Представляю, Вам, перевод статьи одного из разработчиков PHP, в том числе версии 7 и выше, сертифицированного инженера ZendFramework. В данный момент работает в SensioLabs и большую часть занимается низкоуровневыми вещами, в том числе программированием в С под Unix. Оригинал статьи здесь.
Я планирую в будущем писать технические статьи о PHP, связанные с глубоким пониманием памяти. Мне нужно, чтобы мои читатели имели такие знания, которые им помогут понять некоторые концепции дальнейшего объяснения. Для того, чтобы ответить на этот вопрос, нам придется перемотать время назад в 1960-е года. Я собираюсь объяснить вам, как работает компьютер, а точнее, как происходит доступ к памяти в современном компьютере, а затем вы поймете, из-за чего происходит это странное сообщение об ошибке — Segmentation Fault.
То, что вы будете читать здесь, краткое изложение основ дизайна компьютерной архитектуры. Я не буду заходить слишком далеко, если это не нужно, и буду использовать хорошо известные формулировки, так что, кто работает с компьютером каждый день может понять такие важные понятия о том, как работает ПК. Существует много книг о компьютерной архитектуре. Если вы хотите углубиться дальше в этой теме, я предлагаю вам достать некоторые из них и начать читать. Кроме того, откройте исходный код ядра ОС и изучите его, будь то ядро Linux, или любое другое.
Еще в то время, когда компьютерами были огромные машины, тяжелее тонны, внутри вы могли бы найти один процессор с чем-то вроде 16Kb оперативной памяти (RAM). Не будем углубляться дальше =) В этот период компьютер стоил примерно $ 150 000 и мог выполнить ровно одну задачу в момент времени. Если бы мы в то время нарисовали схему его памяти, то архитектура выглядела следующим образом:
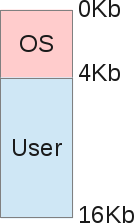
Как вы можете видеть, размер памяти 16Кб, и состоит из двух частей:
Роль операционной системы заключалась в управлении прерываниями центрального процесса аппаратными средствами. Таким образом, операционная система нуждалась в памяти для себя, чтобы копировать данные с устройства и работать с ними (режим PIO). Для предоставления данных на экран тоже была необходима основная память, так как видеоадаптеры имели от нуля до нескольких килобайт памяти. И наша сольная программа использовала память ОС для достижения поставленных задач.
Но одна из главных проблем такой модели заключается в том, что компьютер (стоимостью $ 150 000) мог выполнять только одну задачу единовременно, и эта задача ужасно долго выполнялась: целые дни, чтобы обработать несколько Кб данных. По такой огромной цене явно не представляется возможным купить несколько машин, чтобы выполнить несколько процедур одновременно. Так что люди пытались распределить ресурсы машины. Это было время рождения многозадачности. Имейте в виду, что тогда было ещё очень рано говорить о многопроцессорных ПК. Как мы можем заставить одну машину с одним процессором, и на самом деле решить несколько различных задач? Ответ на этот вопрос — планирование. Пока один процесс занят в ожидании ввода / вывода (ожидает прерывание), процессор может запустить другой процесс. Мы не будем говорить о планировании на всех уровнях (слишком широкой теме), только о памяти. Если машина может выполнять несколько задач, один процесс за другим, то это означает, что память будет распределяться примерно таким образом:

Обе, задачи А и B, сохраняются в оперативной памяти, так как копировать их туда и обратно на диск — слишком ресурсозатратный процесс. Данные должны оставаться в оперативной памяти на постоянной основе, так как их соответствующие задачи по-прежнему работают. Планировщик дает некоторое время процессора, то задаче А, то B, и т.д… каждый раз предоставляя доступ к её области памяти. Но подождите, здесь есть проблема. Когда один программист будет писать код задачи B, он должен знать адреса границ памяти. Например, задача В будет располагаться с 10Kb памяти до 12Кб. Поэтому каждый адрес в программе должен жестко записан именно в эти пределы. Если машина затем будет выполнять ещё 3 задачи, то адресное пространство будет разделено на большее количество областей, и границы памяти задачи В сдвинутся. Программисту пришлось бы переписать свою программу, чтобы использовать меньше памяти, и переписывать каждый адрес указателя памяти.
Здесь очевидна так же другая проблема: что, если задача B получит доступ к памяти задачи А? Это легко может произойти, потому что, когда вы манипулируете указателями, небольшая ошибка при вычислении приводит к совершенно другому адресу. Это может испортить данные задачи А (перезаписать их). Также существует проблема безопасности, что если задача А работает с очень чувствительными данными? Нет никакого способа, чтобы предотвратить чтение задачей B некоторой области памяти задачи А. И последнее: что, если задача B по ошибке перезапишет память ОС? Например, память ОС от 0Kb до 4Kb, в случае если задача B перепишет этот участок, то операционная система наверняка потерпит крах.
Таким образом, нужна помощь операционной системы и аппаратного обеспечения, чтобы получить возможность запускать несколько задач находящиеся в памяти. Один из способов помочь, является создание того, что называется адресное пространство. Адресное пространство является абстракцией памяти, которую операционная система даст процессу, и эта концепция является абсолютно фундаментальной, так как в настоящее время каждая часть компьютера, которую вы встретите в вашей жизни, разработана таким образом. Сейчас не существует никакой другой модели (в гражданском обществе, армия может сохранять тайну).
Адресное пространство содержит все задачи (процессы) которые необходимо запустить:
Адресное пространство делится следующим образом:
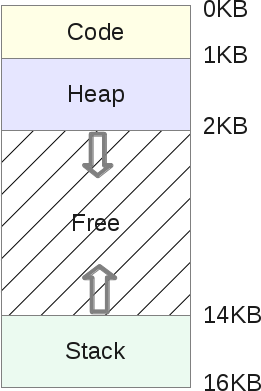
Так как стек и куча являются расширяемыми зонами, они расположены на противоположных местах в одном адресном пространстве: стек будет расти вверх, а куча вниз. Они оба могут свободно расти, каждый в направлении другого. ОС должна просто проверять, чтобы зоны не перекрывались, правильно используя виртуальное пространство.
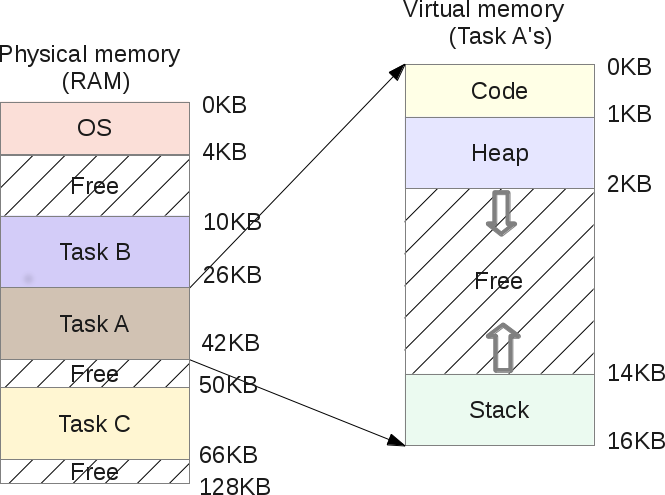
Если задача А получила адресное пространство, такое, которое мы видели, так же как и задача B. То как мы можем разместить их в памяти? Это кажется странным, но адресное пространство задачи А начинается от 0KB до 16Kb, так же как и задачи B. Хитрость заключается в создании виртуальной среды. На самом деле картина размещения А и В в памяти:
Когда задача А попытается получить доступ к памяти в своем адресном пространстве, например индекс 11К, где-то в своем собственном стеке, операционная система выполнит хак и на самом деле загрузит индекс памяти 1500, потому что индекс 11K принадлежит задаче B. На самом деле, всё адресное пространство каждой программы в памяти — это просто виртуальная память. Каждая программа, работающая на компьютере, обращается к виртуальным адресам, с помощью некоторых аппаратных чипов ОС будет обманывать процесс, когда он будет пытаться получить доступ к любой зоне памяти.
