Недавно мы рассказали о способах, с помощью которых сэкономили более миллиона долларов на годовом обслуживании AWS. Хотя мы подробно рассказывали о различных проблемах и решениях, всё равно самым популярным вопросом был: «Я знаю, что слишком много трачу на AWS, но как в реальности разбить эти траты на понятные части?»
На первый взгляд, проблема кажется довольно простой.
Вы можете легко разбить свои расходы AWS по месяцам и закончить на этом. Десять тысяч долларов на EC2, одна тысяча на S3, пятьсот долларов на сетевой трафик и т.д. Но здесь отсутствует кое-что важное — на сочетание каких именно продуктов и групп разработки приходится львиная доля расходов.
И учтите, что у вас могут меняться сотни инстансов и миллионы контейнеров. Вскоре то, что поначалу казалось простой аналитической проблемой, становится невообразимо сложным.
В этом продолжении статьи мы хотели бы поделиться информацией о наборе инструментов, который сами используем. Надеемся, что сумеем предложить несколько идей, как анализировать свои затраты AWS независимо от того, работает у вас парочка инстансов или десятки тысяч.
Если вы ведёте масштабные операции на AWS, то, вероятно, уже столкнулись с двумя проблемами.
Во-первых, сложно заметить, если вдруг одна из групп разработки внезапно увеличивает свой бюджет.
Наш счёт за AWS превышает $100 тыс. в месяц, и расходы на каждый компонент AWS быстро изменяются. В каждую конкретную неделю мы можем выкатывать пять новых сервисов, оптимизировать производительность DynamoDB и подключать сотни новых клиентов. В такой ситуации легко пропустить мимо внимания, что какая-то одна команда в этом месяце потратила на EC2 на $20 000 больше, чем в прошлом месяце.
Во-вторых, бывает сложно предсказать, в какую сумму обойдётся обслуживание новых клиентов.
Для ясности, наша компания Segment предлагает единый API, который отправляет аналитические данные любым сторонним инструментам, в хранилища данных, S3 или внутренние информационные системы компаний.
Хотя клиенты довольно точно прогнозируют, какое количество трафика им понадобится и какие продукты они предпочитают использовать, но у нас постоянно возникают проблемы с переводом такого прогноза в конкретную долларовую сумму. В идеале мы хотели бы сказать: «1 миллион новых вызовов API будет стоить нам $X, так что мы должны убедиться, что берём с клиента как минимум $Y».
Решением этой проблемы для нас стало разделение инфраструктуры на то, что мы называем «продуктовыми направлениями». В нашем случае эти направления расплывчато формулируются следующим образом:
Анализируя весь проект, мы пришли к выводу, что тут практически невозможно измерить всё. Так что вместо этого мы поставили задачу отслеживать часть затрат в счёте, скажем, 80%, и попытаться отслеживать эти затраты от начала и до конца.
Для бизнеса полезнее анализировать 80% счёта, чем нацелиться на 100%, завязнуть на этапе сбора данных и никогда не выдать никакого результата. Охват 80% затрат (готовность сказать «этого достаточно») снова и снова спасала нас от безрезультатного ковыряния в данных, которое не даёт ни доллара экономии.
Чтобы разбить затраты по продуктовым направлениям, нужно загрузить данные для биллинговой системы, то есть собрать и впоследствии объединить следующие данные:
Когда мы определили продуктовые направления по всем этим данным, можно загрузить их для анализа в Redshift.
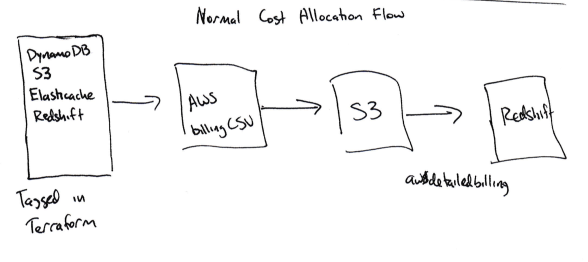
Анализ ваших затрат начинается с разбора файла CSV от AWS. Можно активировать соответствующую опцию на биллинговом портале — и Amazon будет каждый день сохранять на S3 файл CSV с подробной биллинговой информацией.
Под подробной я имею в виду ОЧЕНЬ подробную. Вот типичная строка в отчёте:
Это счёт на внушительную сумму $0,00000001, то есть одну миллионную цента, за хранение в базе DynamoDB единственной таблицы 7 февраля между 3:00 и 4:00 часами ночи. В обычный день наш CSV содержит примерно шесть миллионов таких записей. (К сожалению, большинство из них с более значительными суммами, чем одна миллионная цента).
Для переноса данных из S3 в Redshift мы используем инструмент awsdetailedbilling от Heroku. Это неплохо для начала, но у нас не было нормального способа связать конкретные затраты AWS с нашими продуктовыми направлениями (то есть использовался ли конкретный инстанс-час для интеграций или для хранилищ данных).
Более того, примерно 60% расходов приходится на долю EC2. Хотя это львиная часть расходов, но понять связь между инстансами EC2 и конкретными продуктовыми направлениями абсолютно невозможно только из того CSV, что генерирует AWS.
Есть важная причина, почему мы не могли определить продуктовые направления просто по названиям инстансов. Дело в том, что вместо запуска по одному процессу на хосте мы интенсивно используем ECS (Elastic Container Service) для размещения сотен контейнеров на хосте и значительно более интенсивного использования ресурсов.
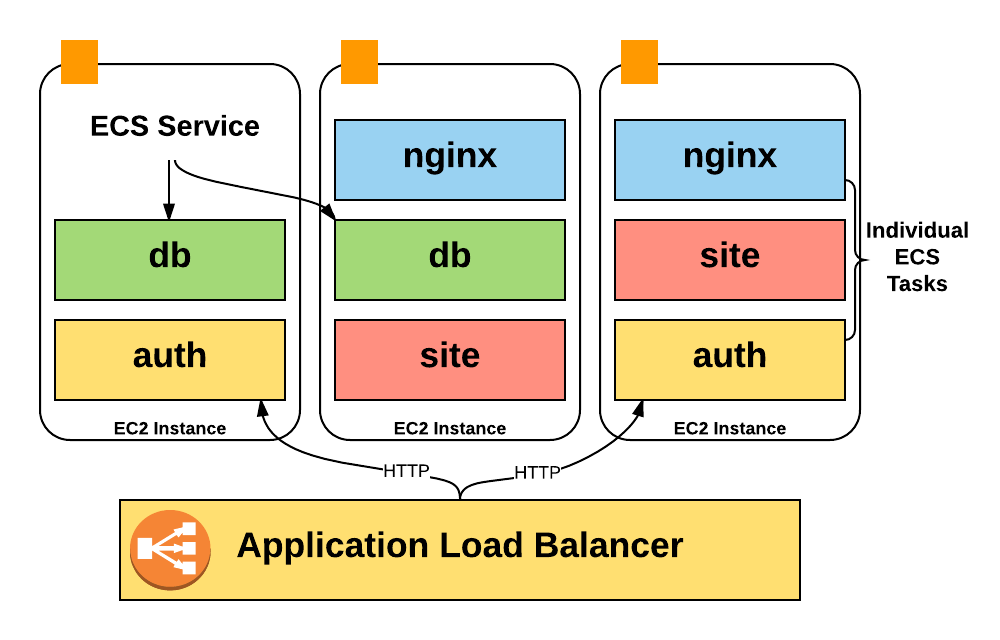
К сожалению, счета Amazon содержат только расходы инстансов EC2, так что у нас не было никакой информации о расходах контейнеров, работающих на инстансе: сколько контейнеров было запущено в обычное время, какую часть пула мы использовали, сколько задействовали юнитов CPU и памяти.
