Уважаемые читатели. Это третья статья из цикла по базам данных.
Оглавление:
Данный способ – способ реализации хранения файлов, приложенных пользователем на сайте, через веб интерфейс. Это не будет “файловой системой” в том понимании как это организовано в операционной системе.
Пример, описанный в этой статье, будет решать задачу стоявшую когда-то у меня: “Выделить раздел внутри аккаунта компании на веб сайте, где сотрудники компании смогут хранить свои файлы, создавать папки (назовем его “Диск”). Диск должен быть изолированным от аккаунтов других компаний и должен интегрироваться в процессы работы аккаунта (организация хранения файлов, прикладываемых к задачам, проектам, карточкам контрагентов, отчетов и т.п.) ”.
Сразу замечу, что данный способ, с точки зрения быстродействия, менее эффективен простого сохранения файлов на веб-сервере. Но он имеет определенные преимущества, которые в моем случае перевесили недостатки потери скорости загрузки.
Недостатки: Увеличенное время загрузки файла
Преимущества
Основным аргументом реализации данной системы хранения файлов послужила возможность распределённого хранения. В принципе можно использовать решения типа cifs и samba, примонтировать сетевые диски от других машин и там хранить файлы клиентов. Но в то время мне пришло вот такое вот, не совсем стандартное решение, и я им полностью доволен.
В данной статье мы будем рассматривать процесс реализации от простого к сложному:
Итак начнем.
В качестве базы данных, используется firebird 3
1. Общая организация структуры хранения.
Как и в предыдущей статье (по хранению логов), не стоит в основной рабочей базе хранить файлы, это будет много мусора, проблемы с бекапами и т.д. Для этого лучше выделить отдельную базу данных. Назовем ее “Файловая БД”. В основной базе данных должна храниться структура каталогов и ссылки на файлы, а сами бинарные данные из файлов, будут храниться в файловой БД.
В этом случае вы получите удобство бекапов, и быструю базу данных. Например, я в своей системе даю пользователям возможность самостоятельно планировать график своих бекапов, в том числе и бекапов файловой базы данных. Более того, даже есть возможность автоматического закидывания архива бекапа пользователю на его FTP (например, если он бекапы желает хранить на своем оборудовании и не платить за аренду места в облаке). Такая реализация возможна как раз благодаря хранению файлов в отдельной базе и организации распределенной системы хранения.
Так же благодаря такой организации, веб-сервер выполняет только функции веб-сервера, а не файлового хранилища. Можно более грамотно организовать распределение ресурсов в сети. При огромном количестве клиентов (огромном количестве баз данных и файловых структур) нераспределенная организация хранения данных будет просто неприемлема. Структура должна быть неограниченно масштабируемой, а так же простой.
Схему можно представить следующим образом:
При этом каждый из элементов может быть (и лучше сделать так) на своем отдельном сервере. Структура хранения данных может быть организована следующим образом. В основной базе данных создается структура с данными о приложенном файле
Структура файловой базе данных может быть такой (минимум данных о файле и сам файл в blob поле).
Тут есть некоторая избыточность данных в этих двух таблицах относительно друг друга, но в последствии она пригодиться, например, при операции отложенной архивации, при отладке, при последующих анализах данных и т.п. Не городить же единый запрос в несколько БД.
Начнем рассмотрение с простой записи файла в blob поле.
2.1. Сохранение файлов в blob поля.
Веб формы и процесс закачки файла в каталог на веб-сервере мы рассматривать тут не будем. Предполагается что читатель с этим знаком.
Итак, пользователь нажал в веб форме кнопку, файл загрузился и сохранился в каталоге веб-сервера (пусть будет например tmp).
Данные файла в этот момент у нас есть в глобальном массиве FILES.
(примеры буду приводить на PHP)
PS: Для простоты изложения, я сознательно опускаю преобразование опасных спецсимволов к мнемоникам, принудительное приведение числовых данных к числу и т.п. Предполагается, что у читателя есть свои процедуры для этого и он осознает опасность sql-инъекций. Если этого нет, то очень рекомендую познакомится с данной темой и делать соответствующие преобразования.
В $prom_query[0] – будет значение ID записанного файла. После успешной записи данных файла в файловую БД надо записать данные о файле в нашу основную БД.
Все, у нас файл записан в файловую БД. На веб-сервере его нет. В основной БД есть информация об этом файле, его статусе, типе, размере и идентификаторе в файловой БД.
2.2. Чтение файла из БД.
Когда пользователь кликает на ссылку с именем файла, нам надо осуществить обратный процесс. Извлечь файл из БД и преподнести браузеру пользователя эту последовательность данных, сказав какого типа этот файл.
В ссылке в качестве GET параметров должен быть указан идентификатор файла (либо хэш идентификатора с солью – зависит от требований к безопасности системы, мы будем рассматривать пока простую ситуацию). Например, ссылка может выглядеть следующим образом Файл.
На этапе простого чтения из БД (без архивирования данных), нам достаточно обращения в файловую БД.
При указании типа данных в header, выявлена индивидуальная проблема с браузером Chrome. Ему принципиально необходимо чтобы filename в header было с одинарными кавычками, другим же браузерам принципиально необходимо без кавычек. Для этого например, можно использовать следующее решение.
Замена пробела на "_" осуществляется для корректного отражения имени файла при скачивании, ибо скорее всего по пробелу имя обрежется.
После этого выводим бинарные данные файла в тело скрипта.
PS: Тут хочу обратить внимание на типовую ошибку. Перед <?php и после ?> не должно быть никаких символов – иначе ничего не получится.
Теперь при клике на ссылку file_b.php?id=123, у пользователя загрузится окошко для скачивания его файла (с его именем и нужного типа).
3.1. Загрузка файла с промежуточным архивированием
Мы рассмотрели достаточно простой, базовый способ, хранения файлов. Теперь немного усовершенствуем его. Ведь в базе данных храниться бинарная последовательность, почему бы не сделать ее короче и сэкономить место. Для этого, перед тем как записать данные файла в blob, заархивируем его.
