Comments 67
Замеры производились с помощью System.Diagnostics.Stopwatch, который точнее DateTime, потому что реализован поверх PerformanceCounter.
Why not BenchmarkDotNet?
Более того, итератор гораздо более семантически «чист», чем индекс массива.
Запутаться может только неосилятор, но никак не компилятор.
Чем меньше вариантов и чем лучше вы конкретизируете что вы хотите выразить в коде, тем больше шансов на оптимизацию. «Запутаться» тут просто фигура речи. Давайте рассмотрим классический пример:
*dst++ = *src++; // Copy buffer
Даже в таком простейшем случае компилятор не сможет заменить код на оптимизированный std::memcpy, если не будет уверен что эти указатели не перекрываются. В случае с индексами и массивами у вас больше шансов:
dst[n++] = src[m++]; // Copy buffer
Чего уж говорить про более сложные случаи.
int * restrict dst = ...;
int * restrict src = ...;
*dst = *src;
++dst;
++src;
Кстати, про memcpy. У меня были реальные ситуации, когда копирование в цикле было несколько эффективнее memcpy. Я сильно не вдавался, скорее всего из-за того, что memcpy работает на уровне байт, а в цикле копировалось по 4-8 байт и профит был за счёт меньшего числа итераций. Экономия на инкрементах xD.
И ещё раз про memcpy. Вы точно не перепутали его с memmove? memcpy это просто цикл, на инлайн ассемблере (по крайней мере так было в MSVC лет пять назад), там нет требований по непересекаемости областей памяти.
скорее всего из-за того, что memcpy работает на уровне байтЭто не так. Можете сами убедиться. MSVC копирует самими широкими словами, которые есть в его распоряжении.
вы точно не перепутали его с memmoveТочно. У memmove вообще не бывает проблем с перекрытием, она для этого и предназначена.
Значит, они уже улучшили функцию, разбив цикл копирования на две части: копирование DWORD'ами (QWORD'ами) и добивание оставшегося числа байт по одному. Именно такой алгоритм у меня работал быстрее стандартного memcpy в 2005 студии, или примерно в те года.
Приведи пример, где итератор (указатель) дает худшую оптимизацию, чем индекс
Более того, итератор гораздо более семантически «чист», чем индекс массива.Речь об этом твоем утверждении
Более того, итератор гораздо более семантически «чист», чем индекс массива.Я это не утвеждал или вы непонятно объясняете о чем речь.
С точки зрения производительности, я уверен что современный компилятор построит абсолютно идентичный код и для указателей и для индексов (это в случае если код нельзя выбросить и его нужно выполнять в лоб, а нужно исполнить механически). А вот если у вас мало мальски сложный код, да еще и на шаблонах, то указатели могут помешать выкинуть неиспользуемый код или оптимизировать его для конкретного частного случая. Для демонстрации рабочего примера нужно проделать много работы, что бы вычленить минимально рабочий пример, а это не тот случай, или искать в интернете, так что ограничимся простейшим:
uint8_t buf[100];
void IndexFill()
{
for (uint_t n = 0; n < 100; n++)
buf[n] = 255;
}
void PointerFill()
{
uint8_t* bufp = buf;
for (uint_t n = 0; n < 100; n++)
*bufp++ = 255;
}
int main(int argc, char_t* argv[])
{
IndexFill();
PointerFill();
return 0;
}
VS2013 в первом случае выбрасывает вызов IndexFill() так как результат нигде не используется, а во втором случае PointerFill() честно заполняет массив, так как указатель сбивает ее с толку.
Поясню. Итератор (== указатель) по определению обозначает последовательный обход контейнера. При помощи индекса обход может быть хоть последовательный, хоть случайный, хоть какой. Т.е. если используется итератор, код сам говорит о том, что требуется пройти по всем элементам контейнера. Я не беру в расчёт говнокод, когда обращение по индексу заменяют на *(ptr+10), это уже на совести программиста пусть остаётся. Так же итераторы позволяют легко заменить тип контейнера, если это потребуется, практически не изменяя кода.