Хуже того, нигде в CSV не отражена информация об автомасштабировании контейнеров. Чтобы добыть эти данные для анализа, пришлось написать собственный инструментарий для сбора информации. В следующих главах я подробнее расскажу, как работает этот конвейер.
Тем не менее, файл CSV от AWS предоставляет очень хорошие детальные данные об использовании сервиса, которые стали основой для анализа. Нужно только связать их с нашими продуктовыми направлениями.
Примечание: Эта проблема тоже никуда не денется. Биллинг по инстанс-часам будет становиться всё большей и большей заботой с точки зрения вопроса «На что я трачу свои деньги?», потому что всё больше компаний запускают кучу контейнеров на большом количестве инстансов, используя системы вроде ECS, Kubernetes и Mesos. Есть некая ирония в том, что сама Amazon испытывает точно такую проблему уже много лет, ведь каждый инстанс EC2 — это гипервизор Xen, который работает совместно с другими инстансами на одном и том же физическом сервере.
Самые важные и уже готовые для обработки данные поступают от «помеченных» ресурсов AWS.
По умолчанию биллинговый CSV не содержит каких-либо тегов. Поэтому невозможно различить, как один инстанс EC2 или бакет ведёт себя по сравнению с другим.
Однако вы можете активировать некоторые метки, которые будут отображаться рядом с вашими расходами на каждую единицу, используя теги распределения затрат.
Эти теги официально поддерживаются многими ресурсами AWS, бакетами S3, таблицами DynamoDB и т.д. Чтобы отобразить теги распределения затрат в CSV, вы можете включить соответствующий параметр в консоли биллинга AWS. Через день или около того выбранный вами тег (мы выбрали
Если вы больше не предпринимали никаких оптимизаций, то можно сразу начать использование тегов распределения затрат для разметки своей инфраструктуры. Это по сути «бесплатная» услуга и не требует никакой инфраструктуры для работы.
После активации функции у нас возникло две задачи: 1) разметка всей существующей инфраструктуры; 2) проверка, что всех новые ресурсы автоматически будут помечены тегами.
Проставить теги для существующей инфраструктуры довольно легко: для каждого конкретного продукта AWS запрашиваете в Redshift список ресурсов с наибольшими расходами — и тормошите людей в Slack до тех пор, пока они не скажут, как эти ресурсы нужно пометить. Заканчиваете процедуру, когда пометите 90% или больше ресурсов по стоимости.
Однако для гарантии, что новые ресурсы станут помечены, требуется некоторая автоматизация и инструментарий.
Для этого мы используем Terraform. В большинстве случаев конфигурация Terraform поддерживает добавление тех же тегов распределения затрат, которые добавляются через консоль AWS. Вот пример конфигурации Terraform для бакета S3:
Хотя Terraform обеспечивает базовую конфигурацию, мы хотели убедиться, что при каждой записи нового ресурса
К счастью, конфигурации Terraform написаны на HCL (Hashicorp Configuration Language), в котором есть парсер конфигурации с сохранением комментариев. Так что мы написали функцию проверки, которая проходит по всем файлам Terraform и ищет подлежащие разметке ресурсы без тега
Мы наладили непрерывную интеграцию для репозитория с конфигами Terraform, а затем добавили эти проверки, так что тесты не пройдут, если встретится подлежащий разметке ресурс без тега
Это не идеально — тесты привередливы, а люди технически имеют возможность создавать непомеченные ресурсы напрямую в консоли AWS, но система достаточно хорошо работает для данного этапа. Самый простой способ описания новой инфраструктуры — делать это через Terraform.
После разметки ресурсов их учёт представляет собой простую задачу.
У вас может появиться желание разбить расходы по сервисам AWS — у нас есть две отдельные таблицы, одна по продуктовым направлениям Segment, а вторая по сервисам AWS.
С помощью обычных тегов распределения затрат AWS мы сумели распределить примерно 35% расходов.
Такой подход хорошо для размеченных, доступных инстансов. Но в некоторых случаях AWS берёт авансовую оплату за «бронирование». Бронирование гарантирует доступность определённого объёма ресурсов в обмен на авансовую оплату по сниженным тарифам.
В нашем случае получается, что несколько крупных платежей из прошлогоднего декабрьского счёта CSV нужно распределить по всем месяцам текущего года.
Чтобы корректно учесть эти расходы, мы решили использовать данные по раздельным (unblended) расходам за данный период. Запрос выглядит примерно так:
Расходы на подписку оформляются в виде "$X0000 of DynamoDB", так что их невозможно приписать к какому-то ресурсу или продуктовому направлению.
Вместо этого мы складываем расходы на каждый ресурс по продуктовым направлениям, а затем распределяем расходы на подписку в соответствии с долей в процентах. Если на хранилища данных ушло 60% расходов EC2, то мы предполагаем, что из абонентского аванса на эти цели тоже ушло 60%.
Это тоже не идеально. Если большая часть вашего счёта берётся из авансового платежа, такую стратегию распределения исказят небольшие изменения в текущих расходах на работающие инстансы. В этом случае вы захотите распределять расходы исходя из информации по использованию каждого ресурса, а её сложнее суммировать, чем расходы.
Хотя разметка инстансов и таблиц DynamoDB — это отлично, но другие ресурсы AWS не поддерживают теги распределения расходов. Эти ресурсы потребовали создания заумного рабочего процесса в стиле Руба Голдберга для успешного получения данных о затратах и перенесения их в Redshift.
Две самых больших группы непомеченных ресурсов в нашем случае — это ECS и EBS.
Система ECS непрерывно увеличивает и уменьшает масштаб работы наших сервисов, в зависимости от количества контейнеров, которые нужны каждому из них для работы. Она также отвечает за перебалансировку и упаковку в контейнеры в большом количестве отдельных инстансов.
ECS запускает на хостах контейнеры в зависимости от количества «зарезервированных CPU и памяти». Каждый сервис сообщает, сколько ему нужно частей CPU, а ECS или разместит новые контейнеры на хосте с достаточным объемом ресурсов, или масштабирует количество инстансов, чтобы добавить необходимые ресурсы.
Ни одно из этих действий ECS напрямую не отражается в биллинговом отчёте CSV — но ECS по прежнему отвечает за запуск автомасштабирования для всех наших инстансов.
