Привет, Хабр. Рад представить свою первую статью: описание прототипа игрового мультиплеерного сервера.
→ Исходный код (под лицензией Apache 2.0)
Содержание:
Входной точкой является websocket-контроллер, принимающий всевозможные реквесты от пользователей: начиная от логина и заявок на игру до игровых ходов и написания сообщений в чат. Этот контроллер обслуживает thread-pool (около 20 потоков).
Одной из самых важных вещей в игре — является быстрая обработка игровых действий (приоритетный безнес-кейз). То есть в идеале игра должна мгновенно реагировать на действия пользователя и не «зависать». В то время как для множества других не игровых действий, таких например, как аутентификация, написание сообщений в чат или матчинг игроков (для совместной игры) — большая или меньшая задержка вполне приемлема для пользователя.
Поэтому архитектуру я постарался спроектировать также и в соответствии с этим требованием (см. картинку):
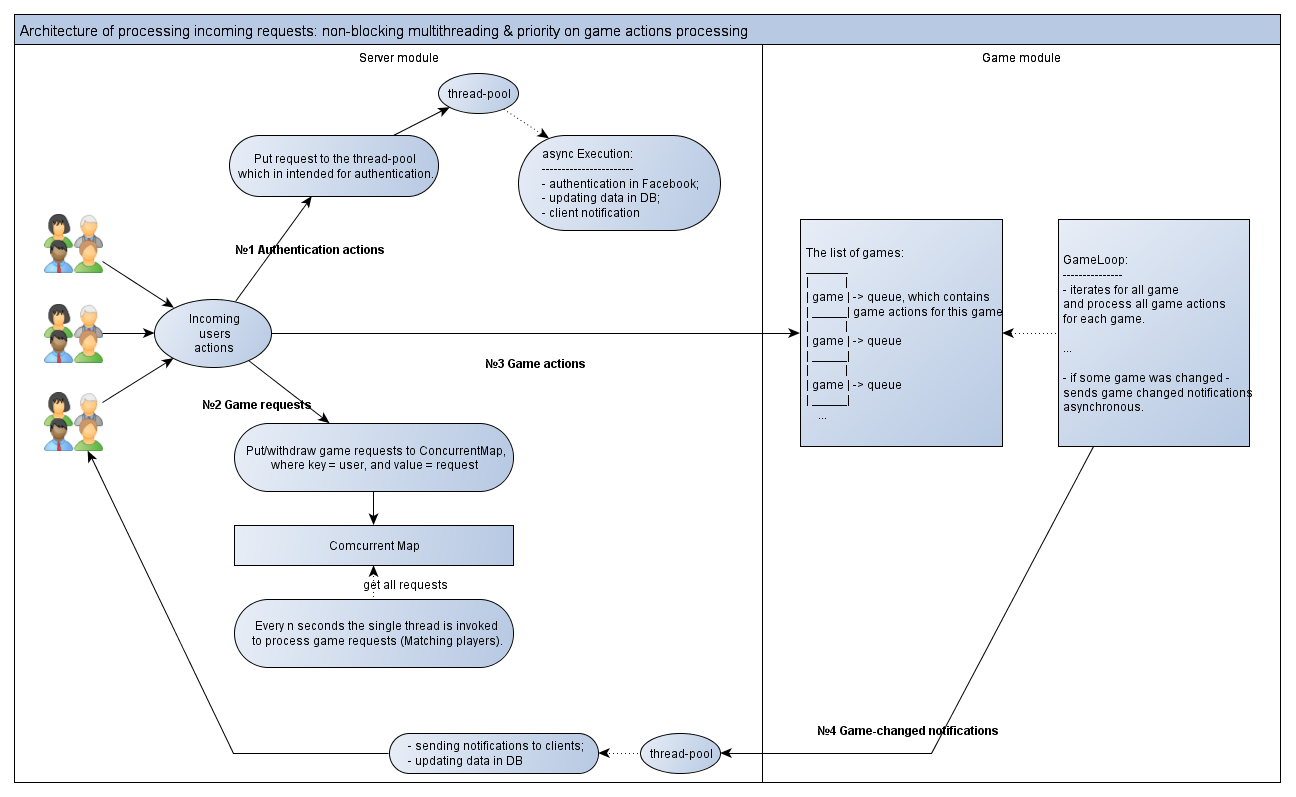
Входящие запросы на аутентификацию помещаются в очередь в специальный thread-pool. После этого поток сразу отпускается и снова готов принимать действия пользователя.