Теперь, если компилятор «тупой» (80-е годы) и процессор «тупой» (какой-нибудь DSP простенький), то никто не спорит, что указатели будут быстрее. Я сам начинал писать с PDP-11 ассемблера и очень хорошо представляю что там под капотом. Но время идет и прогресс не стоит на месте. Современные компиляторы в состоянии понять что доступ к индексам последовательный и заменять все умножения на последовательные сложения. Процессоры теперь также имеют множество блоком ALU и могут выполнять сразу много сложений и умножений за один такт, регистры становятся все шире и шире.
Сейчас предпочтительней писать более понятный код, как можно яснее выражать семантику операции и свои намерения. Не нужно заниматься ручной оптимизацией. В случае микрооптимизаций (в пределах одной функции), указатели все еще могут дать выигрыш, но в глобальной оптимизации они только мешают (если мы передаем указатели на данные и объекты из функции в функция или из одного модуля в другой), особенно в ситуации с шаблонами С++, где оптимизатор порой, просто творит чудеса.
> уже полезли итераторы, которые являются указателями только семантически.
Ну, вот, вы подтвердили моё утверждение про семантическую «чистоту» указателей.) Для итерации по массиву указатель(он же итератор) более семантически «чист» чем индекс.
Просто написать два варианта и измерить скорость — не имеет смыслаСогласен, не имеет. Просто я, примерно, видя код уже могу сказать что выигрыша не будет просто исходя из опыта. Часто приходится иметь дело с оптимизацией и все эти штуки MSVC уже знаешь.
Ну, вот, вы подтвердили моё утверждение про семантическую «чистоту» указателейЯ и не спорю. Я правда не уверен что вы имеете ввиду под «чистотой». Если более сильную абстракцию, как и я, то это хорошо только для архитектуры, но в тоже время плохо для оптимизации, где чем более специфический и конкретный будет оператор тем лучше.
int* end = data + length;
while ( data != end )
sum += *data++;
Результат не изменился почти никак, как и отметил Videoman
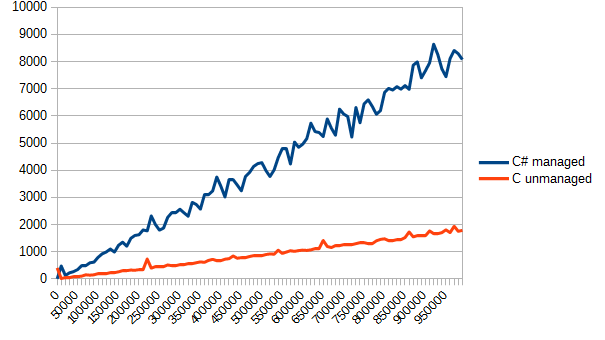
Как-то так. Но идея была интересная.
Ну и на втором графике видим бОльшую стабильность, график более гладкий. Тоже плюс, наверное.)
Есть очень много особенностей и ограничений целевых компиляторов, а также отсутствие вменяемой оптимизации в случае с Сишкой на форточках. В llvm этот вопрос решён хоть как-то, но по уровню оптимизации сишка уступает тому же rust'у. По этому от фронтенда до фронтенда один и тот же биткод (они решили отличиться) будет оптимизирован по разному.
На практике большая часть существующих оптимизаций:
• разворачивание циклов для последующего использования SIMD операций
• комбинирование макро команд для выполнение за один такт процессора (mov, test, cmp etc).
• контроль заполнения очереди комманд
• принудительная подчистка кэша
• контроль глубины ветвлений
• минимизация количества операций со стэком
• использование регистровой памяти для передачи аргументов функций
не применяются вообще, особенно в форточках, либо применяются довольно криво...
У ABI cишки слишком много консервативных и устаревших ограничений для сохранения портабельности, которые нынче не то что не нужны, а просто ставят крест на вертикальном масштабировании большинства решений.
В примерах со статьи — имеет смысл использовать SSE2/SSE4 и AVX2 операции.
Даже банальные strstr / strcmp имеют ассемблерные SIMD аналоги выполняющиеся ровно за один такт, а если правильно чистить кэш и предовращать ITLB/DTLB miss, то и по 4 штуки за такт (по 64/128 байт).
Приложения со статьи получат на выходе приблизительно одинаковый листинг ассемблерных инструкций без каких либо вменяемых оптимизаций, по этому сравнивать их не совсем корректно и целесообразно. Особенно что касается скорости системных вызовов I/O — это просто не самая удачная метрика.