Проще говоря, мы хотели понять, какую «часть» конкретной машины использует каждый контейнер, но отчёт CSV даёт нам только разбивку «целого юнита» по инстансу.
Чтобы определить расходы на конкретный сервис, мы разработали собственный алгоритм:
Как только все данные о старте/остановке/размере поступили в Redshift, мы умножаем количество времени, которые эта задача работала в ECS (скажем, 120 секунд) на количество юнитов CPU, которые она использовала на данной машине (до 4096 — эта информация доступна в описании задачи), чтобы вычислить количество CPU-секунд для каждого сервиса, работавшего на инстансе.
Общие расходы инстанса из счёта затем делятся между сервисами в соответствии с количеством использованных CPU-секунд.
Это тоже не идеальный метод. Инстансы EC2 на работают всё время на 100% мощности, в то время как избыток в данный момент распределяется между всеми сервисами, работавшими на этом инстансе. Это может быть верным или неверным распределением избыточных расходов. Но (и здесь вы можете узнать общую тему этой статьи) этого достаточно.
Вдобавок мы хотим соотнести каждый сервис ECS с соответствующим продуктовым направлением. Однако мы не можем разметить их в AWS, потому что ECS не поддерживает теги распределения расходов.
Вместо этого мы добавляем ключ
Этот скрипт затем на каждую новую отправку данных публикует в основную ветку для DynamoDB карту соотнесения названий сервисов и продуктовых направлений в кодировке base64.
Наконец, затем наши тесты проверяют каждый новый сервис, который снабжён тегом о продуктовом направлении.
Elastic Block Storage (EBS) тоже занимает значительную часть нашего счёта. Тома EBS обычно подключены к инстансам EC2, и для учёта имеет смысл учитывать расходы на тома EBS вместе с соответствующими инстансами EC2. Однако биллинг CSV от AWS не показывает, какой том EBS подключён к какому инстансу.
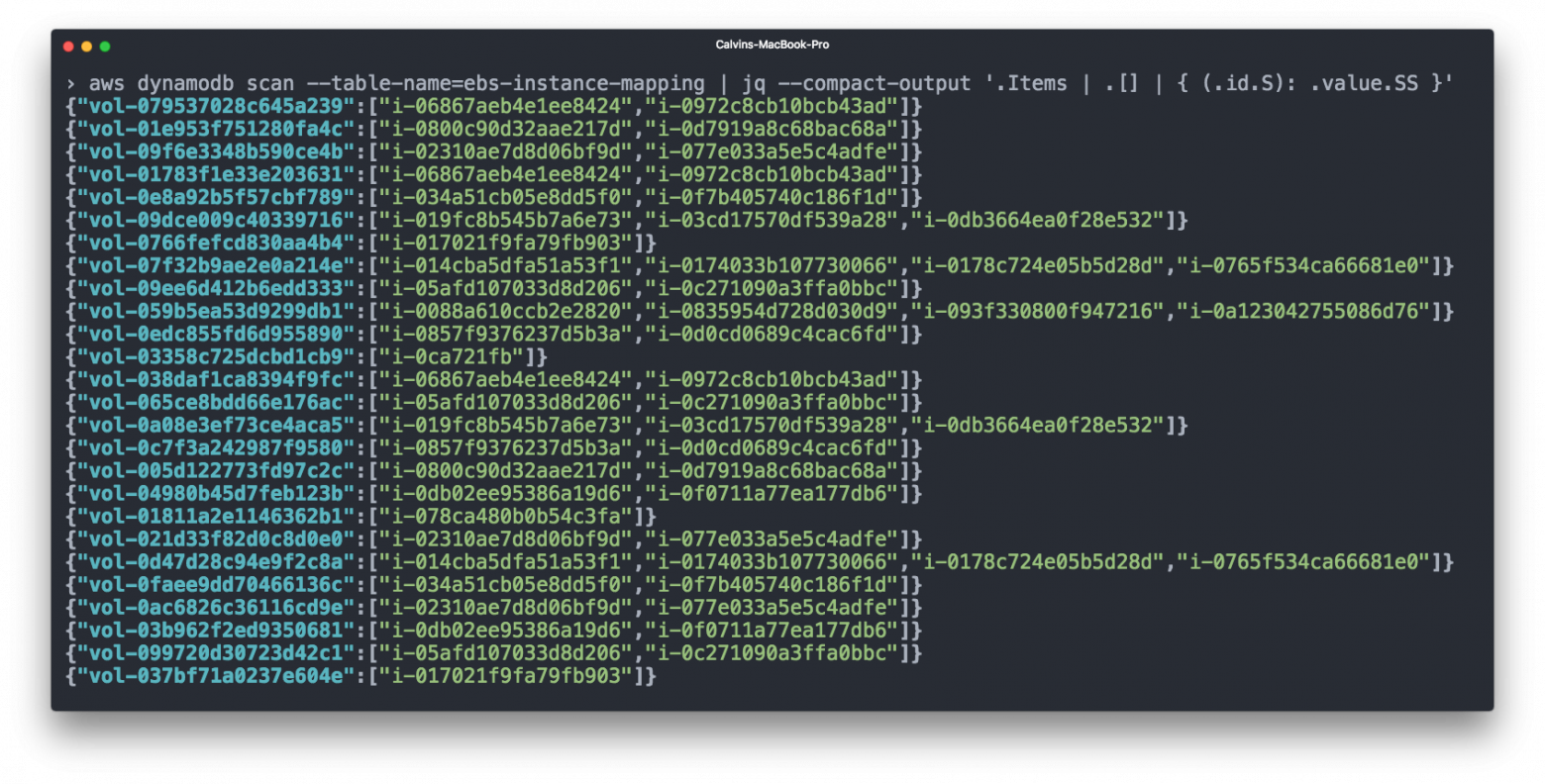
Для этого мы опять использовали Cloudwatch — оформили подписку на события типа «подключение тома» и «отключение тома», а затем регистрировали связи EBS => EC2 в таблице DynamoDB.
Затем мы добавляем расходы томов EBS к расходам соответствующих инстансов EC2, прежде чем учитывать расходы ECS.
До сих пор мы обсуждали все наши расходы в контексте одного аккаунта AWS. Но на самом деле это не отражает нашу реальную конфигурацию AWS, которая распределяется между разными физическими аккаунтами AWS.