ОС виртуализирует память и гарантирует, что любая задача не сможет получить доступ к памяти, которой не владеет. Виртуализация памяти позволяет изолировать процесс. Задача А больше не может получить доступ к памяти задачи B и не сможет получить доступ к памяти ОС. И все это полностью прозрачно для задач на уровне пользователя, благодаря тоннам сложного кода ядра ОС. Таким образом, операционная система обслуживает каждый запрос памяти процесса. Это работает очень эффективно — даже если запущено слишком много различных программ. Для достижения этой цели процесс получает помощь от аппаратного обеспечения, главным образом от процессора и некоторых электронных компонентов вокруг него, таким как блок управления памятью (MMU ). MMU появился в начале 70-х годов, вместе с IBM, как отдельные чипы. Сейчас они встраиваются непосредственно в наши чипы CPU и являются обязательными для любой современной ОС для запуска. На самом деле, операционная система не выполняет тонны операций, а полагается на некоторые аппаратные особенности поведения, которые облегчат доступ к памяти.
Вот небольшая программа на C, показывающая некоторые адреса памяти:
На моей LP64 x86_64 машине он показывает:
Мы можем видеть, что адрес стека находится намного выше адреса кучи, а код расположен ниже стека. Но каждый из этих 3-х адресов являются подделками: в физической памяти, по адресу 0x7ffe60a1465c точно не расположено целое число 3. Помните, что каждая программа пользователя манипулирует адресами виртуальной памяти, тогда как программы уровня ядра, таких как само ядро ОС (или аппаратный код драйвера) могут манипулировать физическими адресами RAM.
Адресная трансляция — это формулировка, за которой скрывается некая магическая техника. Аппаратное обеспечение (ММУ)транслирует каждый виртуальный адрес программы уровня пользователя в правильный физический адрес. Таким образом, операционная система помнит для каждой задачи соответствие между его виртуальными адресами и физическими. И это является сложной задачей. Операционная система управляет всей памятью задач на уровне пользователя для каждого требования доступа к памяти, обеспечивая тем самым полную иллюзию процессу. Таким образом, операционная система преобразует всю физическую память в полезную, мощную и простую абстракцию.
Давайте подробно рассмотрим простой сценарий:
Когда процесс запускается, операционная система бронирует фиксированную область физической памяти, скажем, 16KB. Затем сохраняет начальный адрес этого пространства в специальную переменную, называемую базой. Потом устанавливает другую специальную переменную, называемую границами (или пределом) ширины пространства — 16КB. Далее операционная система сохранит эти два значения в таблице процессов, называемой PCB (Process Control Block).
А вот как выглядит процесс виртуального адресного пространства:
А вот его физическое изображение:

ОС решила сохранить его в физической памяти в диапазоне адресов от 4K до 20K. Таким образом, базовый адрес устанавливается в 4K, а предел установлен на 4 + 16 = 20К. Когда этот процесс планируется (учитывая некоторое время процессора), операционная система считывает обратно предельные значения из PCB и копирует их в конкретные регистры процессора. Когда CPU во время работы попытается загрузить, например, виртуальный адрес 2K (что-то в его куче), CPU добавит этот адрес базы, полученный от операционной системы. Таким образом, процесс доступа памяти приведет к физическому местоположению 2K + 4K = 6К.
Физический адрес = виртуальный адрес + предел
Если полученный физический адрес (6К) находится вне границ (-4K | 20K-), это означает, что процесс попытался получить доступ к неправильному участку памяти, которым он не владеет. Процессор сгенерирует исключение, и поскольку в ОС есть обработчик исключений для этого события, ОС активируется процессором и будет знать, что исключение памяти только что произошло на CPU. Затем ОС по умолчанию передаст сигнал поврежденному процессу “SIGSEGV”. Ошибка сегментации, которая по умолчанию (это может быть изменено) завершит задачу с сообщением — “Произошел сбой в работе с недопустимым доступом к памяти”.
Еще лучше, если задача А не запланирована, это означает, что она извлекается из CPU, так как планировщик попросил запустить другую задачу (скажем, задачу B). При выполнении задачи B ОС может свободно переместить всё физическое адресное пространство задачи A. Операционная система часто получает время процессора при выполнении пользовательских задач. Когда завершается последний системный вызов, управление ЦП возвращается к ОС, и до выполнения системного вызова ОС может делать все, что захочет, управляя памятью, перемещая все пространство процесса в различные физические слоты карт памяти.
Это относительно просто: операционная система перемещает область 16K в другую 16K свободного пространства, и просто обновляет базовые и связанные переменные задачи A. Когда задача будет возобновлена и передана CPU, процесс преобразования адреса по-прежнему будет работать, но это не приведет к тому же физическому адресу, как раньше.
Задача А не заметила ничего, с её точки зрения, её адресное пространство по-прежнему начинается от 0К до 16К. Операционная система и аппаратное обеспечение MMU берут полный контроль над каждым доступом к памяти для задачи А, давая ей полную иллюзию. Программист задачи A манипулирует своими разрешенными виртуальными адресами, от 0 до 16, а MMU будет заботиться о позиционировании в физической памяти.
Образ памяти после перемещения будет выглядеть следующим образом:
В настоящее время программист больше не должен задаваться вопросом, где его программа находиться в оперативной памяти, если другая задача работает рядом с его собственной, и какими адресами манипулировать. Это делает сама ОС вместе с очень производительным и умным аппаратным средством — “Блок управления памяти” (MMU).
Обратите внимание на внешний вид слова «сегментация» — мы близки к объяснению почему происходят ошибки сегментации. В предыдущей главе мы объяснили о трансляции и перемещении памяти, но модель, которую мы использовали имеет свои недостатки:
Мы предположили, что каждое виртуальное адресное пространство фиксируется шириной 16Kb. Очевидно, что это не так в действительности. Операционная система должна поддерживать список физической памяти свободных слотов (шириной 16 Kb), чтобы иметь возможность найти место для любого нового процесса с просьбой начать или переместить запущенный процесс. Как сделать это эффективно, чтобы не замедлить всю систему? Как вы можете видеть, каждый процесс занимает участок памяти 16 Kb, даже если процесс не использует всё своё адресное пространство, что очень вероятно. Эта модель явно тратит много памяти, процесс потребляет1KB памяти, а его участок памяти в физической памяти 16Кб. Такие отходы называют внутренней фрагментацией: память зарезервирована, но никогда не используется.
Для решения некоторых из этих проблем, мы собираемся погрузиться в более сложную организацию памяти в ОС — сегментацию. Сегментацию легко понять: мы расширяем идею «базы и границ» трех логических сегментов памяти: кучи, кода и стека; каждого процесса — вместо того, чтобы просто рассматривать образ памяти в качестве одного уникального объекта.
При такой концепции, память между стеком и кучей больше не тратится впустую. Вот так:

Теперь легко заметить, что свободное пространство в виртуальной памяти для задач А больше не выделяется в физической памяти, использование памяти становится гораздо более эффективным. Единственным отличием является то, что в настоящее время для любой задачи, ОС должна запоминать не одну пару баз/границ, а три: по одной паре для каждого типа сегмента. ММУ заботится о переводе, так же, как и раньше, и теперь поддерживает, 3 базовых величин, и 3 границ.
Например, здесь, куча задачи A имеет базу 126K и границы 2К. Затем задача просит доступ к виртуальному адресу 3KB, в куче; физический адрес 3Kb — 2Кб (начало кучи) = 1Kb + 126K (смещение) = 127K. 127K находится перед 128К — это правильный адрес памяти, который может быть выполнен.