Также есть специализированное File mapping API — аналог mmap Posix вызова.
У ABI cишки слишком много консервативных и устаревших ограничений для сохранения портабельности, которые нынче не то что не нужны, а просто ставят крест на вертикальном масштабировании большинства решений.
Можете привести пример какие такие сишные ABI?
а также отсутствие вменяемой оптимизации в случае с Сишкой на форточках
Вменяемой оптимизации по сравнению с чем?
но по уровню оптимизации сишка уступает тому же rust'у.
ну там же сам автор признал, что первая попытка была неверная и написал специально второй пост в котором ему также указали, что для получения схожего эффекта есть ключевое слово restrict.
По этому от фронтенда до фронтенда один и тот же биткод (они решили отличиться) будет оптимизирован по разному.
Да что уж там, один и тот же байткод будет отличатся от компилятора к компилятору ну и что?
какие такие сишные ABI?
Например вот это нечто пожирающее стэк без острой необходимости.
оптимизации по сравнению с чем?
С официальным гайдом по оптимизации.
ну там же сам автор признал
Действительно плохой пример. Просто на практике сталкивался с подобными вещами довольно часто, чаще чем хотелось бы.
Да что уж там, один и тот же байткод будет отличатся от компилятора к компилятору ну и что?
Есть micro и macro fusion операции внутри самого блока трансляции процессора… различие в результирующем коде означает что везде они будут применяться по разному, и зависеть от солнечной радиации и положения звёзд на небе… как и производительность результирующего кода.
Например вот это нечто пожирающее стэк без острой необходимости.
И какое отношение это имеет к "сишичке"? Изначальное утверждение было о том, что сишные ABI консервативны устаревши и ставят крест на вертикальной масштабируемости, вот я и спрашиваю какие такие сишные ABI?
С официальным гайдом по оптимизации.
Не совсем понял, какой-то компилятор генерирует код под форточки, который противоречит этому ману? Или тут упор на то, что ручная оптимизация качественней чем автоматическая?
Кстати современные (условно, примерно лет 15 последних) оптимизирующие компиляторы делают порой чудные оптимизации до которых так просто и не додумаешся. Не говоря о том, что код на "сишичке" нужно грамотно расхинтовать для началу,
И какое отношение это имеет к "сишичке"?
Прямое, это и есть сишное ABI, — унифицированная конвенция вызова сишных функций в форточках на x64 системах.
Какой-то компилятор генерирует код под форточки, который противоречит этому ману?
Не один существующий компилятор не генерирует код который ему следует.
… до которых так просто и не додумаешся
Не используется многопроходный GA.
Оно не сможет эффективно использовать большую часть существующих SIMD инструкций и менять последовательности команд в различных оптимизационных целях… приходится самому всегда колупаться в intrinsics'ах. Даже полигидральные плюшки не решают этот вопрос.
Прямое, это и есть сишное ABI, — унифицированная конвенция вызова сишных функций в форточках на x64 системах.
Т.е. сишное это то, которое может использоваться в си? Сами по себе ни Си ни С++ не определяют никаких ABI. Ну и каким образом это соглашение о вызове ставит крест на вертикальной масштабируемости?
Оно не сможет эффективно использовать большую часть существующих SIMD инструкций и менять последовательности команд в различных оптимизационных целях
Так оно же мысли читать не умеет, компилятору без хинта не понятно нужно считывать все время значение по адресу или программист задумал, что значение меняться не будет и можно закешировать значение в регистре.
Оно не сможет эффективно использовать большую часть существующих SIMD инструкций и менять последовательности команд в различных оптимизационных целях…
Ну допустим пока не сможет, хотя верится слабо, зачем тогда нужен программист? )
Пример что вы привели правильно говорит что некоторые случаи в расте для оптимизитора лучше, но это не значит что на си нельзя оптимизировать чтобы было так же.
Такую же функцию, чтобы получилась 1 асм инструкция легко сделать и на си, более того многие inrinsic функции так и сделаны в системных инклудах, и принимать они могут на вход и выход любые регистры, несмотря на ABI.
