Если вы хоть раз были сбиты с толку, что означает символ "амперсанд" (&) или "звёздочка" ("знак умножения", *) или запутывались, когда что использовать, то это статья для вас. Авторы Go старались сделать язык знакомым большинству программистов, и многие элементы синтаксиса заимствовали из языка С. Но в 2017м уже сложно понять, большинство программистов владеют С или нет, и смею полагать, что уже нет. Поэтому концепции хорошо знакомые прошлому поколению разработчиков, могут выглядеть совершенной абракадаброй для для нового поколения. Давайте немного копнём историю и расставим все точки над ї в вопросах указателей в Go и использования символов & и *.

Указатели
Про то, что такое и как устроены указатели я писал в статье "Как не наступать на грабли в Go", которую рекомендую к прочтению даже не новичкам в Go. Краткий повтор про указатели:
по сути, это один блок памяти, который содержит адрес другого блока памяти, где лежат данные. Если вы слышите фразу "разыменовать указатель", то это означает "найти данные из блока памяти, на который указывает этот адрес".
Вот визуализация из статьи:

Здесь Point{10, 20} это "литерал" — новая переменная, объявленная на месте, "блок памяти", а & — это "адрес этого блока памяти".
Тоесть в коде:
var a int
var b = &a
fmt.Println(a, b) // выведет "0 0x10410020"переменная b будет является указателем и содержать адрес a.
Тот же код, но запишем тип b явно:
var a int
var b *int = &a
fmt.Println(a, b) // выведет "0 0x10410020"здесь звёздочка означает "тип указатель на число". Но, если она используется не перед типом, а перед самой переменной, то значение меняется на обратное — "значение по этому адресу":
var a int
var b *int = &a
var c int = *b
fmt.Println(a, b, c) // выведет "0 0x10410020 0"Это может запутывать и сбивать с толку, особенно людей, никогда, не работавших с указателями, которых нет, например, в таких популярных языках как JavaScript или Ruby. Причём в языках вроде C и С++ есть ещё масса применений указателям, например "арифметика указателей", позволяющая вам прямо смещениями по сырой памяти бегать и реализовывать невероятно быстрые по современным меркам структуры данных. Ещё очень удобно переполнение буфера получать благодаря этому, создавая баги, приносящие ущерб на миллиарды долларов. Есть даже целые книги по тому, как понимать указатели в С.
Но если механика работы с указателями в Go относительно простая, остаётся открытым вопрос — почему "амперсанд" и "звёздочка" — что это вообще должно означать? Возможно это потому что символы рядом на клавиатуре (Shift-7 и Shift-8)? Ну а чтобы понять любую тему, нет способа лучше, нежели копнуть её историю.
История
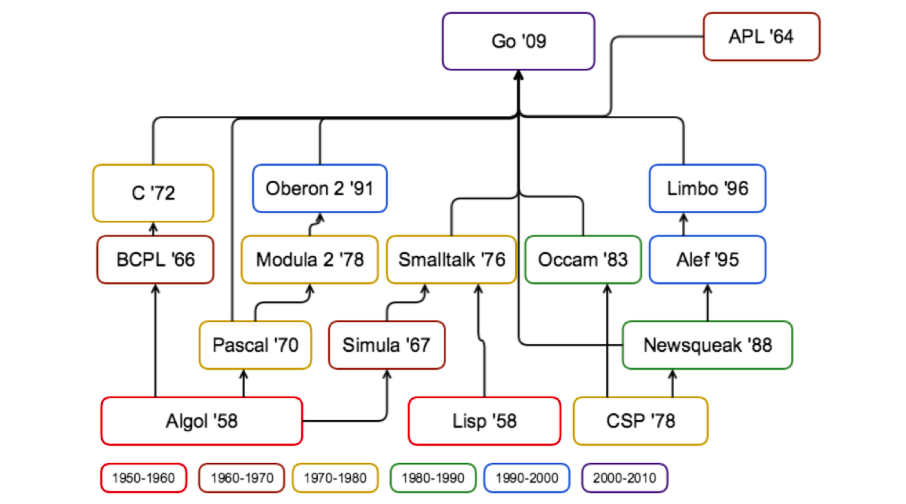
А история такова. Одним из авторов Go был легендарный Кен Томпсон, один из пионеров компьютерной науки, подаривший нам регулярные выражение, UTF-8 и язык программирования B, из которого появился C, на базе которого, 35 лет спустя, появился Go. Вообще, генеалогия Go немного сложнее, но С был взят за основу по той простой причине, что это язык, который десятилетиями был стандартом для изучения программирования в университетах, ну и о его популярности в своё время, думаю, не нужно говорить.
И хотя сейчас Кен Томпсон отошёл немного от Go и летает на своём частном самолёте, его решения проникли в Go ещё задолго до Go. В юности он развлекался тем, что писал на завтрак новые языки программирования (слегка утрирую), и одним из языков, который был им создан вместе с ещё одной легендой компьютерной науки Денисом Ритчи, являлся язык программирования B (Би).
В то время Кен Томпсон написал операционную систему на ассемблере для компьютера PDP-7, который стоил 72000 долларов — а это примерно полмиллиона долларов сегодня — обладал памятью в 9 КБ (расширялась до 144КБ) и выглядел вот так:

Собственно, эта операционная система называлась Unics, и затем была переименована в UNIX. И когда зашла речь о переписывании её для нового крутого компьютера PDP-11, было принято решение писать на каком-то более высокоуровневом языке программирования. BCPL, который был предшественником B был слишком многословен — много букв. B был более лаконичен, но имел другие проблемы, которые делали его плохим кандидатом для портирования UNIX на PDP-11. Именно тогда Денис Ритчи и начал работать над новым языком, во многом основанном на B, специально для написания UNIX под PDP-11. Имя C было выбрано, как следующая буква алфавита после B.
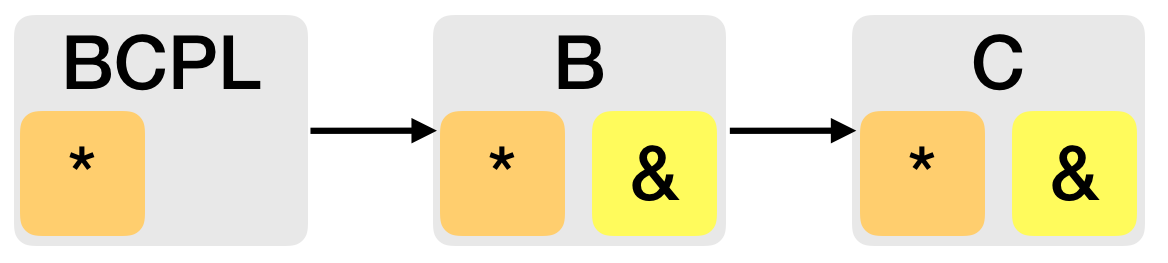
Но вернёмся к теме об амперсанде и звёздочке. Звёздочка (*) была ещё в языке BCPL, и в B попала с тем же смыслом обозначения указателя, просто потому что так было в BCPL. Ровно по этой же причине перекочевали в С.
А вот амперсанд (&), означающий "адрес переменной", появился в B (и также перекочевал в С просто потому что), и был выбран по нескольким причинам:
- нужен был один символ, а не два или целое слово
- выбор символов был очень ограниченный (об этом чуть ниже)
- как говорит сам Кен Томпсон, слово "амперсанд" звучало мнемонически похоже на "адрес" и было выбрано именно по этому.
Если я вас запутал, то вот нагляднее:
И тут нужно посмотреть внимательно на клавиатуры того времени. Чуть выше на картинке PDP-7 можно рассмотреть вводное устройство, коим являлся Телетайп 33. Стоит посмотреть на его клавиатуру повнимательнее, чтобы понять реалии того времени, и понять, с какими ограничениями сталкивались программисты и дизайнеры языков программирования в то время:

Как можно увидеть, ни тачбара, ни эмоджи не было :), и символы приходилось выбирать только из того набора, который был в телетайпе. Также, примечательно, что амперсанд и звёздочка тогда были не рядом, а на целых 4 клавиши порознь, что опровергает идею выбора амперсанда из-за близости клавиш. Собственно, из всех доступных клавиш, Кену Томпсону на тот момент больше всего приглянулся "амперсанд", похожий на "адрес".
Ну а дальше вы знаете — С стал языком века (прошлого), повлиял на огромное количество других языков, а книги по С стали настольными библиями программистов на несколько десятилетий. В таком же виде указатели вместе со звёздочкой и амперсандом попали и в С++ — ещё один язык мейнстримовый язык, на котором до Go писалась большая часть сетевого и серверного софта.
Поэтому решение включить указатели (без арифметики указателей, к счастью) в Go с тем же синтаксисом — было вполне логичным и естественным. Для С/C++ программистов это такие же базовые и простые понятия, как скобочки { и }.
И всё таки это удивительно осознавать, какое сильное влияние имеют исторические решения, принятые пол столетия назад на современные технологии.
Заключение
Если вы всё ещё неуверенно себя чувствуете себя с указателями в Go, запомните два простых правила:
- "Амперсанд"
&звучит похоже на "Адрес" (ну, и то слово и другое на "А" начинается, по крайней мере)))), поэтому&xчитается как "адрес переменной X" - звёздочка
*ни на что не похоже на звучит, но может использоваться в двух случаях — перед типом (var x *MyType— означает "тип указателя на MyType") и перед переменной (*x = y— означает "значение по адресу")
Надеюсь, кому то это немного поможет лучше понимать смысл указателей и символов, стоящими за ними в Go.
