Зависит ли производительность mass storage устройства от содержимого записываемых файлов? Во времена, когда монополия на реализацию внешней памяти вычислительных систем принадлежала накопителям на магнитных дисках, такой вопрос показался бы странным. Очевидно, в таких устройствах, время передачи файла определяется его размером, а также фрагментацией, заставляющей устройство выполнять дополнительное позиционирование. И нет причин для возникновения зависимости скорости от содержимого, если говорить исключительно об аппаратной производительности, не принимая во внимание программные драйверы, выполняющие архивацию или шифрование данных на уровне файловой системы. А как обстоят дела с данным вопросом у твердотельных дисков?
На этот вопрос мы попытались найти ответ, написав java-приложение, использующее Non-Blocking I/O технологию обмена. В итоге появился NIOBench, с помощью которого можно получить бенчмарки магнитных и твердотельных носителей с различными интерфейсами, а фактически – любого внешнего накопителя (за исключением, разве что, устройств с дисциплиной доступа Read Only, но и на них есть свои планы).
В процессе разработки возник ряд ситуаций, когда нужно было определяться со сценариями тестирования. Оставим рабочие моменты в стенах лаборатории, остановимся подробно на таком важном аспекте, как выбор тестового паттерна. Использовать эвристические методы, как это реализовано, например, в AS SSD, не было резона: по сути, — это повторение пройденного. Решено было искать свой вариант. Прежде, чем перейти к его изложению, немного нудных воспоминаний.
Современные микросхемы энергонезависимой Flash-памяти, применяемые в твердотельных накопителях располагают собственным встроенным автоматом записи, оптимально управляющим процессом программирования запоминающей матрицы. Внутри такой микросхемы находится основная часть логики программатора постоянного запоминающего устройства (ПЗУ). Это обстоятельство не только делает электронное устройство компактным, но и охраняет интеллектуальную собственность производителя, превращая чип в «черный ящик».
Поэтому, для наглядности, рассмотрим «антикварные» микросхемы с электрическим программированием, ультрафиолетовым стиранием и объемом 2 килобайта. Очевидно, устройства 30-летней давности существенно отличаются от современных, тем не менее, ряд физических принципов и эффектов, сохранили свою актуальность.

Рис. 1. Интерфейс микросхем содержит линии адреса, данных, управления и питания
Как известно, после стирания такой микросхемы, ячейки памяти устанавливаются в состояние 0FFh или «все единицы». Байты, значение которых должно быть 0FFh можно просто не записывать. Кроме того, количество и(или) длительность программирующих импульсов, необходимых для записи байта, зависит от соотношения количества нулей и единиц в этом байте. Таким образом, налицо зависимость времени записи от данных. Отметим, что если в записываемых данных нулей значительно больше, чем единиц, разработчик устройства может принять решение хранить данные в инверсном виде, сэкономив не только время записи, но и ресурс микросхемы и даже некоторую (пусть и микроскопическую) часть потребляемой мощности.
Накопитель, архивирующий информацию неизбежно должен использовать алгоритм, анализирующий и преобразующий потоки данных, курсирующие между хост-интерфейсом и матрицей Flash-памяти.
А это означает, что время обработки данных будет различным, в зависимости от энтропии, если, конечно, разработчик устройства не нивелирует этот эффект намеренно.
В версии v0.42 бенчмарка NIOBench реализован сценарий заполнения тестовых паттернов (копируемых файлов) псевдослучайными данными. По умолчанию в качестве заполнителя используются нули.
