Уже больше года, как у меня есть свой хобби-проект, в котором я разрабатываю движок базы данных для хранения временных рядов — dariadb. Задача довольно интересная — тут есть и сложные алгоритмы да и область для меня совершенно новая. За год был сделан сам движок, небольшой сервер для него и клиент. Написано все это на С++. И если клиент-сервер находится пока в достаточно сыром состоянии, то движок уже обрел некоторую стабильность.Задача хранения временных рядов достаточно распространена там, где есть хоть какие-то измерения (от SCADA-систем до мониторинга состояния серверов).
Для решения этой задачи есть некоторое количество решений разной степени навороченности:
В качестве вводной статьи могу посоветовать широко известную в определенных кругах статью от FaceBook “Gorilla: A Fast, Scalable, In-Memory Time Series Database”.
Основной задачей же dariadb было создание встраиваемого решения, которое можно было бы (подобно SQLite) встроить в свое приложение и переложить на него хранение, обработку и анализ временных рядов. Из поставленных задач на данный момент выполнено приём, хранение и обработка измерений. Проект пока носит исследовательский характер, поэтому сейчас для использования в продакшене он не годится. Во всяком случае пока :)
Временной ряд измерений
Временной ряд измерений представляет из себя последовательность четверок {Time, Value, Id, Flag}, где
- Time, время измерения (8 байт)
- Value, сам замер (8 байт)
- Id, идентификатор временного ряда (4 байта)
- Flag, флаг замера (4 байта)
Флаг используется только при чтении. Есть специальный флаг “нет данных” (_NO_DATA = 0xffffffff), который проставляется для значений, которых или нет совсем или они не удовлетворяют фильтру. Если в запросе поле флаг указано не 0 (ноль), то для каждого измерения, которое подходит по времени для запроса, к его полю flag применяется операция "логическое И", если ответ равен фильтру, то измерение проходит. Значение поступают в порядке возрастания метки времени (но это не обязательно, иногда нужно записать значение “в прошлое”), по ним надо уметь делать срез и запрашивать интервалы.
Читаем срез
Срез значения для временного ряда на метку времени T, это значение, которые существует в момент времени T или “левее” этого времени.Мы всегда возвращаем левое ближайшее, но только если устраивает флаг. Если значения нет или флаг не подходит, то “нет данных”.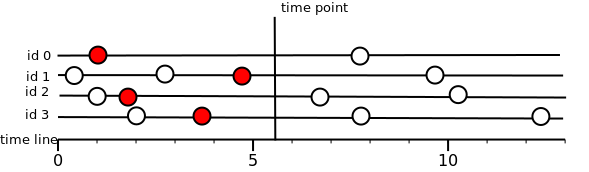
Тут важно понять, почему именно возвращается “нет данных” для значений, не попавших под флаг. Может так случиться, что ни одно из хранимых значений не попадает под флаг, тогда это приведет к чтению всего хранилища. Поэтому было принято решение, что если значение на момент среза есть, но флаг не совпал, то считаем, что значения нет.
Читаем интервал.
Тут все значительно проще: возвращаются все значения, которые попали во временной интервал. Т.е. должно выполняться условие from<=T<=to, где T — время замера.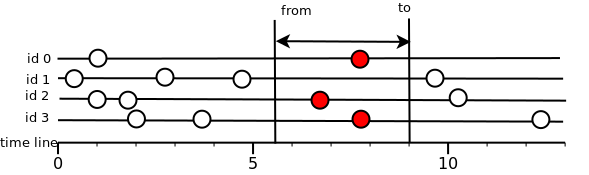
Если измерение попадает в интервал, но не удовлетворяет флагу, то оно отбраковывается. Данные всегда отдаются пользователю в порядке возрастания метки времени.
МинМаксы, последние значения, статистика.
Также есть возможность получить для каждого временного ряда его минимальное и максимальное время, которое записано в хранилище; последнее записанное значение; разную статистику на интервале.
