Всем привет! Хочу поделиться своим переводом интересной статьи Reducing our Redux code with React Apollo автора Peggy Rayzis. Статья о том, как автор и её команда внедряли технологию GraphQL в их проект. Перевод публикуется с разрешения автора.
Переключаемся на декларативный подход в Высшей Футбольной Лиге
Я твёрдо убеждена, что лучший код — это отсутствие кода. Чем больше кода, тем больше вероятности для появления багов и тем больше тратится времени на поддержку такого кода. В Высшей Футбольной Лиге у нас совсем небольшая команда, поэтому мы принимаем этот принцип близко к сердцу. Мы стараемся оптимизировать всё, что нам по силам, либо путём увеличения переиспользуемости кода, либо просто перестав обслуживать определённую часть кода.
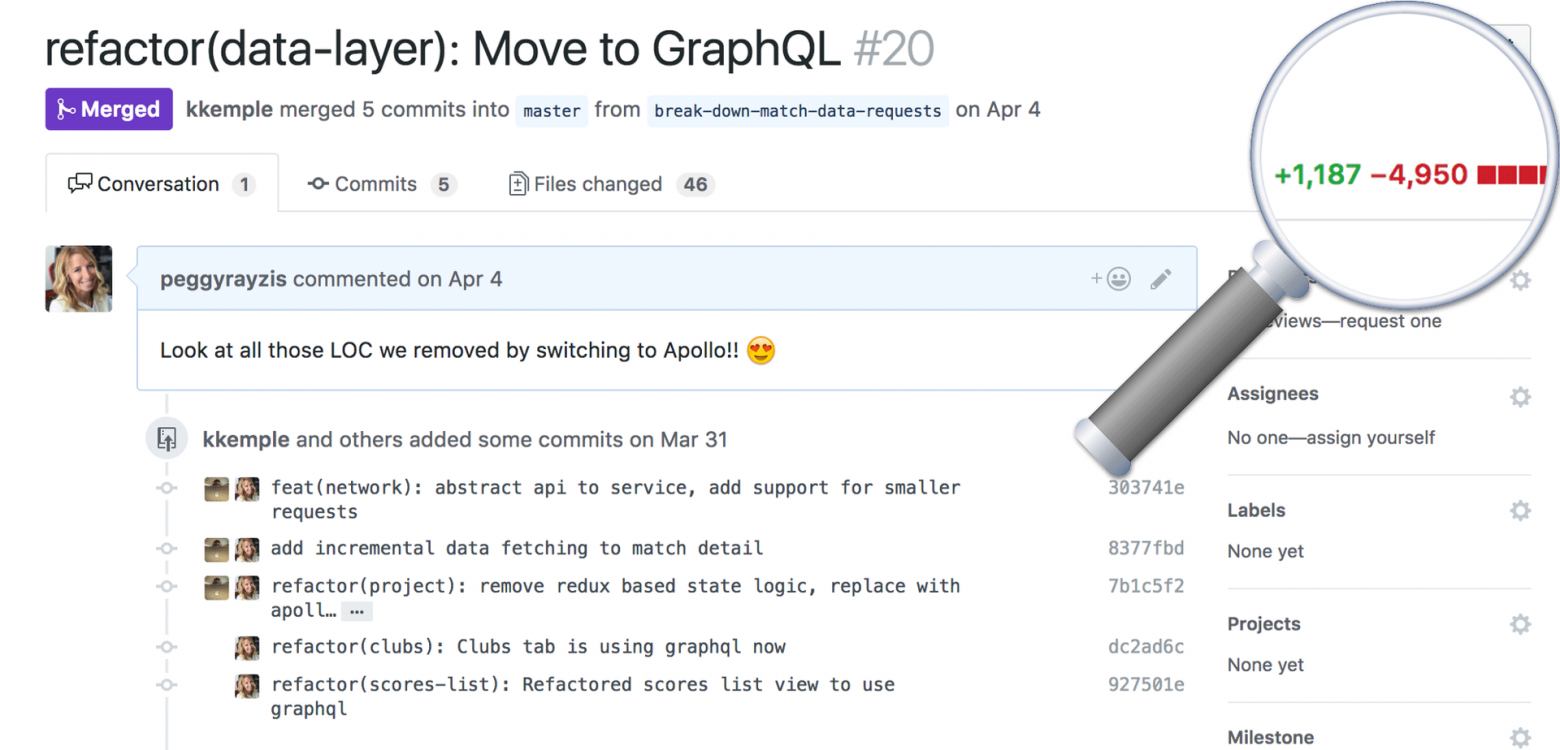
В данной статье вы узнаете о том, как мы передали контроль над получением данных в Apollo, что позволило нам избавиться от почти 5,000 строчек кода. К тому же, после перехода на Apollo наше приложение стало не только намного меньше по объёму, оно также стало более декларативным, поскольку теперь наши компоненты запрашивают только те данные, которые им нужны.
