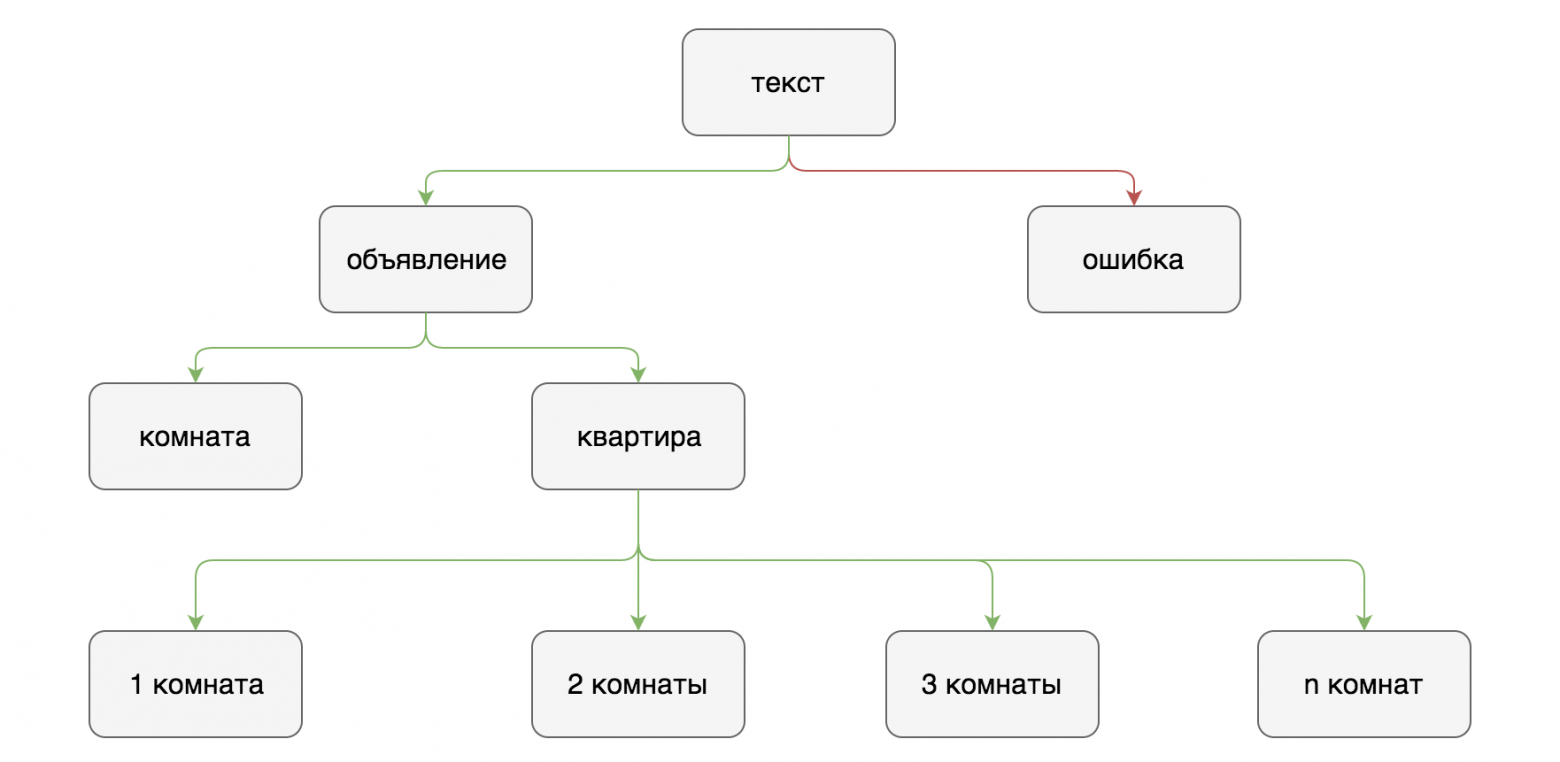
Расскажу, как классификация текста помогла мне в поиске квартиры, а также почему я отказался от регулярных выражений и нейронных сетей и стал использовать лексический анализатор.
Примерно год назад мне необходимо было найти квартиру для съема. Больше всего объявлений от частных лиц публикуется в социальных сетях, где объявление пишется в свободной форме и для поиска нет никаких фильтров. Вручную просматривать публикации в разных сообществах долго и неэффективно.
На тот момент уже существовало несколько сервисов, которые собирали объявления из социальных сетей и опубликовывали их на сайте. Таким образом, можно было увидеть все объявления в одном месте. К сожалению, там также отсутствовали фильтры по типу объявлений, цене. Поэтому спустя какое-то время я захотел создать свой сервис с необходимым мне функционалом.
Классификация текстов
Первая попытка (RegExp)
Сначала я подумал решить задачу в лоб с помощью регулярных выражений.