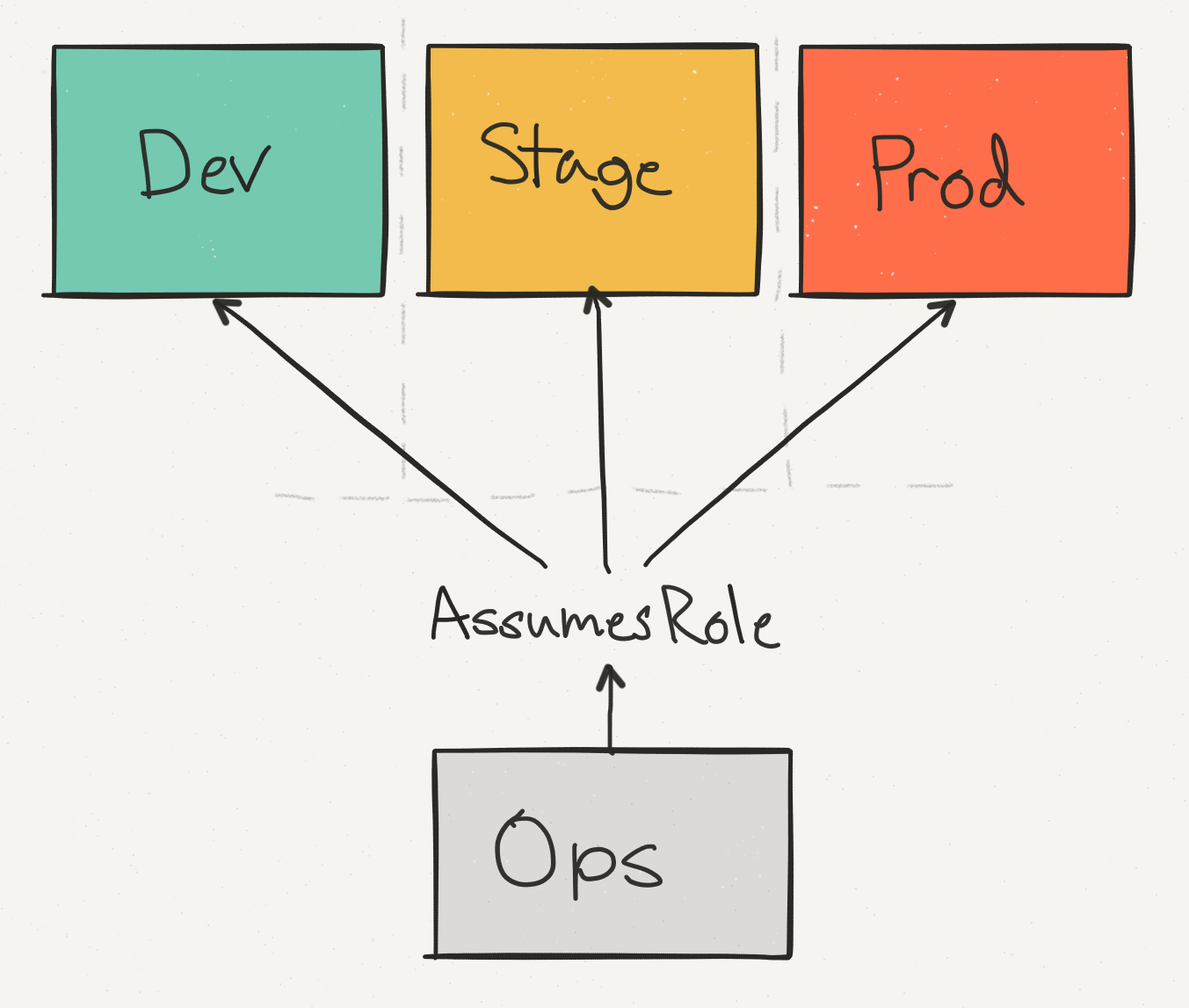
Мы используем операционный аккаунт (Ops) не только для консолидации данных и биллинга по всем аккаунтам, но и чтобы обеспечить единую точку доступа инженерам для осуществления изменений в продакшне. Мы отделяем этап Stage от продакшна — так можно проверить, что вызов API, например, на удаление таблицы DynamoDB, безопасно обрабатывается с соответствующими проверками.
Среди этих аккаунтов по расходам доминирует аккаунт Prod, но расходы аккаунта Stage тоже составляют значительную часть общего счёта AWS.
Сложности начинаются, когда нужно записать данные о сервисах ECS из аккаунта Stage в кластер Redshift на продакшне.
Чтобы получить возможность записи «между аккаунтами», мы должны позволить обработчикам подписок Cloudwatch взять на себя роль в продакшне для записи в Firehose (для ECS) или DynamoDB (для EBS). Это непросто сделать, потому что нужно добавить корректные разрешения правильной функции в аккаунте Stage (sts.AssumeRole) и в аккаунте Prod, а любая ошибка приведёт к путанице разрешений.
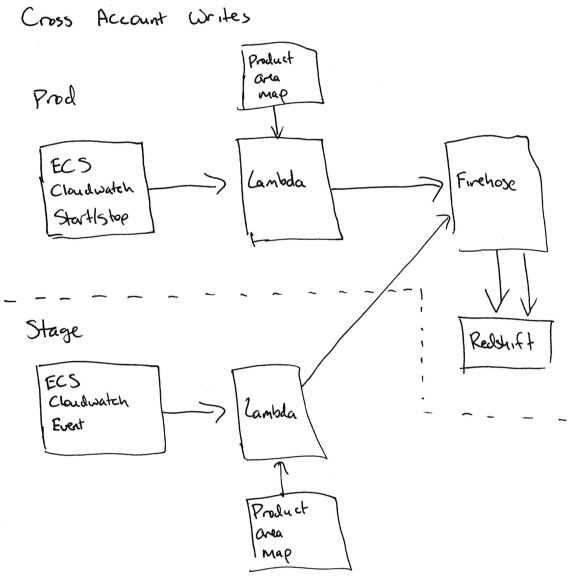
Для нас это значит, что код для учёта не работает на аккаунте Stage, а вся информация заносится в базу данных на аккаунте Prod.
Хотя на аккаунте Stage можно добавить второй сервис, который подписан на те же данные, но не записывает их, мы решили, что в этом случае есть вероятность столкнуться со случайными проблемами в коде учёта Stage.
Наконец-то у нас есть всё для правильного анализа данных:
Чтобы выдать это всё сотрудникам аналитической группы, я разбил данные по сервисам AWS. Для каждого сервиса AWS я суммировал продуктовые направления Segment и их расходы по этому сервису AWS.
Эти данные выдаются в трёх разных таблицах:
Общие расходы для отдельных продуктовых направлений выглядят примерно так:
А расходы по сервисам AWS в сочетании с продуктовыми направлениями Segment выглядят так:
Для каждой из этих таблиц у нас есть итоговая таблица с итоговыми цифрами за каждый месяц и дополнительная сводная таблица, которая каждый день обновляет данные за текущий месяц. Уникальный идентификатор в сводной таблице соответствует каждому проходу, так что вы можете свести воедино счёт AWS, найдя все строки для данного прохода.
Итоговые данные эффективно выполняют роль нашего золотого «источника истины», который используется для высокоуровневых метрик и отчётности перед руководством. Сводные таблицы используются для мониторинга текущих затрат в течение месяца.
Примечание: AWS выдаёт «итоговый» счёт только через несколько дней после окончания месяца, так что любая логика, которая помечает биллинговые записи как окончательные по окончании месяца, будет некорректной. Вы можете узнать итоговый счёт Amazon, когда в поле
Прежде чем завершить, мы поняли, что во всём процессе есть некоторых мест, где небольшая подготовка и знание могли бы сэкономить нам много времени. Без какой-либо сортировки вот эти места:
Получить наглядный счёт AWS непросто. Это требует большого объёма работы — как для разработки и настройки инструментария, так и для выявления дорогих ресурсов на AWS.