Что я подразумеваю под декларативным и почему это так здорово? Декларативное программирование фокусируется на конечной цели, в то время как императивное программирование сосредоточено на шагах, которые требуются для её достижения. React же сам по себе декларативный.
Получение данных с помощью Redux
Давайте взглянем на простой компонент Article:
Предположим, мы хотим отрендерить <Article/> в подключённом <MatchDetail/> представлении, который получает ID матча в качестве props. Если бы мы выполняли это без GraphQL клиента, наш процесс получения данных, необходимых для рендеринга <Article/> мог бы быть таким:
- Когда
<MatchDetail/>монтируется, вызываем action creator для получения данных матча по ID. Action creator диспатчит action, чтобы сообщить Redux о начале процесса получения данных. - Мы достигли точки назначения и возвращаемся с данными назад. Мы нормализуем данные в удобную нам структуру.
- После того, как данные нормализованы, мы диспатчим ещё один action, чтобы сообщить Redux о завершении процесса получения данных.
- Redux обрабатывает action в нашем reducer и обновляет state приложения.
<MatchDetail/>получает все необходимые данные матча через props и отфильтровывает их для рендеринга статьи.
Так много шагов, чтобы просто получить данные для <Article/>! Без клиента GraphQL наш код становится намного более императивным, поскольку нам приходится концентрироваться на том, как мы получаем данные. Но что, если мы не хотим передавать все данные матча для простого рендеринга <Article/>? Вы могли бы построить другой endpoint и создать отдельный набор action creators для получения от него данных, но такой вариант очень легко может стать неподдерживаемым.
Давайте сравним, как бы мы могли сделать то же самое с помощью GraphQL:
<MatchDetail/>подключён к компоненту высшего порядка, который выполняет следующий запрос:
query Article($id: Float!) {
match(id: $id) {
article {
title
body
}
}
}… и это всё! Как только клиент получает данные, он передаёт их в props, которые могут быть далее переданы в <Article/>. Это намного более декларативно, поскольку мы фокусируемся только на том, какие данные нам нужны для рендеринга компонента.
В этом вся прелесть делегирования получения данных GraphQL клиенту, будь то Relay или Apollo. Когда вы начнёте "думать в концепциях GraphQL", вы станете заботиться только о том, в каких props нуждается компонент для рендеринга, вместо того, чтобы беспокоиться о том, как получить эти данные.
В какой то момент вам придётся подумать об этом "как", но это уже забота серверной части, и, соответственно, сложность для front-end резко снижается. Если вы новичок в серверной архитектуре GraphQL, то попробуйте И хотя этот пост о том, как сократить использование вашего Redux кода, вы не избавитесь от него полностью! Apollo использует Redux под капотом, поэтому вы всё ещё сможете извлекать выгоду из иммутабельности и все клёвые возможности Redux Dev Tools, типа time-travel debugging, так же будут работать. Во время конфигурирования вы можете подключить Apollo к существующему store в Redux, чтобы поддерживать единый "источник правды". Как только ваш store сконфигурирован, вы передаёте его в Прежде, чем мы начнём резать наш Redux код, я бы хотела назвать одну из лучших фукнциональных особенностей GraphQL: поэтапная настройка (incremental adoption). Вам не обязательно совершать рефакторинг всего приложения сразу. После интеграции Apollo с вашим существующим Redux store, вы можете переключаться с ваших reducers постепенно. То же самое применимо и к серверной части — если вы работаете над большим масштабным приложением, вы можете использовать GraphQL бок о бок с вашим текущим REST API, до того момента, пока вы не будете готовы для полного перехода. Справедливое предупреждение: как только вы попробуете GraphQL, вы можете влюбиться в эту технологию и захотить переделать всё ваше приложение. Перед переходом от Redux к Apollo, мы тщательно подумали о том, отвечает ли Apollo нашим потребностям. Вот на что мы обратили внимание перед тем, как принять решение: Надо сказать, что Apollo удовлетворял не только всем нашим текущим требованиям, он также охватывал и некоторые наши будущие потребности, особенно учитывая то, что в наш roadmap включена расширенная персонализация. И хотя наш сервер в настоящее время доступен "только для чтения", нам в будущем может потребоваться ввести мутации (mutations) для сохранения пользователями их любимых команд. На случай, если мы решим добавить комментирование в режиме реального времени или взаимодействия с фанатами, которые не могут быть решены с помощью поллинга (polling), то в Apollo есть поддержка подписок (subscriptions). Момент, которого все ждали! Изначально, когда я только задумалась о написании этой статьи, я собиралась лишь привести примеры кода до и после, но я думаю, что было бы трудно сравнивать вот так напрямую эти два подхода, особенно для новичков в Apollo. Вместо этого я собираюсь подсчитать количество удалённого кода в целом и провести вас через знакомые вам концепции Redux, которые вы сможете применить