
Думаю, мы недостаточно говорим о будущем API. Я не помню ни одного хорошего обсуждения о том, что ждёт API в будущем. Вот совсем не припоминаю. Но если мы хорошенько подумаем об этом, то придём к выводу, что API в том виде, в каком мы понимаем сейчас — это далеко не конец игры. В этом виде API не будет оставаться вечно. Давайте попробуем заглянуть в будущее и ответить на вопрос, что случится с API в будущем.
Турок
Наша история начинается в 1770 году в Венгерском Королевстве, входящего в то время в Габсбургскую Империю. Вольфганг фон Кампелен разрабатывает машину, способную играть в шахматы. Идея была в том, чтобы играть с сильнейшими игроками того времени.
Закончив работу над машиной, он впечатляет ею двор Марии Терезы Австрийской. Кампелен и его шахматный автоматон быстро становятся популярны, выигрывая у шахматистов в демонстрационных играх по всей Европе. Среди очевидцев присутствуют даже такие деятели, как Наполеон Бонапарт и Бенджамин Франклин.
Машина, выглядевшая как человек, одетый в турецкие робы, была на самом деле механической иллюзией. Ею управлял сидевший внутри живой человек. Турок был просто тщательно разработанным трюком. Мифом, придуманным для того, чтобы заставить людей думать, что соревнуются с настоящей машиной. Секрет был полностью раскрыт только в 1850-м году.

С тех пор, термин "механический турок" (Mechanical Turk) используется для систем, которые выглядят как полностью автономные, но на самом деле нуждаются в человеке, чтобы функционировать.
Чужие
Переносимся в 1963 год, где американский психолог и учёный Джозеф Ликлайдер пишет "Меморандум для Членов и Союзников Галактической Компьютерной Сети".
Ликлайдер является одной из самых важных фигур в истории компьютеров. Его смело можно назвать провидцем. Он предвидел появление графических интерфейсов и был причастен к созданию ARPANET и интернета.
В меморандуме Ликлайдер задаётся вопросом:
"Как вы начнёте общение между двумя никак не связанными друг с другом мудрыми существами?"
Представьте, что есть гигантская сеть, связывающая множество галактик и соединяющая разумных существ, которые никогда не встречались ранее. Вопрос следующий: Как они будут общаться, когда они встретятся?
Аналогично картине, показанной в фильме "Прибытие" (2016), эти существа должны будут исследовать друг друга, наблюдать и записывать реакции, чтобы сначала найти общий лексикон. И только потом они смогут использовать этот лексикон, чтобы иметь осмысленный диалог.
Конец эпохи Турка
Переносимся на 33 года вперёд, в 1996 год. Компьютер IBM Deep Blue выигрывает первую игру в шахматном турнире с чемпионом мира Гарри Каспаровым. В конце турнира, Каспаров побеждает в матче из шести игр, проиграв лишь первую игру.
IBM улучшает Deep Blue. Год спустя компьютер выигрывает матч-реванш 3½–2½, становясь тем самым первой машиной, победившей действующего чемпиона мира.
Между оригинальным Турком фона Кампелена и настоящей машиной, способной победить лучших шахматистов планеты прошло 227 лет.
Второе пришествие Турков
Всего лишь через 3 года после Deep Blue, в 2000 году, Рой Филдинг публикует свою диссертацию "Архитектурные стили и дизайн программных архитектур сетевой среды". Эта работа позже станет известна как архитектурный стиль REST API. Она стала шаблоном для появления целого поколения Web API, использующих HTTP протокол.
В том же году Salesforce выпускает первую версию своих Web API для автоматизации продаж. eBay присоединяется чуть позже, и все остальные известные интернет-компании следуют тренду.