Сегментирование физической памяти не только решает проблему свободной виртуальной памяти, освобождая больше физической памяти, но она также позволяет разделить физические сегменты с помощью различных процессов виртуальных адресных пространств. Если запустить дважды ту же задачу, задачу А например, сегмент кода точно такой же: обе задачи выполняют одни и те же команды процессора. Обе задачи будут использовать свой собственный стек и кучу, обращаться к своим собственным наборам данных. Неэффективно дублировать сегмент кода в памяти. ОС теперь может разделить его и сэкономить еще больше памяти. Например так:
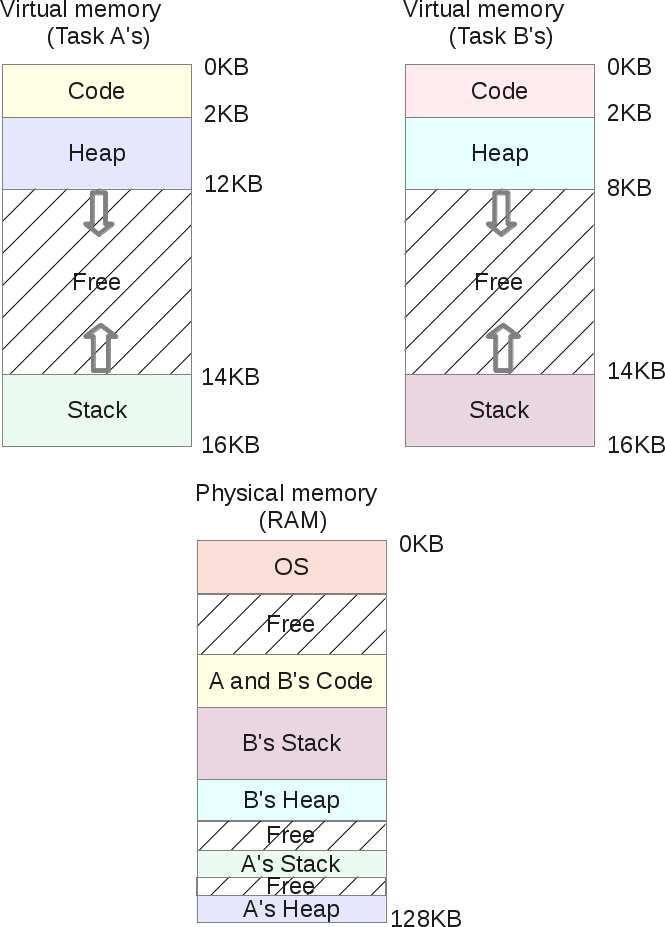
На картинке выше, А и В имеют свою собственную область кода в их соответствующем виртуальном пространстве памяти, но под капотом. Операционная система разделяет эту область в одних и тех же физических сегментах памяти. Обе задачи А и В абсолютно не видят этого, для них обеих — они владеют своей памятью. Для достижения этой цели ОС должна реализовать еще одну особенность: бит защиты сегмента. ОС будет для каждого физического сегмента создавать, регистрировать границы / пределы для правильной работы блока MMU, но она также зарегистрирует флаг разрешения.
Поскольку код не является изменяемым, сегменты кода все созданы с флагом разрешения RX. Процесс может загрузить эту область памяти для выполнения, но любой процесс, попытавшийся писать в эту область памяти, будет завершен ОС. Остальные два сегмента: куча и стек являются RW, процессы могут читать и писать от своего собственного стека / кучи, но они не могут выполнять код из него (это предотвращает недостатки безопасности программы, где плохой пользователь может захотеть повредить кучу или стек, чтобы ввести код для запуска, которому будет доступно ядро ОС. Это невозможно, так как куча и стек сегментов часто не являются исполняемыми. Обратите внимание, что это было не всегда, так как требует дополнительной поддержки аппаратного обеспечения для эффективной работы, это называется «бит NX» под процессором Intel). Сегменты памяти разрешений изменяемы во время выполнения: задача может потребовать mprotect () от ОС. Эти сегменты памяти отчетливо видны под Linux, используйте утилиты /proc/{pid}/maps или /usr/bin/pmap
Ниже приведен пример для PHP:
Здесь мы детально видим все отображения памяти. Адреса являются виртуальными и отображают их разрешения области памяти. Как мы можем видеть, каждый общий объект (.so) отображается в адресное пространство как несколько отображений (вероятно кода и данных), и области кода являются исполнимыми, а под капотом они разделяются в физической памяти между каждым процессом, отображающим такой общий объект в его собственное адресное пространство…
Самое большое преимущество разделяемых объектов под Linux (и Unix) — это экономия памяти. Возможно также создать общую зону, ведущую к общему физическому сегменту памяти, с помощью системного вызова mmap(). Буква 's', появившаяся рядом с этой областью, означает “разделяемая”.
Мы видели, что сегментация решает проблему не используемой виртуальной памяти. Когда процесс не использует некоторый объем памяти, этот процесс не отображается в физическую память благодаря сегментам, которые соответствуют выбранной памяти. Тем не менее, это не совсем верно. Что делать, если процесс требует 16Kb кучи? ОС, скорее всего, создаст сегмент физической памяти размером 16КБ. Но если пользователь затем освобождает 2Кб такой памяти? Тогда, ОС должна уменьшить сегмент 16Кб до 14kb. Что делать, если теперь программист спрашивает 30Kb кучи? Старый сегмент 14Kb теперь должен вырасти до 30 КБ, но может ли он это сделать? Другие сегменты теперь могут окружать наш сегмент 14kb, препятствуя его росту. Тогда ОС придется искать свободное пространство 30 КБ, а затем перемещать сегмент.

Большая проблема с сегментами в том, что они приводят к очень фрагментированной физической памяти, потому что они продолжают расти, поскольку пользовательские задачи запрашивают и освобождают память. Операционная система должна поддерживать список свободных кусочков памяти и управлять ими.
Иногда, ОС путем суммирования всех свободных сегментов получает некоторое доступное пространство, но так как оно не соприкасается, она не может использовать это пространство и должна отказать требованию памяти от процессов, даже если существует пространство в физической памяти. Это очень плохой сценарий. Операционная система может попытаться сжать память путем слияния всех свободных участков в один большой кусок, который можно было бы использовать в будущем, чтобы удовлетворить запрос памяти.
Но такой алгоритм уплотнения сложен для CPU, и в это время ни один пользовательский процесс не сможет получить CPU: операционная система полностью загружена реорганизацией своей физической памяти, таким образом, система становится непригодной для использования. Сегментация памяти решает множество проблем управления памятью и многозадачности, но она также показывают реальные недостатки. Таким образом, существует необходимость в расширении возможностей сегментации и исправлении этих недостатков. Отсюда образовалось ещё одно понятие — “пагинация памяти”.
Пагинация страниц памяти разделяет некоторые концепции сегментации памяти и пытается решить её проблемы. Мы увидели, что основной проблемой сегментации памяти является то, что сегменты будут увеличиваться и уменьшаться очень часто, так как пользовательский процесс запрашивает и освобождает память. Иногда операционная система сталкивается с проблемой. Она не может найти большую область свободного места, чтобы удовлетворить запрос памяти пользовательского процесса, потому что физическая память стала сильно фрагментирована с течением времени: она содержит много сегментов разного размера по всей физической памяти, что приводит к сильно фрагментированной физической памяти.
Разбивка решает эту проблему с помощью простой концепции: что если для каждого физического распределения ядро будет выделять фиксированный размер? Страницы — это сегменты физической памяти фиксированного размера. Если операционная система использует распределения фиксированного размера, то намного легче управлять пространством, что в итоге сводит на нет фрагментацию памяти.
Давайте покажем пример еще раз, предполагая небольшое 16Кб виртуальное адресное пространство, чтобы облегчить представление:
С пагинацией мы не говорим о кучи, стеке или сегменте кода. Мы разделим весь процесс виртуальной памяти на зоны фиксированного размера: мы называем их страницы. На приведенном выше примере мы разделили адресное пространство в виде 4-х страниц, 4КБ каждый.