Помимо написания самих регулярных выражений, пришлось также сделать последующую обработку результатов. Необходимо было учитывать количество вхождений и их взаимное расположение относительно друг друга. Проблема была и с обработкой текста по предложениям: невозможно было отделить одно предложение от другого и текст обрабатывался весь сразу.
По мере усложнения регулярных выражений и обработки результата становилось все тяжелее повышать процент правильных ответов на тестовой выборке.
Регулярные выражения, которые использовались в тестах
- '/(комнат|\d.{0,10}комнат[^н])/u'
- '/(квартир\D{4})/u'
- '/(((^|\D)1\D{0,30}(к\.|кк|кв)|одноком|однуш)|(квартир\D{0,3}1(\D).{0,10}комнатн))/u'
- '/(((^|\D)2\D{0,30}(к\.|кк|кв)|двух.{0,5}к|двуш|двух.{5,10}(к\.|кк|кв))|(квартир\D{0,3}2(\D).{0,10}комнатн))/u'
- '/(((^|\D)3\D{0,30}(к\.|кк|кв)|тр(е|ё)х.{0,5}к|тр(е|ё)ш|тр(е|ё)х.{5,10}(к\.|кк|кв))|(квартир\D{0,3}3(\D).{0,10}комнатн))/u'
- '/(((^|\D)4\D{0,30}(к\.|кк|кв)|четыр\Sх)|(квартир\D{0,3}4(\D).{0,10}комнатн))/u'
- '/(студи)/u'
- '/(ищ.{1,5}сосед)/u'
- '/(сда|засел|подсел|свобо(ж|д))/u'
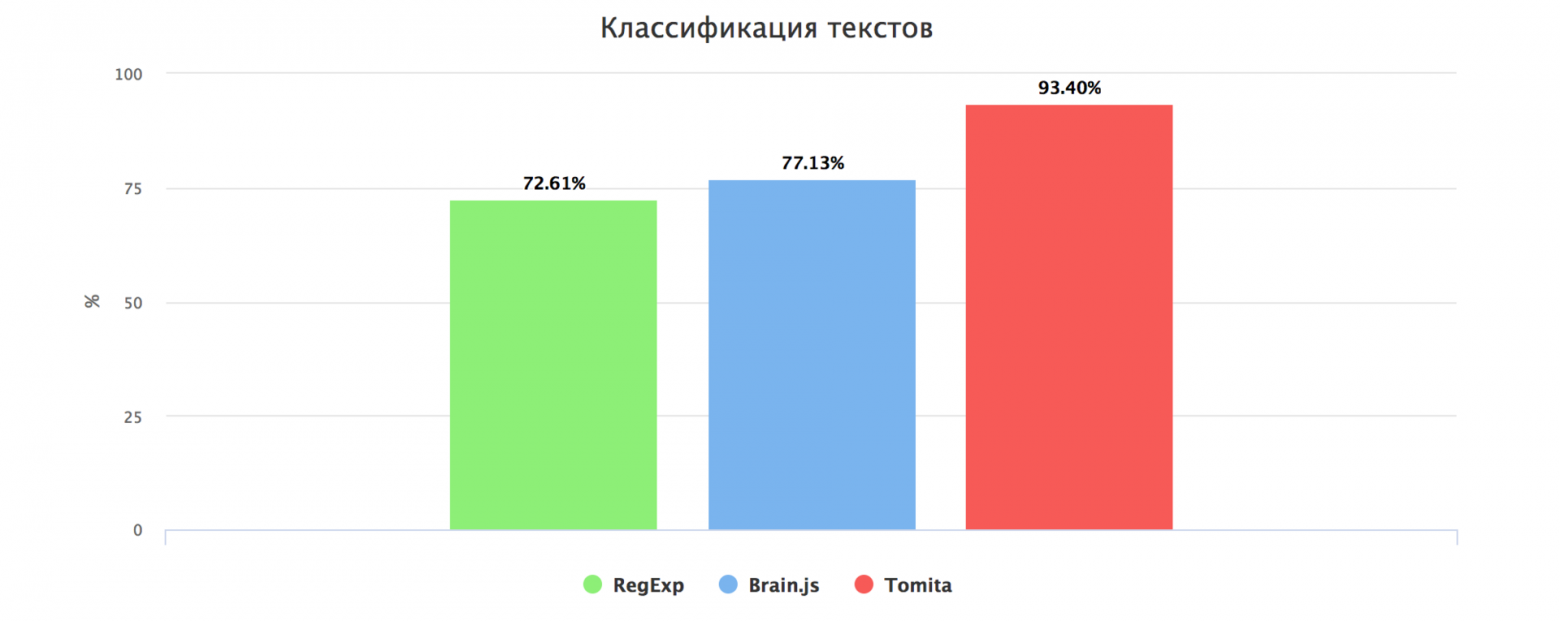
- '/(\?)$/u'Такой метод для тестового набора дал 72.61% правильных ответов.
