
На фото: Платформа SKARAB для цифровой обработки данных с телескопа MeerKAT. За счет технологии HMC каждая из 64 антенн телескопа может передать на платформу поток данных со скоростью 40 Гбит/с
В ожидании нового стандарта памяти DDR5 SDRAM, который появится уже в следующем году, мы исследуем альтернативные технологии. В этой статье изучим память HMC (Hybrid Memory Cube), которая обеспечивает 15-кратный рост производительности при 70% экономии на энергопотреблении на бит по сравнению с DDR3 DRAM.
В то время как DDR4 и DDR5 представляют собой эволюцию стандарта, HMC — это революционная технология, которая может изменить рынок не только в сфере специализированных высокопроизводительных вычислений, но также в области потребительской электроники, такой как планшеты и графические карты, где важен форм-фактор, энергоэффективность и пропускная способность.
Архитектура и устройство HMC
HMC – сокращение от Hybrid Memory Cube — гибридный куб памяти. Физически чип состоит из нескольких слоев, соединенных кремниевыми переходными по технологии TSV. Верхние слои представляют собой кристаллы DRAM-памяти, нижний слой – контроллер, управляющий передачей данных.
Внутренняя структура HMC чипа:
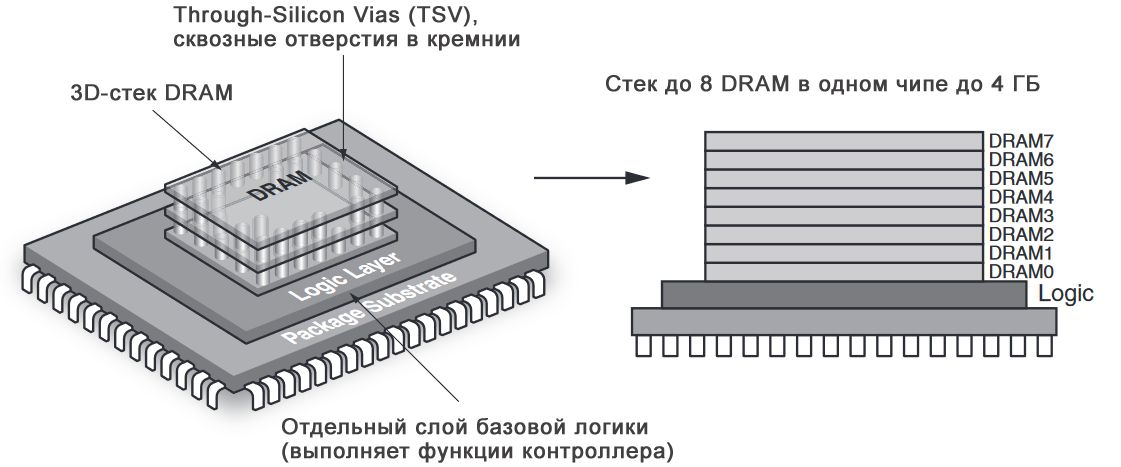
HMC применяется там, где необходимо быстродействие, а также малое количество чипов для необходимого объема памяти. Чипы HMC могут объединятся в последовательную цепочку — до 8 штук. Выпускаются чипы емкостью 2 и 4 ГБайта. Данные передаются по последовательным интерфейсам со скоростью 15 Гбит/с на линию; всего линий может быть от 32 до 64. Таким образом, теоретическая пропускная способность может достигать 240 Гбит/с, но она ограничена пропускной способностью DRAM-кристалла на уровне 160 Гбит/с.
Ниже приведена таблица с потреблением на бит данных:
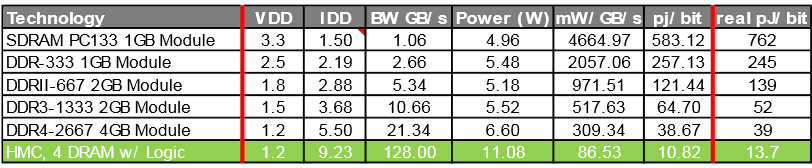
Сравнительная таблица HMC, DDR4 (первое поколение, конфигурация памяти 4+1)
Помимо HMC существует несколько похожих направлений у других компаний-разработчиков.
