Все, кто работал с seo-продвижением ни раз слышал утверждения: “Сайту нужно семантическое ядро (СЯ)”, “Нет семантического ядра – нет и продвижения”, “СЯ – это основа сайта” и т.д. и т.п. Вскоре начали говорить, что СЯ – это, конечно, хорошо, но нужна ещё и “карта релевантности” (она же карта перелинковки, карта вхождения ключевых запросов). Но с определением этого понятия творится какая-то неразбериха. Даже подробные гайды по составлению карты релевантности от ведущих агентств ясности не добавляют. Сложно понять как с тем, что они показывают в примерах можно работать системно.
В статье мы поделимся нашим видением этого инструмента и опытом разработки.
Что о карте релевантности говорят в интернете?
Об этом инструменте написано мало, одно из наиболее полных определений можно найти на сайте агентства “Текстерра”:
“Карта релевантности – это файл в формате .excel, который создают наши специалисты отдела продвижения перед началом работ по продвижению. Карта релевантности – это, по сути, семантическое ядро, натянутое на структуру сайта. Помимо этого, карта релевантности содержит информацию о:
Перелинковке, т.е. внутренних ссылках со страницы-донора на страницу-акцептор (отражаются ссылки, которые уже существуют и которые только будут проставлены в ходе работ в будущем)
Релевантности таких элементов, как H1, Title, Description.” (Текстерра)
Вот как это выглядит у них:
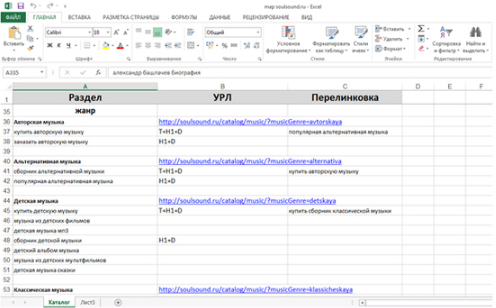
Зачем нужна карта релевантности?
В том же источнике читаем:
“К этому документу постоянно обращаются при работе наши seo-оптимизаторы и копирайтеры. Благодаря ему не возникает путаницы и случайных ошибок, не появляются разделы, релевантные тем или иным ключам, которые должны присутствовать совсем на других страницах. Например, релевантной страницы еще нет, но она уже отображена в плане, и мы знаем, что на другой странице нельзя «накачивать» текстовую релевантность по ключам, которые «забронированы» другой, пока еще не существующей, страницей”. (Текстерра)
Все, что сказано верно, но смотрим на пример карты в скриншоте и совершенно не понимаем как с этим инструментом можно работать системно:
В общем, вопросов больше, чем ответов. Вероятно статья устарела, либо в в качестве примера использован упрощенный вариант.
Наш вариант карты релевантности
Вначале определимся с тем, что нам нужно в этом документе:
1. Совместное редактирование. Должен иметь возможность правки несколькими сотрудниками.
2. Фильтрация. В карте представлено много разных данных, а значит без фильтрации и сортировки никуда.
3. Наглядность общей структуры сайта. Это значит, что в карте понятно какой запрос к какому разделу и подразделу сайта относится.
4. Полная информация о семантике. Частотности, страницы на сайте, метатеги, расположение согласно разделам сайта – удобно всё это видеть в одном месте.
Первое требование решается легко с помощью Google SpreadSheet. Волшебный инструмент для совместного редактирования, делает почти всё тоже самое что и Эксель, но ещё и в режиме онлайн.
Соответствовать остальным пунктам сложнее. Для этого придётся обратиться к теории реляционных баз данных :)
Работа с фильтрацией
Чтобы удобно работать с фильтрацией (повторимся, без этого нет смысла использовать таблицы! Пишите в блокноте – разницы не почувствуете) необходимо иметь таблицу в нормализованном виде, в данном случае это “1 нормальная форма”.
“Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто”.
Проще говоря, таблица не должна иметь составных полей и пустых важных полей. В любой строке таблицы вам должно быть понятно к чему относятся отраженные в ней данные.