Загрузка файла с архивированием проблем особых не вызывает. Необходимо только перед тем, как сохранить blob последовательность файла в базу данных, выполнить его архивирование, например так:
А потом в конце помимо оригинала, удалить еще и его архив с веб-сервера.
А вот процесс извлечения такого файла пользователю уже гораздо интереснее.
3.2. Чтение файла из БД с извлечением его из архива
Просто так, как в прямом извлечении, поступить не получится. После того, как пользователь кликнет по ссылке, сначала надо считать файл, сохранить его на веб-сервере, разархивировать, а потом передать пользователю.
Т.е. когда пользователь кликает на ссылку file_b.php?id=123, скрипт должен дернуть другой скрипт, который считает в себя данные из blob файла (абсолютно аналогично с п.2.2) после сохранить этот файл на диск сервера, потом запустить его разархивацию, и данные из полученного файла вывести в себя, подставив нужный header, чтобы пользователю вылезло окошко – что он скачивает файл.
Для этих целей используем CURL.
После определения типа браузера и подстановки header, делаем следующее.
Таким образом, в файле с именем $path, оказывается наш заархивированный файл. Производим его разархивацию.
После этого считываем файл и интегрируем его данные уже в наш скрипт при помощи fpassthru
Теперь все должно получиться.
4. Сохранение файлов с промежуточной архивацией в blob поля.
Теперь рассмотрим вопросы быстродействия. Место то мы конечно экономим. Но вместо того, чтобы пользователь ждал только время загрузки файла на сервер, мы его заставляем ожидать еще и время архивации, и время добавления файла в blob поле. Для пользователя время загрузки файла зачастую увеличивается даже более чем в 2 раза. При извлечении аналогично, вместо того, чтобы считать данные напрямую, мы начинаем их сначала сохранять, разархивировать, а потом уже предоставлять пользователю. Все это не очень хорошо. Что же можно сделать в данном случае?
1) Во первых, можно разнести процесс загрузки файла и процесс его архивации. Т.е. пользователь загружает файл в оригинальном виде. А уже потом, скрипт запускающийся с какой-то периодичностью, будет смотреть на вновь загруженные файлы и их архивировать. В этом случае для пользователя загрузка файлов будет происходить намного быстрее, а мы при этом будем экономить место. Более того, работу данного скрипта можно организовать на другом сервере, и он не будет потреблять ресурсов веб-сервера (зачем нам высоконагруженный сервер еще и заставлять заниматься архивированием?), этот процесс может происходить в стороне, не спеша.
2) Во вторых, далеко не все типы файлов имеет смысл сжимать. Например, если разница между сжатым и несжатым файлом будет менее 10%, то игра точно не стоит свеч, экономия места минимальна – напряги процессора и время ожидания пользователя – максимальны. Для себя я отобрал следующие типы плохо сжимаемых файлов, которые архиватор даже не трогает, а просто ставит галочку (обработано – больше не трогать). RAR, GZ, ZIP, JAR, TAR, ARJ, UC2, GZ, UUE, LHA, CAB, LZH, ACE, TGZ, 7Z, AVI, MPG, 3GP, WMV, ASF, FLV, MP3, AAC, WMA, AMR, TIF, JPG, JP2, GIF, PNG.
PS: информация от ivanbolhovitinov. Правильный XLSX,DOCX — это всегда ZIP-архив. Первые 2 байта «PK». Проверить их можно так: file_get_contents($filename, NULL, NULL, 0,2)
3) Т.к. при извлечении файла пользователю, мы тоже проводим работу по разархивированию, то даже если файл не является типом из п.2 – все равно не факт что его имеет смысл архивировать. Пустая архивация – съедание своих ресурсов и что более страшно – времени ожидания пользователя. Поэтому система, перед тем как заархивировать файл – должна проверить, если в этом смысл. Для этого пришлось сделать систему превентивной архивации, т.е. скрипт сначала “пробует” — он скачивает файл, архивирует его, но перед тем как оригинал заменить архивом – происходит проверка, на сколько процентов отличается размер архива от размера оригинала. Если эта величина опять же, менее 10% — то архивация смысла никакого не имеет. Такие файлы отмечаются как обработанные и не архивируются.
Типичные представители таких файлов xlsx. Формат уже сам по себе сжатый, но по факту встречаются очень отличные файлы, какие-то можно сжать на 50%, а какие-то дай бог на 5%. Зависит от начинки.
4) Так же не имеет смысла архивировать файлы размером менее 250 байт, архив получится больше оригинала.
5) Не нужно архивировать файлы большого размера. Эмпирически выведено, что это в районе 15 мб и более. Даже, если он хорошо сжимается – на его разархивацию придется потратить определенное время (помимо того, что его надо извлечь из blobа) – такие временные ожидания пользователей уже могут напрягать.
5. Организация структуры каталогов, организация прав доступа, операции с файлами, некоторые частные случаи.
Пока мы рассмотрели только систему хранения файлов. Это базовая вещь, на которой основывается все остальное. Но для полноценной “Файловой системы” еще необходимо как-то эти файлы структурировать, назначать им права доступа и т.д.
Возможно, эта глава не всем будет интересна, т.к. реализация данной структуры будет очень сильно зависеть от стоящей задачи. Я реализовывал данную структуру для облачного сервиса erp-platform.com, поэтому в этой главе рассмотрю задачи, которые должна решать файловая система для сервиса организации работы компании:
1) Классика – Дерево каталогов, файлы. Механизм приложения файлов, редактирования их метаданных, удаления.
2) К этому пункту необходимо небольшое вступление. Рассмотрим не для всех очевидную вещь в работе систем автоматизации: когда вы прикладываете файл к задаче, он физически хранится не в задаче, а на диске. В задаче находится только ссылка на этот файл.
Когда место на диске заканчивается, системному администратору возможно понадобиться его очистить. И перебирать ему все задачи за дцать лет, удаляя из них файлы – ну это просто глупо.