Вторая попытка (Нейронные сети)
В последнее время стало очень модно использовать машинное обучение для всего что угодно. После обучения сети сложно или даже невозможно сказать, почему она решила именно так, но это не мешает успешно применять нейронные сети в классификации текстов. Для тестов использовался многослойный перцептрон с методом обучения обратного распространения ошибки.
В качестве готовых библиотек нейронных сетей использовались:
FANN написана на C
Brain написана на JavsScript
Необходимо было преобразовать текст разной длины так, чтобы его можно было подать на вход нейронной сети c постоянным количеством входов.
Для этого из всех текстов тестовой выборки были выявлены n-граммы из более чем 2х символов и повторяющиеся в более чем 15% текстов. Таких оказалось чуть больше 200.
Пример n-грамм
- /ные/u
- /уютн/u
- /доб/u
- /кон/u
- /пол/u
- /але/u
- /двух/u
- /так/u
- /даю/uДля классификации одного объявления в тексте искались n-граммы, выяснялось их расположение, и затем эти данные подавались на вход нейронной сети так, чтобы значения были в переделах от 0 до 1.
Такой метод для тестового набора дал 77.13% правильных ответов (при том, что тесты выполнялись на той же выборке, на которой производилось обучение).
Я уверен, что при большем на несколько порядков тестовом наборе и использовании сетей с обратной связью можно было бы добиться намного лучших результатов.
Третья попытка (Синтаксический анализатор)
В то же время я стал больше читать статей про обработку естественного языка и наткнулся на прекрасный парсер Tomita от Yandex. Основное его преимущество перед другими подобными программами состоит в том, что он работает с русским языком и имеет довольно внятную документацию. В конфигурации можно использовать регулярные выражения, что очень кстати, поскольку часть из них у меня уже была написана.
По сути своей, это намного более продвинутая версия варианта с регулярными выражениями, но намного более мощная и удобная. Здесь также не обошлось без предварительной обработки текста. Текст, который пишут пользователи в социальных сетях, часто не отвечаeт грамматическим и синтаксическим нормам языка, поэтому у парсера возникают трудности при его обработке: разбиении текста на предложения, разбиении предложений на лексемы, приведении слов к нормальной форме.
Пример конфигурации
#encoding "utf8"
#GRAMMAR_ROOT ROOT
Rent -> Word<kwset=[rent, populate]>;
Flat -> Word<kwset=[flat]> interp (+FactRent.Type="квартира");
AnyWordFlat -> AnyWord<kwset=~[rent, populate, studio, flat, room, neighbor, search, number, numeric]>;
ROOT -> Rent AnyWordFlat* Flat { weight=1 };Все конфигурации можно посмотреть тут. Такой метод для тестового набора дал 93.40% правильных ответов. Помимо классификации текста из него также выделяются факты, такие как: стоимость аренды, площадь квартиры, станция метро, телефон.
В итоге, при небольшом тестовом наборе и необходимости высокой точности получилось выгодней писать алгоритмы вручную.
Разработка сервиса
Параллельно с решением задачи классификации текста было написано несколько сервисов для сбора объявлений и представления их в удобном для пользователя виде.
github.com/mrsuh/rent-view
Сервис, который отвечает за отображение.
Написан на NodeJS. Использовались шаблонизатор doT.js и БД Mongo.
github.com/mrsuh/rent-collector
Сервис, который отвечает за сбор объявлений. Написан на PHP. Используются фреймворк Symfony3 и БД Mongo.
Писался с расчетом собирать данные из разных источников, но, как оказалось, почти все объявления размещаются в социальной сети Вконтакте. У данной соцсети есть отличный API, поэтому не составило труда собирать объявления из стен и обсуждений в публичных группах.
github.com/mrsuh/rent-parser
Сервис, который отвечает за классификацию объявлений. Написан на Golang. Использует парсер Tomita. В сущности, представляет из себя обертку над парсером, но также осуществляет предварительную обработку текста и последующую обработку результатов парсинга.
Для всех сервисов настроен CI с помощью Travis-CI и Ansible (как настроен автоматический деплой, писал в этой статье).
Статистика
Сервис работает уже примерно два месяца для города Санкт-Петербург и за это время успел собрать чуть больше 8000 объявлений. Вот немного интересной статистики по объявлениям за весь период.
В день в среднем добавляют 131.2 объявлений (точнее текстов, которые были классифицированы как объявления).

Самый активный час 12 дня.

Самая популярная станция метро Девяткино

Вывод: если у вас нет большой тестовой выборки, на которой вы могли бы натренировать сеть, и при этом вам необходима высокая точность, то лучше всего использовать алгоритмы, написанные вручную.
Если кто-то захочет сам решить подобную задачу, то вот здесь лежит тестовый набор из 8000 текстов и их типов.