Базовое устройство хранилища
Получился проект со следующими характеристиками:
- Поддержка неотсортированных значений
- Значения, которые записаны в хранилище поменять уже нельзя.
- Различные стратегии записи.
- Хранение на диске в виде LSM-дерева (https://ru.wikipedia.org/wiki/LSM-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
- Высокая скорость записи:2.5 — 3.5 миллиона записей в секунду, при записи на диск; 7-9 миллионов записей в секунду при записи в память.
- Восстановление после сбоев.
- CRC32 для всех сжатых значений.
- Два варианта запроса данных: Functor API (async) — для запроса передается колбек-функция, которая будет применяться для каждого значения, попавшего в запрос. Standard API — значения вернуться в виде списка или словаря.
Статистика на интервале: время min/max; значения min/max количество измерений; сумма значений
Реализованы следующие слои: хранение в оперативной памяти, хранение на диске в лог файлах, хранение в сжатом виде.
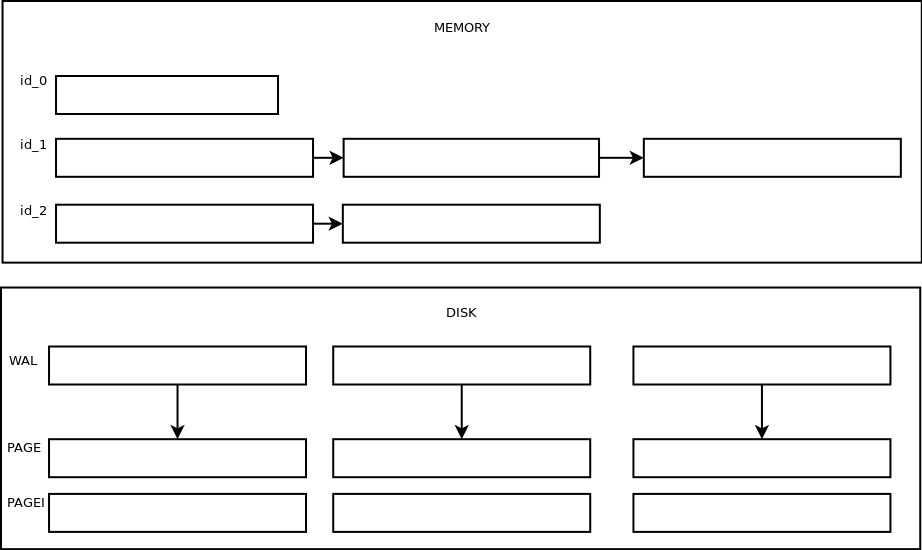
Лог-файлы (*.wal)
Это просто лог-файлы. В памяти держится небольшой буфер, при заполнении которого он сортируется и сбрасывается на диск. Максимальный размер буфера и файла регламентируется настройкам (см. ниже). При запросах весь файл вычитывается и значения попавшие в запрос отдаются пользователю. Никаких индексов и маркеров для ускорения поиска, просто лог-файл. Имя файла формируется из времени создания этого файла в микросекундах + расширение (wal).
Сжатые страницы (*.page)
Страницы получают путем сжатия лог-файлов и их имя совпадает с лог-файлом из которого страница была получена. Если при старте у нас оказывается, что есть страницы с таким же именем (без учета расширения), что и лог файл, то мы делаем вывод, что хранилище не было остановлено нормальным способом, страница удаляется и сжатие повторяется вновь.Эти файлы уже лучше оптимизированы для чтения. Они состоят из наборов чанков, каждый чанк хранит отсортированные и сжатые значения для одного временного ряда, максимальный размер чанка ограничен настройками. В конце файла находится футер, который хранит минмаксы времени, фильтр блума для id попавших в файл временных рядов, статистику для хранимого временного ряда.