Т.е. должна быть некая файловая структура, например, служебный каталог “Задачи” на диске, где будут храниться все файлы, прикладываемые к задачам, и сисадмин старые файлы может просто почистить.
Но что получится, если он их удалит? В задачах останутся ссылки, которые никуда не ведут! Тоже не есть гуд. Следовательно, в задачах должна быть не ссылка, а некое “окно” в Диск, в котором задача будет видеть только свои файлы.
Но просто “окна” мало. Пользователь может “помнить” что приложил файл, а “злой” сисадмин его тихо удалит с диска и скажет пользователю что он сумасшедший. Поэтому, данные файла можно удалить, но вот запись что файл был, должна остаться где-то в закромах и в нашем “окне” ссылка таки должна выводится каким-нибудь серым, неактивным цветом.
“Задачу” я привел для примера, аналогично файлы могут прикладываться к проектам, контрагентам, сотрудникам, объектам и т.п. Т.е. система должна быть универсальная.
Но и это еще не все. Например, заказчик, может запросто захотеть, чтобы у контрагентов было 2 области приложения файлов, например область где прикладываются счета и область где прикладываются документы. Т.е. эти “окна” должны привязываться не просто к странице и ее входным данным, а к конкретным элементам страницы.
Подведем итог пункта: файловая система должна поддерживать некие “окна” в нее из внешней системы. Каждое “окно” должно иметь функции операции с файлами в пределах своих рамок.
3) Пользователю может потребоваться найти в папке файлы, которые были приложены к такому-то контрагенту, или такому-то проекту или еще по каким-то неведомым нам признакам, при этом не важно как эти файлы могут называться. Т.е. нужна некая система поиска не только по названиям файлов, но и по их принадлежности внешним структурам.
PS: На мой взгляд такие вещи оптимально реализовывать при помощи хэштегов. Для этих целей, в файлах, можно ввести еще пару свойств: “системные хэштеги” и ”пользовательские хэштеги”. В системных пишутся системные названия, например ФИО контрагента. В пользовательские – произвольно пользователем, при приложении файла.
4) Права доступа. Само собой кто-то должен иметь права просматривать те или иные папки, кто-то нет. Права на добавление, удаление. А может так получиться, что у пользователя должен быть доступ к задаче и файлам приложенным в ней, а к папке в которой эти файлы доступа не быть. Т.е. “окно” должно иметь свои права. У системного администратора должен быть механизм для назначения или удаления прав доступа тем или иным пользователям.
Вот такие получились требования к структуре файловой системы.
Реализация всех этих вещей – достаточно сложный и ветвистый код в скриптах и в структуре БД, поэтому в рамках статьи такое не привести. И так уже очень большая статья получается.
Я опишу базовые принципы реализации каждой из задач.
Структуру каталогов вести достаточно просто. Это простая таблица в БД компании, у которой есть:
1) Название папки
2) Создатель папки
3) Узел папки в котором находится данная папка
4) Статус папки
5) Идентификатор папки
6) Общие права на папку по умолчанию (что могут все пользователи делать в папке, если им не выданы специальные права)
Подробнее по каждому пункту:
1) Название папки может дублироваться на разных уровнях дерева, в разных узлах. В одном узле название папки дублироваться не может. Данный механизм реализовать очень просто, достаточно поставить уникальный индекс на поля 1 и 3 таблицы. При дублировании имени в одном узле – система выдаст ошибку.
2) Создателя папки надо записать. Создатель папки имеет на нее всегда полные права, если иное не прописано администратором в роли пользователя. Например, даже если пользователь создал папку – администратор системы может все же закрыть ему доступ к ней, сделав соответствующую запись в роли.
Создатель папки может настроить права по умолчанию для остальных пользователей. Т.е. видят ли остальные папку, могут ли они смотреть файлы только на чтение, или могут их удалять, изменять пользовательские хэштеги и т.п. Опять же, данные настройки могут перекрываться системным администратором.
3) В папке прописывается узел другой папки, в которой она находится. Это нужно для построения древовидной системы папок.
4) Статус папки. Папка может быть рабочей, или ее можно удалить. Вопрос на самом деле не простой. Тут каждый разработчик может для себя решать что делать, можно например, организовать служебную папку “Корзина”, в которой будут отображаться папки со статусом удалено. Можно их реально удалять – но надо тогда проработать, что делать с файлами в папке, а так же со связями папки в структуре системы. Правильное решение, на мой взгляд, не давать физически удалять запись папки, пока на нее есть ссылки в системе и в ней есть какие-то файлы. Чистим файлы, чистим связи, и после этого – пожалуйста, удаляйте. Иначе можно получить глюки в зависимых модулях.
5) Каждая папка должна иметь свой идентификатор. Названия разных папок в разных узлах может дублироваться, а идентификаторы — нет. При программировании системы, когда пользователь на веб странице создает элемент Файл, в этом элементе он всегда указывает идентификатор папки, и именно в этой папке система будет сохранять файлы, прикладываемые в этом модуле, через этот элемент.
6) Права папки по умолчанию. При просмотре пользователем папки система сначала должна проверить записи на эту папку в роли пользователя, если стоят хоть какие-то настройки прав (будь то права на все, или наоборот запрет всех действий) то применяться должны эти правила, если же не написано ничего – то должны вступать правила, выставленные создателем папки.
В своей разработке, систему прав на папки, я интегрировал в общую систему прав и у администратора компании добавление в роль пользователя папки вызвать проблем не должна (как пример, реализацию прав доступа к элементам системы, можно почитать здесь).
Для связки файла с элементом страницы есть изящное решение.
Надо вычислить хэш сумму, в которой должен быть уникальный идентификатор элемента страницы, и данные страницы (например, номер проекта или задачи). Этот хэш будет являться всегда уникальным и должен храниться в записи данных файла. При загрузке страницы в момент отображения “окна”, должен вычисляться этот связующих хэш и по нему производиться поиск файлов и вывод на страницу их списка.
Также “окно” должно знать каталог, в который складывать файлы новые файлы.