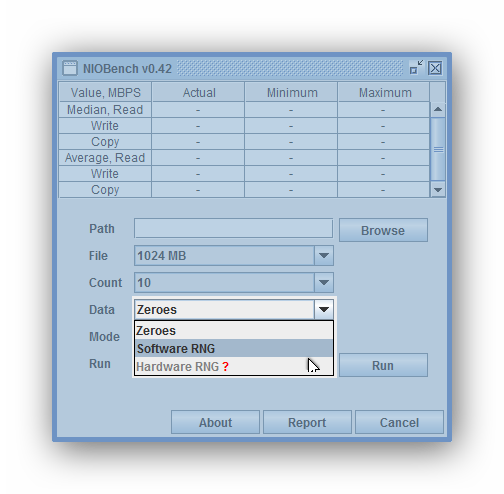
Поддерживается два вида генераторов случайных чисел:
Если инструкция RDRAND не поддерживается, либо отсутствует нативная библиотека под данную ОС, опция Hardware RNG не активируется — бенчмарки можно выполнить в режиме заполнения нулями либо c программной генерацией тестового паттерна псевдослучайными числами. Опция Data, выбирает один из трех методов тестирования:
Режимы 1 и 2 поддерживаются на всех платформах. Режим 3 поддерживается при условии поддержки процессором инструкции RDRAND и наличия нативной библиотеки для данной ОС. В этой версии присутствуют нативные библиотеки для Windows 32/64. Планируется поддержка инструкции RDRAND и под Linux.
Нативные библиотеки упакованы в составе выполняемого JAR-архива. Подключение к java приложению, процедур, написанных на ассемблере, базируется на спецификации JNI (Java Native Interface).
В ходе тестовых операций таблица в верхней части окна утилиты NIOBench заполняется полученными результатами. По столбцам разнесена статистика бенчмарок: средняя, минимальная и максимальная скорости. Построчно выводятся медианы чтения, записи и копирования, а затем — средние значения, полученные в процессе выполнения этих же операций.

Пользователь может сохранить текстовый рапорт выполнения бенчмарок. В нем детально представлены результаты по каждой из итераций, заданных в поле Count. Данные, участвующие в вычислениях медиан, отмечены литерой «M».

При разработке сценария теста, поставлена задача измерить исключительно производительность накопителя (либо схем архивации данных, работающих на уровнях, ниже файловых API, что возможно в некоторых системах хранения данных) и ее зависимость от данных. При этом необходимо исключить зависимость результатов от производительности самого генератора случайных чисел. Поэтому массивы тестовых данных заполняются один раз при старте приложения, а не во время выполнения измерительной операции. В зависимости от состояния опции Data, выбирающей метод тестирования, используется один из трех заранее подготовленных массивов (нули, soft-RNG, hard-RNG). Тестовые данные повторяются с периодом 1 мегабайт.
Написание и отладка java-приложения выполнены в среде NetBeans 8.1. Ассемблерные библиотеки написаны в среде FASM Editor 2.0, оттранслированы с помощью Flat Assembler 1.71.49. Отладка 32-битного ассемблерного кода выполняется в OllyDbg v2.01. Отладка 64-битного ассемблерного кода выполняется в FDBG v0025.
На этот вопрос мы попытались найти ответ, написав java-приложение, использующее Non-Blocking I/O технологию обмена. В итоге появился NIOBench, с помощью которого можно получить бенчмарки магнитных и твердотельных носителей с различными интерфейсами, а фактически – любого внешнего накопителя (за исключением, разве что, устройств с дисциплиной доступа Read Only, но и на них есть свои планы).
В процессе разработки возник ряд ситуаций, когда нужно было определяться со сценариями тестирования. Оставим рабочие моменты в стенах лаборатории, остановимся подробно на таком важном аспекте, как выбор тестового паттерна. Использовать эвристические методы, как это реализовано, например, в AS SSD, не было резона: по сути, — это повторение пройденного. Решено было искать свой вариант. Прежде, чем перейти к его изложению, немного нудных воспоминаний.
Фактор нулей и единиц
Современные микросхемы энергонезависимой Flash-памяти, применяемые в твердотельных накопителях располагают собственным встроенным автоматом записи, оптимально управляющим процессом программирования запоминающей матрицы. Внутри такой микросхемы находится основная часть логики программатора постоянного запоминающего устройства (ПЗУ). Это обстоятельство не только делает электронное устройство компактным, но и охраняет интеллектуальную собственность производителя, превращая чип в «черный ящик».
Поэтому, для наглядности, рассмотрим «антикварные» микросхемы с электрическим программированием, ультрафиолетовым стиранием и объемом 2 килобайта. Очевидно, устройства 30-летней давности существенно отличаются от современных, тем не менее, ряд физических принципов и эффектов, сохранили свою актуальность.