Это делается легко, и выглядит примерно так:
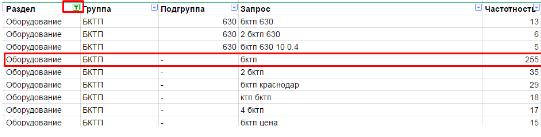
В этом случае мы можем использовать стандартную фильтрацию и сортировку. Каждая строка в отдельности содержит все необходимые данные для ее идентификации. В выделенной строке понятно, что запрос “бктп” относится к группе “БКТП”, которая, в свою очередь, относится к разделу “Оборудование”. Запрос имеет частотность 255.
Наглядность общей структуры сайта
Для этого построили сводную таблицу по исходным данным. Ниже представлен маленький ее кусочек.

В агентстве мы постоянно работаем с картой, поэтому быстро поняли, что такой вариант не вариант. И вот почему:
В одном документе нужно хранить много разных данных, но все они относятся к двум разным сущностям. Например, частотность относится к каждому запросу в отдельности, а вот url страницы относится к группе запросов. И чтобы в таблице все было правильно приходится для всех запросов, относящихся к одной странице, указывать один и тот же url. Копирайтеру и менеджеру проекта важна карта в разрезе страниц сайта, а для seo оптимизатора важнее ключевые слова. Короче нестыковочка.
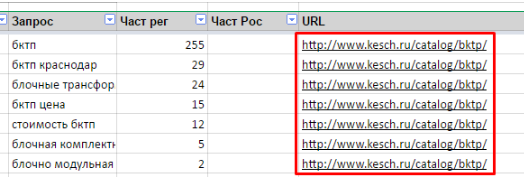
Получается вот такой ад.
Разрываясь между представлением данных “одна строчка — один запрос” либо “одна строчка — одна страница”, мы нашли ну просто изумительное, на наш взгляд, решение. Объединив два уровня абстракции в одной таблице с помощью скриптов, мы сделали нашу карту релевантности двуликой, так сказать. Появилось два варианта представления карты, опишу каждый из них подробно, чтобы было понятно как это сделано и для чего.
Первое представление “Одна строка – один запрос”. Если мы работаем на уровне запросов, то наша карта выглядит так:

Это представление “Одна строка – один запрос”. Вся информация указана для каждого конкретного запроса. Мы можем сортировать фильтровать их, делать все что угодно.
Здесь есть ряд фишек, которые делают её безумно удобной:
В общем фильтруем всё вдоль и поперёк. Добавляем новые характеристики запросов, такие как частотность, title, description и вообще всё, что нужно знать в разрезе запроса.
Представление “Одна строка — одна страница”
Повторюсь, что предыдущее представление прекрасно подходит для работы с запросами, но как только нам необходимо добавить данные, относящиеся к странице, то возникает неудобство. И тут на помощь приходит представление “Одна строка – одна страница”. Пишем небольшой скрипт, выбираем в меню Гугл таблиц пункт “Сгруппировать”.

Скрипт перебирает строки в нашей таблице и группирует все данные для каждого url. Получается следующий вид:
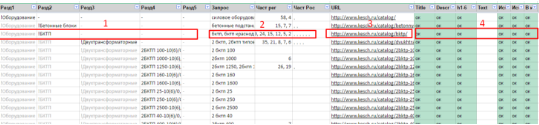
В этом виде данные указаны для каждого URL, то есть для каждой страницы.
Здесь:
Данные разделов (цифра 1) — группируются
Данные запросов (цифра 2 ) — объединяются в одно поле через запятую
Адрес страницы URL (цифра 3) — группируются
Данные по страница (цифра 4) — группируются
Вот, что нужно от представления карты в разрезе страниц:
Таким образом, в одном файле все участники процесса видят сделанное и запланированное.
Если же нам понадобилось вернуться к представлению “Один строка – один запрос”, но мы жмем “Разгруппировать” и возвращаемся к предыдущему виду:

Что мы получили в итоге?
У нас получилась многоуровневая карта релевантности, которая:
А как вы работаете с семантикой? У каждого свои методики — давайте делиться.
В статье мы поделимся нашим видением этого инструмента и опытом разработки.
Что о карте релевантности говорят в интернете?