Записи хэштегов к файлам. С пользовательскими (произвольными) хэштегами проблем нет, надо сделать пользователю при добавлении файла (или при его редактировании) возможность внесения пометок к файлу.
Сложнее с системными хэштегами. Например, в каждый добавляемый файл к задаче надо ставить тег “#Задача №…#”. Потом в папке Задачи, пользователь, введя в строку поиска, например “№…#“, получит все файлы интересующей задачи. У меня данный функционал реализован на уровне языка программирования, в свойствах элемента формы “Файл” (в статье я это называл “окном”). В его свойствах можно задавать строку с элементами идентификаторов, и связывать данные элементы с необходимым источником данных. Остальное система построит автоматически.
Еще, в качестве приятного бонуса, можно рассмотреть частный случай файловой игры с blob полями – Систему хранения изображений.
В какой-то момент, в разработке внутреннего языка программирования, я столкнулся с необходимостью введения нестандартного типа данных. Есть разные типы данных, integer, varchar, timestamp и т.д. Но вот типа image в базах данных нет. А нужен. Например, очень удобно взять и запросом вывести таблицу, в которой будут изображения, например стрелки вверх, вниз для перемещения данных, удаления данных и т.п. Чтобы это уже все было в базе и обрабатывалось на уровне базы, а не городить каждый раз что-то в интерфейсе юзера. Например, вот такие вещи у меня можно выводить одним запросом:

Это как раз возможно благодаря использованию blob полей. В файловой базе клиента, помимо таблицы хранения файлов, можно создать к примеру таблицу IMG и там организовать хранение изображений. На физическом уровне, в базе данных с этим типом, будет храниться только идентификатор изображения. При выводе данных на страницу, скрипт интерпретатора, встретив тип данных image, по этому идентификатору обратится в файловую базу данных и выведет изображение из blob поля. При этом пользователь, не будет видеть всей этой внутренней кухни. Он просто укажет в выходных данных процедуры параметр с типом image и сделает в процедуре запрос, выводящий поле таблицы с типом image в этот параметр. Очень удобный механизм.
На этом цикл по базам данных пока заканчиваю.
Если есть предложения по улучшению механизмов описанных в статье, или альтернативной организации хранения файлов с аналогичными возможностями, пишите комментарии.
Оглавление:
- Как сделать разный часовой пояс в разных базах данных на одном сервере.
- Как вести логи изменений данных пользователями в базе данных, сохраняя их в другой базе данных (чтобы база основная база данных не забивалась мусором и не росла)
- Как создать свою файловую систему на основе blob полей в базе данных. Почему это удобно. Вопросы эффективности хранения файлов (как получить максимальное быстродействие и при этом минимальное занимаемое место)
Данный способ – способ реализации хранения файлов, приложенных пользователем на сайте, через веб интерфейс. Это не будет “файловой системой” в том понимании как это организовано в операционной системе.
Пример, описанный в этой статье, будет решать задачу стоявшую когда-то у меня: “Выделить раздел внутри аккаунта компании на веб сайте, где сотрудники компании смогут хранить свои файлы, создавать папки (назовем его “Диск”). Диск должен быть изолированным от аккаунтов других компаний и должен интегрироваться в процессы работы аккаунта (организация хранения файлов, прикладываемых к задачам, проектам, карточкам контрагентов, отчетов и т.п.) ”.
Сразу замечу, что данный способ, с точки зрения быстродействия, менее эффективен простого сохранения файлов на веб-сервере. Но он имеет определенные преимущества, которые в моем случае перевесили недостатки потери скорости загрузки.
Недостатки: Увеличенное время загрузки файла
Преимущества
- Распределенная структура хранения. Т.е. не обязательно хранить файлы клиента на самом веб-сервере. Можно хранить их где угодно, на любых серверах своей сети. Легко перемещать их с сервера на сервер в случае необходимости.
- Удобство резервного копирования файлов клиента. Можно все делать стандартными средствами бекапа.
- Безопасность. Данный способ лишен основных уязвимостей веб приложений при загрузке файлов (ознакомиться с ними можно например здесь). Так же способ осуществляет физическую изоляцию данных клиента, от данных других клиентов, ибо у каждой компании своя БД.
Основным аргументом реализации данной системы хранения файлов послужила возможность распределённого хранения. В принципе можно использовать решения типа cifs и samba, примонтировать сетевые диски от других машин и там хранить файлы клиентов. Но в то время мне пришло вот такое вот, не совсем стандартное решение, и я им полностью доволен.
В данной статье мы будем рассматривать процесс реализации от простого к сложному:
- Общая организация структуры хранения.
- Сохранение файлов в blob поля. Прямое извлечение.
- Сохранение файлов с промежуточной архивацией в blob поля. Извлечение с промежуточной разархивацией.
- Сохранение файлов с отложенной и выборочной архивацией (не все файлы имеет смысл архивировать, в каких случаях овчинка не стоит выделки, а так же не всегда имеет смысл архивировать сразу).
- Потом мы рассмотрим организацию структуры каталогов, организацию прав доступа, операции с файлами, некоторые частные случаи и т.п.
Итак начнем.
Итак начнем.
В качестве базы данных, используется firebird 3
1. Общая организация структуры хранения.
Как и в предыдущей статье (по хранению логов), не стоит в основной рабочей базе хранить файлы, это будет много мусора, проблемы с бекапами и т.д. Для этого лучше выделить отдельную базу данных. Назовем ее “Файловая БД”. В основной базе данных должна храниться структура каталогов и ссылки на файлы, а сами бинарные данные из файлов, будут храниться в файловой БД.
В этом случае вы получите удобство бекапов, и быструю базу данных. Например, я в своей системе даю пользователям возможность самостоятельно планировать график своих бекапов, в том числе и бекапов файловой базы данных. Более того, даже есть возможность автоматического закидывания архива бекапа пользователю на его FTP (например, если он бекапы желает хранить на своем оборудовании и не платить за аренду места в облаке). Такая реализация возможна как раз благодаря хранению файлов в отдельной базе и организации распределенной системы хранения.