Самая главная победа, которой мы добились, — это возможность простого непрерывного прогнозирования затрат вместо периодических «одноразовых анализов».
Для этого мы автоматизировали весь сбор данных, реализовали поддержку тегов в Terraform и нашей системе непрерывной интеграции и объяснили всем сотрудникам группы разработки, как правильно помечать тегами свою инфраструктуру.
Все наши данные не лежат мёртвым грузом в PDF, а непрерывно обновляются в Redshift. Если мы хотим ответить на новые вопросы и сгенерировать новые отчёты, то мгновенно получаем результаты с помощью SQL-запроса.
Вдобавок мы экспортировали все данные в формат Excel, где можем точно рассчитать, во сколько нам обойдётся новый клиент. И мы также можем увидеть, если на какой-то сервис или продуктовое направление внезапно начинает уходить намного больше денег — мы видим это до того, как незапланированные расходы нанесут удар по финансовому состоянию компании.
Хотя эта статья не соответствует в точности вашей инфраструктуре, всё-таки надеемся, что наша история будет полезна и поможет лучше разобраться в своих расходах и управлять ими по мере масштабирования своего бизнеса!
На первый взгляд, проблема кажется довольно простой.
Вы можете легко разбить свои расходы AWS по месяцам и закончить на этом. Десять тысяч долларов на EC2, одна тысяча на S3, пятьсот долларов на сетевой трафик и т.д. Но здесь отсутствует кое-что важное — на сочетание каких именно продуктов и групп разработки приходится львиная доля расходов.
И учтите, что у вас могут меняться сотни инстансов и миллионы контейнеров. Вскоре то, что поначалу казалось простой аналитической проблемой, становится невообразимо сложным.
В этом продолжении статьи мы хотели бы поделиться информацией о наборе инструментов, который сами используем. Надеемся, что сумеем предложить несколько идей, как анализировать свои затраты AWS независимо от того, работает у вас парочка инстансов или десятки тысяч.
Группировка по «направлениям продуктов»
Если вы ведёте масштабные операции на AWS, то, вероятно, уже столкнулись с двумя проблемами.
Во-первых, сложно заметить, если вдруг одна из групп разработки внезапно увеличивает свой бюджет.
Наш счёт за AWS превышает $100 тыс. в месяц, и расходы на каждый компонент AWS быстро изменяются. В каждую конкретную неделю мы можем выкатывать пять новых сервисов, оптимизировать производительность DynamoDB и подключать сотни новых клиентов. В такой ситуации легко пропустить мимо внимания, что какая-то одна команда в этом месяце потратила на EC2 на $20 000 больше, чем в прошлом месяце.
Во-вторых, бывает сложно предсказать, в какую сумму обойдётся обслуживание новых клиентов.
Для ясности, наша компания Segment предлагает единый API, который отправляет аналитические данные любым сторонним инструментам, в хранилища данных, S3 или внутренние информационные системы компаний.
Хотя клиенты довольно точно прогнозируют, какое количество трафика им понадобится и какие продукты они предпочитают использовать, но у нас постоянно возникают проблемы с переводом такого прогноза в конкретную долларовую сумму. В идеале мы хотели бы сказать: «1 миллион новых вызовов API будет стоить нам $X, так что мы должны убедиться, что берём с клиента как минимум $Y».
Решением этой проблемы для нас стало разделение инфраструктуры на то, что мы называем «продуктовыми направлениями». В нашем случае эти направления расплывчато формулируются следующим образом:
- Интеграции (код, который отправляет данные из Segment различным провайдерам аналитики).
- API (сервис, который принимает данные в Segment из клиентских библиотек).
- Хранилища данных (конвейер, который загружает данные Segment в пользовательское хранилище данных).
- Веб-сайт и CDN.
- Внутренние системы (общая логика и системы поддержки для всего вышеперечисленного).
Анализируя весь проект, мы пришли к выводу, что тут практически невозможно измерить всё. Так что вместо этого мы поставили задачу отслеживать часть затрат в счёте, скажем, 80%, и попытаться отслеживать эти затраты от начала и до конца.
Для бизнеса полезнее анализировать 80% счёта, чем нацелиться на 100%, завязнуть на этапе сбора данных и никогда не выдать никакого результата. Охват 80% затрат (готовность сказать «этого достаточно») снова и снова спасала нас от безрезультатного ковыряния в данных, которое не даёт ни доллара экономии.
Сбор, затем анализ
Чтобы разбить затраты по продуктовым направлениям, нужно загрузить данные для биллинговой системы, то есть собрать и впоследствии объединить следующие данные:
- Биллинговая информация в формате CSV от AWS — это CSV, который генерирует AWS со всеми статьями расходов.
- Помеченные ресурсы AWS — ресурсы, которые можно пометить в биллинговом CSV.
- Непомеченные ресурсы — сервисы вроде EBS и ECS, которым нужны особые конвейеры данных для разметки потребления ресурсов по «направлениям продуктов».
Когда мы определили продуктовые направления по всем этим данным, можно загрузить их для анализа в Redshift.
1. Биллинг CSV от AWS
Анализ ваших затрат начинается с разбора файла CSV от AWS. Можно активировать соответствующую опцию на биллинговом портале — и Amazon будет каждый день сохранять на S3 файл CSV с подробной биллинговой информацией.
Под подробной я имею в виду ОЧЕНЬ подробную. Вот типичная строка в отчёте:
record_type | LineItem record_id | 60280491644996957290021401 product_name | Amazon DynamoDB rate_id | 0123456 subscription_id | 0123456 pricing_plan_id | 0123456 usage_type | USW2-TimedStorage-ByteHrs operation | StandardStorage availability_zone | us-west-2 reserved_instance | N item_description | $0.25 per GB-Month of storage used beyond first 25 free GB-Months usage_start_date | 2017-02-07 03:00:00 usage_end_date | 2017-02-07 04:00:00 usage_quantity | 6e-08 blended_rate | 0.24952229400 blended_cost | 0.00000001000 unblended_rate | 0.25000000000 unblended_cost | 0.00000001000 resource_id | arn:aws:dynamodb:us-west-2:012345:table/a-table statement_month | 2017-02-01
Это счёт на внушительную сумму $0,00000001, то есть одну миллионную цента, за хранение в базе DynamoDB единственной таблицы 7 февраля между 3:00 и 4:00 часами ночи. В обычный день наш CSV содержит примерно шесть миллионов таких записей. (К сожалению, большинство из них с более значительными суммами, чем одна миллионная цента).
Для переноса данных из S3 в Redshift мы используем инструмент awsdetailedbilling от Heroku. Это неплохо для начала, но у нас не было нормального способа связать конкретные затраты AWS с нашими продуктовыми направлениями (то есть использовался ли конкретный инстанс-час для интеграций или для хранилищ данных).
