
В проекте, над которым я сейчас работаю, применяется распределённая система обработки данных: сначала несколько десятков машин одновременно производят некоторые сообщения, затем эти сообщения отправляются в очередь, из очереди три потока извлекают сообщения и после финальной обработки выкладывают данные в базу Redis. При этом имеется требование: от «зарождения» события в машине, производящей сообщение, до выкладывания обработанных данных в базу должно проходить не более четырёх секунд в 90% случаев.
В какой-то момент стало очевидно, что мы это требование не выполняем, несмотря на затрачиваемые усилия. Несколько произведённых измерений и маленький экскурс в теорию очередей привели меня к выводам, которые я бы хотел донести до себя самого несколько месяцев назад, когда проект только начинался. Отправить письмо в прошлое я не могу, но могу написать заметку, которая, возможно, избавит от неприятностей тех, кто только задумывается над тем, чтобы применять очереди в собственной системе.
Я начал с того, что измерил время, которое сообщение проводит на разных стадиях обработки, и получил примерно такой результат (в секундах):

Таким образом, невзирая на то, что обработка сообщения занимает довольно мало времени, больше всего сообщение простаивает в очереди. Как такое может быть? И главное: как с этим бороться? Ведь если бы картинка выше была результатом профайлинга обычного кода, то всё было бы очевидно: надо оптимизировать «красную» процедуру. Но вся беда в том, что в нашем случае в «красной» зоне ничего не происходит, сообщение просто ждёт в очереди! Ясно, что оптимизировать надо обработку сообщения («жёлтую» часть диаграммы), но возникают вопросы: каким образом эта оптимизация может повлиять на длину очереди и где гарантии, что мы вообще сможем добиться желаемого результата?
Я помнил, что вероятностными оценками времени ожидания в очереди занимается теория очередей (подраздел исследования операций). В своё время в университете, впрочем, мы это не проходили, поэтому на некоторое время мне предстояло погрузиться в Википедию, PlanetMath и онлайн-лекции, откуда на меня как из рога изобилия посыпались сведения о нотации Кендалла, законе Литтла, формулах Эрланга, и т. д., и т. п.
Аналитические результаты теории очередей изобилуют довольно серьёзной математикой, основная часть этих результатов была получена в XX веке. Изучать всё это — занятие хотя и увлекательное, но довольно долгое и кропотливое. Не могу сказать, что я смог хоть сколько-нибудь глубоко туда погрузиться.
И тем не менее, пробежавшись всего лишь «по верхам» теории очередей, я обнаружил, что основные выводы, которые можно применить на практике в нашем случае, лежат на поверхности, требуют для своего обоснования только лишь здравый смысл и могут быть изображены на графике зависимости времени обработки в системе с очередью от пропускной способности сервера, вот он:

Здесь
 — пропускная способность сервера (в сообщениях за секунду)
— пропускная способность сервера (в сообщениях за секунду)  — средняя частота поступления запросов (в сообщениях за секунду)
— средняя частота поступления запросов (в сообщениях за секунду)- По оси ординат отложено среднее время обработки сообщения.
Точный аналитический вид этого графика является предметом изучения теории очередей, и для очередей M/M/1, M/D/1, M/D/c и т. д. (если не знаете, что это такое — см. нотация Кендалла) эта кривая описывается совершенно различными формулами. Тем не менее, какой бы моделью ни описывалась очередь, внешний вид и асимптотическое поведение этой функции будет одинаковым. Доказать это можно простыми рассуждениями, что мы и проделаем.
Во-первых, посмотрим на левую часть графика. Совершенно очевидно, что система не будет стабильной, если
(пропускная способность) меньше (частоты поступления): сообщения на обработку приходят с большей частотой, чем мы их можем обработать, очередь неограниченно растёт, а у нас возникают серьёзные неприятности. В общем, случай  — аварийный всегда.
— аварийный всегда.Тот факт, что в правой части график асимптотически стремится к
 , тоже довольно прост и для своего доказательства глубокого анализа не требует. Если сервер работает очень быстро, то мы практически не ждём в очереди, и общее время, которое мы проводим в системе, равно времени, которое сервер затрачивает на обработку сообщения, а это как раз .
, тоже довольно прост и для своего доказательства глубокого анализа не требует. Если сервер работает очень быстро, то мы практически не ждём в очереди, и общее время, которое мы проводим в системе, равно времени, которое сервер затрачивает на обработку сообщения, а это как раз . Не сразу очевидным может показаться лишь тот факт, что при приближении
к с правой стороны время ожидания в очереди растёт до бесконечности. В самом деле: если  , то это значит, что средняя скорость обработки сообщений равна средней скорости поступления сообщений, и интуитивно кажется, что при таком раскладе система должна справляться. Почему же график зависимости времени от производительности сервера в точке вылетает в бесконечность, а не ведёт себя как-нибудь так:
, то это значит, что средняя скорость обработки сообщений равна средней скорости поступления сообщений, и интуитивно кажется, что при таком раскладе система должна справляться. Почему же график зависимости времени от производительности сервера в точке вылетает в бесконечность, а не ведёт себя как-нибудь так:
Но и этот факт можно установить, не прибегая к серьёзному математическому анализу! Для этого достаточно понять, что сервер, обрабатывая сообщения, может находиться в двух состояниях: 1) он занят работой 2) он простаивает, потому что обработал все задачи, а новые в очередь ещё не поступили.
Задания в очередь приходят неравномерно, где «погуще, где пореже»: количество событий в единицу времени является случайной величиной, описываемой так называемым распределением Пуассона. Если задания в какой-то интервал времени шли редко и сервер простаивал, то время, в течение которого он простаивал, он не может «сберечь» для того, чтобы использовать его для обработки будущих сообщений.
Поэтому за счёт периодов простоя сервера средняя скорость выхода событий из системы будет всегда меньше пиковой пропускной способности сервера.
В свою очередь, если средняя скорость выхода меньше средней скорости входа, то это и приводит к бесконечному удлинению среднего времени ожидания в очереди. Для очередей с пуассоновским распределением событий на входе и постоянным либо экспоненциальным временем обработки величина ожидания около точки насыщения пропорциональна

