Добрый день, друзья. Сегодня я бы хотел поделиться своим личным опытом по настройке Proxmox на soft-Raid 10.
Что имеем:
Что хотим:
Что делаем – общий план действий:
Под катом поэтапное прохождение квеста.
А теперь поэтапно.
Первый момент:
Подключил флешку – если вкратце — не найден установочный диск. Не могу смонтироваться.
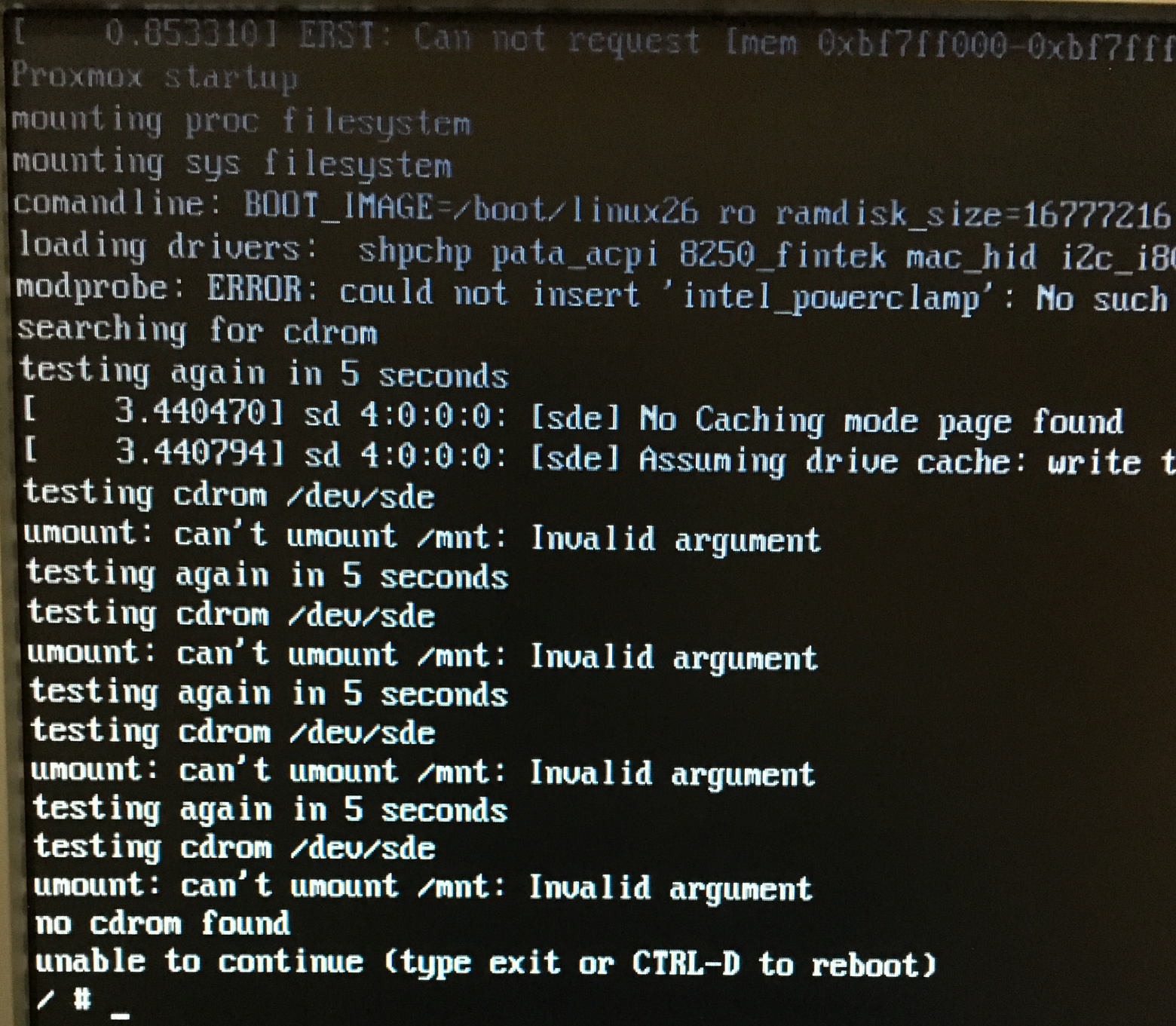
Не стал разбираться что да как, да почему. Записал образ на CD-диск и подключил USB CDROM (благо он был рядом)
Второй момент:
Подключил к серверу CDROM и клавиатуру в передние порты сервера (их у него два) – первое что увидел, на первом приветственном скрине proxmox нельзя ничего нажать без мышки. То есть прееключение Tab-ом по управляющим кнопкам не происходит. Т.к. сервер был в стойке и залазить сзади было проблематично, начал по очереди втыкать клаву и мышку. Мышкой щелкаю «далее», клавой — ввожу данные.
Установка состоит из нескольких шагов:
PROXMOX установлен на первый диск, который он обозвал как /dev/sda. Подключаюсь со своего ноута на адрес, который указал при установке:
Обновляю систему:
Это не дело. Покупать пока лицензию на поддержку не планирую. Меняю официальную подписку на их «бесплатный» репозиторий.