Для каждой страницы создается индексный файл. Индексный файл содержит набор минмаксов времени для каждого чанка в странице, id временного ряда, позицию в странице. Таким образом, при запросах за интервал или среза нам просто необходимо в индексном файле найти нужные чанки и вычитать их из страницы.В каждом чанке значения хранятся в сжатом виде. Для каждого поля измерения используется свой алгоритм (вдохновлялся знаменитой статьей “Gorilla: A Fast, Scalable, In-Memory Time Series Database”):
DeltaDelta — для времени
Xor — для самих значений
LEB128 — для флагов
В результате на разных данных сжатие достигает до 3-х раз.
Футеры индексных файлов всегда лежат в кеше и используются для быстрого поиска нужных страниц, для выдачи результатов.
Хранение в памяти
В памяти каждый временной ряд хранится в списке (простой std::list из stl) чанков, а для быстрого поиска над всем этим построено B+ дерево, построенное по максимальному времени каждого чанка. Таким образом, при запросах интервала или среза, мы просто находим чанки, которые содержат нужные нам данным, распаковываем их и отдаем. Хранилище в памяти ограничено по максимальному размеру, т.е. если мы слишком энергично будем писать в него, то лимит быстро кончится и дальше все пойдет по сценарию, который определяется стратегией хранения
Cтратегии хранения
WAL — данные пишутся только в лог файлы, пережатие в страницы автоматически не запускается, но есть возможность запустить сжатие всех лог-файлов вручную.
COMPRESSED — данные пишутся в лог файлы, но как только файл достигает предела (см настройки), рядом создается новый файл, а старый ставится в очередь на сжатие.
MEMORY — все пишется в память, как только достигаем лимит, самые старые чанки начинаем сбрасывать на диск.
- CACHE — пишем и в память и на диск. данная стратегия дает скорость записи как у COMPRESSED, зато быстрый поиск для свежих недавно записанных данных. Для данной также актуален лимит по памяти, если мы его достигнем, то старые чанки просто удаляются.
Переупаковка и запись в прошлое.
Возможна запись данных в любом порядке. Если стратегия MEMORY и мы пишем в прошлое, которое хранится еще в памяти, то мы просто добавим в существующий чанк новые данные. Если же мы пишем так далеко в прошлое, что это время уже не находится в памяти, или стратегия хранения у нас не MEMORY, то данные запишутся в текущий чанк, но при чтении данных будет использован алгоритм k-merge, что немного замедляет чтение, если таких чанков очень много. Чтобы такого не было, есть вызов repack, который переупаковывает страницы, убирая дубликаты и сортируя данные в порядке возрастания метки времени. При этом страницы схлопываются так, чтобы на каждом уровне было страниц не больше, чем задано настройками (LSM — дерево).
Создание временного ряда
Выбор идентификатора для временного ряда можно реализовать самостоятельно, а можно возложить на dariadb — реализована возможность создания именованных временных рядов, затем по имени можно получить идентификатор, а его уже прописать в нужное измерение. Это проще чем кажется. В любом случае, если вы запишите измерение, но оно не описано в файле с временными рядами (создается автоматически при инициализации хранилища), то измерение будет записано без каких либо проблем.
Настройки
Настройки можно задать через класс Settings(см пример ниже). доступны следующие настройки:
- wal_file_size — максимальный размер лог файла в измерениях (не в байтах!).
- wal_cache_size — размер буфера в памяти, в который пишутся измерения, перед тем как попасть в лог-файл.
- chunk_size — размер чанка в байтах strategy — стратегия хранения.
- memory_limit максимальный размер занимаемой памяти хранилищем в ОЗУ.
- percent_when_start_droping — процент заполнения памяти ОЗУ хранилищем, когда начнется сброс чанков.
- percent_to_drop — сколько процентов памяти надо очистить, когда мы достигли предела по памяти.
- max_pages_in_level — максимальное количество страниц (.page) на каждом уровне.
Итоговые бенчмарки
Приведу скоростные характеристики на типичных задачах.
Условия:
2 потока пишут по 50 временных рядов, в каждом ряде измерения за 2-е суток. Частота замера — 2 измерения в сек. В итоге получаем 2000000 измерений. Машина Intel core i5 2.8 760 @ GHz, 8 Gb озу, жесткий диск WDC WD5000AAKS, Windows 7
Средняя скорость записи в секунду:
| WAL, зап/сек | Compressed, зап/сек | MEMORY, зап/сек | CACHE, зап/сек |
|---|---|---|---|
| 2.600.000 | 420.000 | 5.000.000 | 420.000 |
Чтение среза.