Затем мы делаем то же самое с физической памятью.
И операционная система просто хранит то, что называется «Таблица процессорных страниц» — связь между одной страницей виртуальной памяти процесса и базовой физической страницей (который мы называем «страница кадра»).
С помощью этого способа управления памятью больше нет проблем в свободном управлении пространством. Кадр страницы отображается (используется) или нет, ядру легко найти достаточное количество страниц, чтобы удовлетворить запрос памяти пользовательского процесса. Он просто хранит список свободных страниц кадров, а также просматривает его при каждом запросе памяти. Страница является наименьшей единицей памяти, которой ОС может управлять. Страница (на нашем уровне) является неделимой. Вместе со страницами каждому процессу прилагается таблица страниц, которая хранит адресные переводы. Переводы больше не используют значения границы, как это было с сегментацией, а использует «номер виртуальной страницы (VPN)» и «смещение» на этой странице.
Давайте покажем пример преобразования адресов с нумерацией страниц. Виртуальное адресное пространство размером 16Kb, т.е. нам нужно 14 бит для представления адреса (2 ^ 14 = 16Kb). Размер страницы 4 Кб, так что нам нужно 4kb (16/4), чтобы выбрать нашу страницу:

Теперь, когда процесс хочет загрузить, например, адрес 9438 (из 16384 возможностей), это дает 10.0100.1101.1110 в двоичной системе, что приводит к следующему:

То есть 1246й байт виртуальной страницы 2 ( «0100.1101.1110» го байта в «10» й странице). Теперь, операционная система должна искать эту страницу таблицы процессов, чтобы узнать на какой странице 2я карта. Согласно тому, что мы предложили, страница 2 — это 8К байт в физической памяти. Таким образом, виртуальный адрес 9438 приводит к физическому адресу 9442 (8k + 1246 смещение). Мы нашли наши данные! Как мы уже говорили, существует лишь одна таблица страниц для каждого процесса, поскольку каждый процесс будет иметь свои собственные переводы адреса, так же, как с сегментами. Но подождите, где эти таблицы страниц хранятся на самом деле? Угадайте ...: в физической памяти, да, а где же ей ещё быть? Если таблицы страниц сами хранятся в памяти, следовательно, для каждого доступа к памяти, память должна иметь доступ для извлечения VPN. Таким образом, со страницами один доступ к памяти равен фактически двум доступам к памяти: один для извлечения записи таблицы страниц, и один, чтобы получить доступ к «реальным» данным. Зная, что доступ к памяти медленный процесс, получаем — что это не лучшая идея.
Использование поискового вызова в качестве механизма ядра для поддержки виртуальной памяти может привести к высокой производительности накладных расходов. Измельчение адресного пространства на небольшие фиксированного размера единицы (страницы) требует большого количества информации о карте. Потому что информация о карте, как правило, хранится в физической памяти. Логический поиск подкачки требует дополнительного поиска в памяти для каждого виртуального адреса, сгенерированного программой. И тут опять приходят аппаратные средства, чтобы ускорить и помочь ОС. В пагинации, как и в сегментации, аппаратные средства помогают ядру ОС перевести адреса эффективным приемлемым способом. TLB является частью MMU, всего лишь простой кэш некоторых VPN переводов. TLB будет предотвращать доступ ОС к памяти от доступа к таблице страниц процесса, для получения физического адреса памяти из виртуальной. Аппаратное обеспечение MMU будет срабатывать на каждом виртуальном доступе к памяти, извлекая VPN из этого адреса, и выполняя поиск TLB, если он совпадает для этого конкретного VPN. Если он совпал, то он просто выполнил свою роль. Если он получает промах, то он будет искать таблицу страниц процесса, и если ссылка на память действительна, она обновит TLB, так что любой дальнейший доступ памяти этой страницы попадет в TLB.
Как и в любом кэше, вы чаще попадете, чем получите промах, так как ситуация промах вызывает страницу поиска, вследствие чего, доступ к памяти будет медленным. Вы догадаетесь об этом. Чем больше страниц, тем лучше TLB попадает, но тем больше неиспользуемого пространства вы будете иметь на каждой странице. Здесь должен быть найден компромисс. Современные ядра используют различные размеры страницы. Ядро Linux может использовать то, что называется «огромные страницы», страницы, размером 2Mb что больше традиционных 4Kb. Кроме того, информацию лучше хранить в смежных адресах памяти. Если вы сократите свои данные в памяти, то скорее всего будете страдать от пропусков TLB или от переполнения TLB. Это то, что называется Эффективность пространственной локальности TLB: Данные, находящиеся непосредственно рядом с вами, могут быть сохранены в той же физической странице, таким образом, получая выгоду из текущего доступа к памяти из TLB.
Для переключения контекста TLB хранит также то, что называется ASID в каждой из своих записей. Это идентификатор адресного пространства, который является чем-то вроде PID. Каждый запланированный процесс имеет свой собственный ASID, следовательно TLB может управлять любым адресом процесса без риска недействительных адресов из других процессов. Также, если пользовательский процесс попытается загрузить неверный адрес, адрес, скорее всего, не будет сохранен в TLB, следовательно произойдет промах в поиске в записи таблицы страниц процесса. Теперь адрес сохраниться, но с неверным битом. Под X86 каждый перевод использует 4 байта, таким образом, имеется много бит. И нередко можно найти действительный бит вместе с другими составными, такими как грязный бит, биты защиты, опорного бита и т.д.… Если запись помечена как недопустимая, ОС по умолчанию использует SIGSEGV, что приводит к «ошибке сегментации», даже если здесь мы больше не говорим о сегментах. Вы должны знать, что подкачка более сложна в современных ОС, чем я объяснил. Современные ОС, как правило, используют многоуровневые таблицы страниц, многостраничные размеры, а также важную концепцию, которую мы не будем объяснять. Страница выселения, известная как «swaping» (Процесс, когда ядро обменивает страницы памяти на дисковое пространство, чтобы эффективно использовать главную память и создать иллюзию для пользовательских процессов, что основная память не ограничена в пространстве).
Теперь вы знаете, что находится под сообщением «Ошибка сегментации». Операционная система использует сегменты для отображения виртуальной памяти в физической памяти. Когда процесс ядра хочет получить доступ к некоторой памяти, он выдает требование о том, чтобы MMU переводил на физический адрес памяти. Но если этот адрес не правильный, из пределов физического сегмента, или если права защиты сегмента не подходящие, то ОС по умолчанию посылает сигнал процессу, вызвавшего отказ: SIGSEGV, который имеет обработчик по умолчанию. Он убивает процесс и выводит сообщение: «Ошибка сегментации”. В других операционных системах (предполагаю) часто сообщение выглядит как „Общая неисправность защиты“. С Linux — нам повезло, мы имеем возможность доступа к исходному коду, здесь есть место исходного кода для X86 / 64 платформ, которое управляет ошибками доступа к памяти, так же здесь и SIGSEGV. Если вы заинтересованы в разработке сегментов для X86 / 64 платформ, вы можете посмотреть на их определение в ядре Linux. Вы также найдете интересный материал о пейджинговой памяти, которая поддерживает более длинный путь сегментирования памяти, чем использование классических сегментов. Мне понравилось писать эту статью, она перенесла меня в конец девяностых, когда я программировал свой первый CPU: Motorola 68HC11 с использованием C, VHDL и прямого монтажа. Я не программировал виртуальное управления памятью ОС, а использовал физические адреса напрямую (моему процессору не нужны такие сложные механизмы). Затем я подался в Web; но мои первые знания пришли от электроники, систем которые мы используем каждый день…
Ошибка Сегментации: (Компьютерная верстка памяти)
Несколько слов, о чем эта запись в блоге
Я планирую в будущем писать технические статьи о PHP, связанные с глубоким пониманием памяти. Мне нужно, чтобы мои читатели имели такие знания, которые им помогут понять некоторые концепции дальнейшего объяснения. Для того, чтобы ответить на этот вопрос, нам придется перемотать время назад в 1960-е года. Я собираюсь объяснить вам, как работает компьютер, а точнее, как происходит доступ к памяти в современном компьютере, а затем вы поймете, из-за чего происходит это странное сообщение об ошибке — Segmentation Fault.