Сама же обработка аутентификации будет проходить уже в асинхронном режиме. Она включает:
— аутентификацию в Facebook'е;
— создание либо обновление данных о пользователе в БД;
— отсылку информации на клиент в случае успешного логина.
Размер этого thread-pool можно регулировать уже в зависимости от нагруженности сервера.
При запросе игрока создать игровую заявку — решением в лоб было бы сразу вызывать функционал (функцию/метод), который бы матчил игроков. А в целях потокобезопасности добавить какой-либо вариант блокирования общего ресурса (в нашем случае это список заявок на игру). То есть берём лок, затем матчим игроков, затем создаём мужду ними игру и рассылаем нотификации на клиенты. Если эти операции занимают относительно длительное время, то все остальные потоки, ожидающие снятия лока, будут простаивать впустую. Как следствие — сервер может потенциально не принимать входящих игровых действий, которые должны поступать в Game Loop немедленно.
Также этот вариант является потенциально плохо масштабируемым: с ростом числа потоков — они все могут вставать (блочить друг друга) при обращении к этому разделяемому ресурсу. Отсюда будет мало выгоды при вертикальном масштабировании и увеличении кол-ва потоков. Поэтому я придумал другой вариант (кстати, если у этого подхода есть название — пишите в комментарии):
В новом варианте запросы на игру добавляются в Concurrent Map, где key — это пользователь, а value — заявка на игру.
Всё — после этого входящий поток сразу отпускается.
Потоки даже не всегда будут блочить друг друга (при записи в неё), так как ConcurrentMap лочит не всю мапу, а сегмент.
Раз в n секунд вызывается ровно 1 поток для обработки входящих игровых заявок (Matching players). Он спокойно и обрабатывает эту мапу. Тем самым обеспечивается потокобезопасность без блокировок и быстрое отпускание входящих потоков.
Это решение обладает ещё одним плюсом — оно позволяет «набиться» заявкам и потом сматчить их более подходящим образом. Логика и реализация стали проще.
Здесь несколько сложнее:
1) Входящие игровые действия (ходы) просто складываются в специальную очередь (для каждой игры предназначена своя очередь). Эта очередь просто хранит совершённые игроками действия. После этого поток традиционно отпускается.
2) Как водится, у нас есть GameLoop (игровой цикл). Он обходит список всех игр. Далее для каждой игры он достаёт связанную с ней очередь. И уже из этой очереди достаёт сделанные игроками ходы. Затем последовательно обрабатывает каждое действие. Всё просто.
В принципе, также возможно распараллелить обработку разных игр по пулу потоков. Это возможно, так как игры никак не связаны друг с другом. Этот функционал также можно сделать неблокирующим: достаточно, например, использовать неблокирующие локи из библиотеки java.util.concurrent. Либо, если у нас распределенное решение, — использовать Hazelcast как распределенный кэш с возможностью лочить ключи в шареной мапе… Однако данный функционал не требуется, так как обработка игровых действий итак слишком быстрая. Поэтому GameLoop выполняется в одном потоке.
3) Есть еще один момент — если игра изменилась, то на клиенты нужно отправить уведомления, а также, при необходимости, обновить данные в БД. Это также сделано в асинхронном режиме (№ 4 на картинке), чтобы не тормозить GameLoop.
Резюмируя
Архитектура спроектирована так, чтобы:
— Реквесты с игровыми действиями обладали максимальным приоритетом перед другими типами запросов (например, перед логином, или заявкой на игру).
Чтобы не было такого, что пришло 100 запросов на аутентификацию и «забили» thread-pool (обслуживающий пользовательские запросы). При этом поступающие игровые действия вставали бы в очередь, и все игры разом «притормаживали» бы на несколько секунд.
— Везде была неблокирующая многопоточность.
