По мотивам недавних обсуждений здесь захотелось более широко взглянуть на вопрос о том, кто больше кушает — новомодные хипстерские лямбды или старые проверенные анонимные классы. Давайте устроим словесную перепалку между ними и посмотрим, кто выиграет. Как с любым добротным холиваром, даже если не удастся выяснить победителя, можно узнать много нового для себя.
Первый раунд. Пространство на экране.
Лямбда-кун: хе. Хе-хе-хе. Нет, это несерьёзно. Ну как может сравниться вот это убожество:
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println("Hello!");
}
};С вот этой красотой:
Runnable r = () -> System.out.println("Hello!");Анон-сан: ну-ну, молодой человек, незачем так выражаться. В наши дни никого не волнует, что там в файле на самом деле. Достаточно взять хорошую IDE и разница уже практически незаметна.
Вот как выглядит анонимный класс:
А вот лямбда: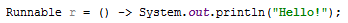
Анон-сан: при этом меня можно развернуть и посмотреть, что я такое на самом деле, а вот что вы такое на самом деле — большая загадка.
Второй раунд. Пространство на диске.
Лямбда-кун: кх-хм… Нет, это, конечно, нечестно. Ну ладно. Но на диске-то я занимаю меньше. Возьмём простой класс:
public class Test {
Runnable r = () -> {};
}А с тобой будет вот что:
public class Test {
Runnable r = new Runnable() {
@Override
public void run() {
}
};
}52 байта против 126! Каково, а?
Анон-сан: ну с байтами исходников я соглашусь, хотя кого они волнуют. А если скомпилировать?
Лямбда-кун: естественно, я выиграю! Из меня получится один файл, а из тебя вообще два! В двух файлах вдвое больше заголовков и всякой метаинформации.
Анон-сан: не спешите, молодой человек, давайте проверим. Запускаем javac Test.java для обоих версий. Что мы видим? Вариант с анонимным классом генерирует Test.class (308 байт) и Test$1.class (377 байт), всего 685 байт, а вариант с лямбдой генерирует только Test.class, зато он весит 783 байта. Почти сто байтов оверхед — не дороговато ли за синтаксический сахар?
Лямбда-кун: эээ, как это получилось? Не могло быть, я же легковеснее! Ну-ка, а с отладочной информацией сколько будет? Все же с ней компилируют.
Анон-сан: давайте попробуем: javac -g Test.java. Лямбда — 838 байт, анонимный класс — 825 байт. Так разница меньше, но всё же хвалёной легковесности не видно. Вы забываете, что на каждый вызов лямбды создаётся развесистая запись в Bootsrtap methods, которая анонимным классам не нужна.
Лямбда-кун: стой, стой. Я всё понял. Это не сама запись развесистая, а константы, которые попадают в пул констант. Всякие штуки вроде java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;. Да, они длинные, но переиспользуются, если лямбд больше одной. Ну-ка, добавим вторую:
public class Test {
Runnable r = () -> {};
Runnable r2 = () -> {};
}Лямбда-кун: вооот, уже я выигрываю! С отладочной информацией 957 байт, а если заменить на анонимные классы, будет ажно 1351 байт в трёх файлах. Даже без отладочной информации я выигрываю. А ведь могут и другие константы эффективно переиспользоваться! Любые поля, методы, классы, используемые внутри лямбд. Если они используются в нескольких лямбдах или в лямбде и вокруг неё, то схлопнутся в одну константу. А с анонимными классами в каждом будет копия. То-то же!
Третий раунд. Классы в рантайме.
Анон-сан: видимо, тут мне придётся уступить. Если лямбд много, то вы действительно компактнее в скомпилированном виде. Однако более интересно, что происходит в рантайме, в памяти виртуальной машины. Пусть для тебя нету анонимного класса на диске, но точно такой же класс, а то и больший, будет сгенерирован при запуске и сожрёт все те же ресурсы.
Лямбда-кун: а вот и не те же! Я же легковеснее! Там наверняка сгенерируется маленький компактный классик, который не содержит всякой ненужной ерунды. Да и как ты это проверишь? Оно ж всё в рантайме в памяти!