То, что вы будете читать здесь, краткое изложение основ дизайна компьютерной архитектуры. Я не буду заходить слишком далеко, если это не нужно, и буду использовать хорошо известные формулировки, так что, кто работает с компьютером каждый день может понять такие важные понятия о том, как работает ПК. Существует много книг о компьютерной архитектуре. Если вы хотите углубиться дальше в этой теме, я предлагаю вам достать некоторые из них и начать читать. Кроме того, откройте исходный код ядра ОС и изучите его, будь то ядро Linux, или любое другое.
Немного истории computer science
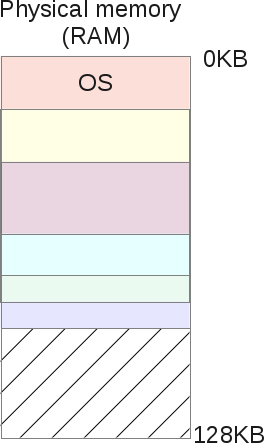
Еще в то время, когда компьютерами были огромные машины, тяжелее тонны, внутри вы могли бы найти один процессор с чем-то вроде 16Kb оперативной памяти (RAM). Не будем углубляться дальше =) В этот период компьютер стоил примерно $ 150 000 и мог выполнить ровно одну задачу в момент времени. Если бы мы в то время нарисовали схему его памяти, то архитектура выглядела следующим образом:
Как вы можете видеть, размер памяти 16Кб, и состоит из двух частей:
- Область памяти операционной системы(4kb)
- Область памяти запущенных процессов (12Kb)
Роль операционной системы заключалась в управлении прерываниями центрального процесса аппаратными средствами. Таким образом, операционная система нуждалась в памяти для себя, чтобы копировать данные с устройства и работать с ними (режим PIO). Для предоставления данных на экран тоже была необходима основная память, так как видеоадаптеры имели от нуля до нескольких килобайт памяти. И наша сольная программа использовала память ОС для достижения поставленных задач.
<Совместное использование компьютера
Но одна из главных проблем такой модели заключается в том, что компьютер (стоимостью $ 150 000) мог выполнять только одну задачу единовременно, и эта задача ужасно долго выполнялась: целые дни, чтобы обработать несколько Кб данных. По такой огромной цене явно не представляется возможным купить несколько машин, чтобы выполнить несколько процедур одновременно. Так что люди пытались распределить ресурсы машины. Это было время рождения многозадачности. Имейте в виду, что тогда было ещё очень рано говорить о многопроцессорных ПК. Как мы можем заставить одну машину с одним процессором, и на самом деле решить несколько различных задач? Ответ на этот вопрос — планирование. Пока один процесс занят в ожидании ввода / вывода (ожидает прерывание), процессор может запустить другой процесс. Мы не будем говорить о планировании на всех уровнях (слишком широкой теме), только о памяти. Если машина может выполнять несколько задач, один процесс за другим, то это означает, что память будет распределяться примерно таким образом:
Обе, задачи А и B, сохраняются в оперативной памяти, так как копировать их туда и обратно на диск — слишком ресурсозатратный процесс. Данные должны оставаться в оперативной памяти на постоянной основе, так как их соответствующие задачи по-прежнему работают. Планировщик дает некоторое время процессора, то задаче А, то B, и т.д… каждый раз предоставляя доступ к её области памяти. Но подождите, здесь есть проблема. Когда один программист будет писать код задачи B, он должен знать адреса границ памяти. Например, задача В будет располагаться с 10Kb памяти до 12Кб. Поэтому каждый адрес в программе должен жестко записан именно в эти пределы. Если машина затем будет выполнять ещё 3 задачи, то адресное пространство будет разделено на большее количество областей, и границы памяти задачи В сдвинутся. Программисту пришлось бы переписать свою программу, чтобы использовать меньше памяти, и переписывать каждый адрес указателя памяти.
Здесь очевидна так же другая проблема: что, если задача B получит доступ к памяти задачи А? Это легко может произойти, потому что, когда вы манипулируете указателями, небольшая ошибка при вычислении приводит к совершенно другому адресу. Это может испортить данные задачи А (перезаписать их). Также существует проблема безопасности, что если задача А работает с очень чувствительными данными? Нет никакого способа, чтобы предотвратить чтение задачей B некоторой области памяти задачи А. И последнее: что, если задача B по ошибке перезапишет память ОС? Например, память ОС от 0Kb до 4Kb, в случае если задача B перепишет этот участок, то операционная система наверняка потерпит крах.
Адресное пространство
Таким образом, нужна помощь операционной системы и аппаратного обеспечения, чтобы получить возможность запускать несколько задач находящиеся в памяти. Один из способов помочь, является создание того, что называется адресное пространство. Адресное пространство является абстракцией памяти, которую операционная система даст процессу, и эта концепция является абсолютно фундаментальной, так как в настоящее время каждая часть компьютера, которую вы встретите в вашей жизни, разработана таким образом. Сейчас не существует никакой другой модели (в гражданском обществе, армия может сохранять тайну).
Каждая система в настоящее время организована с таким макетом памяти как “код — стек — куча”, и это расстраивает.
Адресное пространство содержит все задачи (процессы) которые необходимо запустить:
- Код: это машинные инструкции, которые процессор должен обработать
- Данные: данные машинных команд которые обрабатываются вместе с ними.
Адресное пространство делится следующим образом:
- Стек — это область памяти, где программа хранит информацию о вызываемых функциях, их аргументах и каждой локальной переменной в функции.
- Куча — это область памяти где программист волен делать всё что угодно.
- Код — область памяти, где будут храниться инструкции ЦП скомпилированной программы. Эти инструкции генерируются компилятором, но могут быть написаны вручную. Обратите внимание, что сегмент кода обычно делится на три части (текст, данные и BSS), но мы не будем так глубоко погружаться.
- Код всегда фиксированного размера создаётся компилятором и будет весить (в нашем примере) 1Кб.
- Стек, однако, является изменяемой зоной, так как программа работает. Когда функции вызываются, стек расширяется, при возвращении из функции: стек уменьшается.
- Куча тоже является изменяемой зоной, когда программист выделяет память из кучи (malloc()), она расширяется, а когда программист освобождает память обратно (free()), куча сужается.
Так как стек и куча являются расширяемыми зонами, они расположены на противоположных местах в одном адресном пространстве: стек будет расти вверх, а куча вниз. Они оба могут свободно расти, каждый в направлении другого. ОС должна просто проверять, чтобы зоны не перекрывались, правильно используя виртуальное пространство.
Виртуализация памяти
Если задача А получила адресное пространство, такое, которое мы видели, так же как и задача B. То как мы можем разместить их в памяти? Это кажется странным, но адресное пространство задачи А начинается от 0KB до 16Kb, так же как и задачи B. Хитрость заключается в создании виртуальной среды. На самом деле картина размещения А и В в памяти:
Когда задача А попытается получить доступ к памяти в своем адресном пространстве, например индекс 11К, где-то в своем собственном стеке, операционная система выполнит хак и на самом деле загрузит индекс памяти 1500, потому что индекс 11K принадлежит задаче B. На самом деле, всё адресное пространство каждой программы в памяти — это просто виртуальная память. Каждая программа, работающая на компьютере, обращается к виртуальным адресам, с помощью некоторых аппаратных чипов ОС будет обманывать процесс, когда он будет пытаться получить доступ к любой зоне памяти.