Такой подход поддерживает вертикальное масштабирование и увеличение количества потоков. Статья в тему, см. раздел «Проблемы масштабируемости»
Одной из малоприоритетных задач было сделать слабое связывание между модулем сервера и модулем игры. Иными словами, чтобы можно было легко «выдернуть» саму игру и прицепить её к Desktop-UI. Либо поместить другую игру настольного типа к многопользовательскому серверу.
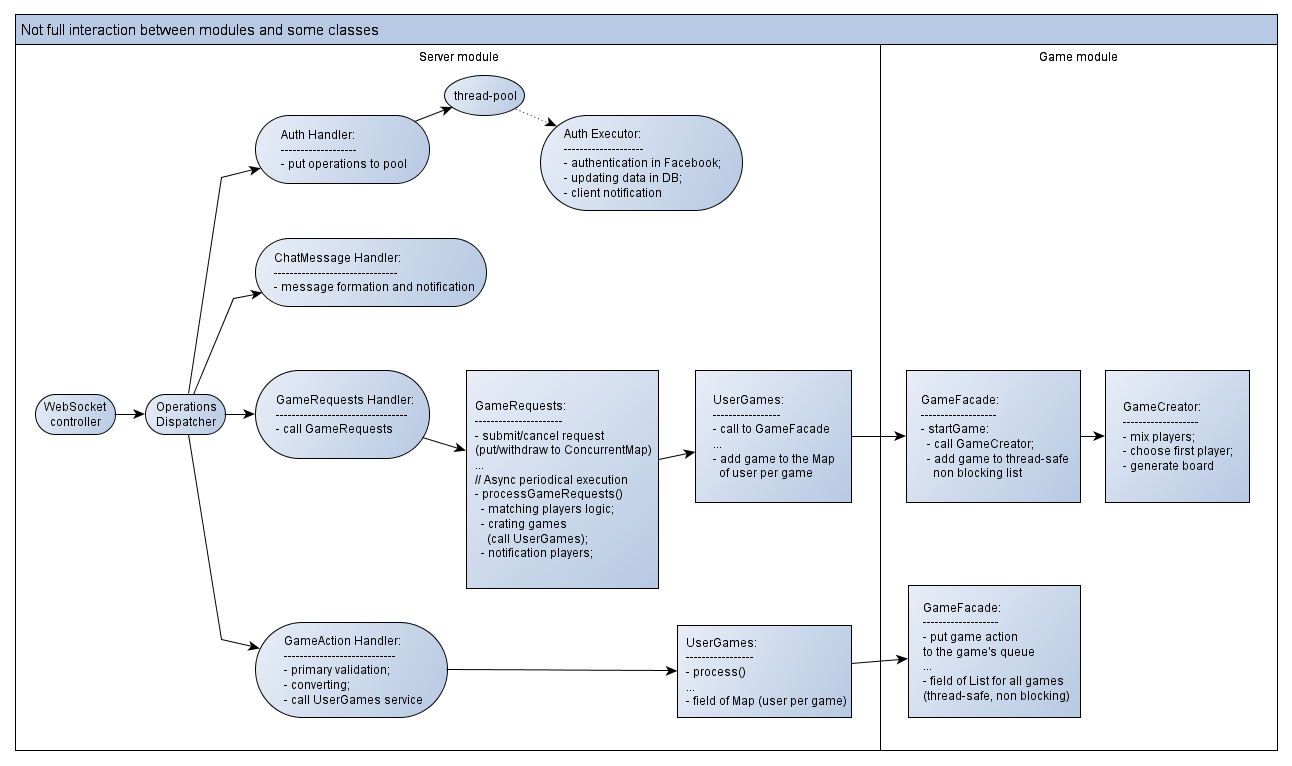
Это достигается за счёт разграничения зон ответственности. Проект разбит на три модуля: сервер, игровое API и реализация игры.
Вся игровая логика «зашита» в модуле игры. Сервер просто переадресует через code API (Java-код) принимаемые игровые действия в контроллер игры. Ответы от игры приходят либо сразу же, либо отложено — через подписку (шаблон Subscriber).