Так же благодаря такой организации, веб-сервер выполняет только функции веб-сервера, а не файлового хранилища. Можно более грамотно организовать распределение ресурсов в сети. При огромном количестве клиентов (огромном количестве баз данных и файловых структур) нераспределенная организация хранения данных будет просто неприемлема. Структура должна быть неограниченно масштабируемой, а так же простой.
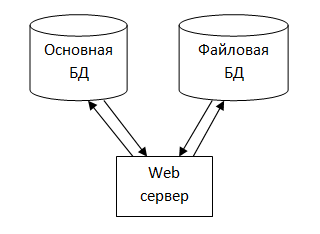
Схему можно представить следующим образом:
При этом каждый из элементов может быть (и лучше сделать так) на своем отдельном сервере. Структура хранения данных может быть организована следующим образом. В основной базе данных создается структура с данными о приложенном файле
CREATE TABLE FILES_ (
ID BIGINT,
DATA TIMESTAMP, --Дата добавления файла
DATA_DEL TIMESTAMP, --Дата удаления файла
USER_ INTEGER, --Юзер, добавивший файл
USER_DEL INTEGER, --Юзер, удаливший файл
ID_FILE INTEGER, --ID файла в файловой БД
FILE_NAME VARCHAR(256), --Название файла
FILE_NAME_TMP VARCHAR(256), --Название файла при закачке
CONTENT_TYPE VARCHAR(100), --Тип контента файла
STATUS SMALLINT, --Статус файла (есть или удален)
SIZE BIGINT, --Размер файла
SIZE_ZIP BIGINT, --Размер архива файла
SIZE_ZIP_2 BIGINT, --Тестовый прогон архивации
ZIP_USE SMALLINT, --Какого типа архиватор используется
ID_FOLDER INTEGER, --Идентификатор каталога, где лежит файл
FLAG_ZIP SMALLINT --Флаг использования архивации
);
Структура файловой базе данных может быть такой (минимум данных о файле и сам файл в blob поле).
CREATE TABLE FILES_ (
ID BIGINT,
DATA TIMESTAMP,
USER_ INTEGER, --Юзер, добавивший файл
FILE_NAME VARCHAR(256), --Название файла
CONTENT_TYPE VARCHAR(100), --Тип контента файла
FILE_DATA BLOB SUB_TYPE 0 SEGMENT SIZE 80, --Бинарная последовательность файла
STATUS SMALLINT, --Статус (есть или удален)
SIZE INTEGER, --Размер файла
SIZE_ZIP INTEGER, --Размер архива файла
ZIP_USE SMALLINT --Какого типа архиватор используется
);
Тут есть некоторая избыточность данных в этих двух таблицах относительно друг друга, но в последствии она пригодиться, например, при операции отложенной архивации, при отладке, при последующих анализах данных и т.п. Не городить же единый запрос в несколько БД.
Начнем рассмотрение с простой записи файла в blob поле.
2.1. Сохранение файлов в blob поля.
Веб формы и процесс закачки файла в каталог на веб-сервере мы рассматривать тут не будем. Предполагается что читатель с этим знаком.
Итак, пользователь нажал в веб форме кнопку, файл загрузился и сохранился в каталоге веб-сервера (пусть будет например tmp).
Данные файла в этот момент у нас есть в глобальном массиве FILES.
(примеры буду приводить на PHP)
PS: Для простоты изложения, я сознательно опускаю преобразование опасных спецсимволов к мнемоникам, принудительное приведение числовых данных к числу и т.п. Предполагается, что у читателя есть свои процедуры для этого и он осознает опасность sql-инъекций. Если этого нет, то очень рекомендую познакомится с данной темой и делать соответствующие преобразования.
//Коннект к файловой базе данных.
$dbh_file = ibase_connect(…);
//Открываем наш файл для чтения
$fd = fopen($_FILES[…]['tmp_name'], 'r');
//Добавляем данные файла в переменную
$blob = ibase_blob_import($dbh_file, $fd);
//Закрываем файл
fclose($fd);
//Если все успешно, то производим данных файла в файловую БД.
if (!is_string($blob)) {
} else {
$query = 'INSERT INTO FILES_ (
USER_,
NAME_FILE,
CONTENT_TYPE,
FILE_DATA,
SIZE,
SIZE_ZIP,
ZIP_USE)
VALUES (
'.$USER_.',
'.$_FILES[...]['name'].',
'.$file_type.',
?,
'.$_FILES[...]['size'].',
'.$_FILES[...]['size'].',
0)
RETURNING ID';
$prepared = ibase_prepare($dbh_file, $query);
$res_query = ibase_execute($prepared, $blob);
$prom_query = ibase_fetch_row($res_query);В $prom_query[0] – будет значение ID записанного файла. После успешной записи данных файла в файловую БД надо записать данные о файле в нашу основную БД.
//Делает проверку, что все ок, ID нового файла есть.
if (isset($prom_query[0]))
//Делаем коннект к основной базе
$dbh_osn = ibase_connect(…);
$query2 = '
INSERT INTO FILES (
USER_,
ID_FILE,
FILE_NAME,
SIZE,
SIZE_ZIP,
CONTENT_TYPE,
FILE_ NAME_TMP,
ZIP_USE)
VALUES (
'.$USER_.',
'.$prom_query[0].',
'. $_FILES[…]['name']).',
'. $_FILES[…]['size'].',
'. $_FILES[…]['size'].',
'.$_FILES[…]['type'].',
'.basename($_FILES[…]['tmp_name']).',
0)';
$res_query2 = ibase_query($dbh_osn, $query2);
//Последним шагом удаляем оригинал файлов в папке tmp.
unlink($_FILES[…]['tmp_name']);Все, у нас файл записан в файловую БД. На веб-сервере его нет. В основной БД есть информация об этом файле, его статусе, типе, размере и идентификаторе в файловой БД.
2.2. Чтение файла из БД.