Анон-сан: а вот этого вам стыдно не знать. Должны же вас как-то отлаживать разработчики. Есть недокументированное системное свойство jdk.internal.lambda.dumpProxyClasses, с помощью которого можно указать, в какой каталог скидывать сгенерированные рантайм-представления лямбд. Запускаем приложение с -Djdk.internal.lambda.dumpProxyClasses=. и всё видим.
Лямбда-кун: ага, только пока лямбду ни разу не используешь, рантайм-представление не будет сгенерировано вообще, а анонимные классы существуют всегда, даже если ни разу не пригодились!
Анон-сан: нет никакой разницы. Даже наоборот, разница не в вашу пользу. Анонимный класс существует всегда на диске, но он не будет загружен в память, пока не используется. Рантайм-представление лямбды, конечно, сгенерировано не будет, однако её тело в виде приватного синтетического метода загружается фактически вместе с классом, в котором она объявлена. Даже если тело ни разу не используется, оно память отъест. Впрочем, к этому вопросу вернёмся позднее. Посмотрим сперва, что происходит, если лямбда используется. Для этого нам потребуется немного модифицировать программу:
public class Test {
static Runnable r = () -> {};
public static void main(String[] args) { }
}Компилируем (хорошо, пусть с отладочной информацией), запускаем java -Djdk.internal.lambda.dumpProxyClasses=. Test и видим: лямбда создала класс Test$$Lambda$1.class, который весит 308 байт. Это помимо основного класса Test.class, который весит 1004 байта. Заменяем лямбду на аналогичный анонимный класс, имеем 508+399 байт в двух классах сразу, но в рантайме ничего не создаётся. Много вы всё-таки кушаете, молодой человек, на 405 байт больше меня.
Лямбда-кун: ну мы же договорились, что одной лямбдой меряться нечестно. Давай добавим вторую.
Анон-сан: да хоть десять. Дописываем static Runnable r1 = () -> {}; и так далее. Получается 11 классов, с лямбдами 5174 байта, а с анонимными — 5059 байт. Неспеша догоняю я вас, конечно, но, согласитесь, уж 10 лямбд не в каждом классе есть. Где-то после 14-го анонимного класса только вы начинаете кушать меньше.
Лямбда-кун: так-так. А давай-ка эти все лямбды поместим прямо в метод main(). Согласись, нечасто они в статических полях лежат, нэ?
public class Test {
public static void main(String[] args) {
Runnable r = new Runnable() {public void run() {}};
Runnable r1 = new Runnable() {public void run() {}};
Runnable r2 = new Runnable() {public void run() {}};
...
}
}Анон-сан: хм, а в чём разница?
Лямбда-кун: а скомпилируй, и увидишь. У меня-то как раз разницы нет, сгенерированные в рантайме классы весят столько же. А у тебя каждый байт на 40 потолстел. Теперь на десяти лямбдах я кушаю меньше (5290 байт против 4995). Уже даже на шести я тебя опережаю!
Анон-сан: ах, вон оно что. Для отладки в каждый анонимный класс теперь добавлена строчка EnclosingMethod: Test.main, что, конечно, съедает дополнительное место. Эх, зря я на отладочную информацию согласился.
Лямбда-кун: эта запись добавляется даже при полностью отключенной отладочной информации (javac -g:none). Этот атрибут обязан быть по спецификации вне зависимости от отладки. А моё рантайм-представление формально не является анонимным классом, и ему этот атрибут не нужен. Тебе ещё повезло, что имя метода main такое короткое. Если анонимные классы в методе с длинным названием, каждый будет отъедать дополнительно пропорционально его длине!
Анон-сан: по-моему, наша игра уже перетекает в нечестную плоскость. Так что вот, с вашего позволения, ответный удар: замыкание на переменных. Принимаю ваше условие и остаюсь внутри метода. Но захватим-ка переменную:
import java.util.function.IntSupplier;
public class Test {
public static void main(String[] args) {
int i = 0;
IntSupplier s = () -> i;
IntSupplier s1 = () -> i;
IntSupplier s2 = () -> i;
...
}
}Ну и для анонимных классов заменим на new IntSupplier() {public int getAsInt() {return i;}}. Как вы думаете, сколько теперь потребуется лямбд, чтобы победить анонимные классы?