- Bandwidth Engine (BE) от MoSys – чип, призванный заменить QDR-память, работает подобно SRAM. Использует последовательные трансиверы на скорости до 16 Гбит/с. Назначение данного типа памяти – буфер с низкой задержкой чтения для хранения заголовков пакетов или look-up-таблиц вместо хранения пакетов целиком.
- Ternary Content Addressable Memory (TCAM) – cпециальная быстродействующая память, используется в роутерах и сетевых коммутаторах, имеет высокую цену. Высокая производительность достигнута за счет большого энергопотребления. Передача данных осуществляется параллельно.
- High Bandwidth Memory (HBM) – тип памяти, разработанный Samsung. Он не выпускается в виде чипов: если пользователь желает использовать данную память, он должен обращаться в компанию, чтобы она изготовила ему кремневую подложку и интегрировала ее в чип пользователя. Данная память похожа на DDR и не использует последовательные трансиверы для передачи данных.
Примеры подключения HMC
Физически данные в HMC передаются последовательно по SerDes-интерфейсу со скоростью 15 Гбит/с. Вскоре появятся чипы со скоростью 30 Гбит/с. 16 линий объединяются в один логический канал. Канал может работать как в полноканальном режиме, так и в полуканальном (используются 8 линий). Обычно HMC доступны с 2 или 4 каналами. Каждый канал может быть как мастером, так и промежуточным. Промежуточные режимы используются, когда необходимо объединить несколько чипов в цепочку. Процессор обязан сконфигурировать каждый HMC-чип.
Пример объединения чипов HMC в цепочку:


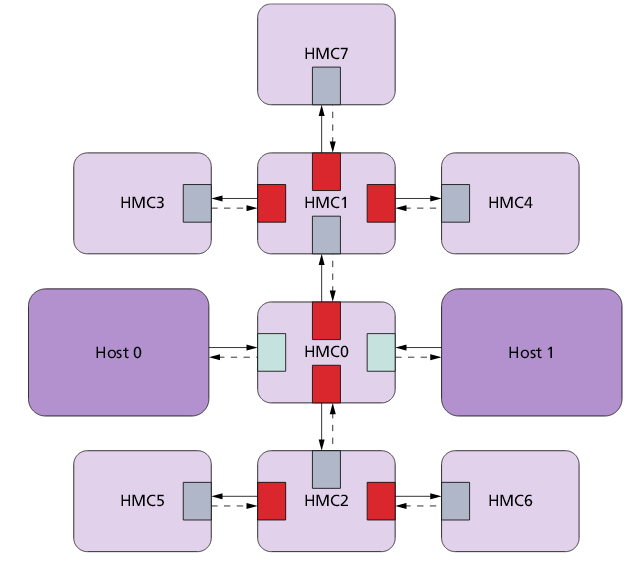
Пример объединения чипов HMC звездой, с возможностью мультихостового режима:
Передача данных по логическому каналу
Структура канальной передачи:
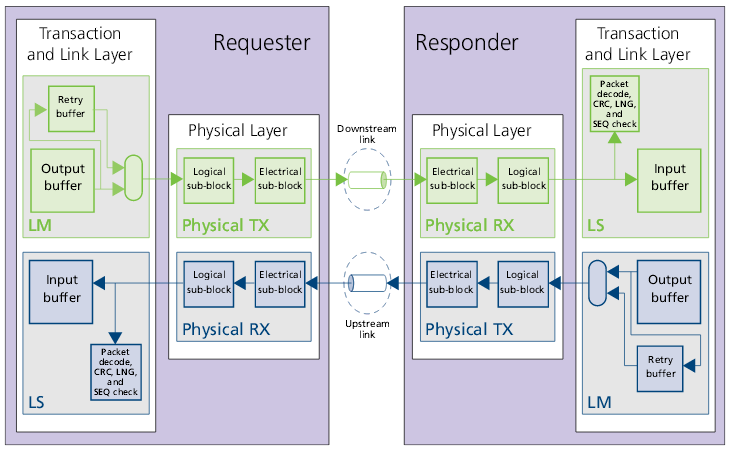
Команды и данные передаются в обоих направлениях, используя пакетный протокол. Пакеты состоят из групп длинной 128 бит, называемых FLIT. Они передаются последовательно через физические линии, а затем собираются на приемной стороне.