Когда пользователь кликает на ссылку с именем файла, нам надо осуществить обратный процесс. Извлечь файл из БД и преподнести браузеру пользователя эту последовательность данных, сказав какого типа этот файл.
В ссылке в качестве GET параметров должен быть указан идентификатор файла (либо хэш идентификатора с солью – зависит от требований к безопасности системы, мы будем рассматривать пока простую ситуацию). Например, ссылка может выглядеть следующим образом Файл.
На этапе простого чтения из БД (без архивирования данных), нам достаточно обращения в файловую БД.
//Делаем коннект к базе данных
$dbh_file = ibase_connect(…)
$query="select
p.file_data,
p.CONTENT_TYPE,
p.FILE_NAME,
p.size
from FILES p where p.id=".$_GET['id'];
$res = ibase_query($dbh_file, $query);
$data = ibase_fetch_row($res);При указании типа данных в header, выявлена индивидуальная проблема с браузером Chrome. Ему принципиально необходимо чтобы filename в header было с одинарными кавычками, другим же браузерам принципиально необходимо без кавычек. Для этого например, можно использовать следующее решение.
preg_match("/(MSIE|Opera|Firefox|Chrome|Version)(?:\/| )([0-9.]+)/", $_SERVER['HTTP_USER_AGENT'], $browser_info);
list(,$browser,$version) = $browser_info;
if ($browser=='Chrome')
header("Content-Disposition: attachment; filename='".str_replace(' ','_',$data[2])."'");
else
header("Content-Disposition: attachment; filename=".str_replace(' ','_',$data[2]));
Замена пробела на "_" осуществляется для корректного отражения имени файла при скачивании, ибо скорее всего по пробелу имя обрежется.
После этого выводим бинарные данные файла в тело скрипта.
echo ibase_blob_echo($data[0]);PS: Тут хочу обратить внимание на типовую ошибку. Перед <?php и после ?> не должно быть никаких символов – иначе ничего не получится.
Теперь при клике на ссылку file_b.php?id=123, у пользователя загрузится окошко для скачивания его файла (с его именем и нужного типа).
3.1. Загрузка файла с промежуточным архивированием
Мы рассмотрели достаточно простой, базовый способ, хранения файлов. Теперь немного усовершенствуем его. Ведь в базе данных храниться бинарная последовательность, почему бы не сделать ее короче и сэкономить место. Для этого, перед тем как записать данные файла в blob, заархивируем его.
Немного статистики:
В первый раз эта мысль мне пришла около 1.5 лет назад. В тот момент я как раз разрабатывал модуль согласования счетов для одной компании и решил экспериментально интегрировать им данную функцию. В данный модуль прикладываются всевозможные файлы с информацией по счетам и договорам, pdf, xls, doc и т.п.
За 1.5 года в средне-типовой компании со штатом 50-70 человек, к одному модулю было приложено(на текущий момент) 4085 файлов общим объемом 1526 мб, при этом на диске это все занимает 1240 мб. Т.е. архивация zip архивом, дала экономию около 20%. Это довольно неплохо.
В те времена архивация реализовывалась мной через библиотеку zip.lib.php прямо в скрипте. Позже я пришел к выводу, что этот способ не оптимален и по сжатию и по быстродействию. В текущий момент на практике используется архиватор 7zip.
Загрузка файла с архивированием проблем особых не вызывает. Необходимо только перед тем, как сохранить blob последовательность файла в базу данных, выполнить его архивирование, например так:
exec('7z a <ваш файл> <файл архива>);А потом в конце помимо оригинала, удалить еще и его архив с веб-сервера.
А вот процесс извлечения такого файла пользователю уже гораздо интереснее.
3.2. Чтение файла из БД с извлечением его из архива
Просто так, как в прямом извлечении, поступить не получится. После того, как пользователь кликнет по ссылке, сначала надо считать файл, сохранить его на веб-сервере, разархивировать, а потом передать пользователю.
Т.е. когда пользователь кликает на ссылку file_b.php?id=123, скрипт должен дернуть другой скрипт, который считает в себя данные из blob файла (абсолютно аналогично с п.2.2) после сохранить этот файл на диск сервера, потом запустить его разархивацию, и данные из полученного файла вывести в себя, подставив нужный header, чтобы пользователю вылезло окошко – что он скачивает файл.
Для этих целей используем CURL.
После определения типа браузера и подстановки header, делаем следующее.
//Генерируем случайное имя файла и открываем файл для чтения
//Открываем файл
$fp = fopen($path, 'w');
//Дергаем curl-ом ссылку на скрипт, который считывает в себя данные из blob файла, и выводим их в открытый файл.
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_USERAGENT, $agent);
curl_setopt($ch, CURLOPT_FILE, $fp);
curl_exec($ch);
curl_close($ch);
fclose($fp);Таким образом, в файле с именем $path, оказывается наш заархивированный файл. Производим его разархивацию.
exec('7z e '.$path.' –o <каталог разархивации> -y');После этого считываем файл и интегрируем его данные уже в наш скрипт при помощи fpassthru
$stream = fopen(<имя файла>,'r');
fpassthru($stream);
fclose($stream);Теперь все должно получиться.
4. Сохранение файлов с промежуточной архивацией в blob поля.
Теперь рассмотрим вопросы быстродействия. Место то мы конечно экономим. Но вместо того, чтобы пользователь ждал только время загрузки файла на сервер, мы его заставляем ожидать еще и время архивации, и время добавления файла в blob поле. Для пользователя время загрузки файла зачастую увеличивается даже более чем в 2 раза. При извлечении аналогично, вместо того, чтобы считать данные напрямую, мы начинаем их сначала сохранять, разархивировать, а потом уже предоставлять пользователю. Все это не очень хорошо. Что же можно сделать в данном случае?
1) Во первых, можно разнести процесс загрузки файла и процесс его архивации. Т.е. пользователь загружает файл в оригинальном виде. А уже потом, скрипт запускающийся с какой-то периодичностью, будет смотреть на вновь загруженные файлы и их архивировать. В этом случае для пользователя загрузка файлов будет происходить намного быстрее, а мы при этом будем экономить место. Более того, работу данного скрипта можно организовать на другом сервере, и он не будет потреблять ресурсов веб-сервера (зачем нам высоконагруженный сервер еще и заставлять заниматься архивированием?), этот процесс может происходить в стороне, не спеша.
