionInd и entryRelationship.contextConductionInd.
Однако, как можно заметить, entryRelationship наследует и другие атрибуты от своего класса-родителя, ActRelationship. В том числе ActRelationship.seperatableInd, который по умолчанию «true» и используется для «an indication that the source Act is intended to be interpreted independently of the target Act. Indicates the author's desire and willingness to attest to the content of the source Act if separated from the target Act.» (источник HL7 NE)
Таким образом, если ваш шаблон CDA секции, вероятнее всего, использует entryRelationship для описания клинических состояний, например: тип аллергической реакции — аллергические агенты – аллерген — степень проявления, то посколько ActRelationship.seperatableInd = true по умолчанию, то по закону наследования, все ваши описания независимы друг от друга. Т.е., аллерген существует в документе сам по себе, он ни с кем не связан и ни кого не определяет. Также как и «степень проявления» непонятно чего существует сама по себе в непонятно каких условиях.
Если же цель, чтобы «the target (для внутреннего класса Observation) cannot stand by itself without knowledge of the source act (для внешнего класса Act), then this class attribute should be set to “false”». (источник «The CDA Book», с моими добавлениями в скобках)
Т.е. чтобы все вложения несли тот смысл, который в них был первоначально заложен, в каждом случае должен быть entryRelationship.seperatableInd = false в явном виде.
Однако, вы едва ли найдёте хоть один пример использования этого атрибута в реальном CDA документе или шаблоне документа CDA.
Что же делать?
Извечный вопрос. Скорее всего ни чего. Ждать пока HL7 поправит модель, либо описание в одной из следующих версий HL7v3 Normative Edition, где этот атрибут будет false по умолчанию.
Либо самим сделать такие исправления в XML схеме POCD_MT000040.EntryRelationship.
Либо добавить одну строчку в свою спецификацию обозначив, что по умолчанию данный атрибут всегда false.
Update: Я рад, что кто-то минусует. Но от того, что вы минусуете, эта, а также множество других проблем, связанных с CDA conformance tests, не исчезает.
Update2: А кто-то обратил внимание, что C-CDA R2.1 в некоторых случаях требует (SHALL) использовать CD.qualifier элемент, который в XML схеме представлен как:
<xs:element name=«qualifier» type=«CR» minOccurs=«0» maxOccurs=«0»/>