Но есть что-то странное в этих Web API. Они вроде как являются протоколами общения компьютера с компьютером. Но в реальности это оказывается не так.
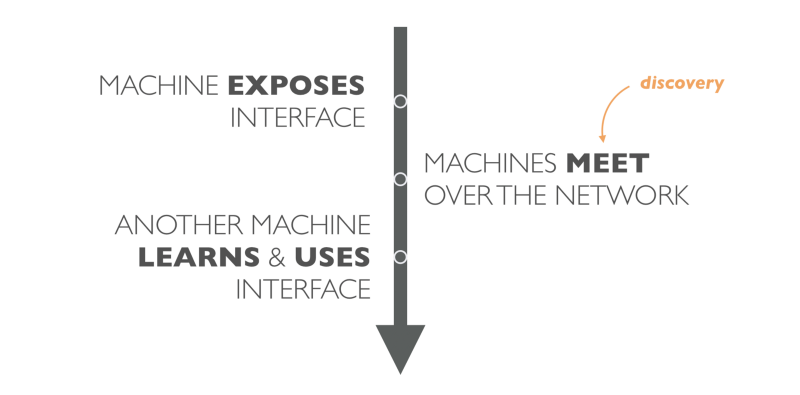
В реальности, один сервис публикует интерфейс; затем человек пишет к нему документацию и публикует её.
Другой человек должен найти эту документацию и прочесть её. Получив эти знания, человек может запрограммировать другую машину на использование этого интерфейса.

По сути, у нас есть промежуточный слой в общении компьютера с компьютером, который включает нас, людей. В итоге то что подразумевается всеми как чистая коммуникация компьютера с компьютером, по факту оказывается новым Механическим Турком.
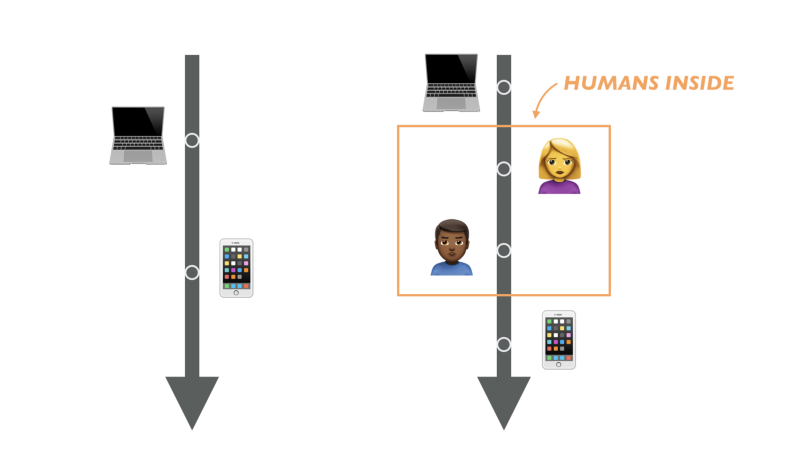
Золотая эра Турков
Как и в случае с Всемирной Сетью, компании по всему миру вскоре поняли важность присутствия в этом сегменте интернета. Бизнес рычаги запустили процесс, и мы с вами являемся свидетелями настоящего бума Web API.

Но по мере экспоненциального распространения API и растущей вокруг них экономики, появляются новые проблемы. И, в большинстве случаев, эти проблемы напрямую связаны с человеком, спрятанным внутри API турка.
Проблема с API турком
Каждое зрелое API должно считаться со следующими задачами:
- синхронизация
- версионирование
- масштабирование
- обнаружение
Синхронизация
В случае API турка мы создаем и рассылаем "словарь Ликлайдера" наперёд. Тоесть мы пишем и публикуем документацию к API до того, как две машины встретятся. И даже если забыть о том, что люди могут просто неправильно понять документацию, мы имеем очевидную проблему в случае когда API меняется, а документация — нет.
Поддерживать документацию к API в синхронизации с реализацией — это непростая задача. Но поддерживать изменения в клиентах — ещё сложнее.

Версионирование
Проблемы с синхронизацией ведут нас к прямиком к вопросу версионирования. Поскольку большинство API турок не следуют принципам REST описанными Филдингом, API клиенты, как правило, сильно связаны с используемыми интерфейсами. Такая сильная связность создаёт очень хрупкие системы. Изменение в API может запросто сломать клиент. Более того, необходимо вмешательство человека, чтобы обновить существующий клиент под новое изменение в API. Но зависимость от человека для такого действия — дорого, медленно, и, в большинстве случаев, недоступно, поскольку клиент уже установлен.