при создании контейнерных компонентов с помощью Apollo. Если вы умеете пользоваться Первый аргумент, переданный в Отлично, у нас есть запрос! Чтобы корректно его выполнить, нам нужно передать в него две переменные Этот объект имеет несколько свойств, которые вы может указать для настройки поведения компонента высшего порядка (HOC). Одно из самых важных свойств — это Наверняка вы использовали функцию Зачем вам переопределять ваши props? Результат запроса GraphQL всегда присваивается к свойству Теперь объект с данными содержит не только результат запроса, но также и свойства типа Compose это функция, использующаяся не только в Redux, но я всё же хочу обратить ваше внимание, что Apollo содержит её. Она очень удобна, если вы хотите скомпоновать несколько Все эти примеры демонстрируют, что если вы знаете Redux, то вы быстро вольётесь в разработку на Apollo! Его API вобрало в себя многое из концепций Redux, при этом уменьшая количество кода, которое вам нужно написать для достижения такого же результата. Я надеюсь, что опыт перехода Высшей Футбольной Лиги на Apollo поможет вам! Как и в случае с любыми решениями относительно различных библиотек, лучшее решение по контролю над получением данных в вашем приложении будет зависеть от конкретных требований вашего проекта. Если у вас есть какие-либо вопросы касательно нашего опыта, пожалуйста, оставляйте комментарии здесь или стучитесь ко мне в Twitter! Спасибо за прочтение!graphql-tools, библиотеку Apollo, которая поможет вам более модульно структурировать вашу схему. Для краткости мы сегодня остановимся только на front-end части.
<ApolloProvider/> компонент, который оборачивает всё ваше приложение. Звучит знакомо? Этот компонент является полной заменой вашего существующего <Provider/> из Redux, за исключением того, что вам потребуется передать ему экземпляр ApolloClient через свойство client.
Наши требования
fetchMore, которая проделывает за нас всю тяжёлую работу?
От Redux к Apollo
Что мы удалили
fetchPolicy из Apollo и использования redux-persist в reducer.
connect() → graphql()
connect, тогда компонент высшего порядка graphql из Apollo вам покажется очень знакомым! Точно так же, как connect возвращает функцию, которая принимает компонент и подключает его к вашему Redux store, также и graphql возвращает функцию, которая принимает компонент и "подключает" его к клиенту Apollo. Давайте посмотрим на это в действии!
graphql это MatchSummaryQuery. Это данные, которые мы хотим получить от сервера. Мы используем загрузчик Webpack для парсинга нашего запроса в GraphQL AST, но если вы не используете Webpack, то вам нужно обернуть ваш запрос в шаблонные строки (template string) и передать его в функцию gql, экспортированную из Apollo. Вот пример запроса на получение данных, необходимых для нашего компонента:
$id и $season. Но откуда мы возьмём эти переменные? Вот здесь то и вступает в игру второй аргумент функции graphql, представленный в виде объекта конфигурации.
options, принимающее функцию, которая получает props вашего контейнера. Эта функция возвращает объект со свойствами типа variables, что позволяет вам передавать ваши переменные в запрос, и pollInterval, который позволяет настраивать поведение поллинга (polling) у компонента. Обратите внимание, как мы используем props нашего контейнера для передачи id и season в наш MatchSummaryQuery. Если эта функция становится слишком длинной, чтобы писать её прямо в декораторе, то мы разбиваем её на отдельную функцию под названием mapPropsToOptions.
mapStateToProps() → mapResultsToProps()
mapStateToProps в ваших Redux контейнерах, передавая эту функцию в connect для передачи данных из state приложения в props данного контейнера. Apollo позволяет вам определять похожую функцию. Помните конфигурационный объект, который ранее мы передавали в функцию graphql? У этого объекта есть ещё одно свойство — props, которое принимает функцию, получающую на вход props и обрабатывающую их перед передачей в контейнер. Вы, конечно, можете определить её прямо в graphql, но нам нравится определять её как отдельную функцию mapResultsToProps.
data. Иногда вам может потребоваться подкорректировать эти данные перед тем, как отправить их в компонент. Вот один из примеров:
data.loading, чтобы дать вам знать, что запрос ещё не возвратил ответ. Это может быть полезным, если в подобной ситуации вы хотите отобразить другой компонент вашим пользователям, как мы сделали это с <NoDataSummary/>.
compose()
graphql функций для использования в одном контейнере. В ней вы даже можете использвать функцию connect из Redux вместе с graphql! Вот как мы используем compose для отображения различных состояний матча:
compose отлично помогает, когда ваш контейнер содержит множественные состояния. Но что, если вам нужно выполнять отдельный запрос только в зависимости от его состояния? Здесь нам поможет skip, который вы можете увидеть в конфигурационном объекте выше. Свойство skip принимает функцию, которая получает props и позволяет вам пропустить выполнение запроса, если он не соответствует необходимым критериям.