2) Во вторых, далеко не все типы файлов имеет смысл сжимать. Например, если разница между сжатым и несжатым файлом будет менее 10%, то игра точно не стоит свеч, экономия места минимальна – напряги процессора и время ожидания пользователя – максимальны. Для себя я отобрал следующие типы плохо сжимаемых файлов, которые архиватор даже не трогает, а просто ставит галочку (обработано – больше не трогать). RAR, GZ, ZIP, JAR, TAR, ARJ, UC2, GZ, UUE, LHA, CAB, LZH, ACE, TGZ, 7Z, AVI, MPG, 3GP, WMV, ASF, FLV, MP3, AAC, WMA, AMR, TIF, JPG, JP2, GIF, PNG.
PS: информация от ivanbolhovitinov. Правильный XLSX,DOCX — это всегда ZIP-архив. Первые 2 байта «PK». Проверить их можно так: file_get_contents($filename, NULL, NULL, 0,2)
3) Т.к. при извлечении файла пользователю, мы тоже проводим работу по разархивированию, то даже если файл не является типом из п.2 – все равно не факт что его имеет смысл архивировать. Пустая архивация – съедание своих ресурсов и что более страшно – времени ожидания пользователя. Поэтому система, перед тем как заархивировать файл – должна проверить, если в этом смысл. Для этого пришлось сделать систему превентивной архивации, т.е. скрипт сначала “пробует” — он скачивает файл, архивирует его, но перед тем как оригинал заменить архивом – происходит проверка, на сколько процентов отличается размер архива от размера оригинала. Если эта величина опять же, менее 10% — то архивация смысла никакого не имеет. Такие файлы отмечаются как обработанные и не архивируются.
Типичные представители таких файлов xlsx. Формат уже сам по себе сжатый, но по факту встречаются очень отличные файлы, какие-то можно сжать на 50%, а какие-то дай бог на 5%. Зависит от начинки.
4) Так же не имеет смысла архивировать файлы размером менее 250 байт, архив получится больше оригинала.
5) Не нужно архивировать файлы большого размера. Эмпирически выведено, что это в районе 15 мб и более. Даже, если он хорошо сжимается – на его разархивацию придется потратить определенное время (помимо того, что его надо извлечь из blobа) – такие временные ожидания пользователей уже могут напрягать.
5. Организация структуры каталогов, организация прав доступа, операции с файлами, некоторые частные случаи.
Пока мы рассмотрели только систему хранения файлов. Это базовая вещь, на которой основывается все остальное. Но для полноценной “Файловой системы” еще необходимо как-то эти файлы структурировать, назначать им права доступа и т.д.
Возможно, эта глава не всем будет интересна, т.к. реализация данной структуры будет очень сильно зависеть от стоящей задачи. Я реализовывал данную структуру для облачного сервиса erp-platform.com, поэтому в этой главе рассмотрю задачи, которые должна решать файловая система для сервиса организации работы компании:
1) Классика – Дерево каталогов, файлы. Механизм приложения файлов, редактирования их метаданных, удаления.
2) К этому пункту необходимо небольшое вступление. Рассмотрим не для всех очевидную вещь в работе систем автоматизации: когда вы прикладываете файл к задаче, он физически хранится не в задаче, а на диске. В задаче находится только ссылка на этот файл.
Когда место на диске заканчивается, системному администратору возможно понадобиться его очистить. И перебирать ему все задачи за дцать лет, удаляя из них файлы – ну это просто глупо.
Т.е. должна быть некая файловая структура, например, служебный каталог “Задачи” на диске, где будут храниться все файлы, прикладываемые к задачам, и сисадмин старые файлы может просто почистить.
Но что получится, если он их удалит? В задачах останутся ссылки, которые никуда не ведут! Тоже не есть гуд. Следовательно, в задачах должна быть не ссылка, а некое “окно” в Диск, в котором задача будет видеть только свои файлы.
Но просто “окна” мало. Пользователь может “помнить” что приложил файл, а “злой” сисадмин его тихо удалит с диска и скажет пользователю что он сумасшедший. Поэтому, данные файла можно удалить, но вот запись что файл был, должна остаться где-то в закромах и в нашем “окне” ссылка таки должна выводится каким-нибудь серым, неактивным цветом.
“Задачу” я привел для примера, аналогично файлы могут прикладываться к проектам, контрагентам, сотрудникам, объектам и т.п. Т.е. система должна быть универсальная.
Но и это еще не все. Например, заказчик, может запросто захотеть, чтобы у контрагентов было 2 области приложения файлов, например область где прикладываются счета и область где прикладываются документы. Т.е. эти “окна” должны привязываться не просто к странице и ее входным данным, а к конкретным элементам страницы.
Подведем итог пункта: файловая система должна поддерживать некие “окна” в нее из внешней системы. Каждое “окно” должно иметь функции операции с файлами в пределах своих рамок.
3) Пользователю может потребоваться найти в папке файлы, которые были приложены к такому-то контрагенту, или такому-то проекту или еще по каким-то неведомым нам признакам, при этом не важно как эти файлы могут называться. Т.е. нужна некая система поиска не только по названиям файлов, но и по их принадлежности внешним структурам.
PS: На мой взгляд такие вещи оптимально реализовывать при помощи хэштегов. Для этих целей, в файлах, можно ввести еще пару свойств: “системные хэштеги” и ”пользовательские хэштеги”. В системных пишутся системные названия, например ФИО контрагента. В пользовательские – произвольно пользователем, при приложении файла.
4) Права доступа. Само собой кто-то должен иметь права просматривать те или иные папки, кто-то нет. Права на добавление, удаление. А может так получиться, что у пользователя должен быть доступ к задаче и файлам приложенным в ней, а к папке в которой эти файлы доступа не быть. Т.е. “окно” должно иметь свои права. У системного администратора должен быть механизм для назначения или удаления прав доступа тем или иным пользователям.