Из-за этих проблем мы боимся делать изменения. Мы не развиваем наши API. Вместо этого, мы создаем новые API поверх существующих, загрязняя кодовую базу. Мы увеличиваем стоимость, технический долг и имеем бесконечные дискуссии о том, как решить проблемы версионирования.
Масштабирование
Поскольку внутри API турок сидят люди, нам приходится нанимать больше людей, чтобы создавать больше API турок. И чтобы делать больше ошибок. Мы же люди — мы делаем ошибки.
Неважно сколько людей мы нанимаем — если речь идёт о чтении или написании документации или исправления кода под новые изменения в API — мы ограничены в скорости. Увеличение количества людей ещё как-то может помочь создавать больше API, но совершенно не помогает масштабировать скорость реагирования на изменения.
Более того, зачастую мы работаем с размытыми формулировками, что создает массу пространства для ошибок и неверных трактований. Там где один человек ожидает название статьи, другой увидит заголовок.
А что, это разве не одно и то же?
Обнаружение
И наконец, есть ещё проблема с обнаружимостью. Как мы узнаём о том, что есть какой-то сервис, который мы захотим использовать? Возможно уже есть сервис, который даст нам возможность построить прорывной продукт или просто сэкономит нам ценное время.
Провайдеры API не знают, где предложить себя. Не имеет значения, что этот сервис для геолокации лучше чем Google Places API — у нас просто нет способа об этом даже узнать.
Сарафанное радио и Google это так себе решение для обнаружения API. И, как и с любым другим решеним, управляемым человеком, это решение не масштабируется.
Возможный выход
В последнее десятилетие, мы разрабатывали процессы и инструменты для решения этих проблем. Вместе с массой народа, мы создали целую индустрию API. Экономику, которая создаёт и поддерживает новых Механических Турков.
API Workflow, API Style Guide, лучшие практики документации API и другие процессы запущены, чтобы поддерживать синхронизацию, предотвращать несовместимые изменения и избегать человеческих ошибок. Мы создаём ещё больше инструментов, чтобы подпирать эти процессы и поддерживать наши API продукты.
Мы стали генерировать документацию и код автоматически, чтобы добиться синхронизации. Мы разрабатываем сложные фреймворки для тестирования и нанимаем больше разработчиков, чтобы поддерживать всё это. Сейчас вполне обыденное дело иметь в штате целую команду разработчиков только для API документации. Давайте я скажу это иначе: Мы нанимаем разработчиков, чтобы создавать документацию для других разработчиков, чтобы они могли понять интерфейс одного компьютера и запрограммировать другой компьютер его использовать.
Как говорит один мой друг:
Программисты решают проблемы программирования ещё больше программируя.
Если API становится популярным, эти провайдеры становятся достаточно везучими, чтобы получить деньги и тратить их на маркетинг и различные PR-мероприятия. Остальные ищут удачи в каталогах API или в надежде быть замеченными на Hacker News.
Роль человека в общении между компьютерами
Так зачем же вообще нужен человек в API турке? Какая роль человека в общении между компьютерами?
Люди играют критически важную роль в обнаружении API и понимании. Когда мы находим какой-либо сервис, первым делом мы пытаемся понять ЧТО именно мы можем делать с его помощью и КАК это делать.

