
Почти каждый из нас когда-либо работал в компании, где есть всеми ненавистная "файлопомойка" — шара с тысячами документов без какой-либо структуры. И наверняка у каждого был момент, когда ему нужно было что-то в этой помойке отыскать. "А Василич этот отчёт на шару кидал в прошлом месяце, глянь там" — слышали мы от коллеги, а тот самый Василич на вопрос "А в какой папке?" конечно же отвечал "А х… не помню, в общем, сам ищи". И мы погружались в многочасовой ад — бродили по папкам с документами из 90-х, фотографиями котов, договорами вперемешку с анекдотами и прочим шлаком в надежде найти заветный документ.
Наверняка многие из нас пытались навести в этой шаре порядок, "С меня хватит, сейчас возьму, разгребу всё и разложу по полочкам" — заявляли мы всем, тратили часы, дни и недели своего времени разгребая завалы. А параллельно Василиса Семёновна из бухгалтерии, или тот же Василич снова разбавляли разобранные файлы своими документами, котами, анекдотами и прочим, возвращая привычный хаос на своё место. И так продолжалось до тех пор, пока вы не сдались. И шара обратно превратилась в привычную помойку.
Как быть?
Раз идея заставить всех пользователей поддерживать порядок в шаре потерпела фиаско, значит нужно искать альтернативные подходы. Очевидным выбором с минимальными трудозатратами был бы поисковик, который позволяет выполнять поиск как по названиям и метаданным, так и по содержимому всех файлов в помойке.