Там вижу:
Меняю на:
И снова обновляюсь и ставлю обновки системы:
Теперь всё обновилось без запинки и система в новейшем состоянии. Ставлю пакеты для работы с рейдом:
Теперь определим точный размер первого диска, он нам пригодится в дальнейшем:
Видим что ровно 1000GB – запомним. Размечаем остальные разделы под наш массив. Первым делом очищаем таблицу разделов на трех пустых дисках и размечаем диски под GPT:
Размечаем:
Второй:
Третий:
Четвертый:
Теперь воссоздаем разделы так же как на оригинальном первом диске:
1.
2.
3.
Вот тут нам пригодится знание размера оригинального первого диска.
4.
Все эти четыре шага проделываем для всех наших дисков: sdb, sdc, sdd. Вот что у меня получилось:
Это оригинальный:
А это второй, третий и четвертый (с разницей в букве диска).
Далее надо уточнить – если вы первый раз играете с этим кейсом и до этого на сервере, а главное на винчестерах, не было даже понятия RAID – можно пропустить этот пункт. Если же что-то не получилось, значит RAID уже возможно был установлен и на винчестерах есть суперблоки которые нужно удалять.
Проверить так:
Проверить нужно все четыре диска.
Теперь настроим mdadm
Создаем конфиг на основе примера:
Опустошаем:
Открываем:
Вводим и сохраняем:
Почту пока оставим как есть, потом к ней еще вернемся.
Теперь поднимаем наши RAID в режиме деградации (пропуская первый рабочий винчестер).
И второй:
Тут надо пояснить по ключам:
UDP. После массы комментариев я вышел на один важный момент.
В процессе создания я сознательно задавал chunk размер в 2048, вместо того что бы пропустить этот флаг и оставить его по умолчанию. Данный флаг существенно снижает производительность. Особенно это даже визуально заметно на виртуалках с Windows.
То есть верная команда на создание должна выглядеть вот так:
и
Сохраняем конфигурацию:
Проверяем содержание:
Теперь нам нужно действующий LVM массив перенести на три пустых диска. Для начала создаем в рейде md1 — LVM-раздел:
И добавляем его в группу pve:
Теперь переносим данные с оригинального LVM на новосозданный:
Процесс долгий. У меня занял порядка 10 часов. Интересно, что запустил я его по привычке будучи подключенным по SSH и на 1,3% понял что сидеть столько времени с ноутом на работе как минимум не удобно. Отменил операцию через CTRL+C, подошел к физическому серверу и попробовал запустить команду переноса там, но умная железяка отписалась, что процесс уже идет и команда второй раз выполнятся не будет, и начала рисовать проценты переноса на реальном экране. Как минимум спасибо :)
Процесс завершился два раза написав 100%. Убираем из LVM первый диск:
Переносим загрузочный /boot в наш новый рейд /md0, но для начала форматируем и монтируем сам рейд.
Создаем директорию и монтируем туда рейд:
Копируем содержимое живого /boot:
Отмонтируем рейд и удаляем временную директорию:
Определим UUID раздела рейда, где хранится /boot – это нужно, что бы правильно записать его в таблицу /etc/fstab:
/dev/md0: UUID=«6b75c86a-0501-447c-8ef5-386224e48538» TYPE=«ext4»
Откроем таблицу и пропишем в ее конец данные загрузки /boot:
Прописываем и сохраняем:
Теперь монтируем /boot:
Разрешим ОС загружаться, даже если состояние BOOT_DEGRADED (то есть рейд деградирован по причине выхода из строя дисков):
Прописываем загрузку ramfs:
Графический режим загрузчика отключаем:
Инсталируем загрузчик на все три диска:
Теперь очень важный момент. Мы берем за основу второй диск /dev/sdb, на котором система, загрузчик и grub и переносим всё это на первый диск /dev/sda, что бы в последствии сделать его так же частью нашего рейда. Для этого рассматриваем первый диск как чистый и размечаем так же, как другие в начале этой статьи
Занулим и пометим как GPT:
Разбиваем его по разделам в точности как другие три:
Тут нам снова понадобиться точное знание размера диска. Напомню, получили мы его командой, которую в данном случае надо применять к диску /dev/sdb:
Так как диски у нас одинаковые, то размер не изменился – 1000Gb. Размечаем основной раздел:
Должно получится так:
Осталось добавить этот диск в общий массив. Второй раздел соответственно в /md0, а третий в /md1:
Ждем синхронизации…
Данная команда в реальном времени показывает процесс синхронизации:
И если первый рейд с /boot синхронизировался сразу, то для синхронизации второго понадобилось терпение (в районе 5 часов).
Осталось установить загрузчик на добавленный диск (тут нужно понимать, что делать это нужно только после того, как диски полностью синхронизировались).
Пару раз нажимаем Enter ничего не меняя и на последнем шаге отмечаем галками все 4 диска
md0/md1 не трогаем!
Осталось перезагрузить систему и проверить, что все в порядке:
Система загрузилась нормально (я даже несколько раз менял в BIOS порядок загрузки винтов — грузится одинаково правильно).
Проверяем массивы:
По четыре подковы в каждом рейде говорят о том, что все четыре диска в работе. Смотрим информацию по массивам (на примере первого, точнее нулевого).
Видим, что массив типа RAID10, все диски на месте, активные и синхронизированы.