Об этом инструменте написано мало, одно из наиболее полных определений можно найти на сайте агентства “Текстерра”:
“Карта релевантности – это файл в формате .excel, который создают наши специалисты отдела продвижения перед началом работ по продвижению. Карта релевантности – это, по сути, семантическое ядро, натянутое на структуру сайта. Помимо этого, карта релевантности содержит информацию о:
Перелинковке, т.е. внутренних ссылках со страницы-донора на страницу-акцептор (отражаются ссылки, которые уже существуют и которые только будут проставлены в ходе работ в будущем)
Релевантности таких элементов, как H1, Title, Description.” (Текстерра)
Вот как это выглядит у них:
Зачем нужна карта релевантности?
В том же источнике читаем:
“К этому документу постоянно обращаются при работе наши seo-оптимизаторы и копирайтеры. Благодаря ему не возникает путаницы и случайных ошибок, не появляются разделы, релевантные тем или иным ключам, которые должны присутствовать совсем на других страницах. Например, релевантной страницы еще нет, но она уже отображена в плане, и мы знаем, что на другой странице нельзя «накачивать» текстовую релевантность по ключам, которые «забронированы» другой, пока еще не существующей, страницей”. (Текстерра)
Все, что сказано верно, но смотрим на пример карты в скриншоте и совершенно не понимаем как с этим инструментом можно работать системно:
- Как использовать нескольким сотрудникам? Если это Excel, то для синхронизации изменений придется вводить отдельную должность “Синхронизатора”.
- Как производить сортировку и фильтрацию? Сама структура документа не предполагает фильтраций, а ведь это очень важно, когда работаешь с массивом данных.
- Как понять какая семантика к какому разделу сайта принадлежит?
- Как выделить приоритетные страницы для работы?
В общем, вопросов больше, чем ответов. Вероятно статья устарела, либо в в качестве примера использован упрощенный вариант.
Наш вариант карты релевантности
Вначале определимся с тем, что нам нужно в этом документе:
1. Совместное редактирование. Должен иметь возможность правки несколькими сотрудниками.
2. Фильтрация. В карте представлено много разных данных, а значит без фильтрации и сортировки никуда.
3. Наглядность общей структуры сайта. Это значит, что в карте понятно какой запрос к какому разделу и подразделу сайта относится.
4. Полная информация о семантике. Частотности, страницы на сайте, метатеги, расположение согласно разделам сайта – удобно всё это видеть в одном месте.
Первое требование решается легко с помощью Google SpreadSheet. Волшебный инструмент для совместного редактирования, делает почти всё тоже самое что и Эксель, но ещё и в режиме онлайн.
Соответствовать остальным пунктам сложнее. Для этого придётся обратиться к теории реляционных баз данных :)
Работа с фильтрацией
Чтобы удобно работать с фильтрацией (повторимся, без этого нет смысла использовать таблицы! Пишите в блокноте – разницы не почувствуете) необходимо иметь таблицу в нормализованном виде, в данном случае это “1 нормальная форма”.
“Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто”.
Проще говоря, таблица не должна иметь составных полей и пустых важных полей. В любой строке таблицы вам должно быть понятно к чему относятся отраженные в ней данные.
Это делается легко, и выглядит примерно так:
В этом случае мы можем использовать стандартную фильтрацию и сортировку. Каждая строка в отдельности содержит все необходимые данные для ее идентификации. В выделенной строке понятно, что запрос “бктп” относится к группе “БКТП”, которая, в свою очередь, относится к разделу “Оборудование”. Запрос имеет частотность 255.
Наглядность общей структуры сайта
Для этого построили сводную таблицу по исходным данным. Ниже представлен маленький ее кусочек.
В агентстве мы постоянно работаем с картой, поэтому быстро поняли, что такой вариант не вариант. И вот почему:
В одном документе нужно хранить много разных данных, но все они относятся к двум разным сущностям. Например, частотность относится к каждому запросу в отдельности, а вот url страницы относится к группе запросов. И чтобы в таблице все было правильно приходится для всех запросов, относящихся к одной странице, указывать один и тот же url. Копирайтеру и менеджеру проекта важна карта в разрезе страниц сайта, а для seo оптимизатора важнее ключевые слова. Короче нестыковочка.