Лямбда-кун: ну тут-то разницы быть не должно. У тебя компилятором генерируется синтетическое поле и конструктор с одним параметром, который это поле инициализирует. У меня примерно то же самое будет создано в рантайме. Какой-то примерно такой класс генерируется и для тебя, и для меня:
class Test$1 implements IntSupplier {
private final int val$i;
Test$1(int i) { val$i = i; }
@Override int getAsInt() { return val$i; }
}Анон-сан: такой, да не такой. Пробуем. Одна лямбда: 1493 байта, один анонимный класс: 1006 байт. Десять лямбд: 6803 байта, десять анонимных классов: 6039 байт. Двадцать лямбд: 12743 байта, двадцать анонимных классов: 11669 байт. Разрыв постоянно увеличивается! Тут хоть тысяча лямбд, а вам меня не догнать.
Лямбда-кун: ээ… Так. Ну-ка, декомпилируем. Это ещё что за ерунда? Какой-то фабричный метод? Глупость какая-то. Помимо конструктора мне ещё зачем-то добавляют метод вида static IntSupplier get$Lambda(int i) { return new Test$1(i);}. Бред какой-то, зачем?
Анон-сан: не бред, а производительность. Когда-то в незапамятные времена Walrus исправил скорость инстанциирования лямбд в интерпретаторе (JDK-8023984). Фабричный метод оказался быстрее, чем конструктор. Заметьте, молодой человек, со мной таких странных проблем не возникает, у меня всё быстро и так.
Лямбда-кун: вот же глупость-то! Нет чтобы допилить свои методхэндлы до ума, они костыли лепят… Интересно, может уже с тех пор допилили и этот метод не нужен стал?..
Анон-сан: как знать, как знать...
Лямбда-кун: однако мой ход! Принимаю твоё условие и захват переменной, но давай-ка не IntSupplier, а Supplier<Integer>:
import java.util.function.Supplier;
public class Test {
public static void main(String[] args) {
int i = 0;
Supplier<Integer> s = new Supplier<Integer>() {public Integer get() {return i;}};
Supplier<Integer> s1 = new Supplier<Integer>() {public Integer get() {return i;}};
...
}
}Ну а лямбда останется как раньше: Supplier<Integer> s = () -> i.
Анон-сан: хм… не вижу, где вы хотите меня околпачить… А, ну да, добавится запись типа Signature: Ljava/lang/Object;Ljava/util/function/Supplier<Ljava/lang/Integer;>; Это чтобы всякий reflection работал правильно и s.getClass().getGenericInterfaces() возвращал именно Supplier<Integer>, а не просто Supplier. А разве вам это не надо?
Лямбда-кун: выходит, что нет. Лямбде позволительно, чтобы для неё это не работало!
Анон-сан: однако хотя эта строчка отъест место, не верится мне, что сильно много против вашего фабричного метода.
Лямбда-кун: а ты не верь, а проверь. Теперь всего три лямбды кушают меньше, чем три анонимных класса (2963 против 3034 байта) и с каждой новой строчкой ты всё больше проигрываешь! Каждый анонимный класс кушает на 270 байт больше соответствующей лямбды. И это с учётом того, что у меня лишний фабричный метод!
Анон-сан: не может быть. Что же там ещё напихал-то компилятор? Ааа, как же я мог забыть. Бридж-метод. Так как в коде у нас Integer get() {}, а в интерфейсе после erasure — Object get(), нужен ещё мостик, который при вызове интерфейса перенаправит к Integer get(). А вам что ли мостик не нужен?
Лямбда-кун: нет, и мостик нам не нужен. Точнее наоборот, он нам нужен всегда, Object get() — это мостик, а реальная реализация в основном классе в синтетическом методе вида lambda$main$1. Но мостик всегда один, в случае с генериками второй мостик не нужен. А вот тебе потребовался и тут стало понятно, что мы всё-таки на самом деле легковеснее!
Анон-сан: вообще, конечно, наши тесты не сильно надёжные. Неизвестно, насколько на самом деле коррелирует размер класс-файлов и расход памяти в рантайме. Но на сегодня беседа и так затянулась, так что отложим этот вопрос на следующий раз.