Теперь можно было бы поиграться с отключением дисков, изменении диска-загрузчика в BIOS, но перед этим давайте настроим уведомление администратора при сбоях в работе дисков, а значит и самого рейда. Без уведомления рейд будет умирать медленно и мучительно, а никто не будет об этом знать.
В Proxmox по умолчанию уже стоит postfix, удалять его я не стал, хоть и сознательно понимаю что другие MTA было бы проще настроить.
Ставим SASL библиотеку (мне она нужна, что бы работать с нашим внешним почтовым сервером):
Создаем файл с данными от которых будем авторизовываться на нашем удаленном почтовом сервере:
Там прописываем строчку:
Теперь создаем транспортный файл:
Туда пишем:
Создаем generic_map:
Тут пишем (обозначаем от кого будет отправляться почта):
Создаем sender_relay (по сути, маршрут до внешнего сервера):
И пишем туда:
Хешируем файлы:
В файле /etc/postfix/main.cf у меня получилась вот такая рабочая конфигурация:
Перезагружаем postfix:
Теперь нужно вернуться в файл настроек рейда и немного его поправить. Указываем кому получать письма счастья и от кого они будут приходить.
У меня вот так:
Перезапускаем mdadm, что бы перечитать настройки:
Проверяем через консоль тестирование рейда и отправку письма:
У меня пришло два письма с информацией по обоим созданным мною рейдам. Осталось добавить задачу тестирования в крон и убрать ключ –test. Чтобы письма приходили только тогда, когда что-то произошло:
Добавляем задачу (не забудьте после строки нажать на Enter и перевести курсор вниз, что бы появилась пустая строка):
Каждое утро в 5 утра будет производится тестирование и если возникнут проблемы, произойдет отправка почты.
На этом всё. Возможно перемудрил с конфигом postfix – пока пытался добиться нормальной отправки через наш внешний сервер, много чего надобавлял. Буду признателен, если поправите (упростите).
В следующей статье я хочу поделиться опытом переезда виртуальных машин с нашего гипервизора Esxi-6 на этот новый Proxmox. Думаю будет интересно.
UPD.
Стоит отдельно отменить момент с физическим местом на разделе /dev/data – это основной раздел созданный как LVM-Thin
Когда ставился Proxmox, он автоматически разметил /dev/sda с тем учетом, что на /root раздел где хранится система, ISO, дампы и темплеи контейнеров, он выделил 10% емкости от раздела, а именно 100Gb. На оставшемся месте он создал LVM-Thin раздел, который по сути никуда не монтируется (это еще одна тонкость версии >4.2, после перевода дисков в GPT). И как вы понимаете этот раздел стал размером 900Gb. Когда мы подняли RAID10 из 4х дисков по 1Tb – мы получили емкость (с учетом резерва RAID1+0) – 2Tb
Но когда копировали LVM в рейд – копировали его как контейнер, с его размером в 900Gb.
При первом заходе в админку Proxmox внимательный зритель может заметить, что тыкая на раздел local-lvm(pve1) – мы и наблюдаем эти с копейками 800Gb
Так вот что бы расширить LVM-Thin на весь размер в 1,9TB нам потребуется выполнить все одну команду:
После этого систему не нужно даже перезапускать.
Не нужно делать resize2fs – и это скорее даже невозможно, потому как система начнет ругаться на
И правильно начнет – этот раздел у нас не подмонтирован через fstab
В общем пока я пытался понять, как расширить диск и читал форум Proxmox – система тем временем уже во всю показывала новый размер, как в таблице, так и на шкале.

Что имеем:
- Сервер HP ProLiant DL120 G6 (10 GB ОЗУ)
- 4x1000Gb SATA винчестера – без физического RAID контроллера на борту
- Флешка с PROXMOX 4.3 (об этом ниже)
Что хотим:
- Получить инсталляцию PROXMOX 4.3 установленную полностью на S-RAID 10 GPT, что бы при отказе любого диска система продолжала работу.
- Получить уведомление об отказе сбойного диска на почту.
Что делаем – общий план действий:
- Устанавливаем PROXMOX 4.3
- Поднимаем и тестируем RAID10
- Настраиваем уведомления на почту
Под катом поэтапное прохождение квеста.
А теперь поэтапно.
Первый момент:
Подключил флешку – если вкратце — не найден установочный диск. Не могу смонтироваться.
Не стал разбираться что да как, да почему. Записал образ на CD-диск и подключил USB CDROM (благо он был рядом)
Второй момент:
Подключил к серверу CDROM и клавиатуру в передние порты сервера (их у него два) – первое что увидел, на первом приветственном скрине proxmox нельзя ничего нажать без мышки. То есть прееключение Tab-ом по управляющим кнопкам не происходит. Т.к. сервер был в стойке и залазить сзади было проблематично, начал по очереди втыкать клаву и мышку. Мышкой щелкаю «далее», клавой — ввожу данные.
Установка состоит из нескольких шагов:
- Согласится с их требованиями
- Выбрать винчестер, куда система установится.
- Выбрать страну и часовой пояс
- Указать имя сервера, адресацию
- И собственно немного подождать развертки образа на сервер.