Получается вот такой ад.
Разрываясь между представлением данных “одна строчка — один запрос” либо “одна строчка — одна страница”, мы нашли ну просто изумительное, на наш взгляд, решение. Объединив два уровня абстракции в одной таблице с помощью скриптов, мы сделали нашу карту релевантности двуликой, так сказать. Появилось два варианта представления карты, опишу каждый из них подробно, чтобы было понятно как это сделано и для чего.
Первое представление “Одна строка – один запрос”. Если мы работаем на уровне запросов, то наша карта выглядит так:
Это представление “Одна строка – один запрос”. Вся информация указана для каждого конкретного запроса. Мы можем сортировать фильтровать их, делать все что угодно.
Здесь есть ряд фишек, которые делают её безумно удобной:
- Отображено до 5 уровней разделов/подразделов (если требуется, то можно и больше);
- на скриншоте ниже видно, что в первой строке название раздела визуально выделено, а последующие аналогичные названия затемнены. Такие выделения делаются автоматически с помощью банального условного форматирования и значительно упрощают восприятие структуры сайта;

- Можно отфильтровать так, чтобы отображались запросы только одного раздела, или любого подраздела;
- Есть возможность отсортировать запросы по частотности;
- Можем легко скопировать список интересующих запросов и нам не придётся тащить за собой кучу разрозненных, не связанных между собой строк. Удобно, к примеру, собрать дополнительную статистику в других сервисах;
- Видно к какой странице какой запрос относится, можно отфильтровать запросы, относящиеся только к одной странице или к группе страниц.
В общем фильтруем всё вдоль и поперёк. Добавляем новые характеристики запросов, такие как частотность, title, description и вообще всё, что нужно знать в разрезе запроса.
Представление “Одна строка — одна страница”
Повторюсь, что предыдущее представление прекрасно подходит для работы с запросами, но как только нам необходимо добавить данные, относящиеся к странице, то возникает неудобство. И тут на помощь приходит представление “Одна строка – одна страница”. Пишем небольшой скрипт, выбираем в меню Гугл таблиц пункт “Сгруппировать”.
Скрипт перебирает строки в нашей таблице и группирует все данные для каждого url. Получается следующий вид:
В этом виде данные указаны для каждого URL, то есть для каждой страницы.
Здесь:
Данные разделов (цифра 1) — группируются
Данные запросов (цифра 2 ) — объединяются в одно поле через запятую
Адрес страницы URL (цифра 3) — группируются
Данные по страница (цифра 4) — группируются
Вот, что нужно от представления карты в разрезе страниц:
- Можно скопировать страницы списком (например, для проверки страниц в сервисе проверки уникальности);
- Отметить факт выполнения какой-либо работы, относящейся к странице. Сюда можно добавить всё, что угодно: “Проверку на уникальность”, “Проверку оптимизации текста”, “Проверку индексации страниц” и т.д. Проверяете тексты по Закону Ципфа или пропускаете через сервис Главред? Добавьте новое поле и фиксируйте факт выполнения;
- Копирайтер видит требуемые страницы, по которым еще не написан контент.

Таким образом, в одном файле все участники процесса видят сделанное и запланированное.
Если же нам понадобилось вернуться к представлению “Один строка – один запрос”, но мы жмем “Разгруппировать” и возвращаемся к предыдущему виду:
Что мы получили в итоге?
У нас получилась многоуровневая карта релевантности, которая:
- Хранится “в облаке” и не требует дополнительной синхронизации;
- Позволяет удобно работать совместно;
- Позволяет наглядно видеть всю структуру сайта;
- Позволяет хранить информацию в разрезе запросов и одновременно с этим работать в разрезе страниц;
- С помощью скриптов можно менять представление данных в зависимости от потребностей каждого участника проекта;
- С помощью скриптов указать данные, относящиеся к странице только один раз, а для каждого запроса этой страницы данные продублируются автоматически;
- Упрощает диалог с копирайтером. По сути карта является готовым ТЗ к каждой странице сайта;
- даёт всем участникам процесса видение общей картины проекта.
А как вы работаете с семантикой? У каждого свои методики — давайте делиться.