Выбирается N случайных временных рядов, для каждого находится время, на котором точно есть значения и запрашивается среза на случайный момент времени в этом интервале.
| WAL, сек | Compressed, сек | MEMORY, сек | CACHE, сек |
|---|---|---|---|
| 0.03 | 0.02 | 0.005 | 0.04 |
Время чтение интервала за 2-е суток для всех значений:
| WAL, сек | Compressed, сек | MEMORY, сек | CACHE, сек |
|---|---|---|---|
| 13 | 13 | 0.5 | 5 |
Чтение интервала за случайный промежуток времени
| WAL, зап/с | Compressed, зап/с | MEMORY, зап/с | CACHE, зап/с |
|---|---|---|---|
| 2.043.925 | 2.187.507 | 27.469.500 | 20.321.500 |
Как все собрать и попробовать.
Проект сразу задумывался как кроссплатформенный, разработка его идет на windows и ubuntu/linux. Поддерживаются компиляторы gcc-6 и msvc-14. Сборка через clang пока не поддерживается.
Зависимости
В Ubuntu 14.04 надо подключить ppa ubuntu-toolchain-r-test:
$ sudo add-apt-repository -y ppa:ubuntu-toolchain-r/test
$ sudo apt-get update
$ sudo apt-get install -y libboost-dev libboost-coroutine-dev libboost-context-dev libboost-filesystem-dev libboost-test-dev libboost-program-options-dev libasio-dev libboost-log-dev libboost-regex-dev libboost-date-time-dev cmake g++-6 gcc-6 cpp-6
$ export CC="gcc-6"
$ export CXX="g++-6"Пример использование в качестве встраиваемого проекта (https://github.com/lysevi/dariadb-example)
$ git clone https://github.com/lysevi/dariadb-example
$ cd dariadb-example
$ git submodule update --init --recursive
$ cmake .Сборка проекта у разработчика
$ git clone https://github.com/lysevi/dariadb.git
$ cd dariadb
$ git submodules init
$ git submodules update
$ cmake .Запуск тестов
$ ctest --verbose .Пример
Создание хранилища и наполнение значениями
#include <iostream>
#include <libdariadb/dariadb.h>
#include <libdariadb/utils/fs.h>
int main(int, char **) {
const std::string storage_path = "exampledb";
// удалим старое хранилище, если оно есть
if (dariadb::utils::fs::path_exists(storage_path)) {
dariadb::utils::fs::rm(storage_path);
}
// инициализируем настройки. ничего менять не будем
auto settings = dariadb::storage::Settings::create(storage_path);
settings->save();
//создадим два временных ряда. p1 и p2 содержат идентификаторы временных
//новых рядов
auto scheme = dariadb::scheme::Scheme::create(settings);
auto p1 = scheme->addParam("group.param1");
auto p2 = scheme->addParam("group.subgroup.param2");
scheme->save();
//создаем сам движок.
auto storage = std::make_unique<dariadb::Engine>(settings);
auto m = dariadb::Meas();
auto start_time = dariadb::timeutil::current_time(); //текущее время в милисекундах
// пишем значения в оба временных ряда по очереди за интервал
// [currentTime:currentTime+10]
m.time = start_time;
for (size_t i = 0; i < 10; ++i) {
if (i % 2) {
m.id = p1;
} else {
m.id = p2;
}
m.time++;
m.value++;
m.flag = 100 + i % 2;
auto status = storage->append(m);
if (status.writed != 1) {
std::cerr << "Error: " << status.error_message << std::endl;
}
}
}Открытие хранилища и чтение интервала.