PROXMOX установлен на первый диск, который он обозвал как /dev/sda. Подключаюсь со своего ноута на адрес, который указал при установке:
root@pve1:~#ssh root@192.168.1.3Обновляю систему:
root@pve1:~#apt-get update На выходе вижу
Ign http://ftp.debian.org jessie InRelease
Get:1 http://ftp.debian.org jessie Release.gpg [2,373 B]
Get:2 http://security.debian.org jessie/updates InRelease [63.1 kB]
Get:3 http://ftp.debian.org jessie Release [148 kB]
Get:4 https://enterprise.proxmox.com jessie InRelease [401 B]
Ign https://enterprise.proxmox.com jessie InRelease
Get:5 https://enterprise.proxmox.com jessie Release.gpg [401 B]
Ign https://enterprise.proxmox.com jessie Release.gpg
Get:6 http://ftp.debian.org jessie/main amd64 Packages [6,787 kB]
Get:7 https://enterprise.proxmox.com jessie Release [401 B]
Ign https://enterprise.proxmox.com jessie Release
Get:8 http://security.debian.org jessie/updates/main amd64 Packages [313 kB]
Get:9 https://enterprise.proxmox.com jessie/pve-enterprise amd64 Packages [401 B]
Get:10 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en_US [401 B]
Get:11 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en [401 B]
Get:12 https://enterprise.proxmox.com jessie/pve-enterprise amd64 Packages [401 B]
Get:13 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en_US [401 B]
Get:14 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en [401 B]
Get:15 https://enterprise.proxmox.com jessie/pve-enterprise amd64 Packages [401 B]
Get:16 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en_US [401 B]
Get:17 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en [401 B]
Get:18 https://enterprise.proxmox.com jessie/pve-enterprise amd64 Packages [401 B]
Get:19 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en_US [401 B]
Get:20 http://security.debian.org jessie/updates/contrib amd64 Packages [2,506 B]
Get:21 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en [401 B]
Get:22 https://enterprise.proxmox.com jessie/pve-enterprise amd64 Packages [401 B]
Err https://enterprise.proxmox.com jessie/pve-enterprise amd64 Packages
HttpError401
Get:23 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en_US [401 B]
Get:24 http://security.debian.org jessie/updates/contrib Translation-en [1,211 B]
Ign https://enterprise.proxmox.com jessie/pve-enterprise Translation-en_US
Get:25 https://enterprise.proxmox.com jessie/pve-enterprise Translation-en [401 B]
Ign https://enterprise.proxmox.com jessie/pve-enterprise Translation-en
Get:26 http://security.debian.org jessie/updates/main Translation-en [169 kB]
Get:27 http://ftp.debian.org jessie/contrib amd64 Packages [50.2 kB]
Get:28 http://ftp.debian.org jessie/contrib Translation-en [38.5 kB]
Get:29 http://ftp.debian.org jessie/main Translation-en [4,583 kB]
Fetched 12.2 MB in 15s (778 kB/s)
W: Failed to fetch https://enterprise.proxmox.com/debian/dists/jessie/pve-enterprise/binary-amd64/Packages HttpError401
E: Some index files failed to download. They have been ignored, or old ones used instead.Это не дело. Покупать пока лицензию на поддержку не планирую. Меняю официальную подписку на их «бесплатный» репозиторий.
root@pve1:~#nano /etc/apt/sources.list.d/pve-enterprise.listТам вижу:
deb https://enterprise.proxmox.com/debian jessie pve-enterpriseМеняю на:
deb http://download.proxmox.com/debian jessie pve-no-subscriptionИ снова обновляюсь и ставлю обновки системы:
root@pve1:~#apt-get update && apt-get upgradeТеперь всё обновилось без запинки и система в новейшем состоянии. Ставлю пакеты для работы с рейдом:
root@pve1:~#apt-get install -y mdadm initramfs-tools partedТеперь определим точный размер первого диска, он нам пригодится в дальнейшем:
root@pve1:~#parted /dev/sda printModel: ATA MB1000EBNCF (scsi)
Disk /dev/sda: 1000GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 10.5MB 9437kB primary bios_grub
2 10.5MB 1000MB 990MB ext4 primary
3 1000MB 1000GB 999GB primaryВидим что ровно 1000GB – запомним. Размечаем остальные разделы под наш массив. Первым делом очищаем таблицу разделов на трех пустых дисках и размечаем диски под GPT:
root@pve1:~#dd if=/dev/zero of=/dev/sb[bcd] bs=512 count=11+0 records in
1+0 records out
512 bytes (512 B) copied, 7.8537e-05 s, 6.5 MB/sРазмечаем:
Второй:
root@pve1:~#parted /dev/sdb mklabel gptWarning: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No? yes
Information: You may need to update /etc/fstab.Третий:
root@pve1:~#parted /dev/sdc mklabel gptWarning: The existing disk label on /dev/sdc will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No? yes
Information: You may need to update /etc/fstab.Четвертый:
root@pve1:~#parted /dev/sdd mklabel gptWarning: The existing disk label on /dev/sdd will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No? yes
Information: You may need to update /etc/fstab.Теперь воссоздаем разделы так же как на оригинальном первом диске:
1.
root@pve1:~#parted /dev/sdb mkpart primary 1M 10MInformation: You may need to update /etc/fstab.2.
root@pve1:~#parted /dev/sdb set 1 bios_grub onInformation: You may need to update /etc/fstab.3.
root@pve1:~#parted /dev/sdb mkpart primary 10М 1GInformation: You may need to update /etc/fstab.Вот тут нам пригодится знание размера оригинального первого диска.