ОС виртуализирует память и гарантирует, что любая задача не сможет получить доступ к памяти, которой не владеет. Виртуализация памяти позволяет изолировать процесс. Задача А больше не может получить доступ к памяти задачи B и не сможет получить доступ к памяти ОС. И все это полностью прозрачно для задач на уровне пользователя, благодаря тоннам сложного кода ядра ОС. Таким образом, операционная система обслуживает каждый запрос памяти процесса. Это работает очень эффективно — даже если запущено слишком много различных программ. Для достижения этой цели процесс получает помощь от аппаратного обеспечения, главным образом от процессора и некоторых электронных компонентов вокруг него, таким как блок управления памятью (MMU ). MMU появился в начале 70-х годов, вместе с IBM, как отдельные чипы. Сейчас они встраиваются непосредственно в наши чипы CPU и являются обязательными для любой современной ОС для запуска. На самом деле, операционная система не выполняет тонны операций, а полагается на некоторые аппаратные особенности поведения, которые облегчат доступ к памяти.
Вот небольшая программа на C, показывающая некоторые адреса памяти:
#include <stdio.h>
#include <stdlib.h>
int main (int argc, символ ** argv)
{
int v = 3;
printf("Code is at %p \n", (void *)main);
printf("Stack is at %p \n", (void *)&v);
printf("Heap is at %p \n", malloc(8));
return 0;
}
На моей LP64 x86_64 машине он показывает:
Code is at 0x40054c
Stack is at 0x7ffe60a1465c
Heap is at 0x1ecf010Мы можем видеть, что адрес стека находится намного выше адреса кучи, а код расположен ниже стека. Но каждый из этих 3-х адресов являются подделками: в физической памяти, по адресу 0x7ffe60a1465c точно не расположено целое число 3. Помните, что каждая программа пользователя манипулирует адресами виртуальной памяти, тогда как программы уровня ядра, таких как само ядро ОС (или аппаратный код драйвера) могут манипулировать физическими адресами RAM.
Трансляция адреса
Адресная трансляция — это формулировка, за которой скрывается некая магическая техника. Аппаратное обеспечение (ММУ)транслирует каждый виртуальный адрес программы уровня пользователя в правильный физический адрес. Таким образом, операционная система помнит для каждой задачи соответствие между его виртуальными адресами и физическими. И это является сложной задачей. Операционная система управляет всей памятью задач на уровне пользователя для каждого требования доступа к памяти, обеспечивая тем самым полную иллюзию процессу. Таким образом, операционная система преобразует всю физическую память в полезную, мощную и простую абстракцию.
Давайте подробно рассмотрим простой сценарий:
Когда процесс запускается, операционная система бронирует фиксированную область физической памяти, скажем, 16KB. Затем сохраняет начальный адрес этого пространства в специальную переменную, называемую базой. Потом устанавливает другую специальную переменную, называемую границами (или пределом) ширины пространства — 16КB. Далее операционная система сохранит эти два значения в таблице процессов, называемой PCB (Process Control Block).
А вот как выглядит процесс виртуального адресного пространства:
А вот его физическое изображение:
ОС решила сохранить его в физической памяти в диапазоне адресов от 4K до 20K. Таким образом, базовый адрес устанавливается в 4K, а предел установлен на 4 + 16 = 20К. Когда этот процесс планируется (учитывая некоторое время процессора), операционная система считывает обратно предельные значения из PCB и копирует их в конкретные регистры процессора. Когда CPU во время работы попытается загрузить, например, виртуальный адрес 2K (что-то в его куче), CPU добавит этот адрес базы, полученный от операционной системы. Таким образом, процесс доступа памяти приведет к физическому местоположению 2K + 4K = 6К.
Физический адрес = виртуальный адрес + предел
Если полученный физический адрес (6К) находится вне границ (-4K | 20K-), это означает, что процесс попытался получить доступ к неправильному участку памяти, которым он не владеет. Процессор сгенерирует исключение, и поскольку в ОС есть обработчик исключений для этого события, ОС активируется процессором и будет знать, что исключение памяти только что произошло на CPU. Затем ОС по умолчанию передаст сигнал поврежденному процессу “SIGSEGV”. Ошибка сегментации, которая по умолчанию (это может быть изменено) завершит задачу с сообщением — “Произошел сбой в работе с недопустимым доступом к памяти”.
Перемещение памяти
Еще лучше, если задача А не запланирована, это означает, что она извлекается из CPU, так как планировщик попросил запустить другую задачу (скажем, задачу B). При выполнении задачи B ОС может свободно переместить всё физическое адресное пространство задачи A. Операционная система часто получает время процессора при выполнении пользовательских задач. Когда завершается последний системный вызов, управление ЦП возвращается к ОС, и до выполнения системного вызова ОС может делать все, что захочет, управляя памятью, перемещая все пространство процесса в различные физические слоты карт памяти.
Это относительно просто: операционная система перемещает область 16K в другую 16K свободного пространства, и просто обновляет базовые и связанные переменные задачи A. Когда задача будет возобновлена и передана CPU, процесс преобразования адреса по-прежнему будет работать, но это не приведет к тому же физическому адресу, как раньше.
Задача А не заметила ничего, с её точки зрения, её адресное пространство по-прежнему начинается от 0К до 16К. Операционная система и аппаратное обеспечение MMU берут полный контроль над каждым доступом к памяти для задачи А, давая ей полную иллюзию. Программист задачи A манипулирует своими разрешенными виртуальными адресами, от 0 до 16, а MMU будет заботиться о позиционировании в физической памяти.
Образ памяти после перемещения будет выглядеть следующим образом:
В настоящее время программист больше не должен задаваться вопросом, где его программа находиться в оперативной памяти, если другая задача работает рядом с его собственной, и какими адресами манипулировать. Это делает сама ОС вместе с очень производительным и умным аппаратным средством — “Блок управления памяти” (MMU).
Сегментация памяти
Обратите внимание на внешний вид слова «сегментация» — мы близки к объяснению почему происходят ошибки сегментации. В предыдущей главе мы объяснили о трансляции и перемещении памяти, но модель, которую мы использовали имеет свои недостатки:
Мы предположили, что каждое виртуальное адресное пространство фиксируется шириной 16Kb. Очевидно, что это не так в действительности. Операционная система должна поддерживать список физической памяти свободных слотов (шириной 16 Kb), чтобы иметь возможность найти место для любого нового процесса с просьбой начать или переместить запущенный процесс. Как сделать это эффективно, чтобы не замедлить всю систему? Как вы можете видеть, каждый процесс занимает участок памяти 16 Kb, даже если процесс не использует всё своё адресное пространство, что очень вероятно. Эта модель явно тратит много памяти, процесс потребляет1KB памяти, а его участок памяти в физической памяти 16Кб. Такие отходы называют внутренней фрагментацией: память зарезервирована, но никогда не используется.
Для решения некоторых из этих проблем, мы собираемся погрузиться в более сложную организацию памяти в ОС — сегментацию. Сегментацию легко понять: мы расширяем идею «базы и границ» трех логических сегментов памяти: кучи, кода и стека; каждого процесса — вместо того, чтобы просто рассматривать образ памяти в качестве одного уникального объекта.
При такой концепции, память между стеком и кучей больше не тратится впустую. Вот так:
Теперь легко заметить, что свободное пространство в виртуальной памяти для задач А больше не выделяется в физической памяти, использование памяти становится гораздо более эффективным. Единственным отличием является то, что в настоящее время для любой задачи, ОС должна запоминать не одну пару баз/границ, а три: по одной паре для каждого типа сегмента. ММУ заботится о переводе, так же, как и раньше, и теперь поддерживает, 3 базовых величин, и 3 границ.
