
Публикуя свою игру в Play-Market, я локализовал её только на два языка: английский и русский. Обзорные статьи по игре размещал тоже, соответственно, только на русскоязычных и англоязычных форумах. Статистика первого месяца позволила определить перечень стран, в которых игру начали активно качать. Поэтому было решено для закрепления успеха добавить локализацию еще на ряд языков. Среди прочих интерес к игре проявила и Индия.
За помощью по локализации игры на хинди я обратился к своему старинному индийскому другу, доктору Рудре Нараяну Пандею, который любезно согласился мне в этом помочь. Я предоставил Рудре таблицу игровых фраз, он быстро перевел всё на Хинди, а я, без всякой задней мысли, так же быстро скопипастил перевод в JSON-файл локализации. И, довольный, отправил Рудре билд на проверку. О, как же наивен был я тогда!
Рудра только снисходительно улыбнулся моей наивности и сказал, что текст содержит огромное количество неточностей, которых не было в его переводе. По описанию Рудры, текст в игре выглядел, как будто бы по аналогии в русском языке вместо «Ё» стояло бы «ЙО», а вместо «Ц» – «ТС». А для меня, совершенно не посвященного в тонкости хинди, всё выглядело одинаковым: что перевод в документе MS Word, что текст в игре. Но, внимательно пройдясь по рисунку текста, я действительно заметил разницу: как будто в некоторых местах буквы были переставлены местами, а кое-где выглядели по-разному. Ни мой друг, ни я не были посвящены в тайны шрифтов, и о причинах такого поведения текста могли только догадываться.
Поиск решения
После некоторого блуждания по бескрайним просторам Интернета причину удалось выяснить. Проблема оказалась в том, что Unity не поддерживает работу с таблицами GSUB и GPOS шрифтов. Первая, GSUB (Glyph Substitution Table), отвечает за замену последовательности символов на одну лигатуру, а вторая, GPOS (Glyph Positioning Table), – за корректировку взаимного расположения символов.
Если для русского текста в качестве примера работы GSUB я сходу вспомню только замену в MS Word трех точек подряд на один символ троеточие, то текст на хинди чуть ли не наполовину состоит из лигатур.
Например, вот так выглядит самоназвание языка:

В этом слове 2 лигатуры:
 и
и 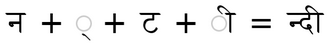
А вот так это слово отображается в Unity:

Unity просто рисует знаки по порядку их следования в слове, не изменяя согласно правил GSUB.
Итак, причину мы выяснили, а вот однозначного решения вопроса не было. В основном, на форумах все признавали факт, что проблема есть и с ней надо что-то делать. Нам удалось найти несколько полезных идей по данной теме.
Идея первая
Взята тут. Перед отображением текста программно менять местами знак огласовки
 (и) и предшествующую ему букву.
(и) и предшествующую ему букву.Да, это решение делает текст в Unity более похожим на хинди. Но оно затрагивает только малую часть правил GSUB, к тому же, не позволяет корректировать ширину «шапочки» знака в зависимости от ширины «накрываемой» буквы. Можно было бы написать такие замены для всех правил GSUB, но есть еще одна беда: Unity не импортирует символы шрифта, если они не имеют Unicode-номера. Стандартным шрифтом хинди в Windows является Mangal – в нём все лигатуры не имеют Unicode-номеров, поэтому Unity их «не видит». Следовательно, используя Mangal, программно сделать все замены не получится.
До перестановки:

После перестановки:

Должно быть:

Идея вторая
Из этого обсуждения, начиная с комментария #20. Для перевода текста на хинди использовать текстовый редактор, написанный на Unity, и шрифт, который включает в себя все возможные лигатуры, но с Unicode-номерами.
Ребята уже создали такой редактор – его можно скачать и опробовать. Но, к сожалению, он оказался очень неудобным в работе. Нижняя часть экрана редактора содержит огромную виртуальную клавиатуру со всеми лигатурами из этого шрифта, на которой переводчик должен вручную находить нужные символы и вставлять их в текст мышкой, что крайне неудобно и долго, ведь их там больше тысячи!
Идея третья
Из того же обсуждения, комментарий #38. Использовать шрифт Chanakya и конвертор текста для этого шрифта.
Данный шрифт содержит хинди-алфавит, а также небольшое количество (несколько десятков) наиболее часто используемых лигатур, которые имеют Unicode-номера, и, следовательно, могут быть импортированы и отображены в Unity. Web-конвертор производит преобразование Unicode-текста в кодировку шрифта Chanakya с одновременной заменой последовательностей символов, образующих лигатуры, на символы из шрифта с изображениями этих лигатур.
Опробовав этот метод, я убедился в его работоспособности.
Процесс локализации данным способом выглядит так:
1) Делаем перевод на хинди в любом удобном Unicode-редакторе, например, MS Word.
2) Конвертируем Unicode-текст из документа MS Word в кодировку шрифта Chanakya при помощи web-конвертора.
3) Полученную последовательность символов сохраняем в файле локализации.
4) В Unity эту последовательность отображаем шрифтом Chanakya, в результате чего визуально получаем красивый и правильный хинди.
Но не всё так просто, как хотелось бы. В этом методе оказалось большое количество подводных камней, с которыми пришлось разбираться.
Во-первых, огромный недостаток данного метода – это то, что шрифт Chanakya не содержит стандартных латинских символов, не говоря уже о кириллице. Из-за этого невозможно совместное отображение в одном текстовом поле текста на хинди и текста на каком либо другом языке.
Во-вторых, шрифт не содержит всех стандартных знаков пунктуации, а те, что содержит, стоят не под своими Unicode-номерами. Если в исходном тексте есть какие-либо знаки пунктуации, то они будут заменены конвертором на нежелаемые хинди-символы. Поэтому, для правильного результата нужно перед конвертированием удалить в исходном тексте все знаки пунктуации, а в результат добавить те Unicode-символы, на местах которых в Chanakya стоят требуемые знаки пунктуации.
Например, в исходном тексте имеются кавычки. Перед конвертацией мы их удаляем, а в результирующий текст на места открывающей и закрывающей кавычек добавляем символы Ò и Ó, соответственно, т.к. вместо этих символов в Chanakya стоят кавычки (только одинарные).
В-третьих, так как шрифт Chanakya содержит ограниченное количество лигатур, то возможны некоторые неконвертируемые последовательности – это видно по тому, что на странице конвертора в поле результата текст содержит латинские символы вместо хинди-символов. В этом случае следует попросить переводчика подобрать синонимы к тем словам, которые несконвертировались.
Иллюстрация процесса локализации:
Перевод на хинди:

Перевод, подготовленный для конвертирования – убраны знаки пунктуации:

Конвертированный текст в Unicode-виде:
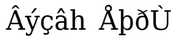
Конвертированный текст с добавленными кавычками и точкой:
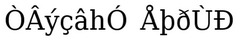
Конвертированный текст, отображаемый в Unity с помощью шрифта Chanakya:

Вот так, через танцы с бубном я и локализовал игру. У меня в игре язык переключается «на лету», поэтому я написал враппер на текстовое поле, который по событию переключения на хинди меняет Unicode-шрифт на Chanakya и обратно, соответственно, при переключении на другой язык. Также, враппер увеличивает размер шрифта текстового поля, потому что символы Chanakya маленькие.
При подготовке скриншотов для Play-Market и добавлении к ним подписей оказалось, что Photoshop, как и Unity, тоже не умеет работать с таблицами GPOS и GSUB. Этот метод помог и тут. Для этого потребовалось установить шрифт Chanakya в систему, конвертировать текст подписей web-конвертором, а в Photoshop отобразить полученный текст шрифтом Chanakya.
Мой друг Рудра остался очень доволен результатом. Он с гордостью рассказал в Facebook о нашей совместной работе, вспомнив давно забытый лозунг «Хинди руси бхай бхай». Наградой нам стал плавный, но уверенный рост количества скачиваний и большое количество пятерок с комментариями по поводу локализации.
Однако мой внутренний перфекционист не был удовлетворен. Вышеперечисленные недостатки не позволяли мне признать этот метод удобным для дальнейшего использования в своих играх, тем более, рекомендовать его широкой аудитории Unity разработчиков.
Универсальный метод локализации Unity-игры на хинди.
Тогда-то и родилась еще одна идея, а именно: из идеи номер два взять шрифт Siddhanta, содержащий полный набор лигатур с Unicode-номерами, и написать на C# конвертор текста, эмулирующий действие GSUB и GPOS.
Главной преградой в реализации этой идеи стало то, что у меня не было полного списка последовательностей символов, отображаемых в виде лигатур. На просторах Интернета мне не удалось найти такого списка. Пришлось самостоятельно изучать вопрос и собирать информацию из разрозненных источников. В итоге я, если и не начал читать на хинди, то, как говорится в классике, как минимум стал видеть «блондинок, брюнеток, рыженьких»…
Также я написал автору шрифта Siddhanta – Михаилу Боярину, который разрешил использовать свой шрифт и проконсультировал меня по некоторым вопросам. Выражаю Михаилу благодарность за помощь. А объем работы, проделанный Михаилом при создании такого всеобъемлющего шрифта, поражает и вызывает уважение!
Результатом моих изысканий стал скрипт HindiCorrector, содержащий таблицу соответствий последовательностей символов лигатурам, и шрифт Siddhanta Unity.
Скачать проект можно тут: HindiCorrector.
Формат записей таблицы GSUB из скрипта HindiCorrector следующий:
{ source = "\u091F\u094D\u091F", dest = "\uF5A2\uF61F" }
Символы в полях source – это в основном простые буквы, знак халант и знаки огласовки, которые переводчик вводит с клавиатуры в текстовом редакторе. Символы в полях dest – это конечные лигатуры, которые, в отличие от шрифта Mangal, в шрифте Siddhanta имеют Unicode-номера, поэтому могут быть импортированы и отображены в Unity.
Метод скрипта Correct заменяет в исходном тексте все вхождения source на dest.
Помимо замены последовательностей символов на лигатуры скрипт также решает задачу корректировки ширины «шапочек» знаков огласовки
(и) и  (ии). В шрифте Siddhanta есть линейки этих символов с «шапочками» разной ширины. Скрипт выбирает символ с нужной шириной в зависимости от буквы, стоящей перед этим символом.
(ии). В шрифте Siddhanta есть линейки этих символов с «шапочками» разной ширины. Скрипт выбирает символ с нужной шириной в зависимости от буквы, стоящей перед этим символом.
Аналогичным образом модифицируются остальные знаки огласовки, если буквы оказываются сильно широкими, и знаки огласовки не совпадают с вертикальной чертой букв.
Данный метод локализации не требует каких-то ручных модификаций исходного текста на хинди. Всё делает скрипт.
Если требуется «обучить» хинди другой шрифт, используемый в игре, достаточно скопировать диапазоны символов 0900-097F и F000-F633 из шрифта Siddhanta Unity в нужный шрифт.
Шрифт Siddhanta Unity отличается от исходного шрифта Михаила Боярина тем, что из второго удалены все лигатуры, не участвующие в таблице GSUB скрипта HindiCorrector. Это позволило значительно снизить размер конечного шрифта, что крайне принципиально для мобильной разработки. Также добавлен диапазон символов F000-F01B, в который помещены некоторые существующие символы с откорректированными позициями.
Моя таблица GSUB не претендует на полноту, но она однозначно больше, чем реализовано в шрифте Chanakya из третьей идеи. Если потребуется добавить новую лигатуру, которой нет в моей таблице GSUB, то нужно выполнить следующие действия:
1) найти в исходном шрифте Siddhanta нужную лигатуру и cкопировать её под своим Unicode-номером в шрифт Siddhanta Unity;
2) добавить в таблицу GSUB скрипта HindiCorrector запись о замене последовательности символов на эту лигатуру.
Есть еще один важный момент: Unity не умеет стандартным способом распознавать установленный на телефоне язык хинди – метод Application.systemLanguage возвращает значение Unknown, что делает все усилия по локализации наполовину бессмысленными, т.к. далеко не все игроки посмотрят в настройках варианты выбора языка. На помощь пришло решение, описанное тут – запрашивать системный язык напрямую из JAVA-окружения.
В заключение благодарю своего друга доктора Рудру Нараяна Пандея за плодотворную совместную работу, интересное общение и новые знания. «Хинди руси бхай бхай»!