Три уровня обслуживания пакетов:
- Физический уровень обеспечивает прием, передачу, сериализацию и десереализацию данных.
- Канальный уровень обеспечивает низкоуровневое сопровождение пакетов.
- Транспортный уровень определяет поля, заголовки пакетов, проверяет целостность пакетов и канала связи.
Организация передачи 128 битного FLIT через физические линии в различных режимах:
1. Распределение FLIT-пакета по линиям в полной конфигурации (16 линий)
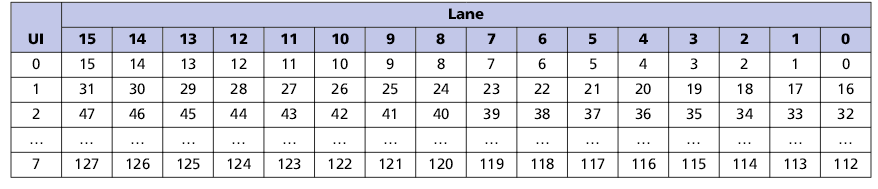
2. Распределение FLIT-пакета по линиям в половинной конфигурации (8 линий)
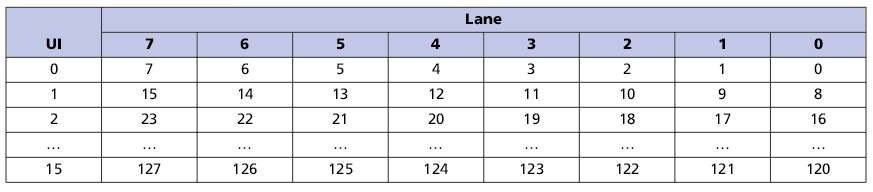
Адресация памяти
Заголовок пакета содержит 34 адресных бита, включая банк, DRAM-адрес. Текущая конфигурация позволяет адресовать максимум 4 ГБайта для одного чипа, при этом старшие 2 бита игнорируются, они зарезервированы на будущее. Чтение и запись данных происходит с 16-байтной грануляцией. Размер блока можно установить на 16, 32, 64, 128 Байт.
Адресация в HMC:
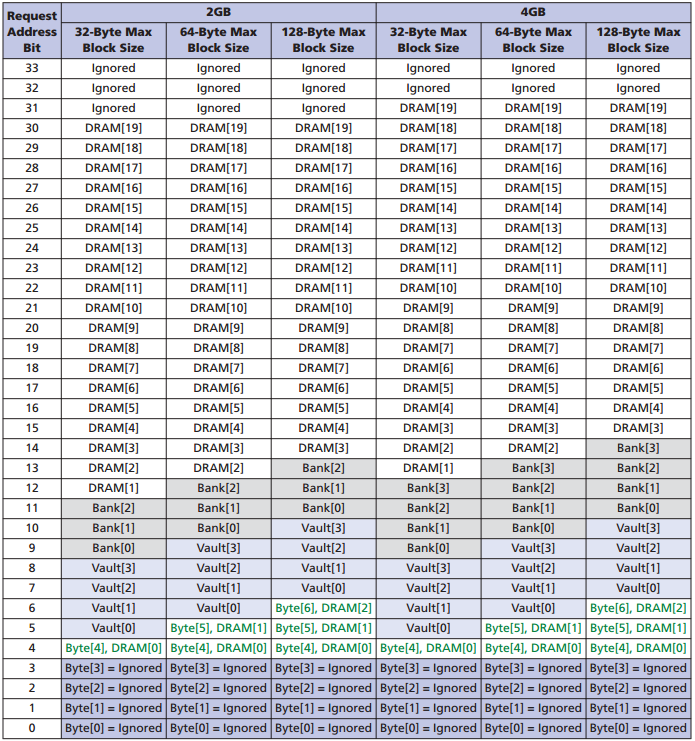
Более подробно данные команды можно изучить в спецификации HMC на сайте компании Micron.