Например, здесь, куча задачи A имеет базу 126K и границы 2К. Затем задача просит доступ к виртуальному адресу 3KB, в куче; физический адрес 3Kb — 2Кб (начало кучи) = 1Kb + 126K (смещение) = 127K. 127K находится перед 128К — это правильный адрес памяти, который может быть выполнен.
Совместное использование сегментов
Сегментирование физической памяти не только решает проблему свободной виртуальной памяти, освобождая больше физической памяти, но она также позволяет разделить физические сегменты с помощью различных процессов виртуальных адресных пространств. Если запустить дважды ту же задачу, задачу А например, сегмент кода точно такой же: обе задачи выполняют одни и те же команды процессора. Обе задачи будут использовать свой собственный стек и кучу, обращаться к своим собственным наборам данных. Неэффективно дублировать сегмент кода в памяти. ОС теперь может разделить его и сэкономить еще больше памяти. Например так:
На картинке выше, А и В имеют свою собственную область кода в их соответствующем виртуальном пространстве памяти, но под капотом. Операционная система разделяет эту область в одних и тех же физических сегментах памяти. Обе задачи А и В абсолютно не видят этого, для них обеих — они владеют своей памятью. Для достижения этой цели ОС должна реализовать еще одну особенность: бит защиты сегмента. ОС будет для каждого физического сегмента создавать, регистрировать границы / пределы для правильной работы блока MMU, но она также зарегистрирует флаг разрешения.
Поскольку код не является изменяемым, сегменты кода все созданы с флагом разрешения RX. Процесс может загрузить эту область памяти для выполнения, но любой процесс, попытавшийся писать в эту область памяти, будет завершен ОС. Остальные два сегмента: куча и стек являются RW, процессы могут читать и писать от своего собственного стека / кучи, но они не могут выполнять код из него (это предотвращает недостатки безопасности программы, где плохой пользователь может захотеть повредить кучу или стек, чтобы ввести код для запуска, которому будет доступно ядро ОС. Это невозможно, так как куча и стек сегментов часто не являются исполняемыми. Обратите внимание, что это было не всегда, так как требует дополнительной поддержки аппаратного обеспечения для эффективной работы, это называется «бит NX» под процессором Intel). Сегменты памяти разрешений изменяемы во время выполнения: задача может потребовать mprotect () от ОС. Эти сегменты памяти отчетливо видны под Linux, используйте утилиты /proc/{pid}/maps или /usr/bin/pmap
Ниже приведен пример для PHP:
$ pmap -x 31329
0000000000400000 10300 2004 0 r-x-- php
000000000100e000 832 460 76 rw--- php
00000000010de000 148 72 72 rw--- [ anon ]
000000000197a000 2784 2696 2696 rw--- [ anon ]
00007ff772bc4000 12 12 0 r-x-- libuuid.so.0.0.0
00007ff772bc7000 1020 0 0 ----- libuuid.so.0.0.0
00007ff772cc6000 4 4 4 rw--- libuuid.so.0.0.0
... ...Здесь мы детально видим все отображения памяти. Адреса являются виртуальными и отображают их разрешения области памяти. Как мы можем видеть, каждый общий объект (.so) отображается в адресное пространство как несколько отображений (вероятно кода и данных), и области кода являются исполнимыми, а под капотом они разделяются в физической памяти между каждым процессом, отображающим такой общий объект в его собственное адресное пространство…
Самое большое преимущество разделяемых объектов под Linux (и Unix) — это экономия памяти. Возможно также создать общую зону, ведущую к общему физическому сегменту памяти, с помощью системного вызова mmap(). Буква 's', появившаяся рядом с этой областью, означает “разделяемая”.
Пределы Сегментации
Мы видели, что сегментация решает проблему не используемой виртуальной памяти. Когда процесс не использует некоторый объем памяти, этот процесс не отображается в физическую память благодаря сегментам, которые соответствуют выбранной памяти. Тем не менее, это не совсем верно. Что делать, если процесс требует 16Kb кучи? ОС, скорее всего, создаст сегмент физической памяти размером 16КБ. Но если пользователь затем освобождает 2Кб такой памяти? Тогда, ОС должна уменьшить сегмент 16Кб до 14kb. Что делать, если теперь программист спрашивает 30Kb кучи? Старый сегмент 14Kb теперь должен вырасти до 30 КБ, но может ли он это сделать? Другие сегменты теперь могут окружать наш сегмент 14kb, препятствуя его росту. Тогда ОС придется искать свободное пространство 30 КБ, а затем перемещать сегмент.
Большая проблема с сегментами в том, что они приводят к очень фрагментированной физической памяти, потому что они продолжают расти, поскольку пользовательские задачи запрашивают и освобождают память. Операционная система должна поддерживать список свободных кусочков памяти и управлять ими.
Иногда, ОС путем суммирования всех свободных сегментов получает некоторое доступное пространство, но так как оно не соприкасается, она не может использовать это пространство и должна отказать требованию памяти от процессов, даже если существует пространство в физической памяти. Это очень плохой сценарий. Операционная система может попытаться сжать память путем слияния всех свободных участков в один большой кусок, который можно было бы использовать в будущем, чтобы удовлетворить запрос памяти.
Но такой алгоритм уплотнения сложен для CPU, и в это время ни один пользовательский процесс не сможет получить CPU: операционная система полностью загружена реорганизацией своей физической памяти, таким образом, система становится непригодной для использования. Сегментация памяти решает множество проблем управления памятью и многозадачности, но она также показывают реальные недостатки. Таким образом, существует необходимость в расширении возможностей сегментации и исправлении этих недостатков. Отсюда образовалось ещё одно понятие — “пагинация памяти”.
Пагинация памяти
Пагинация страниц памяти разделяет некоторые концепции сегментации памяти и пытается решить её проблемы. Мы увидели, что основной проблемой сегментации памяти является то, что сегменты будут увеличиваться и уменьшаться очень часто, так как пользовательский процесс запрашивает и освобождает память. Иногда операционная система сталкивается с проблемой. Она не может найти большую область свободного места, чтобы удовлетворить запрос памяти пользовательского процесса, потому что физическая память стала сильно фрагментирована с течением времени: она содержит много сегментов разного размера по всей физической памяти, что приводит к сильно фрагментированной физической памяти.
Разбивка решает эту проблему с помощью простой концепции: что если для каждого физического распределения ядро будет выделять фиксированный размер? Страницы — это сегменты физической памяти фиксированного размера. Если операционная система использует распределения фиксированного размера, то намного легче управлять пространством, что в итоге сводит на нет фрагментацию памяти.
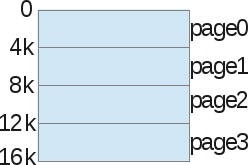
Давайте покажем пример еще раз, предполагая небольшое 16Кб виртуальное адресное пространство, чтобы облегчить представление:
С пагинацией мы не говорим о кучи, стеке или сегменте кода. Мы разделим весь процесс виртуальной памяти на зоны фиксированного размера: мы называем их страницы. На приведенном выше примере мы разделили адресное пространство в виде 4-х страниц, 4КБ каждый.
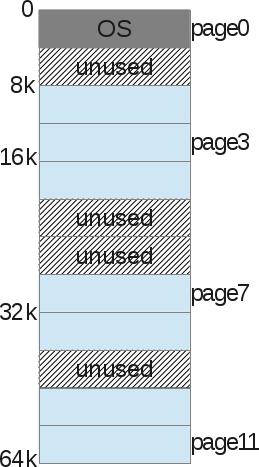
Затем мы делаем то же самое с физической памятью.
И операционная система просто хранит то, что называется «Таблица процессорных страниц» — связь между одной страницей виртуальной памяти процесса и базовой физической страницей (который мы называем «страница кадра»).