4.
root@pve1:~#parted /dev/sdb mkpart primary 1G 1000GBInformation: You may need to update /etc/fstab.Все эти четыре шага проделываем для всех наших дисков: sdb, sdc, sdd. Вот что у меня получилось:
Это оригинальный:
root@pve1:~#parted /dev/sda printModel: ATA MB1000EBNCF (scsi)
Disk /dev/sda: 1000GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 17.4kB 1049kB 1031kB bios_grub
2 1049kB 134MB 133MB fat32 boot, esp
3 134MB 1000GB 1000GB lvmА это второй, третий и четвертый (с разницей в букве диска).
root@pve1:~#parted /dev/sdb printModel: ATA MB1000EBNCF (scsi)
Disk /dev/sdd: 1000GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 10.5MB 9437kB primary bios_grub
2 10.5MB 1000MB 990MB primary
3 1000MB 1000GB 999GB primaryДалее надо уточнить – если вы первый раз играете с этим кейсом и до этого на сервере, а главное на винчестерах, не было даже понятия RAID – можно пропустить этот пункт. Если же что-то не получилось, значит RAID уже возможно был установлен и на винчестерах есть суперблоки которые нужно удалять.
Проверить так:
root@pve1:~#mdadm --misc --examine /dev/sda/dev/sda:
MBR Magic : aa55
Partition[0] : 1953525167 sectors at 1 (type ee)Проверить нужно все четыре диска.
Теперь настроим mdadm
Создаем конфиг на основе примера:
root@pve1:~#cp /etc/mdadm/mdadm.conf /etc/mdadm/mdadm.conf.origОпустошаем:
root@pve1:~#echo "" > /etc/mdadm/mdadm.confОткрываем:
root@pve1:~#nano /etc/mdadm/mdadm.confВводим и сохраняем:
CREATE owner=root group=disk mode=0660 auto=yes
MAILADDR user@mail.domainПочту пока оставим как есть, потом к ней еще вернемся.
Теперь поднимаем наши RAID в режиме деградации (пропуская первый рабочий винчестер).
- В /dev/md0 – у меня будет /boot
- В /dev/md1 – VML раздел с системой
root@pve1:~#mdadm --create /dev/md0 --metadata=0.90 --level=10 --chunk=2048 --raid-devices=4 missing /dev/sd[bcd]2mdadm: array /dev/md0 started.И второй:
root@pve1:~#mdadm --create /dev/md1 --metadata=0.90 --level=10 --chunk=2048 --raid-devices=4 missing /dev/sd[bcd]3mdadm: array /dev/md1 started.Тут надо пояснить по ключам:
- --level=10 – говорит что наш RAID будет именно 10
- --chunk=2048 – размер кластера на разделе
- --raid-devices=4 – в рейде будут принимать участие четыре устройства
- missing /dev/sd[bcd]2 – первый рабочий раздел пока помечаем отсутствующим, остальные три добавляем в рейд
UDP. После массы комментариев я вышел на один важный момент.
В процессе создания я сознательно задавал chunk размер в 2048, вместо того что бы пропустить этот флаг и оставить его по умолчанию. Данный флаг существенно снижает производительность. Особенно это даже визуально заметно на виртуалках с Windows.
То есть верная команда на создание должна выглядеть вот так:
root@pve1:~#mdadm --create /dev/md0 --metadata=0.90 --level=10 --raid-devices=4 missing /dev/sd[bcd]2и
root@pve1:~#mdadm --create /dev/md1 --metadata=0.90 --level=10 --raid-devices=4 missing /dev/sd[bcd]3Сохраняем конфигурацию:
root@pve1:~#mdadm --detail --scan >> /etc/mdadm/mdadm.confПроверяем содержание:
root@pve1:~# cat /etc/mdadm/mdadm.confCREATE owner=root group=disk mode=0660 auto=yes
MAILADDR user@mail.domain
ARRAY /dev/md0 metadata=0.90 UUID=4df20dfa:4480524a:f7703943:85f444d5
ARRAY /dev/md1 metadata=0.90 UUID=432e3654:e288eae2:f7703943:85f444d5Теперь нам нужно действующий LVM массив перенести на три пустых диска. Для начала создаем в рейде md1 — LVM-раздел:
root@pve1:~#pvcreate /dev/md1 -ffPhysical volume "/dev/md1" successfully createdИ добавляем его в группу pve:
root@pve1:~#vgextend pve /dev/md1Volume group "pve" successfully extendedТеперь переносим данные с оригинального LVM на новосозданный:
root@pve1:~#pvmove /dev/sda3 /dev/md1/dev/sda3: Moved: 0.0%Процесс долгий. У меня занял порядка 10 часов. Интересно, что запустил я его по привычке будучи подключенным по SSH и на 1,3% понял что сидеть столько времени с ноутом на работе как минимум не удобно. Отменил операцию через CTRL+C, подошел к физическому серверу и попробовал запустить команду переноса там, но умная железяка отписалась, что процесс уже идет и команда второй раз выполнятся не будет, и начала рисовать проценты переноса на реальном экране. Как минимум спасибо :)
Процесс завершился два раза написав 100%. Убираем из LVM первый диск:
root@pve1:~#vgreduce pve /dev/sda3 Removed "/dev/sda3" from volume group "pve"Переносим загрузочный /boot в наш новый рейд /md0, но для начала форматируем и монтируем сам рейд.