Типовое подключение HMC к FPGA Xilinx Virtex Ultrascale и требования к питанию
Подключение памяти к FPGA производится через трансиверы GTX. Можно использовать от 8 трансиверов и до 16 в пределах одного канала. Таких каналов может быть 4. Для правильного подключения к трансиверам FPGA необходимо выполнить несколько правил:
- Трансиверы в пределах канала должны идти подряд, не допускается перескакивать через трансиверы.
- Для устройств с технологией SSI (Stacked Silicon Interconnect) необходимо, чтобы трансиверы находились в одном SLR
- Банки FPGA должны идти подряд, не допускается перескакивать через банки
Типовое подключение к FPGA, два канала в полном режиме:
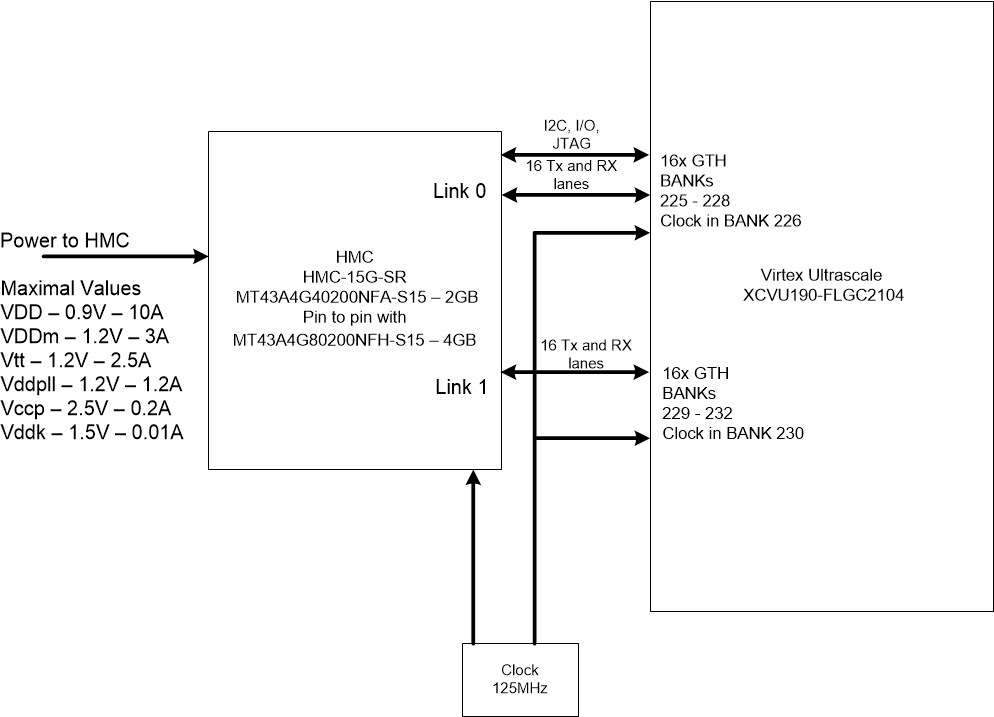
Для более глубокого изучения этой темы можно перейти на сайт консорциума разработчиков технологии HMC — hybridmemorycube.org, где опубликована последняя спецификация HMC версии 2.1.