Более того, примерно 60% расходов приходится на долю EC2. Хотя это львиная часть расходов, но понять связь между инстансами EC2 и конкретными продуктовыми направлениями абсолютно невозможно только из того CSV, что генерирует AWS.
Есть важная причина, почему мы не могли определить продуктовые направления просто по названиям инстансов. Дело в том, что вместо запуска по одному процессу на хосте мы интенсивно используем ECS (Elastic Container Service) для размещения сотен контейнеров на хосте и значительно более интенсивного использования ресурсов.
К сожалению, счета Amazon содержат только расходы инстансов EC2, так что у нас не было никакой информации о расходах контейнеров, работающих на инстансе: сколько контейнеров было запущено в обычное время, какую часть пула мы использовали, сколько задействовали юнитов CPU и памяти.
Хуже того, нигде в CSV не отражена информация об автомасштабировании контейнеров. Чтобы добыть эти данные для анализа, пришлось написать собственный инструментарий для сбора информации. В следующих главах я подробнее расскажу, как работает этот конвейер.
Тем не менее, файл CSV от AWS предоставляет очень хорошие детальные данные об использовании сервиса, которые стали основой для анализа. Нужно только связать их с нашими продуктовыми направлениями.
Примечание: Эта проблема тоже никуда не денется. Биллинг по инстанс-часам будет становиться всё большей и большей заботой с точки зрения вопроса «На что я трачу свои деньги?», потому что всё больше компаний запускают кучу контейнеров на большом количестве инстансов, используя системы вроде ECS, Kubernetes и Mesos. Есть некая ирония в том, что сама Amazon испытывает точно такую проблему уже много лет, ведь каждый инстанс EC2 — это гипервизор Xen, который работает совместно с другими инстансами на одном и том же физическом сервере.
2. Данные о расходах из помеченных ресурсов AWS
Самые важные и уже готовые для обработки данные поступают от «помеченных» ресурсов AWS.
По умолчанию биллинговый CSV не содержит каких-либо тегов. Поэтому невозможно различить, как один инстанс EC2 или бакет ведёт себя по сравнению с другим.
Однако вы можете активировать некоторые метки, которые будут отображаться рядом с вашими расходами на каждую единицу, используя теги распределения затрат.
Эти теги официально поддерживаются многими ресурсами AWS, бакетами S3, таблицами DynamoDB и т.д. Чтобы отобразить теги распределения затрат в CSV, вы можете включить соответствующий параметр в консоли биллинга AWS. Через день или около того выбранный вами тег (мы выбрали
product_area) начнёт появляться как новая колонка рядом с соответствующими ресурсами в детализированном отчёте CSV. Если вы больше не предпринимали никаких оптимизаций, то можно сразу начать использование тегов распределения затрат для разметки своей инфраструктуры. Это по сути «бесплатная» услуга и не требует никакой инфраструктуры для работы.
После активации функции у нас возникло две задачи: 1) разметка всей существующей инфраструктуры; 2) проверка, что всех новые ресурсы автоматически будут помечены тегами.
Разметка существующей инфраструктуры
Проставить теги для существующей инфраструктуры довольно легко: для каждого конкретного продукта AWS запрашиваете в Redshift список ресурсов с наибольшими расходами — и тормошите людей в Slack до тех пор, пока они не скажут, как эти ресурсы нужно пометить. Заканчиваете процедуру, когда пометите 90% или больше ресурсов по стоимости.
Однако для гарантии, что новые ресурсы станут помечены, требуется некоторая автоматизация и инструментарий.
Для этого мы используем Terraform. В большинстве случаев конфигурация Terraform поддерживает добавление тех же тегов распределения затрат, которые добавляются через консоль AWS. Вот пример конфигурации Terraform для бакета S3:
resource "aws_s3_bucket" "staging_table" {
bucket = "segment-tasks-to-redshift-staging-tables-prod"
tags {
product_area = "data-analysis" # this tag is what shows up in the billing CSV
}
}Хотя Terraform обеспечивает базовую конфигурацию, мы хотели убедиться, что при каждой записи нового ресурса
aws_s3_bucket в файл Terraform проставляется тег product_area.К счастью, конфигурации Terraform написаны на HCL (Hashicorp Configuration Language), в котором есть парсер конфигурации с сохранением комментариев. Так что мы написали функцию проверки, которая проходит по всем файлам Terraform и ищет подлежащие разметке ресурсы без тега
product_area.func checkItemHasTag(item *ast.ObjectItem, resources map[string]bool) error {
// looking for "resource" "aws_s3_bucket" or similar
t := findS3BucketDeclaration(item)
tags, ok := hclchecker.GetNodeForKey(t.List, "tags")
if !ok {
return fmt.Errorf("aws_s3_bucket resource has no tags", resource)
}
t2, ok := tags.(*ast.ObjectType)
if !ok {
return fmt.Errorf("expected 'tags' to be an ObjectType, got %#v", tags)
}
productNode, ok := hclchecker.GetNodeForKey(t2.List, "product_area")
if !ok {
return errors.New("Could not find a 'product_area' tag for S3 resource. Be sure to tag your resource with a product_area")
}
}Мы наладили непрерывную интеграцию для репозитория с конфигами Terraform, а затем добавили эти проверки, так что тесты не пройдут, если встретится подлежащий разметке ресурс без тега
product_area. Это не идеально — тесты привередливы, а люди технически имеют возможность создавать непомеченные ресурсы напрямую в консоли AWS, но система достаточно хорошо работает для данного этапа. Самый простой способ описания новой инфраструктуры — делать это через Terraform.
Обработка данных из тегов распределения затрат
После разметки ресурсов их учёт представляет собой простую задачу.
- Найти теги
product_areaдля каждого ресурса, чтобы соотнести идентификаторы ресурсов с тегамиproduct_area. - Сложить расходы всех ресурсов.
- Сложить расходы по продуктовым направлениям и записать результат в сводную таблицу.
SELECT sum(unblended_cost)
FROM awsbilling.line_items
WHERE statement_month = $1 AND product_name='Amazon DynamoDB';У вас может появиться желание разбить расходы по сервисам AWS — у нас есть две отдельные таблицы, одна по продуктовым направлениям Segment, а вторая по сервисам AWS.
С помощью обычных тегов распределения затрат AWS мы сумели распределить примерно 35% расходов.
Анализ забронированных инстансов
Такой подход хорошо для размеченных, доступных инстансов. Но в некоторых случаях AWS берёт авансовую оплату за «бронирование». Бронирование гарантирует доступность определённого объёма ресурсов в обмен на авансовую оплату по сниженным тарифам.
В нашем случае получается, что несколько крупных платежей из прошлогоднего декабрьского счёта CSV нужно распределить по всем месяцам текущего года.
Чтобы корректно учесть эти расходы, мы решили использовать данные по раздельным (unblended) расходам за данный период. Запрос выглядит примерно так:
select unblended_cost, usage_start_date, usage_end_date
from awsbilling.line_items
where start_date < '2017-04-01' and end_date > '2017-03-01'
and product_name = 'Amazon DynamoDB' and resource_id = '';Расходы на подписку оформляются в виде "$X0000 of DynamoDB", так что их невозможно приписать к какому-то ресурсу или продуктовому направлению.