Вот такие получились требования к структуре файловой системы.
Реализация всех этих вещей – достаточно сложный и ветвистый код в скриптах и в структуре БД, поэтому в рамках статьи такое не привести. И так уже очень большая статья получается.
Я опишу базовые принципы реализации каждой из задач.
Структуру каталогов вести достаточно просто. Это простая таблица в БД компании, у которой есть:
1) Название папки
2) Создатель папки
3) Узел папки в котором находится данная папка
4) Статус папки
5) Идентификатор папки
6) Общие права на папку по умолчанию (что могут все пользователи делать в папке, если им не выданы специальные права)
Подробнее по каждому пункту:
1) Название папки может дублироваться на разных уровнях дерева, в разных узлах. В одном узле название папки дублироваться не может. Данный механизм реализовать очень просто, достаточно поставить уникальный индекс на поля 1 и 3 таблицы. При дублировании имени в одном узле – система выдаст ошибку.
2) Создателя папки надо записать. Создатель папки имеет на нее всегда полные права, если иное не прописано администратором в роли пользователя. Например, даже если пользователь создал папку – администратор системы может все же закрыть ему доступ к ней, сделав соответствующую запись в роли.
Создатель папки может настроить права по умолчанию для остальных пользователей. Т.е. видят ли остальные папку, могут ли они смотреть файлы только на чтение, или могут их удалять, изменять пользовательские хэштеги и т.п. Опять же, данные настройки могут перекрываться системным администратором.
3) В папке прописывается узел другой папки, в которой она находится. Это нужно для построения древовидной системы папок.
4) Статус папки. Папка может быть рабочей, или ее можно удалить. Вопрос на самом деле не простой. Тут каждый разработчик может для себя решать что делать, можно например, организовать служебную папку “Корзина”, в которой будут отображаться папки со статусом удалено. Можно их реально удалять – но надо тогда проработать, что делать с файлами в папке, а так же со связями папки в структуре системы. Правильное решение, на мой взгляд, не давать физически удалять запись папки, пока на нее есть ссылки в системе и в ней есть какие-то файлы. Чистим файлы, чистим связи, и после этого – пожалуйста, удаляйте. Иначе можно получить глюки в зависимых модулях.
5) Каждая папка должна иметь свой идентификатор. Названия разных папок в разных узлах может дублироваться, а идентификаторы — нет. При программировании системы, когда пользователь на веб странице создает элемент Файл, в этом элементе он всегда указывает идентификатор папки, и именно в этой папке система будет сохранять файлы, прикладываемые в этом модуле, через этот элемент.
6) Права папки по умолчанию. При просмотре пользователем папки система сначала должна проверить записи на эту папку в роли пользователя, если стоят хоть какие-то настройки прав (будь то права на все, или наоборот запрет всех действий) то применяться должны эти правила, если же не написано ничего – то должны вступать правила, выставленные создателем папки.
В своей разработке, систему прав на папки, я интегрировал в общую систему прав и у администратора компании добавление в роль пользователя папки вызвать проблем не должна (как пример, реализацию прав доступа к элементам системы, можно почитать здесь).
Для связки файла с элементом страницы есть изящное решение.
Надо вычислить хэш сумму, в которой должен быть уникальный идентификатор элемента страницы, и данные страницы (например, номер проекта или задачи). Этот хэш будет являться всегда уникальным и должен храниться в записи данных файла. При загрузке страницы в момент отображения “окна”, должен вычисляться этот связующих хэш и по нему производиться поиск файлов и вывод на страницу их списка.
Также “окно” должно знать каталог, в который складывать файлы новые файлы.
Записи хэштегов к файлам. С пользовательскими (произвольными) хэштегами проблем нет, надо сделать пользователю при добавлении файла (или при его редактировании) возможность внесения пометок к файлу.
Сложнее с системными хэштегами. Например, в каждый добавляемый файл к задаче надо ставить тег “#Задача №…#”. Потом в папке Задачи, пользователь, введя в строку поиска, например “№…#“, получит все файлы интересующей задачи. У меня данный функционал реализован на уровне языка программирования, в свойствах элемента формы “Файл” (в статье я это называл “окном”). В его свойствах можно задавать строку с элементами идентификаторов, и связывать данные элементы с необходимым источником данных. Остальное система построит автоматически.
Еще, в качестве приятного бонуса, можно рассмотреть частный случай файловой игры с blob полями – Систему хранения изображений.
В какой-то момент, в разработке внутреннего языка программирования, я столкнулся с необходимостью введения нестандартного типа данных. Есть разные типы данных, integer, varchar, timestamp и т.д. Но вот типа image в базах данных нет. А нужен. Например, очень удобно взять и запросом вывести таблицу, в которой будут изображения, например стрелки вверх, вниз для перемещения данных, удаления данных и т.п. Чтобы это уже все было в базе и обрабатывалось на уровне базы, а не городить каждый раз что-то в интерфейсе юзера. Например, вот такие вещи у меня можно выводить одним запросом:
Это как раз возможно благодаря использованию blob полей. В файловой базе клиента, помимо таблицы хранения файлов, можно создать к примеру таблицу IMG и там организовать хранение изображений. На физическом уровне, в базе данных с этим типом, будет храниться только идентификатор изображения. При выводе данных на страницу, скрипт интерпретатора, встретив тип данных image, по этому идентификатору обратится в файловую базу данных и выведет изображение из blob поля. При этом пользователь, не будет видеть всей этой внутренней кухни. Он просто укажет в выходных данных процедуры параметр с типом image и сделает в процедуре запрос, выводящий поле таблицы с типом image в этот параметр. Очень удобный механизм.
На этом цикл по базам данных пока заканчиваю.
Если есть предложения по улучшению механизмов описанных в статье, или альтернативной организации хранения файлов с аналогичными возможностями, пишите комментарии.