#include <libdariadb/dariadb.h>
#include <iostream>
// функции для вывода измерения на экран
void print_measurement(dariadb::Meas&measurement){
std::cout << " id: " << measurement.id
<< " timepoint: " << dariadb::timeutil::to_string(measurement.time)
<< " value:" << measurement.value << std::endl;
}
void print_measurement(dariadb::Meas&measurement, dariadb::scheme::DescriptionMap&dmap) {
std::cout << " param: " << dmap[measurement.id]
<< " timepoint: " << dariadb::timeutil::to_string(measurement.time)
<< " value:" << measurement.value << std::endl;
}
class QuietLogger : public dariadb::utils::ILogger {
public:
void message(dariadb::utils::LOG_MESSAGE_KIND kind, const std::string &msg) override {}
};
class Callback : public dariadb::IReadCallback {
public:
Callback() {}
void apply(const dariadb::Meas &measurement) override {
std::cout << " id: " << measurement.id
<< " timepoint: " << dariadb::timeutil::to_string(measurement.time)
<< " value:" << measurement.value << std::endl;
}
void is_end() override {
std::cout << "calback end." << std::endl;
dariadb::IReadCallback::is_end();
}
};
int main(int, char **) {
const std::string storage_path = "exampledb";
// заменяем стандартный логер. это нужно, чтобы не захламлять
// вывод консоли
dariadb::utils::ILogger_ptr log_ptr{new QuietLogger()};
dariadb::utils::LogManager::start(log_ptr);
auto storage = dariadb::open_storage(storage_path);
auto scheme = dariadb::scheme::Scheme::create(storage->settings());
// получаем идентификаторы временных рядов.
auto all_params = scheme->ls();
dariadb::IdArray all_id;
all_id.reserve(all_params.size());
all_id.push_back(all_params.idByParam("group.param1"));
all_id.push_back(all_params.idByParam("group.subgroup.param2"));
dariadb::Time start_time = dariadb::MIN_TIME;
dariadb::Time cur_time = dariadb::timeutil::current_time();
// запрашиваем интервал
dariadb::QueryInterval qi(all_id, dariadb::Flag(), start_time, cur_time);
dariadb::MeasList readed_values = storage->readInterval(qi);
std::cout << "Readed: " << readed_values.size() << std::endl;
for (auto measurement : readed_values) {
print_measurement(measurement, all_params);
}
// применяем колбек к значениям в интервале
std::cout << "Callback in interval: " << std::endl;
std::unique_ptr<Callback> callback_ptr{new Callback()};
storage->foreach (qi, callback_ptr.get());
callback_ptr->wait();
{ // статистика
auto stat = storage->stat(dariadb::Id(0), start_time, cur_time);
std::cout << "count: " << stat.count << std::endl;
std::cout << "time: [" << dariadb::timeutil::to_string(stat.minTime) << " "
<< dariadb::timeutil::to_string(stat.maxTime) << "]" << std::endl;
std::cout << "val: [" << stat.minValue << " " << stat.maxValue << "]" << std::endl;
std::cout << "sum: " << stat.sum << std::endl;
}
}Чтение среза данных
Тут открытие хранилища и получения идентификаторов ничем не отличается от предыдущего примера, поэтому приведу только пример получения среза
dariadb::Time cur_time = dariadb::timeutil::current_time();
// запрашиваем срез;
dariadb::QueryTimePoint qp(all_id, dariadb::Flag(), cur_time);
dariadb::Id2Meas timepoint = storage->readTimePoint(qp);
std::cout << "Timepoint: " << std::endl;
for (auto kv : timepoint) {
auto measurement = kv.second;
print_measurement(measurement, all_params);
}
// последние значения
dariadb::Id2Meas cur_values = storage->currentValue(all_id, dariadb::Flag());
std::cout << "Current: " << std::endl;
for (auto kv : timepoint) {
auto measurement = kv.second;
print_measurement(measurement, all_params);
}
// применяем функцию к каждому значению в срезе.
std::cout << "Callback in timepoint: " << std::endl;
std::unique_ptr<Callback> callback_ptr{new Callback()};
storage->foreach (qp, callback_ptr.get());
callback_ptr->wait();