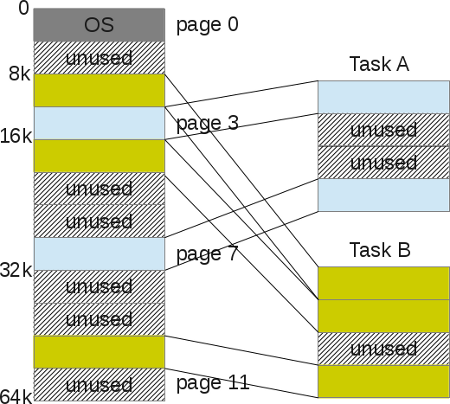
С помощью этого способа управления памятью больше нет проблем в свободном управлении пространством. Кадр страницы отображается (используется) или нет, ядру легко найти достаточное количество страниц, чтобы удовлетворить запрос памяти пользовательского процесса. Он просто хранит список свободных страниц кадров, а также просматривает его при каждом запросе памяти. Страница является наименьшей единицей памяти, которой ОС может управлять. Страница (на нашем уровне) является неделимой. Вместе со страницами каждому процессу прилагается таблица страниц, которая хранит адресные переводы. Переводы больше не используют значения границы, как это было с сегментацией, а использует «номер виртуальной страницы (VPN)» и «смещение» на этой странице.
Давайте покажем пример преобразования адресов с нумерацией страниц. Виртуальное адресное пространство размером 16Kb, т.е. нам нужно 14 бит для представления адреса (2 ^ 14 = 16Kb). Размер страницы 4 Кб, так что нам нужно 4kb (16/4), чтобы выбрать нашу страницу:
Теперь, когда процесс хочет загрузить, например, адрес 9438 (из 16384 возможностей), это дает 10.0100.1101.1110 в двоичной системе, что приводит к следующему:
То есть 1246й байт виртуальной страницы 2 ( «0100.1101.1110» го байта в «10» й странице). Теперь, операционная система должна искать эту страницу таблицы процессов, чтобы узнать на какой странице 2я карта. Согласно тому, что мы предложили, страница 2 — это 8К байт в физической памяти. Таким образом, виртуальный адрес 9438 приводит к физическому адресу 9442 (8k + 1246 смещение). Мы нашли наши данные! Как мы уже говорили, существует лишь одна таблица страниц для каждого процесса, поскольку каждый процесс будет иметь свои собственные переводы адреса, так же, как с сегментами. Но подождите, где эти таблицы страниц хранятся на самом деле? Угадайте ...: в физической памяти, да, а где же ей ещё быть? Если таблицы страниц сами хранятся в памяти, следовательно, для каждого доступа к памяти, память должна иметь доступ для извлечения VPN. Таким образом, со страницами один доступ к памяти равен фактически двум доступам к памяти: один для извлечения записи таблицы страниц, и один, чтобы получить доступ к «реальным» данным. Зная, что доступ к памяти медленный процесс, получаем — что это не лучшая идея.
Переводно-ассоциативный буфер: TLB
Использование поискового вызова в качестве механизма ядра для поддержки виртуальной памяти может привести к высокой производительности накладных расходов. Измельчение адресного пространства на небольшие фиксированного размера единицы (страницы) требует большого количества информации о карте. Потому что информация о карте, как правило, хранится в физической памяти. Логический поиск подкачки требует дополнительного поиска в памяти для каждого виртуального адреса, сгенерированного программой. И тут опять приходят аппаратные средства, чтобы ускорить и помочь ОС. В пагинации, как и в сегментации, аппаратные средства помогают ядру ОС перевести адреса эффективным приемлемым способом. TLB является частью MMU, всего лишь простой кэш некоторых VPN переводов. TLB будет предотвращать доступ ОС к памяти от доступа к таблице страниц процесса, для получения физического адреса памяти из виртуальной. Аппаратное обеспечение MMU будет срабатывать на каждом виртуальном доступе к памяти, извлекая VPN из этого адреса, и выполняя поиск TLB, если он совпадает для этого конкретного VPN. Если он совпал, то он просто выполнил свою роль. Если он получает промах, то он будет искать таблицу страниц процесса, и если ссылка на память действительна, она обновит TLB, так что любой дальнейший доступ памяти этой страницы попадет в TLB.
Как и в любом кэше, вы чаще попадете, чем получите промах, так как ситуация промах вызывает страницу поиска, вследствие чего, доступ к памяти будет медленным. Вы догадаетесь об этом. Чем больше страниц, тем лучше TLB попадает, но тем больше неиспользуемого пространства вы будете иметь на каждой странице. Здесь должен быть найден компромисс. Современные ядра используют различные размеры страницы. Ядро Linux может использовать то, что называется «огромные страницы», страницы, размером 2Mb что больше традиционных 4Kb. Кроме того, информацию лучше хранить в смежных адресах памяти. Если вы сократите свои данные в памяти, то скорее всего будете страдать от пропусков TLB или от переполнения TLB. Это то, что называется Эффективность пространственной локальности TLB: Данные, находящиеся непосредственно рядом с вами, могут быть сохранены в той же физической странице, таким образом, получая выгоду из текущего доступа к памяти из TLB.
Для переключения контекста TLB хранит также то, что называется ASID в каждой из своих записей. Это идентификатор адресного пространства, который является чем-то вроде PID. Каждый запланированный процесс имеет свой собственный ASID, следовательно TLB может управлять любым адресом процесса без риска недействительных адресов из других процессов. Также, если пользовательский процесс попытается загрузить неверный адрес, адрес, скорее всего, не будет сохранен в TLB, следовательно произойдет промах в поиске в записи таблицы страниц процесса. Теперь адрес сохраниться, но с неверным битом. Под X86 каждый перевод использует 4 байта, таким образом, имеется много бит. И нередко можно найти действительный бит вместе с другими составными, такими как грязный бит, биты защиты, опорного бита и т.д.… Если запись помечена как недопустимая, ОС по умолчанию использует SIGSEGV, что приводит к «ошибке сегментации», даже если здесь мы больше не говорим о сегментах. Вы должны знать, что подкачка более сложна в современных ОС, чем я объяснил. Современные ОС, как правило, используют многоуровневые таблицы страниц, многостраничные размеры, а также важную концепцию, которую мы не будем объяснять. Страница выселения, известная как «swaping» (Процесс, когда ядро обменивает страницы памяти на дисковое пространство, чтобы эффективно использовать главную память и создать иллюзию для пользовательских процессов, что основная память не ограничена в пространстве).
Вывод
Теперь вы знаете, что находится под сообщением «Ошибка сегментации». Операционная система использует сегменты для отображения виртуальной памяти в физической памяти. Когда процесс ядра хочет получить доступ к некоторой памяти, он выдает требование о том, чтобы MMU переводил на физический адрес памяти. Но если этот адрес не правильный, из пределов физического сегмента, или если права защиты сегмента не подходящие, то ОС по умолчанию посылает сигнал процессу, вызвавшего отказ: SIGSEGV, который имеет обработчик по умолчанию. Он убивает процесс и выводит сообщение: «Ошибка сегментации”. В других операционных системах (предполагаю) часто сообщение выглядит как „Общая неисправность защиты“. С Linux — нам повезло, мы имеем возможность доступа к исходному коду, здесь есть место исходного кода для X86 / 64 платформ, которое управляет ошибками доступа к памяти, так же здесь и SIGSEGV. Если вы заинтересованы в разработке сегментов для X86 / 64 платформ, вы можете посмотреть на их определение в ядре Linux. Вы также найдете интересный материал о пейджинговой памяти, которая поддерживает более длинный путь сегментирования памяти, чем использование классических сегментов. Мне понравилось писать эту статью, она перенесла меня в конец девяностых, когда я программировал свой первый CPU: Motorola 68HC11 с использованием C, VHDL и прямого монтажа. Я не программировал виртуальное управления памятью ОС, а использовал физические адреса напрямую (моему процессору не нужны такие сложные механизмы). Затем я подался в Web; но мои первые знания пришли от электроники, систем которые мы используем каждый день…