Когда мы находились на этапе решения данной проблемы для наших клиентов, мы в первую очередь рассмотрели имеющиеся системы для поиска и менеджмента документов, отдавая приоритет open-source решениям. Не вдаваясь в детали поиска и исследования сразу декларирую результат: быстрого, простого и удобного решения для индексации и поиска в шарах, с OCR, тегированием и подсветкой именованных сущностей просто не существовало.
Что дальше? Решение
Поэтому, видя эту проблему во многих компаниях, мы решились на создание своего продукта, конечно же open-source'ного.
В итоге у нас получился Ambar — система для поиска и структуризации документов, которая наконец соответствовала всем нашим требованиям (GitHub), а именно:
- Мгновенный поиск по содержимому документов, в т.ч. изображений
- Тегирование документов, в т.ч. автоматическое (например, помечать все изображения тегом image, или помечать все документы где есть IP адреса тегом ip)
- Поддержка всех офисных форматов (в т.ч. openoffice), pdf с картинками и старых кодировок вроде CP866
- Автоматический сбор и синхронизации документов из шар-помоек
Рассмотрим вариант решения нашей проблемы с помощью Ambar, по шагам:
- Устанавливаете Ambar на линукс сервере: нужен Docker и Ubuntu Server 16.04 и выше (
инструкция по установке на английском) - Настраиваете SMB или FTP краулер (инструкция на английском)
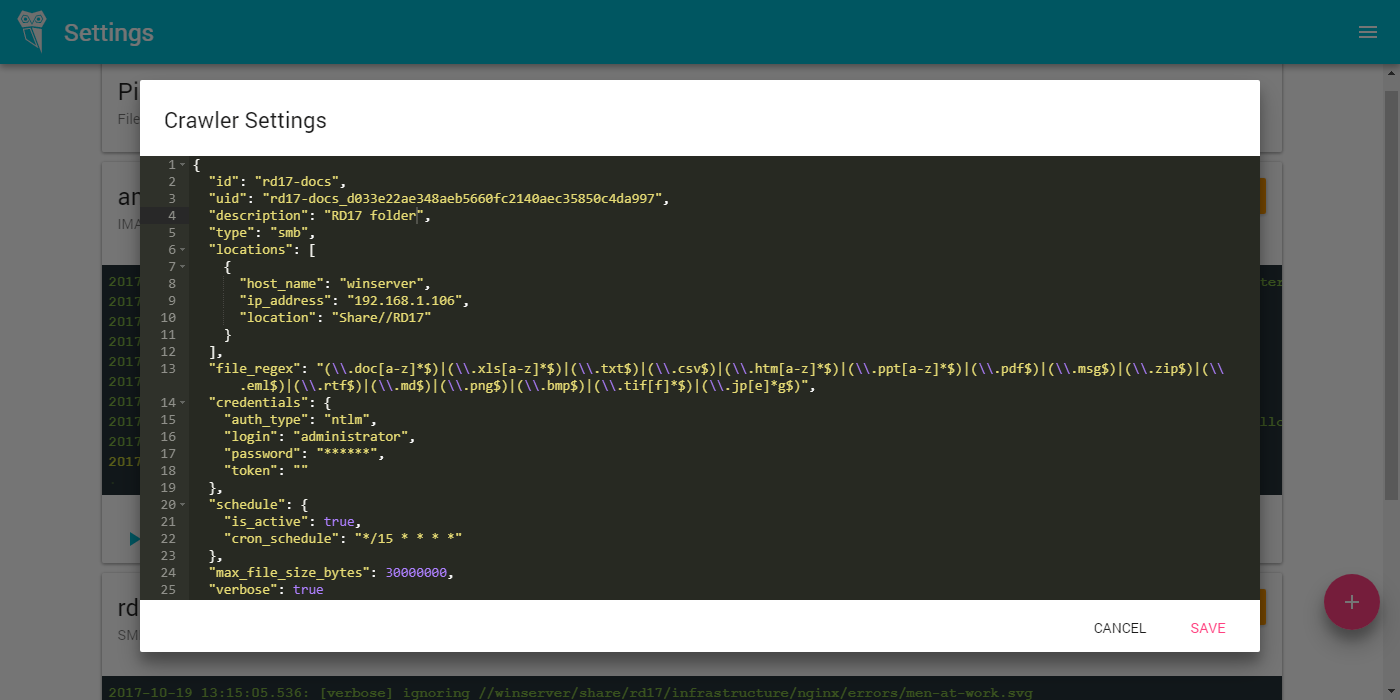
- Наблюдаете за процессом индексации ваших документов на странице статистики
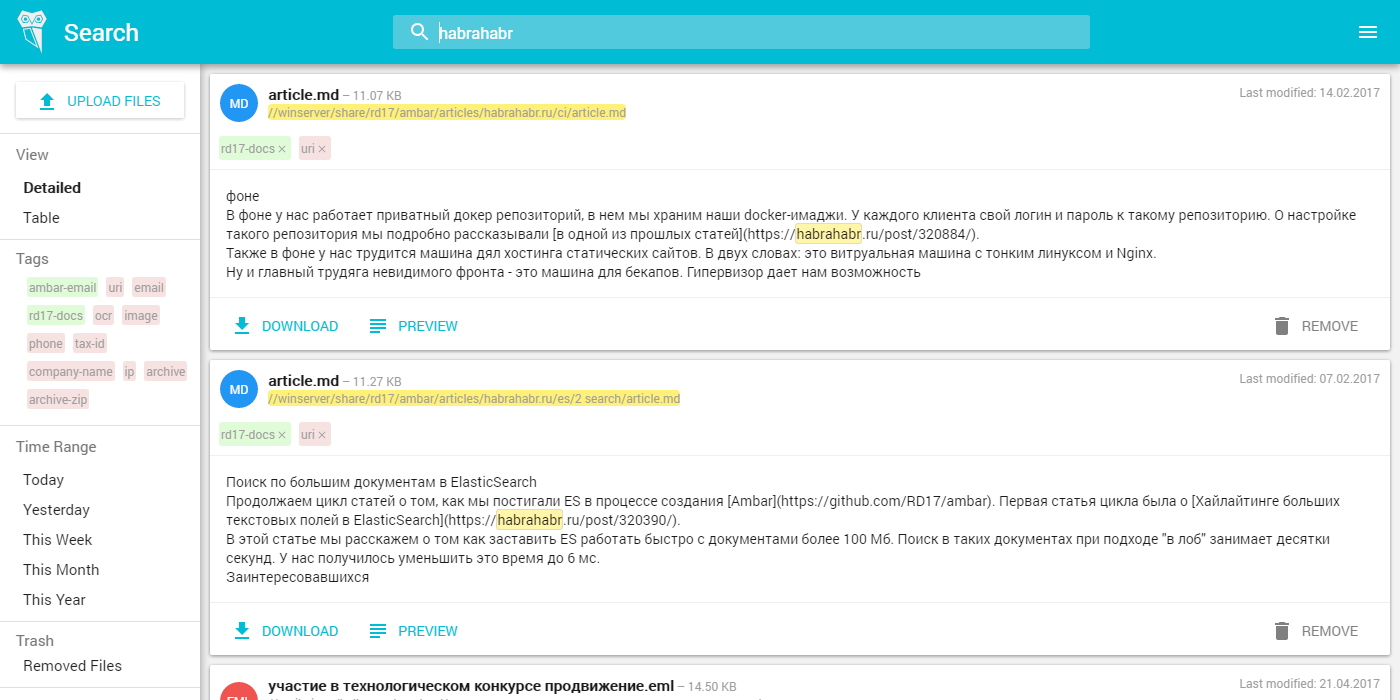
- Используете поиск с тегами и прочими плюшками
Итог
В этой короткой статье мы поделились нашей болью, связанной с большими файловыми помойками в компаниях и нашим подходом к решению этой проблемы.
Спасибо за внимание!