root@pve1:~#mkfs.ext4 /dev/md0mke2fs 1.42.12 (29-Aug-2014)
Creating filesystem with 482304 4k blocks and 120720 inodes
Filesystem UUID: 6b75c86a-0501-447c-8ef5-386224e48538
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: done
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: doneСоздаем директорию и монтируем туда рейд:
root@pve1:~#mkdir /mnt/md0root@pve1:~#mount /dev/md0 /mnt/md0Копируем содержимое живого /boot:
root@pve1:~#cp -ax /boot/* /mnt/md0Отмонтируем рейд и удаляем временную директорию:
root@pve1:~#umount /mnt/md0root@pve1:~#rmdir /mnt/md0Определим UUID раздела рейда, где хранится /boot – это нужно, что бы правильно записать его в таблицу /etc/fstab:
root@pve1:~#blkid |grep md0/dev/md0: UUID=«6b75c86a-0501-447c-8ef5-386224e48538» TYPE=«ext4»
Откроем таблицу и пропишем в ее конец данные загрузки /boot:
root@pve1:~#nano /etc/fstabПрописываем и сохраняем:
UUID="6b75c86a-0501-447c-8ef5-386224e48538" /boot ext4 defaults 0 1Теперь монтируем /boot:
root@pve1:~#mount /bootРазрешим ОС загружаться, даже если состояние BOOT_DEGRADED (то есть рейд деградирован по причине выхода из строя дисков):
root@pve1:~#echo "BOOT_DEGRADED=true" > /etc/initramfs-tools/conf.d/mdadmПрописываем загрузку ramfs:
root@pve1:~#mkinitramfs -o /boot/initrd.img-`uname -r`Графический режим загрузчика отключаем:
root@pve1:~#echo "GRUB_TERMINAL=console" >> /etc/default/grubИнсталируем загрузчик на все три диска:
root@pve1:~#grub-install /dev/sdbInstalling for i386-pc platform.
Installation finished. No error reported.root@pve1:~#grub-install /dev/sdc>Installing for i386-pc platform.
Installation finished. No error reported.root@pve1:~#grub-install /dev/sddInstalling for i386-pc platform.
Installation finished. No error reported.Теперь очень важный момент. Мы берем за основу второй диск /dev/sdb, на котором система, загрузчик и grub и переносим всё это на первый диск /dev/sda, что бы в последствии сделать его так же частью нашего рейда. Для этого рассматриваем первый диск как чистый и размечаем так же, как другие в начале этой статьи
Занулим и пометим как GPT:
root@pve1:~#dd if=/dev/zero of=/dev/sda bs=512 count=11+0 records in
1+0 records out
512 bytes (512 B) copied, 0.0157829 s, 32.4 kB/sroot@pve1:~#parted /dev/sda mklabel gptInformation: You may need to update /etc/fstab.Разбиваем его по разделам в точности как другие три:
root@pve1:~#parted /dev/sda mkpart primary 1M 10MInformation: You may need to update /etc/fstab.root@pve1:~#parted /dev/sda set 1 bios_grub onInformation: You may need to update /etc/fstab.root@pve1:~#parted /dev/sda mkpart primary 10М 1GInformation: You may need to update /etc/fstab.Тут нам снова понадобиться точное знание размера диска. Напомню, получили мы его командой, которую в данном случае надо применять к диску /dev/sdb:
root@pve1:~#parted /dev/sdb printТак как диски у нас одинаковые, то размер не изменился – 1000Gb. Размечаем основной раздел:
root@pve1:~#parted /dev/sda mkpart primary 1G 1000GbInformation: You may need to update /etc/fstab.Должно получится так:
root@pve1:~#parted /dev/sda printModel: ATA MB1000EBNCF (scsi)
Disk /dev/sda: 1000GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 10.5MB 9437kB fat32 primary bios_grub
2 10.5MB 1000MB 990MB primary
3 1000MB 1000GB 999GB primaryОсталось добавить этот диск в общий массив. Второй раздел соответственно в /md0, а третий в /md1:
root@pve1:~#mdadm --add /dev/md0 /dev/sda2mdadm: added /dev/sda2root@pve1:~#mdadm --add /dev/md1 /dev/sda3mdadm: added /dev/sda3Ждем синхронизации…
root@pve1:~#watch cat /proc/mdstatДанная команда в реальном времени показывает процесс синхронизации:
Every 2.0s: cat /proc/mdstat Fri Nov 11 10:09:18 2016
Personalities : [raid10]
md1 : active raid10 sda3[4] sdd3[3] sdc3[2] sdb3[1]
1951567872 blocks 2048K chunks 2 near-copies [4/3] [_UUU]
[>....................] recovery = 0.5% (5080064/975783936) finish=284.8min speed=56796K/sec
bitmap: 15/15 pages [60KB], 65536KB chunk
md0 : active raid10 sda2[0] sdd2[3] sdc2[2] sdb2[1]
1929216 blocks 2048K chunks 2 near-copies [4/4] [UUUU]И если первый рейд с /boot синхронизировался сразу, то для синхронизации второго понадобилось терпение (в районе 5 часов).