Дело вот в чем, в расте просто все функции fn foo() по дефолту скрытые и не имеют привязки к ABI. Как только вы делаете функцию публичной pub extern «C» fn foo() и доступной извне, она приобретает ABI. В си же не имеют привязки статические функции, инлайновые и при использовании whole programm optimization(или и использованием профайловой оптимизации), которые не экспортируются (соответственно ABI им не нужен). Соответственно точно так же можно промаркировать интерфейсные функции торчащие наружу, а остальные скрыть и они будут оптимизироваться как угодно. Так что с ABI пример плохой.
rust использует llvm… и к форточкам это не имеет никакого отношения.
Любая C/С++ функция под форточками будет использовать существующее ABI — там нет понятия "whole program optimization" так как подобные оптимизации могут быть выполнены только во время линковки, и они не реализованы в существующих линковщиках.
Про эти оптимизации во время линковки я в курсе…
Не знаю, не смотрел что на выходе получается, но вряд ли они будут ломать существующее глючное ABI.
Это радует.
Правда на форточках пока мною замечено не было.
То про что вы говорите это:
If the compiler can identify all of the call sites of a function, the compiler ignores explicit calling-convention modifiers on a function and tries to optimize the function's calling convention:
И это только один из пунктов. Собственно rust использует абсолютно те же механизмы llvm что и си.
WPO/PGO не означает что MSVC откажется от существующих x64 ABI и начнёт их ломать в угоду утилизации регистровой памяти. К сожалению WPO/PGO не приводят к ожидаемому вами эффекту на х64'ой платформе, а на x86 просто подбирается наиболее эффективная конвенция вызовов, но существующее ABI сохраняется.
С MSDN'a:
When /LTCG is used to link modules… following optimizations are performed:
• Cross-module inlining
• Interprocedural register allocation (64-bit operating systems only)
• Custom calling convention (x86 only)
• Small TLS displacement (x86 only)
• Stack double alignment (x86 only)
• Improved memory disambiguation
Register Allocation вставляет хинты на подобие USES в MASM'е для резервирования регистровой памяти.
Мне кажется, основной выигрыш в производительности достигается за счёт инлайнинга, а не оптимизации соглашения о вызовах. А для x64 нет смысла менять конвенцию — параметры и так передаются через регистры.
Есть очень много особенностей и ограничений целевых компиляторов, а также отсутствие вменяемой оптимизации в случае с Сишкой на форточках.
Как это нету? А Intel Compiler?
У ICC в целом есть пару особенностей — он обычно мелочёвку оптимизирует на много лучше GCC/LLVM (20-30% компактнее и шустрее), но любые сложные вещи любит раздувать до непонятных размеров (почти в 3 раза). По этому у него свои, особенные глюки с оптимизациями… Для научных вычислений и прочего он подходит лучше чем GCC/LLVM, но любые пользовательские приложения он будет раздувать до совсем несуразных размеров.
В llvm этот вопрос решён хоть как-то, но по уровню оптимизации сишка уступает тому же rust'у.
По приведенной ссылке:
Update Actually as dbaupp points out, this optimization example is not specific to Rust. In fact, LLVM is doing it via local > analysis (the sort I mentioned above), and clang++ produces the same results for the equivalent C++ code. In fact Rust > in general would need to preserve references because you can convert a reference to a raw pointer and compare them > for equality.
Ну и stackalloc до кучи.
Так же в CoreFX появилось много других плюшек для более эффективной работы с памятью.
Ну и это все в unsafe сделать. Страшного тут ничего нет ;)
Пример кода со всякими интересными штуками можно глянуть тут.
Ну и не использовать уже 4.5.2. Хотя бы 4.6.2, а лучше 4.7, если вам именно .Net нужен. Про BenchmarkDotNet вам уже сказали ;)
А ещё можно попробовать .Net Native или пре-компиляцию библиотек в C#.
Вот еще заинтересованным почитать Safe Systems Programming in C# and .NET.
В c# есть оптимизация при работе с массивами, если в качестве верхней границы цикла использовать не переменную length, а именно array.Length, то он выкинет проверку выхода за границы массива. Это же справедливо и для конструкции foreach.
Можете сделать соответсвующие замеры?
Спасибо, уважаемый! Очень интересная статья и полезная тема, комменты тут — просто клад для новичка)
Разве что время загрузки учитывается
.NET Managed + C unmanaged: какова цена?