Модуль игры ничего не знает о том, кто будет вызывать его по java API и подписываться на события. Для лучшего понимания взаимодействия между сервером и игрой выделен отдельный модуль — игровое API — это набор контрактов (интерфейсов). Сервер вызывает только их. А игровой модуль предоставляет реализацию.
Имеются как юнит, так и интеграционные тесты.
В целом, тесты используются там, где есть сложно/долго/нудно тестируемые кейзы.
Например, это могут быть разные варианты дисконнектов: допустим, если пользователь приконнектился с нового устройства, то старый коннекшн нужно закрыть. Или, например, это проверка дисконнекта, если пользователь был неактивен 15 минут (чтобы не ждать так долго — многие параметры вынесены в переменные среды и «замокированы» на несколько миллисекунд для быстрого прогона тестов).
Также есть проверка чата: что разные пользователи видят сообщения друг друга.
Есть проверки игровых запросов и создание игры.
Под вышеперечисленные кейзы хорошо подошли интеграционные тесты, поднимающие сервер и IoC-контекст (замоканы внешние системы).
Также используются и юнит-тесты. Например, там, где не нужно поднимать контекст; или там, где надо проверить множество вариаций входящих параметров.
К примеру, юнит-тесты используются при покрытии игровых правил. Каждый игровой рул реализован отдельным классом с единственной public-методом. Является чистой функцией и легко покрывается тестом.
И далее — из этих функций-рулов составляется уже бизнес-логика в отдельном классе. Так намного легче читать и понимать код.
В целом при выборе типа и методов написания тестов мне понравился этот доклад: «Hexlet — Тестирование и TDD».
Аналогично быстрой обработке игровых запросов — также просчитано и с кэшированием обращений к БД. При аутентификации происходит считывание данных пользователя в кэш (если в кэше их еще не было). После чего все редкие запросы этих данных достаются из кэша. По окончании игры (что случается не часто) происходит запись в БД с обновлением инфы в кэше.
На код и функционал клиента лучше не смотреть: для прототипа там требовалось крайне мало функционала, поэтому написан он по-быстрому. Все точки расширения функционала, генерализованный код заложен на бэкенде.
Не все моменты раскрыты в статье. В частности про управление коннекшенами и дисконнекты (например, в случае открытия сессии нового устройства). В игре также есть система рейтинга и топ-100 игроков на главной таблице. Есть не только мультиплеер, но и игра с ботами. Заложены точки расширения функционала по разным аспектам как сервера так и игры.
Игра написана на Java. С активным использованием Spring Framework, который из коробки даёт работу с Websocket'ами (Spring WebSocket), интеграционные тесты (Spring Boot Test) и кучу других плюшек (DI, например).
Горизонтальное масштабирование для вебсокетов сделать не так просто. Поэтому в целях скорости для прототипа было решено его не делать.
Сервер хостится на бесплатном аккаунте на Heroku. Согласно этому бесплатному тарифу сервер вырубается, если в течение 30 минут к нему не было запросов. Было найдено элегантное решение — я просто зарегистрировался на сайте мониторингов, которые периодически пингуют сервер. Как бонус — получение дополнительной информацию по мониторингу.
Также имеется бесплатный Postgre с лимитом 10к строк. Из-за этого приходится периодически запускать удаление неактуальных аккаунтов.
→ Исходный код (под лицензией Apache 2.0)
Содержание:
- Архитектура обработки входящих запросов
- Краткое описание прочих моментов
- Модули и взаимодействия основных классов
- Разные виды тестов
- Кэширование при работе с БД
Архитектура обработки входящих действий от пользователя
Входной точкой является websocket-контроллер, принимающий всевозможные реквесты от пользователей: начиная от логина и заявок на игру до игровых ходов и написания сообщений в чат. Этот контроллер обслуживает thread-pool (около 20 потоков).
Одной из самых важных вещей в игре — является быстрая обработка игровых действий (приоритетный безнес-кейз). То есть в идеале игра должна мгновенно реагировать на действия пользователя и не «зависать». В то время как для множества других не игровых действий, таких например, как аутентификация, написание сообщений в чат или матчинг игроков (для совместной игры) — большая или меньшая задержка вполне приемлема для пользователя.