Осталось установить загрузчик на добавленный диск (тут нужно понимать, что делать это нужно только после того, как диски полностью синхронизировались).
root@pve1:~#dpkg-reconfigure grub-pcПару раз нажимаем Enter ничего не меняя и на последнем шаге отмечаем галками все 4 диска
md0/md1 не трогаем!
Осталось перезагрузить систему и проверить, что все в порядке:
root@pve1:~#shutdown –r nowСистема загрузилась нормально (я даже несколько раз менял в BIOS порядок загрузки винтов — грузится одинаково правильно).
Проверяем массивы:
<source lang="vim">root@pve1:~#cat /proc/mdstatPersonalities : [raid10]
md1 : active raid10 sda3[0] sdd3[3] sdc3[2] sdb3[1]
1951567872 blocks 2048K chunks 2 near-copies [4/4] [UUUU]
bitmap: 2/15 pages [8KB], 65536KB chunk
md0 : active raid10 sda2[0] sdd2[3] sdc2[2] sdb2[1]
1929216 blocks 2048K chunks 2 near-copies [4/4] [UUUU]По четыре подковы в каждом рейде говорят о том, что все четыре диска в работе. Смотрим информацию по массивам (на примере первого, точнее нулевого).
root@pve1:~#mdadm --detail /dev/md0/dev/md0:
Version : 0.90
Creation Time : Thu Nov 10 15:12:21 2016
Raid Level : raid10
Array Size : 1929216 (1884.32 MiB 1975.52 MB)
Used Dev Size : 964608 (942.16 MiB 987.76 MB)
Raid Devices : 4
Total Devices : 4
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Fri Nov 11 10:07:47 2016
State : active
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 2048K
UUID : 4df20dfa:4480524a:f7703943:85f444d5 (local to host pve1)
Events : 0.27
Number Major Minor RaidDevice State
0 8 2 0 active sync set-A /dev/sda2
1 8 18 1 active sync set-B /dev/sdb2
2 8 34 2 active sync set-A /dev/sdc2
3 8 50 3 active sync set-B /dev/sdd2Видим, что массив типа RAID10, все диски на месте, активные и синхронизированы.
Теперь можно было бы поиграться с отключением дисков, изменении диска-загрузчика в BIOS, но перед этим давайте настроим уведомление администратора при сбоях в работе дисков, а значит и самого рейда. Без уведомления рейд будет умирать медленно и мучительно, а никто не будет об этом знать.
В Proxmox по умолчанию уже стоит postfix, удалять его я не стал, хоть и сознательно понимаю что другие MTA было бы проще настроить.
Ставим SASL библиотеку (мне она нужна, что бы работать с нашим внешним почтовым сервером):
root@pve1:/etc#apt-get install libsasl2-modulesСоздаем файл с данными от которых будем авторизовываться на нашем удаленном почтовом сервере:
root@pve1:~#touch /etc/postfix/sasl_passwdТам прописываем строчку:
[mail.domain.ru] pve1@domain.ru:passwordТеперь создаем транспортный файл:
root@pve1:~#touch /etc/postfix/transportТуда пишем:
domain.ru smtp:[mail.domain.ru]Создаем generic_map:
root@pve1:~#touch /etc/postfix/genericТут пишем (обозначаем от кого будет отправляться почта):
root pve1@domain.ruСоздаем sender_relay (по сути, маршрут до внешнего сервера):
root@pve1:~#touch /etc/postfix/sender_relayИ пишем туда:
pve1@domain.ru smtp.domain.ruХешируем файлы:
root@pve1:~#postmap transportroot@pve1:~#postmap sasl_passwdroot@pve1:~#postmap geniricroot@pve1:~#postmap sender_relayВ файле /etc/postfix/main.cf у меня получилась вот такая рабочая конфигурация:
main.cf
# See /usr/share/postfix/main.cf.dist for a commented, more complete version
myhostname=domain.ru
smtpd_banner = $myhostname ESMTP $mail_name (Debian/GNU)
biff = no
# appending .domain is the MUA's job.
append_dot_mydomain = no
# Uncomment the next line to generate «delayed mail» warnings
#delay_warning_time = 4h
alias_maps = hash:/etc/aliases
alias_database = hash:/etc/aliases
mydestination = $myhostname, localhost.$mydomain, localhost
mynetworks = 127.0.0.0/8,192.168.1.0/24
inet_interfaces = loopback-only
recipient_delimiter = +
smtp_tls_loglevel = 1
smtp_tls_session_cache_database = btree:/var/lib/postfix/smtp_tls_session_cache
smtp_use_tls = no
tls_random_source = dev:/dev/urandom
## SASL Settings
smtpd_sasl_auth_enable = no
smtp_sasl_auth_enable = yes
smtpd_use_pw_server=yes
enable_server_options=yes
smtpd_pw_server_security_options=plain, login
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
smtp_sender_dependent_authentification = yes
sender_dependent_relayhost_maps = hash:/etc/postfix/sender_relay
smtpd_sasl_local_domain = $myhostname
smtp_sasl_security_options = noanonymous
smtp_sasl_tls_security_options = noanonymous
smtpd_sasl_application_name = smtpd
smtp_always_send_ehlo = yes
relayhost =
transport_maps = hash:/etc/postfix/transport
smtp_generic_maps = hash:/etc/postfix/generic
disable_dns_lookups = yes
myhostname=domain.ru
smtpd_banner = $myhostname ESMTP $mail_name (Debian/GNU)