Вместо этого мы складываем расходы на каждый ресурс по продуктовым направлениям, а затем распределяем расходы на подписку в соответствии с долей в процентах. Если на хранилища данных ушло 60% расходов EC2, то мы предполагаем, что из абонентского аванса на эти цели тоже ушло 60%.
Это тоже не идеально. Если большая часть вашего счёта берётся из авансового платежа, такую стратегию распределения исказят небольшие изменения в текущих расходах на работающие инстансы. В этом случае вы захотите распределять расходы исходя из информации по использованию каждого ресурса, а её сложнее суммировать, чем расходы.
3. Данные о расходах из непомеченных ресурсов AWS
Хотя разметка инстансов и таблиц DynamoDB — это отлично, но другие ресурсы AWS не поддерживают теги распределения расходов. Эти ресурсы потребовали создания заумного рабочего процесса в стиле Руба Голдберга для успешного получения данных о затратах и перенесения их в Redshift.
Две самых больших группы непомеченных ресурсов в нашем случае — это ECS и EBS.
ECS
Система ECS непрерывно увеличивает и уменьшает масштаб работы наших сервисов, в зависимости от количества контейнеров, которые нужны каждому из них для работы. Она также отвечает за перебалансировку и упаковку в контейнеры в большом количестве отдельных инстансов.
ECS запускает на хостах контейнеры в зависимости от количества «зарезервированных CPU и памяти». Каждый сервис сообщает, сколько ему нужно частей CPU, а ECS или разместит новые контейнеры на хосте с достаточным объемом ресурсов, или масштабирует количество инстансов, чтобы добавить необходимые ресурсы.
Ни одно из этих действий ECS напрямую не отражается в биллинговом отчёте CSV — но ECS по прежнему отвечает за запуск автомасштабирования для всех наших инстансов.
Проще говоря, мы хотели понять, какую «часть» конкретной машины использует каждый контейнер, но отчёт CSV даёт нам только разбивку «целого юнита» по инстансу.
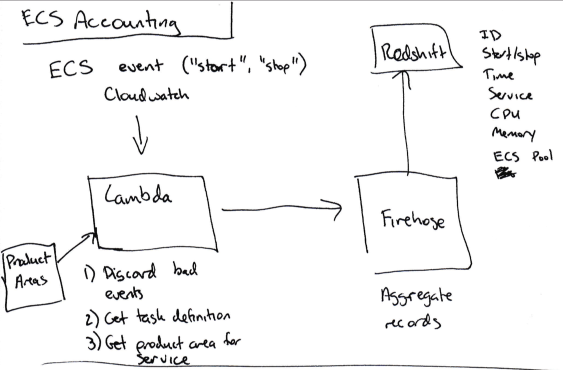
Чтобы определить расходы на конкретный сервис, мы разработали собственный алгоритм:
- Установить подписку Cloudwatch на каждое событие, когда стартует или останавливается задача ECS.
- Отправить релевантные данные этого события (названия сервиса, использование CPU/памяти, старт или остановка, идентификатор инстанса EC2) в Kinesis Firehose (для накопления отдельных событий).
- Отправить данные из Kinesis Firehose в Redshift.
Как только все данные о старте/остановке/размере поступили в Redshift, мы умножаем количество времени, которые эта задача работала в ECS (скажем, 120 секунд) на количество юнитов CPU, которые она использовала на данной машине (до 4096 — эта информация доступна в описании задачи), чтобы вычислить количество CPU-секунд для каждого сервиса, работавшего на инстансе.
Общие расходы инстанса из счёта затем делятся между сервисами в соответствии с количеством использованных CPU-секунд.
Это тоже не идеальный метод. Инстансы EC2 на работают всё время на 100% мощности, в то время как избыток в данный момент распределяется между всеми сервисами, работавшими на этом инстансе. Это может быть верным или неверным распределением избыточных расходов. Но (и здесь вы можете узнать общую тему этой статьи) этого достаточно.
Вдобавок мы хотим соотнести каждый сервис ECS с соответствующим продуктовым направлением. Однако мы не можем разметить их в AWS, потому что ECS не поддерживает теги распределения расходов.
Вместо этого мы добавляем ключ
product_area в модуль Terraform для каждого сервиса ECS. Этот ключ не ведёт ни к каким метаданным, отправляемым в AWS, но он заполняет скрипт, который считывает ключи product_area для всех сервисов.Этот скрипт затем на каждую новую отправку данных публикует в основную ветку для DynamoDB карту соотнесения названий сервисов и продуктовых направлений в кодировке base64.
Наконец, затем наши тесты проверяют каждый новый сервис, который снабжён тегом о продуктовом направлении.
EBS
Elastic Block Storage (EBS) тоже занимает значительную часть нашего счёта. Тома EBS обычно подключены к инстансам EC2, и для учёта имеет смысл учитывать расходы на тома EBS вместе с соответствующими инстансами EC2. Однако биллинг CSV от AWS не показывает, какой том EBS подключён к какому инстансу.
Для этого мы опять использовали Cloudwatch — оформили подписку на события типа «подключение тома» и «отключение тома», а затем регистрировали связи EBS => EC2 в таблице DynamoDB.
Затем мы добавляем расходы томов EBS к расходам соответствующих инстансов EC2, прежде чем учитывать расходы ECS.
Объединение данных между аккаунтами
До сих пор мы обсуждали все наши расходы в контексте одного аккаунта AWS. Но на самом деле это не отражает нашу реальную конфигурацию AWS, которая распределяется между разными физическими аккаунтами AWS.
Мы используем операционный аккаунт (Ops) не только для консолидации данных и биллинга по всем аккаунтам, но и чтобы обеспечить единую точку доступа инженерам для осуществления изменений в продакшне. Мы отделяем этап Stage от продакшна — так можно проверить, что вызов API, например, на удаление таблицы DynamoDB, безопасно обрабатывается с соответствующими проверками.
Среди этих аккаунтов по расходам доминирует аккаунт Prod, но расходы аккаунта Stage тоже составляют значительную часть общего счёта AWS.
Сложности начинаются, когда нужно записать данные о сервисах ECS из аккаунта Stage в кластер Redshift на продакшне.
Чтобы получить возможность записи «между аккаунтами», мы должны позволить обработчикам подписок Cloudwatch взять на себя роль в продакшне для записи в Firehose (для ECS) или DynamoDB (для EBS). Это непросто сделать, потому что нужно добавить корректные разрешения правильной функции в аккаунте Stage (sts.AssumeRole) и в аккаунте Prod, а любая ошибка приведёт к путанице разрешений.
Для нас это значит, что код для учёта не работает на аккаунте Stage, а вся информация заносится в базу данных на аккаунте Prod.
Хотя на аккаунте Stage можно добавить второй сервис, который подписан на те же данные, но не записывает их, мы решили, что в этом случае есть вероятность столкнуться со случайными проблемами в коде учёта Stage.
