Всем доброго времени суток! Я студент, для дипломной работы выбрал тему «информационные нейронные сети» (ИНС). Задачи, где требуется работать с числами, решались достаточно легко. И я решил усложнить систему, добавив обработку слов. Таким образом, я поставил перед собой задачу разработать «робота-собеседника», который мог бы общаться на какую-нибудь определённую тему.
Так как тема общения с роботом довольно обширна, диалог в целом я не оцениваю (привет товарищу Тьюрингу), рассматривается лишь адекватность ответа «собеседника» на реплику человека.
Далее будем называть вопросом предложение, поступающее на вход ИНС, и ответом предложение, полученное на её выходе.
Архитектура 1. Двухслойная нейронная сеть прямого распространения с одним скрытым слоем
Так как нейронные сети работают только с числами, необходимо закодировать слова. Для простоты из рассмотрения исключены знаки препинания, с заглавной буквы пишутся только имена собственные.
Каждое слово кодируется двумя целыми числами, начиная с единицы (ноль отвечает за отсутствие слова) — номером категории и номером слова в этой категории. Предполагалось в «категории» хранить слова, близкие по смыслу или типу (цвета, имена, например).
Таблица 1
| |
Категория 1 |
Категория 2 |
Категория 3 |
Категория 4 |
| 1 2 3 4 5 6 7 |
ты твой тебя твои тебе тобой я |
хорошо прекрасно замечательно превосходно хороший хорошим хорошие |
плохо ужасно отвратительно плохой плохие |
привет здравствуй приветствую приветик здорова |
Для нейронной сети данные нормализуются, приводятся к диапазону ![$[0, 1]$](https://habrastorage.org/getpro/habr/formulas/6e2/075/7f0/6e20757f072cd273db5f1ea44424f67d.svg) . Номер категории и слова — на максимальное значение
. Номер категории и слова — на максимальное значение  номера категории или слова во всех категориях. Предложение переводится в вещественный вектор фиксированной длины, недостающие элементы заполняются нулями.
номера категории или слова во всех категориях. Предложение переводится в вещественный вектор фиксированной длины, недостающие элементы заполняются нулями.
Каждое предложение (вопрос и ответ) может состоять максимум из десяти слов. Таким образом получается сеть с 20 входами и 20 выходами.
Необходимое число связей в сети для запоминания N примеров рассчитывалось по формуле

где m — число входов, n — число выходов, N — число примеров.
Число связей в сети с одним скрытым слоем, состоящим из H нейронов

откуда требуемое число скрытых нейронов

Для
 ,
,  получается соответствие
получается соответствие
В результате получаем зависимость числа скрытых нейронов от количества примеров:

Структура обучаемой сети представлена на рисунке 1.
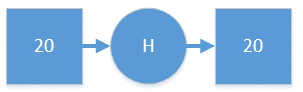
Рисунок 1. Простейшая ИНС для запоминания предложений
Реализована сеть в MATLAB, обучение — метод обратного распространения ошибки. Обучающая выборка содержит 32 предложения…
Большего и не потребовалось…
ИНС не могла запомнить более 15 предложений, что демонстрирует следующий график (рисунок 2). Ошибка вычисляется как модуль разности между текущим выходом НС и требуемым.
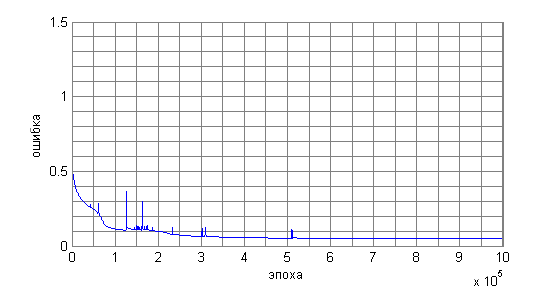
Рисунок 2. Ошибка НС при обучении на 32 примерах
Пример диалога (все вопросы из обучающей выборки):
|
|
В результате тестирования для различного количества примеров стало понятно, что даже обучающую выборку ИНС запоминает с большим трудом (что видно из рисунка 2). Даже за миллион эпох ошибка не смогла уменьшиться до требуемого значения.
Архитектура 2. Двухслойная нейронная сеть прямого распространения
Следующий способ закодировать слова для ИНС — one-hot-кодировка[4]. Суть её в следующем: пусть в словаре имеется  слов, упорядоченных по алфавиту. Каждое слово такого словаря кодируется вектором длины , содержащим единицу на месте, соответствующем номеру слова в словаре и нули на других местах.
слов, упорядоченных по алфавиту. Каждое слово такого словаря кодируется вектором длины , содержащим единицу на месте, соответствующем номеру слова в словаре и нули на других местах.
Для экспериментов был создан словарь из  слов и обучающий набор из 95 предложений. На вход НС подавалось шесть слов и ответ также рассматривался из шести слов.
слов и обучающий набор из 95 предложений. На вход НС подавалось шесть слов и ответ также рассматривался из шести слов.
Число нейронов в скрытом слое определялось по зависимости числа связей от числа примеров, которые сеть может выучить без ошибок.
|
|
По результатам видно, что теперь система может запоминать большее количество слов. Почти победа… но возникает другая проблема — определение синонимов и похожих слов[4].
Архитектура 3. Двухслойная нейронная сеть прямого распространения
с одним скрытым слоем и word2vec-кодировка
Для решения проблемы похожести слов и синонимов решил попробовать word2vec[4], который позволяет нужным образом закодировать слова.
Для экспериментов по работе сети использовался словарь word2vec векторов длины  , обученный на тренировочной базе нейронной сети.
, обученный на тренировочной базе нейронной сети.
На вход нейронной сети подаётся шесть слов (вектор длины 300) и предлагается получить ответ, также состоящий из шести слов. При обратном кодировании вектор предложения разделяется на шесть векторов слов, для каждого из которых в словаре ищется максимально возможное соответствие по косинусу угла между векторами  и
и  :
:
![$cos[A, B]=\frac{\sum_{d=1}^{D}{(A_d B_d)}}{\sqrt{\sum_{d=1}^{D}{A_d^2}}\sqrt{\sum_{d=1}^{D}{B_d^2}}}$](https://habrastorage.org/getpro/habr/formulas/6de/3d9/7a4/6de3d97a4bb4166a5479754b67186088.svg)
Но даже при такой реализации word2vec не делает нужных связей между словами с точки зрения русского языка. Для создания словаря, в котором именно синонимы будут находиться максимально рядом был сформирован корпус обучения с сгруппированными синонимами, по возможности сочетающиеся по смыслу друг с другом:
| МНЕ МОЙ МЕНЯ Я МОЁ МОИХ ТЫ ТЕБЯ ТЕБЕ ТВОИ ТВОЙ ТВОЁ ТОБОЙ НЕ НЕТ НА У С И ДА ДО О ЧЁМ А ТОЖЕ ДАЖЕ ТОЛЬКО ЭТО КТО ЧТО ТАКОЙ РОДИЛСЯ РОЖДЕНИЯ РОБОТ РОБОТАМ РОБОТЫ РОБОТОВ РОБОТАМИ |
В результате такого представления отпадает необходимость запоминать множество синонимов, на которые можно давать одинаковый ответ (типа «привет», «здравствуйте», «приветствую»). Например, в обучающей выборке участвовала только «здравствуй — привет», остальные ответы получены из-за большой косинусной близости «здравствуй», «привет» и «приветствую».
|
|
Однако вместе с этим, из-за большой близости синонимов в ответе (беседа=беседую=беседовал=…, я=меня=моё=мне=…) они чаще всего путаются при незначительной переформулировке вопроса («Как ты учишься?» Вместо «Как ты учишься у человека?»).
Злоключение
Как видите, при попытке использовать ИНС для общения с человеком, у меня получилось «две блондинки»: одна не может запомнить больше 15 предложений, а вторая много знает, но ничего не понимает.
Судя по описаниям как на Хабрахабре, так и на других сайтах, с такой проблемой сталкиваются не все. Поэтому возникает вопрос: где собака зарыта? Какой подход нужно использовать для получения ИНС, способной запоминать и понимать хотя бы 100 – 200 фраз?
Кто сталкивался с подобными вопросами, прошу ваших советов и предложений.
Список литературы
- Как понять LSTM-сети
- Разработка: Chatbot на нейронных сетях
- Разработка: Библиотека машинного обучения Google TensorFlow – первые впечатления и сравнение с собственной реализацией
- Разработка: Классификация предложений с помощью нейронных сетей без предварительной обработки
- Разработка: Русский нейросетевой чатбот