Поэтому архитектуру я постарался спроектировать также и в соответствии с этим требованием (см. картинку):
Запросы на аутентификацию (№1 на картинке)
Входящие запросы на аутентификацию помещаются в очередь в специальный thread-pool. После этого поток сразу отпускается и снова готов принимать действия пользователя.
Сама же обработка аутентификации будет проходить уже в асинхронном режиме. Она включает:
— аутентификацию в Facebook'е;
— создание либо обновление данных о пользователе в БД;
— отсылку информации на клиент в случае успешного логина.
Размер этого thread-pool можно регулировать уже в зависимости от нагруженности сервера.
Запросы на игру (№2 на картинке)
При запросе игрока создать игровую заявку — решением в лоб было бы сразу вызывать функционал (функцию/метод), который бы матчил игроков. А в целях потокобезопасности добавить какой-либо вариант блокирования общего ресурса (в нашем случае это список заявок на игру). То есть берём лок, затем матчим игроков, затем создаём мужду ними игру и рассылаем нотификации на клиенты. Если эти операции занимают относительно длительное время, то все остальные потоки, ожидающие снятия лока, будут простаивать впустую. Как следствие — сервер может потенциально не принимать входящих игровых действий, которые должны поступать в Game Loop немедленно.
Также этот вариант является потенциально плохо масштабируемым: с ростом числа потоков — они все могут вставать (блочить друг друга) при обращении к этому разделяемому ресурсу. Отсюда будет мало выгоды при вертикальном масштабировании и увеличении кол-ва потоков. Поэтому я придумал другой вариант (кстати, если у этого подхода есть название — пишите в комментарии):
В новом варианте запросы на игру добавляются в Concurrent Map, где key — это пользователь, а value — заявка на игру.
Всё — после этого входящий поток сразу отпускается.
Потоки даже не всегда будут блочить друг друга (при записи в неё), так как ConcurrentMap лочит не всю мапу, а сегмент.
Раз в n секунд вызывается ровно 1 поток для обработки входящих игровых заявок (Matching players). Он спокойно и обрабатывает эту мапу. Тем самым обеспечивается потокобезопасность без блокировок и быстрое отпускание входящих потоков.
Это решение обладает ещё одним плюсом — оно позволяет «набиться» заявкам и потом сматчить их более подходящим образом. Логика и реализация стали проще.
Обработка игровых действий (№ 3 на картинке)
Здесь несколько сложнее:
1) Входящие игровые действия (ходы) просто складываются в специальную очередь (для каждой игры предназначена своя очередь). Эта очередь просто хранит совершённые игроками действия. После этого поток традиционно отпускается.
2) Как водится, у нас есть GameLoop (игровой цикл). Он обходит список всех игр. Далее для каждой игры он достаёт связанную с ней очередь. И уже из этой очереди достаёт сделанные игроками ходы. Затем последовательно обрабатывает каждое действие. Всё просто.
В принципе, также возможно распараллелить обработку разных игр по пулу потоков. Это возможно, так как игры никак не связаны друг с другом. Этот функционал также можно сделать неблокирующим: достаточно, например, использовать неблокирующие локи из библиотеки java.util.concurrent. Либо, если у нас распределенное решение, — использовать Hazelcast как распределенный кэш с возможностью лочить ключи в шареной мапе… Однако данный функционал не требуется, так как обработка игровых действий итак слишком быстрая. Поэтому GameLoop выполняется в одном потоке.
3) Есть еще один момент — если игра изменилась, то на клиенты нужно отправить уведомления, а также, при необходимости, обновить данные в БД. Это также сделано в асинхронном режиме (№ 4 на картинке), чтобы не тормозить GameLoop.
Резюмируя
Архитектура спроектирована так, чтобы:
— Реквесты с игровыми действиями обладали максимальным приоритетом перед другими типами запросов (например, перед логином, или заявкой на игру).
Чтобы не было такого, что пришло 100 запросов на аутентификацию и «забили» thread-pool (обслуживающий пользовательские запросы). При этом поступающие игровые действия вставали бы в очередь, и все игры разом «притормаживали» бы на несколько секунд.
— Везде была неблокирующая многопоточность.