Выдача статистики
Наконец-то у нас есть всё для правильного анализа данных:
- Размеченные ресурсы в CSV.
- Данные, когда каждое событие ECS стартует и останавливается.
- Привязка названий сервисов ECS к соответствующим продуктовым направлениям.
- Привязка томов EBS к подключённым инстансам.
Чтобы выдать это всё сотрудникам аналитической группы, я разбил данные по сервисам AWS. Для каждого сервиса AWS я суммировал продуктовые направления Segment и их расходы по этому сервису AWS.
Эти данные выдаются в трёх разных таблицах:
- Общие расходы на каждый сервис ECS в заданный месяц.
- Общие расходы на каждое продуктовое направление в заданный месяц.
- Общие расходы на (сервис AWS, продуктовое направление Segment) а заданный месяц. Например, «Направление хранилищ данных потратило $1000 на DynamoDB в прошлом месяце».
Общие расходы для отдельных продуктовых направлений выглядят примерно так:
month | product_area | cost_cents -------------------------------------- 2017-03-01 | integrations | 500 2017-03-01 | warehouses | 783
А расходы по сервисам AWS в сочетании с продуктовыми направлениями Segment выглядят так:
month | product_area | aws_product | cost_cents ---------------------------------------------------- 2017-03-01 | integrations | ec2 | 333 2017-03-01 | integrations | dynamodb | 167 2017-03-01 | warehouses | redshift | 783
Для каждой из этих таблиц у нас есть итоговая таблица с итоговыми цифрами за каждый месяц и дополнительная сводная таблица, которая каждый день обновляет данные за текущий месяц. Уникальный идентификатор в сводной таблице соответствует каждому проходу, так что вы можете свести воедино счёт AWS, найдя все строки для данного прохода.
Итоговые данные эффективно выполняют роль нашего золотого «источника истины», который используется для высокоуровневых метрик и отчётности перед руководством. Сводные таблицы используются для мониторинга текущих затрат в течение месяца.
Примечание: AWS выдаёт «итоговый» счёт только через несколько дней после окончания месяца, так что любая логика, которая помечает биллинговые записи как окончательные по окончании месяца, будет некорректной. Вы можете узнать итоговый счёт Amazon, когда в поле
invoice_id в файле CSV появится целое число, а не слово “Estimated”.Несколько последних советов
Прежде чем завершить, мы поняли, что во всём процессе есть некоторых мест, где небольшая подготовка и знание могли бы сэкономить нам много времени. Без какой-либо сортировки вот эти места:
- До скриптов, которые агрегируют данные или копируют их из одного места в другое, редко доходят руки разработчиков — и их работа часто недостаточно хорошо отслеживается. Например, один наш скрипт копировал данные биллинга CSV из одного бакета S3 в другой, но вылетал с ошибкой 27-28 числа каждого месяца, потому что обработчику Lambda во время копирования не хватало памяти, когда файл CSV становился достаточно большим. Нам потребовалось некоторое время, чтобы это заметить, потому что в базе Redshift много данных и они выглядят правдоподобными по каждому месяцу. С тех пор мы добавили мониторинг функции Lambda, чтобы гарантировать выполнение скрипта без ошибок.
- Убедитесь, что эти скрипты хорошо задокументированы, особенно с указанием информации, как они задействуются и какая нужна конфигурация. Поставьте ссылки на исходный код в других местах, где упоминаются эти скрипты. Например, во всех местах, где вы запрашиваете данные из бакета S3, поставьте ссылку на скрипт, который записывает данные в бакет. Также подумайте о записи файла README в рутовой директории бакета S3.
- Запросы Redshift могут выполняться по-настоящему медленно без оптимизации. Посоветуйтесь со специалистом по Redshift в своей компании и подумайте, какие запросы вам нужны, перед созданием новых таблиц в Redshift. В нашем случае был пропущен правильный ключ сортировки в таблицах биллинга CSV. После создания таблицы вы уже не сможете добавить ключи сортировки, так что если не позаботиться об этом заранее, то придётся создавать вторую таблицу с правильными ключами, переправлять туда операции записи, а затем копировать все данные.
- Использование правильных ключей сортировки уменьшило время выполнения этапа запросов при проходе для сводной таблицы примерно с 7 минут до 10-30 секунд.
- Изначально мы планировали запускать скрипты для обновления сводной таблицы по расписанию — Cloudwatch может запускать функцию AWS Lambda несколько раз в день. Однако размер прохода был непостоянным (особенно когда включал в себя запись в Redshift) и превышал максимальный таймаут Lambda, так что вместо этого мы перенесли их на сервис ECS.
- Изначально мы выбрали для кода обновления сводной таблицы JavaScript, потому что он работает на Lambda и большинство скриптов в нашей компании написаны на JavaScript. Если бы я знал, что придётся переходить на ECS, я бы выбрал другой язык с лучшей поддержкой сложения 64-битных чисел, параллелизации и отмены работы.
- Каждый раз, когда вы начинаете писать новые данные в Redshift, изменяете данные (скажем, добавляете новые колонки) или исправляете ошибки целостности в отношении анализа данных, дописывайте примечание в файл README с указанием даты и информации об изменениях. Это будет исключительно полезно для сотрудников вашей группы анализа данных.
- Смешанные расходы (blended) не слишком полезны при таком типе анализа — придерживайтесь несмешанных расходов (unblended). Они показывают, какую конкретно плату AWS берёт за данный ресурс.
- В отчёте CSV есть 8 или 9 строк, где Amazon не указывает название сервиса. Они представляют собой общую сумму счёта, но откажитесь от любых попыток суммировать несмешанные расходы за данный месяц. Убедитесь в том, чтобы эти цифры исключены из суммирования расходов.
Практический результат
Получить наглядный счёт AWS непросто. Это требует большого объёма работы — как для разработки и настройки инструментария, так и для выявления дорогих ресурсов на AWS.
Самая главная победа, которой мы добились, — это возможность простого непрерывного прогнозирования затрат вместо периодических «одноразовых анализов».
Для этого мы автоматизировали весь сбор данных, реализовали поддержку тегов в Terraform и нашей системе непрерывной интеграции и объяснили всем сотрудникам группы разработки, как правильно помечать тегами свою инфраструктуру.
Все наши данные не лежат мёртвым грузом в PDF, а непрерывно обновляются в Redshift. Если мы хотим ответить на новые вопросы и сгенерировать новые отчёты, то мгновенно получаем результаты с помощью SQL-запроса.
Вдобавок мы экспортировали все данные в формат Excel, где можем точно рассчитать, во сколько нам обойдётся новый клиент. И мы также можем увидеть, если на какой-то сервис или продуктовое направление внезапно начинает уходить намного больше денег — мы видим это до того, как незапланированные расходы нанесут удар по финансовому состоянию компании.
Хотя эта статья не соответствует в точности вашей инфраструктуре, всё-таки надеемся, что наша история будет полезна и поможет лучше разобраться в своих расходах и управлять ими по мере масштабирования своего бизнеса!