К примеру:
(Обнаружение API и ЧТО): "Есть ли сервис, который даст мне прогноз погоды для Парижа?"
(КАК): "Как я могу использовать этот сервис, чтобы получить прогноз погоды для Парижа?"
Когда мы получаем ответы на эти вопросы, мы можем написать API клиент. Клиент далее сможет работать без нашего участия, до тех пор, пока API (или наши требования) не изменятся. И, конечно, мы подразумеваем, что API документация всегда точна и в синхронизации с реализацией API.
Автономные API
Но если человеческое участие в процессе дорого, медленно и подвержено ошибкам, как мы можем уйти от этого? Чего будет стоить создать полностью автономные API?
Во-первых, мы должны найти способ разрабатывать и публиковать общий словарь. Следующим шагом будет начать распространять понимание смысла на лету. Тогда система обнаружения API сможет регистрировать новые API вместе с его словарем смысла.
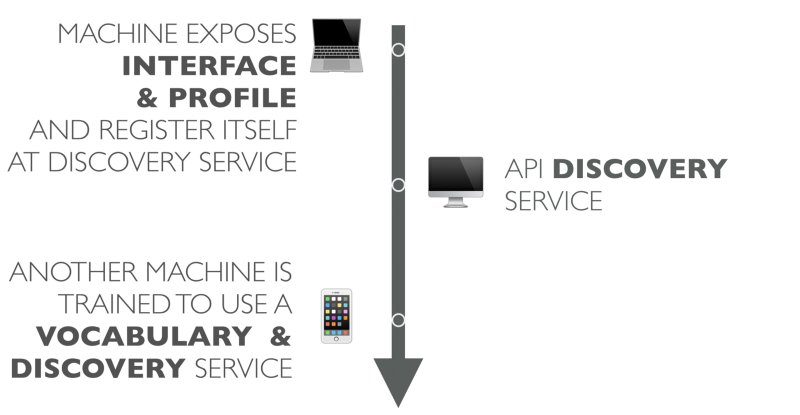
Процесс работы такой автоматизированной системы без участия человека может выглядеть примерно так:
Компьютер публикует свой интерфейс вместе с профилем, описывающим интерфейс и его смысловой словарь. Сервис регистрирует себя в системе обнаружения API.
Позже, другая программа опрашивает сервис обнаружения API, используя термины из словаря. Если что-то находится, сервис обнаружения API возвращает найденный сервис этой программе.
Программа (которая теперь API клиент) уже обучена работать с новым словарём. Теперь она может использовать API для необходимых ей действий.
Клиент запрограммирован декларативным образом для выполнения конкретной задачи, но не привязан жестко к определённому сервису.
Для наглядности, вот пример программы, которая отображает температуру в Париже:
# Using a terms from schema.org dictionary,
# find services that offers WeatherForecast.
services = apiRegistry.find(WeatherForecast, { vocabulary: "http://schema.org"})
# Query a service for WeatherForecast at GeoCoordinates.
forecast = service.retrieve(WeatherForecast, { GeoCoordinates: … })
# Display Temperature
print forecast(Temperature)Такой подход не только позволяет создавать клиенты, устойчивые к изменениям API, но и позволяет переиспользовать код для множества других API.
Например, больше не нужно будет создавать программу прогноза погоды для конкретного сервиса. Напротив, вы пишете универсальный клиент, который знает, как отображать прогноз погоды. Это приложение может использовать различные сервисы, такие как AccuWeather, Weather Underground или любой другой специфичный для страны сервис прогноза погоды, если он поддерживает (хотя бы частично) тот же самый словарь смыслов.
Резюмируя, строительными блоками Автономных API являются:
- регистр словарей
- понимание смысла на лету
- сервис обнаружения API
- программирование под словарь, а не под структуры данных
Прибытие
Итак, где же мы находимся со всем этим в начале 2017 года? Хорошая новость в том, что у нас есть эти строительные блоки, и они понемногу начинают привлекать внимание.
Мы начинаем учиться понимать смысл на лету. HATEOAS используют форматы гипермедия для этого. Использование формата JSON-LD набирает обороты в API индустрии, а поисковые провайдеры вроде Google, Microsoft, Yahoo и Yandex поддерживают словарь Schema.org.
Форматы вроде ALPS дают новую жизнь семантической информации для данных. В тоже время GraphQL Schema может быть изучена на лету, чтобы узнать, что доступно с помощью GraphQL API.
И, напоследок, появляются специальные API каталоги, с HitchHQ и Rapid API во главе.
Заключение
В моей версии будущего API мы избавимся от человеческого участия в документировании, обнаружении и использовании API. Мы начнем писать наши API клиенты в декларативной форме и информация будет узнаваться на лету.
Такой подход наградит нас меньшими затратами, меньшим количеством ошибок и меньшим временем выхода на рынок. С автономными API мы наконец-то сможем развивать API, переиспользовать клиенты и масштабировать API бесконечно.