Такой подход поддерживает вертикальное масштабирование и увеличение количества потоков. Статья в тему, см. раздел «Проблемы масштабируемости»
Краткое описание прочих моментов
Одной из малоприоритетных задач было сделать слабое связывание между модулем сервера и модулем игры. Иными словами, чтобы можно было легко «выдернуть» саму игру и прицепить её к Desktop-UI. Либо поместить другую игру настольного типа к многопользовательскому серверу.
Это достигается за счёт разграничения зон ответственности. Проект разбит на три модуля: сервер, игровое API и реализация игры.
Вся игровая логика «зашита» в модуле игры. Сервер просто переадресует через code API (Java-код) принимаемые игровые действия в контроллер игры. Ответы от игры приходят либо сразу же, либо отложено — через подписку (шаблон Subscriber).
Модуль игры ничего не знает о том, кто будет вызывать его по java API и подписываться на события. Для лучшего понимания взаимодействия между сервером и игрой выделен отдельный модуль — игровое API — это набор контрактов (интерфейсов). Сервер вызывает только их. А игровой модуль предоставляет реализацию.
Имеются как юнит, так и интеграционные тесты.
В целом, тесты используются там, где есть сложно/долго/нудно тестируемые кейзы.
Например, это могут быть разные варианты дисконнектов: допустим, если пользователь приконнектился с нового устройства, то старый коннекшн нужно закрыть. Или, например, это проверка дисконнекта, если пользователь был неактивен 15 минут (чтобы не ждать так долго — многие параметры вынесены в переменные среды и «замокированы» на несколько миллисекунд для быстрого прогона тестов).
Также есть проверка чата: что разные пользователи видят сообщения друг друга.
Есть проверки игровых запросов и создание игры.
Под вышеперечисленные кейзы хорошо подошли интеграционные тесты, поднимающие сервер и IoC-контекст (замоканы внешние системы).
Также используются и юнит-тесты. Например, там, где не нужно поднимать контекст; или там, где надо проверить множество вариаций входящих параметров.
К примеру, юнит-тесты используются при покрытии игровых правил. Каждый игровой рул реализован отдельным классом с единственной public-методом. Является чистой функцией и легко покрывается тестом.
И далее — из этих функций-рулов составляется уже бизнес-логика в отдельном классе. Так намного легче читать и понимать код.
В целом при выборе типа и методов написания тестов мне понравился этот доклад: «Hexlet — Тестирование и TDD».
Аналогично быстрой обработке игровых запросов — также просчитано и с кэшированием обращений к БД. При аутентификации происходит считывание данных пользователя в кэш (если в кэше их еще не было). После чего все редкие запросы этих данных достаются из кэша. По окончании игры (что случается не часто) происходит запись в БД с обновлением инфы в кэше.
На код и функционал клиента лучше не смотреть: для прототипа там требовалось крайне мало функционала, поэтому написан он по-быстрому. Все точки расширения функционала, генерализованный код заложен на бэкенде.
Не все моменты раскрыты в статье. В частности про управление коннекшенами и дисконнекты (например, в случае открытия сессии нового устройства). В игре также есть система рейтинга и топ-100 игроков на главной таблице. Есть не только мультиплеер, но и игра с ботами. Заложены точки расширения функционала по разным аспектам как сервера так и игры.
Игра написана на Java. С активным использованием Spring Framework, который из коробки даёт работу с Websocket'ами (Spring WebSocket), интеграционные тесты (Spring Boot Test) и кучу других плюшек (DI, например).
Горизонтальное масштабирование для вебсокетов сделать не так просто. Поэтому в целях скорости для прототипа было решено его не делать.
Пара смешных моментов
Сервер хостится на бесплатном аккаунте на Heroku. Согласно этому бесплатному тарифу сервер вырубается, если в течение 30 минут к нему не было запросов. Было найдено элегантное решение — я просто зарегистрировался на сайте мониторингов, которые периодически пингуют сервер. Как бонус — получение дополнительной информацию по мониторингу.
Также имеется бесплатный Postgre с лимитом 10к строк. Из-за этого приходится периодически запускать удаление неактуальных аккаунтов.