Рис. 1. Интерфейс микросхем содержит линии адреса, данных, управления и питания
Как известно, после стирания такой микросхемы, ячейки памяти устанавливаются в состояние 0FFh или «все единицы». Байты, значение которых должно быть 0FFh можно просто не записывать. Кроме того, количество и(или) длительность программирующих импульсов, необходимых для записи байта, зависит от соотношения количества нулей и единиц в этом байте. Таким образом, налицо зависимость времени записи от данных. Отметим, что если в записываемых данных нулей значительно больше, чем единиц, разработчик устройства может принять решение хранить данные в инверсном виде, сэкономив не только время записи, но и ресурс микросхемы и даже некоторую (пусть и микроскопическую) часть потребляемой мощности.
Фактор сжатия
Накопитель, архивирующий информацию неизбежно должен использовать алгоритм, анализирующий и преобразующий потоки данных, курсирующие между хост-интерфейсом и матрицей Flash-памяти.
А это означает, что время обработки данных будет различным, в зависимости от энтропии, если, конечно, разработчик устройства не нивелирует этот эффект намеренно.
Тест NIOBench
В версии v0.42 бенчмарка NIOBench реализован сценарий заполнения тестовых паттернов (копируемых файлов) псевдослучайными данными. По умолчанию в качестве заполнителя используются нули.
Поддерживается два вида генераторов случайных чисел:
- Программный, методы класса java.util.Random
- Аппаратный, инструкция RDRAND, опционально поддерживаемая процессорами
Если инструкция RDRAND не поддерживается, либо отсутствует нативная библиотека под данную ОС, опция Hardware RNG не активируется — бенчмарки можно выполнить в режиме заполнения нулями либо c программной генерацией тестового паттерна псевдослучайными числами. Опция Data, выбирает один из трех методов тестирования:
- Zeroes — заполнение тестовых файлов нулями
- Software RNG (Random Number Generator) — заполнение тестовых файлов псевдослучайными данными, полученными программно, методами класса java.util.Random
- Hardware RNG — заполнение тестовых файлов псевдослучайными данными, полученными аппаратно, с помощью машинной инструкции RDRAND
Режимы 1 и 2 поддерживаются на всех платформах. Режим 3 поддерживается при условии поддержки процессором инструкции RDRAND и наличия нативной библиотеки для данной ОС. В этой версии присутствуют нативные библиотеки для Windows 32/64. Планируется поддержка инструкции RDRAND и под Linux.
Нативные библиотеки упакованы в составе выполняемого JAR-архива. Подключение к java приложению, процедур, написанных на ассемблере, базируется на спецификации JNI (Java Native Interface).
О результатах
В ходе тестовых операций таблица в верхней части окна утилиты NIOBench заполняется полученными результатами. По столбцам разнесена статистика бенчмарок: средняя, минимальная и максимальная скорости. Построчно выводятся медианы чтения, записи и копирования, а затем — средние значения, полученные в процессе выполнения этих же операций.
Пользователь может сохранить текстовый рапорт выполнения бенчмарок. В нем детально представлены результаты по каждой из итераций, заданных в поле Count. Данные, участвующие в вычислениях медиан, отмечены литерой «M».
При разработке сценария теста, поставлена задача измерить исключительно производительность накопителя (либо схем архивации данных, работающих на уровнях, ниже файловых API, что возможно в некоторых системах хранения данных) и ее зависимость от данных. При этом необходимо исключить зависимость результатов от производительности самого генератора случайных чисел. Поэтому массивы тестовых данных заполняются один раз при старте приложения, а не во время выполнения измерительной операции. В зависимости от состояния опции Data, выбирающей метод тестирования, используется один из трех заранее подготовленных массивов (нули, soft-RNG, hard-RNG). Тестовые данные повторяются с периодом 1 мегабайт.
Технология разработки и отладки
Написание и отладка java-приложения выполнены в среде NetBeans 8.1. Ассемблерные библиотеки написаны в среде FASM Editor 2.0, оттранслированы с помощью Flat Assembler 1.71.49. Отладка 32-битного ассемблерного кода выполняется в OllyDbg v2.01. Отладка 64-битного ассемблерного кода выполняется в FDBG v0025.