biff = no
# appending .domain is the MUA's job.
append_dot_mydomain = no
# Uncomment the next line to generate «delayed mail» warnings
#delay_warning_time = 4h
alias_maps = hash:/etc/aliases
alias_database = hash:/etc/aliases
mydestination = $myhostname, localhost.$mydomain, localhost
mynetworks = 127.0.0.0/8,192.168.1.0/24
inet_interfaces = loopback-only
recipient_delimiter = +
smtp_tls_loglevel = 1
smtp_tls_session_cache_database = btree:/var/lib/postfix/smtp_tls_session_cache
smtp_use_tls = no
tls_random_source = dev:/dev/urandom
## SASL Settings
smtpd_sasl_auth_enable = no
smtp_sasl_auth_enable = yes
smtpd_use_pw_server=yes
enable_server_options=yes
smtpd_pw_server_security_options=plain, login
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
smtp_sender_dependent_authentification = yes
sender_dependent_relayhost_maps = hash:/etc/postfix/sender_relay
smtpd_sasl_local_domain = $myhostname
smtp_sasl_security_options = noanonymous
smtp_sasl_tls_security_options = noanonymous
smtpd_sasl_application_name = smtpd
smtp_always_send_ehlo = yes
relayhost =
transport_maps = hash:/etc/postfix/transport
smtp_generic_maps = hash:/etc/postfix/generic
disable_dns_lookups = yes
Перезагружаем postfix:
root@pve1:~#/etc/init.d/postfix restartТеперь нужно вернуться в файл настроек рейда и немного его поправить. Указываем кому получать письма счастья и от кого они будут приходить.
root@pve1:~#nano /etc/dmadm/mdadm.confУ меня вот так:
CREATE owner=root group=disk mode=0660 auto=yes
MAILADDR info@domain.ru
MAILFROM pve1@dpmain.ru
ARRAY /dev/md0 metadata=0.90 UUID=4df20dfa:4480524a:f7703943:85f444d5
ARRAY /dev/md1 metadata=0.90 UUID=432e3654:e288eae2:f7703943:85f444d5Перезапускаем mdadm, что бы перечитать настройки:
root@pve1:~#/etc/init.d/mdadm restartПроверяем через консоль тестирование рейда и отправку письма:
root@pve1:~#mdadm --monitor --scan -1 --test --oneshotУ меня пришло два письма с информацией по обоим созданным мною рейдам. Осталось добавить задачу тестирования в крон и убрать ключ –test. Чтобы письма приходили только тогда, когда что-то произошло:
root@pve1:~#crontab -eДобавляем задачу (не забудьте после строки нажать на Enter и перевести курсор вниз, что бы появилась пустая строка):
0 5 * * * mdadm --monitor --scan -1 –oneshotКаждое утро в 5 утра будет производится тестирование и если возникнут проблемы, произойдет отправка почты.
На этом всё. Возможно перемудрил с конфигом postfix – пока пытался добиться нормальной отправки через наш внешний сервер, много чего надобавлял. Буду признателен, если поправите (упростите).
В следующей статье я хочу поделиться опытом переезда виртуальных машин с нашего гипервизора Esxi-6 на этот новый Proxmox. Думаю будет интересно.
UPD.
Стоит отдельно отменить момент с физическим местом на разделе /dev/data – это основной раздел созданный как LVM-Thin
Когда ставился Proxmox, он автоматически разметил /dev/sda с тем учетом, что на /root раздел где хранится система, ISO, дампы и темплеи контейнеров, он выделил 10% емкости от раздела, а именно 100Gb. На оставшемся месте он создал LVM-Thin раздел, который по сути никуда не монтируется (это еще одна тонкость версии >4.2, после перевода дисков в GPT). И как вы понимаете этот раздел стал размером 900Gb. Когда мы подняли RAID10 из 4х дисков по 1Tb – мы получили емкость (с учетом резерва RAID1+0) – 2Tb
Но когда копировали LVM в рейд – копировали его как контейнер, с его размером в 900Gb.
При первом заходе в админку Proxmox внимательный зритель может заметить, что тыкая на раздел local-lvm(pve1) – мы и наблюдаем эти с копейками 800Gb
Так вот что бы расширить LVM-Thin на весь размер в 1,9TB нам потребуется выполнить все одну команду:
lvextend /dev/pve/data -l +100%FREEПосле этого систему не нужно даже перезапускать.
Не нужно делать resize2fs – и это скорее даже невозможно, потому как система начнет ругаться на
root@pve1:~# resize2fs /dev/mapper/pve-data
resize2fs 1.42.12 (29-Aug-2014)
resize2fs: MMP: invalid magic number while trying to open /dev/mapper/pve-data
Couldn't find valid filesystem superblock. И правильно начнет – этот раздел у нас не подмонтирован через fstab
В общем пока я пытался понять, как расширить диск и читал форум Proxmox – система тем временем уже во всю показывала новый размер, как в таблице, так и на шкале.