Выводы
Итак, разглядывая наш график, мы приходим к следующим выводам.
- Время обработки сообщения в системе с очередью есть функция пропускной способности сервера и средней частоты поступления сообщений , и даже проще: это функция отношения этих величин
 .
. - Проектируя систему с очередью, нужно оценить среднюю частоту прибытия сообщений и заложить пропускную способность сервера
 .
. - Всякая система с очередью в зависимости от соотношения и может находиться в одном из трёх режимов:
- Аварийный режим —
 . Очередь и время обработки в системе неограниченно растут.
. Очередь и время обработки в системе неограниченно растут. - Режим, близкий к насыщению:
 , но ненамного. В этой ситуации небольшие изменения пропускной способности сервера очень сильно влияют на параметры производительности системы, как в ту, так и в другую сторону. Нужно оптимизировать сервер! При этом даже небольшая оптимизация может оказаться очень благотворной для всей системы. Оценки скоростей поступления сообщений и пропускной способности нашего сервиса показали, что наша система работала как раз около «точки насыщения».
, но ненамного. В этой ситуации небольшие изменения пропускной способности сервера очень сильно влияют на параметры производительности системы, как в ту, так и в другую сторону. Нужно оптимизировать сервер! При этом даже небольшая оптимизация может оказаться очень благотворной для всей системы. Оценки скоростей поступления сообщений и пропускной способности нашего сервиса показали, что наша система работала как раз около «точки насыщения». - Режим «почти без ожидания в очереди»: . Общее время нахождения в системе примерно равно времени, которое сервер тратит на обработку. Необходимость оптимизации сервера определяется уже внешними факторами, такими как вклад подсистемы с очередью в общее время обработки.
- Аварийный режим —
Разобравшись с этими вопросами, я приступил к оптимизации обработчика событий. Вот какой расклад получился в итоге:
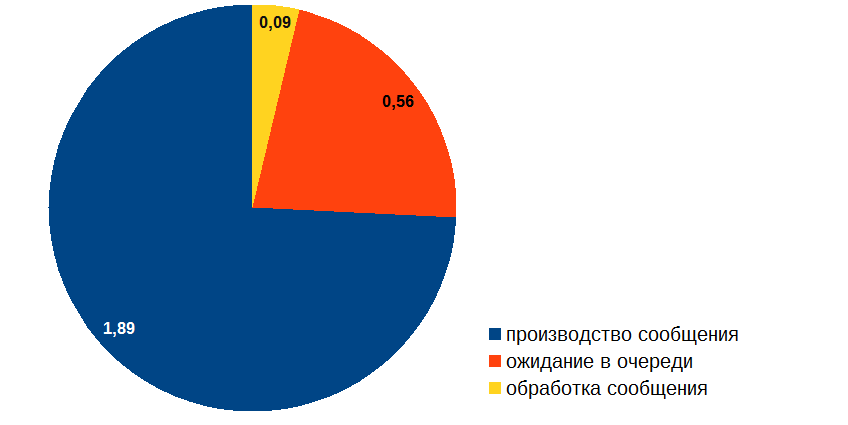
ОК, вот теперь можно и время производства сообщения подоптимизировать!
Также рекомендую прочесть: Принципы и приёмы обработки очередей.
